







在 MapReduce 组件里,官方给我们提供了一些样例程序,其中非常有名的就是 wordcount 和 pi 程序。这些 MapReduce 程序的代码都在 hadoop-mapreduce-examples-2.6.4.jar 包里,这 个 jar 包在 hadoop 安装目录下的/share/hadoop/mapreduce/目录里
下面我们使用 hadoop 命令来试跑例子程序,看看运行效果 先看 MapReduce 程序求 pi 的程序:

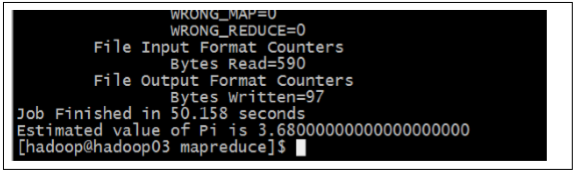

那除了这两个程序以外,还有没有官方提供的其他程序呢,还有就是它们的源码在哪里呢?
我们打开 mapreduce 的源码工程,里面有一个 hadoop-mapreduce-project 项目:

里面有一个例子程序的子项目:hadoop-mapreduce-examples
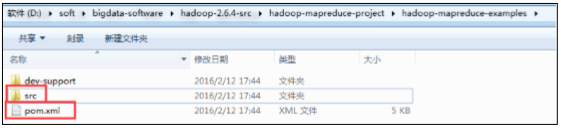
其中 src 是例子程序源码目录,pom.xml 是该项目的 maven 管理配置文件,我们打开该文件, 找到第 127 行,它告诉了我们例子程序的主程序入口:

找到该目录:

打开主入口程序,看源代码:
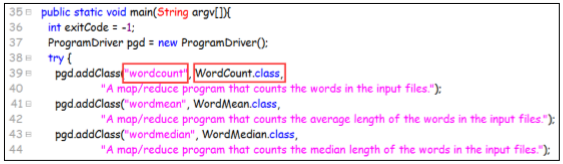
找到这一步,我们就能知道其实 wordcount 程序的实际程序就是 WordCount.class,这就是我 们想要找的例子程序的源码















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









