







1 查询类接口
一 mysql数据库查询超时问题
1 查询字段是否存在索引,索引是否失效
索引是个老生常谈的问题了, 需要特别注意下面几个点
唯一的值必须要建立唯一索引
比如订单号,售后单号,上门取件单号等必须要唯一的值,有助于数据准确
两个字段组成唯一的值必须要建立联合唯一索引
比如pps数据库表t_poroduct_supply 产品和商家供应商关系表, 正常来说supplier_id+product_id 肯定是唯一的值, 这里就要把这两个字段建立唯一索引, 避免产生脏数据, 查询效率也会变高, 需要注意一下联合索引的最左前缀, 只用product_id查询索引会失效的
同一个数据库下, 两张表同一个字段字符集不一样联查时索引会失效
这个问题曾经就遇到过,一张表是utf8格式, 另一张表是utf8mb4格式, 即使关联字段都是varchar类型, 索引也会失效
2 是否有分页?一次性返回数量是否过多导致堆内存溢出
问题描述:
在运费险白名单用户配置功能就遇到过这个问题,当时前端调用了两个接口, 一个是已分配用户列表, 一个是待分配用户列表(全部), 查询已分配用户列表时没有携带分页参数, 导致查询了全部已分配的用户数据(大概几十w条) , 直接后果就是pps服务器堆内存溢出,pps数据库cpu飙升 , 导致服务不可用
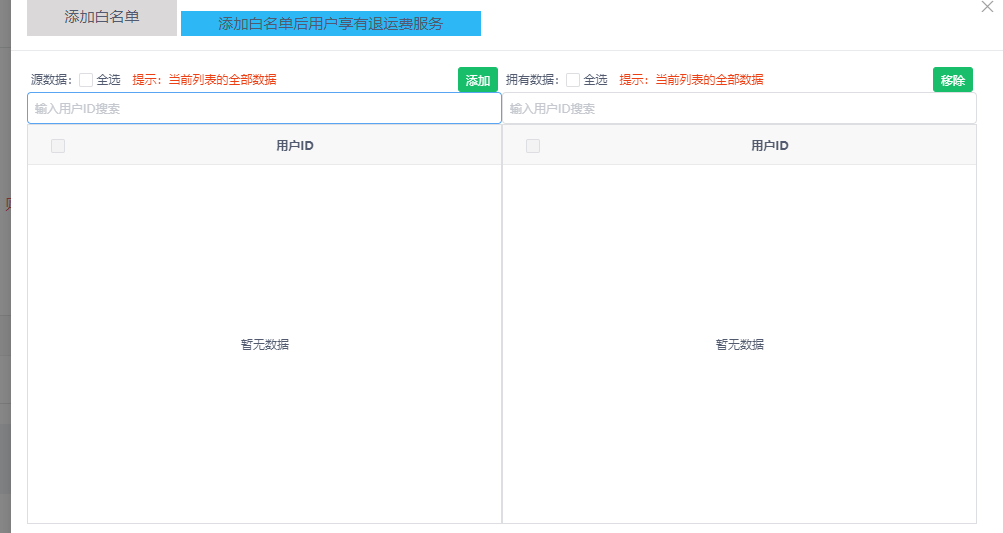
解决方案:
任何需要查询列表的接口, 必须都要使用分页, 前端可以采用默认查询第一页+ 支持精准搜索 方式展示,
拒绝一次性把所有列表数据拿到后在内存中做模糊匹配
3 数据库机器cpu是否正常?有没有可能其他慢SQL导致cpu飙升
这里主要看下执行时长, 平均返回行, 看是否存在执行时间过长,返回数据量过大的SQL产生, 具体页面在哪 怎样优化查询
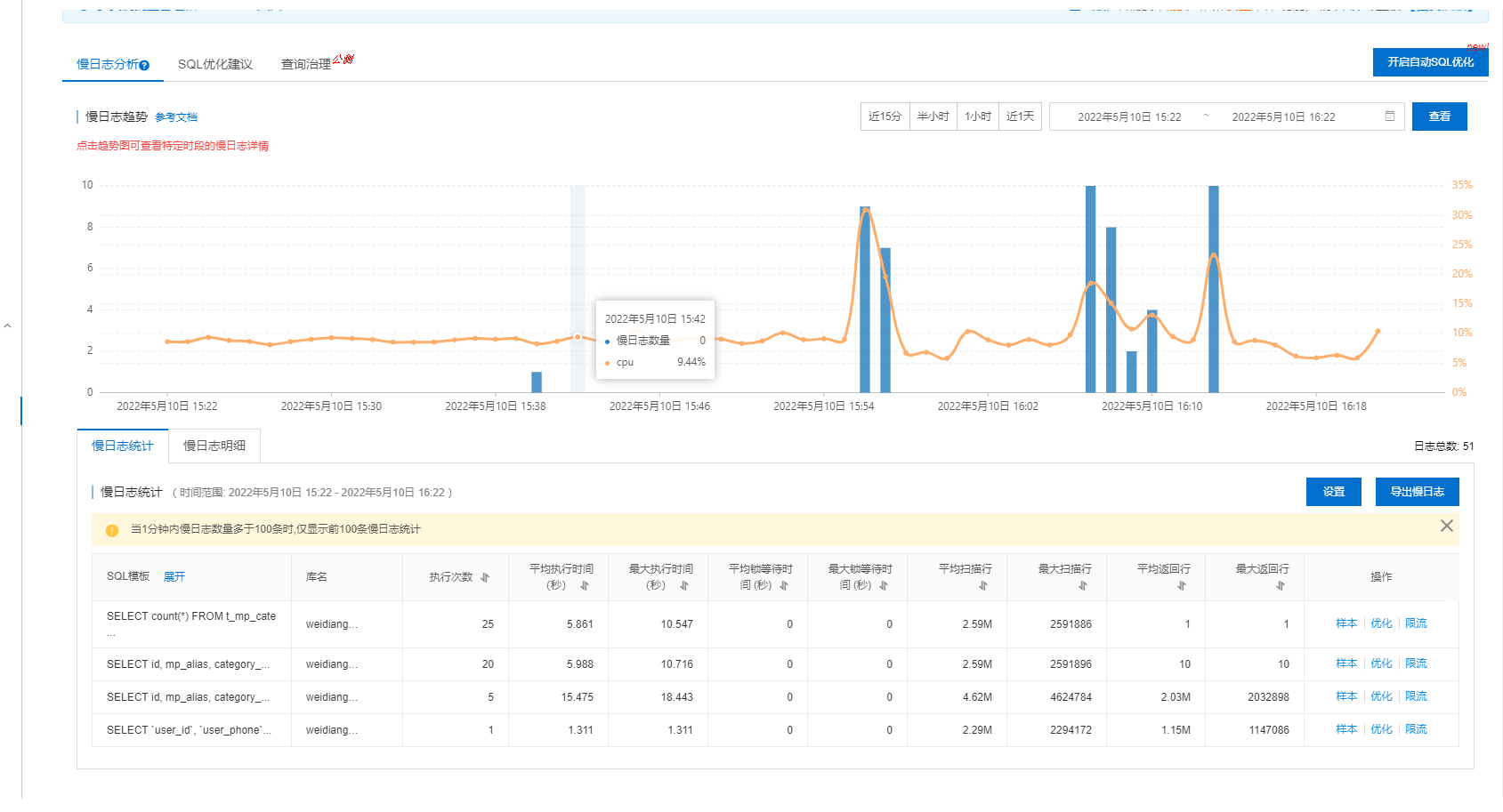
4 数据库数据量大,根据某一状态查询变慢,可以默认加时间只查询最近一段周期数据
这个问题在上门取件列表根据未支付状态搜索遇到过, 表格数据总数大概一百万条数据, 用支付状态搜索时会SQL查询超时, 支付状态只存在几个值,加索引也没什么意义, 只能采用减少查询总量的方式去优化这部分查询, 只查最近一个月的数据, 大概有几万条, 查询效率就很高了
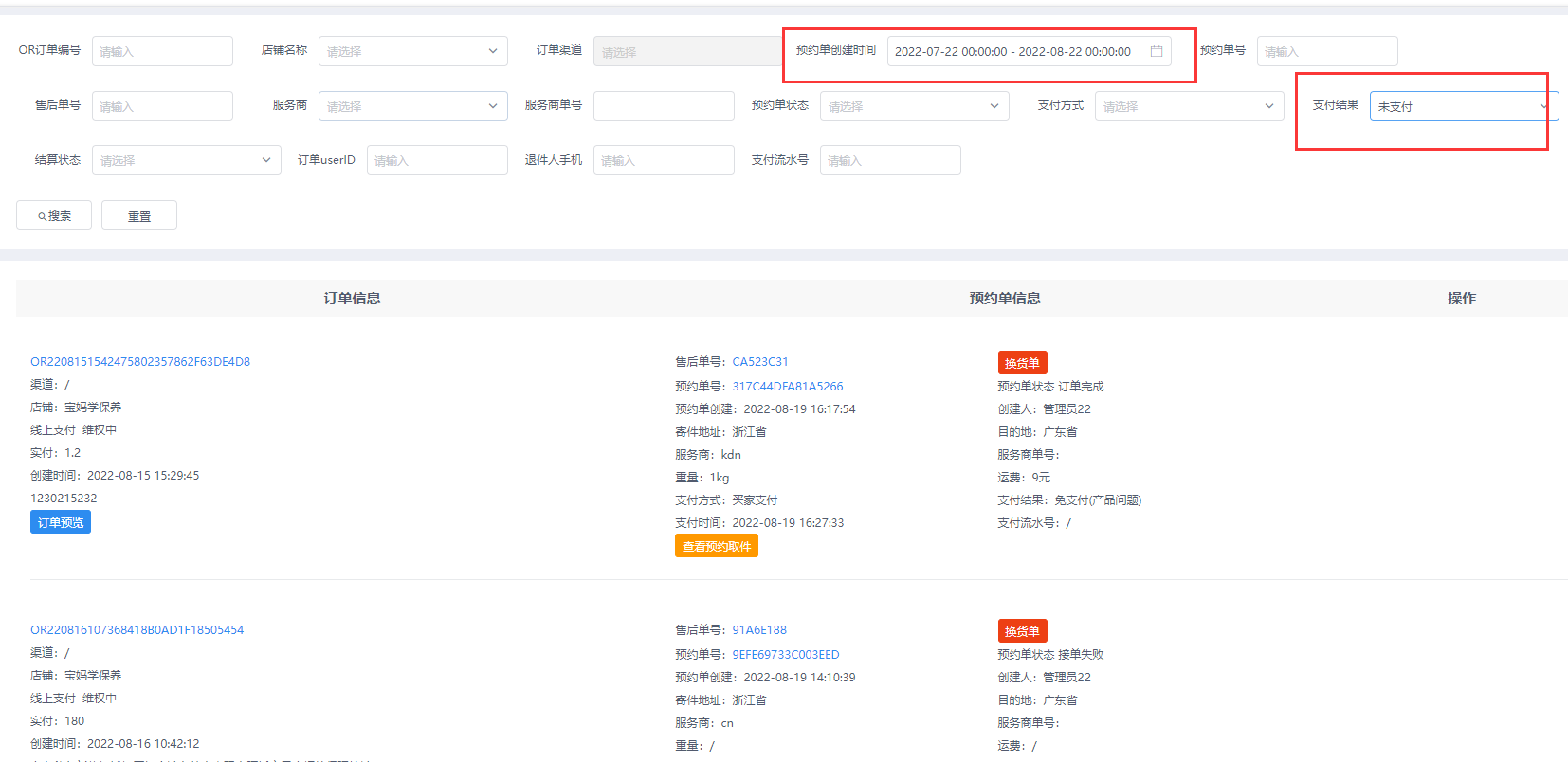
5 针对统计类数据,要是实时性不高,查询时间长,耗费cpu性能
缓存方案
在BMS系统首页有大量的统计数据, 这些统计数据查询的SQL一般在几百毫秒到几秒之间, ,因为这部分查询对实时性不高, 就加了接口切面级别的缓存, 避免存在相同条件的SQL短时间内重复请求数据库
统计表方案
针对于一些统计数据, 比如产品每日的维权率, 转化率等查询涉及到数据量很大时, 就可以将需要统计的数据存放在统计表中, 直接查询这张统计表就可以了
二 Redis超时问题
1 使用keys命令阻塞线程
因为redis是单线程执行的, 执行keys命令时底层是遍历所有的key匹配, 当一个库下面数据量很大时, 需要匹配的时间特别长, 而且会阻塞其他命令, 间接影响其他功能
问题代码:
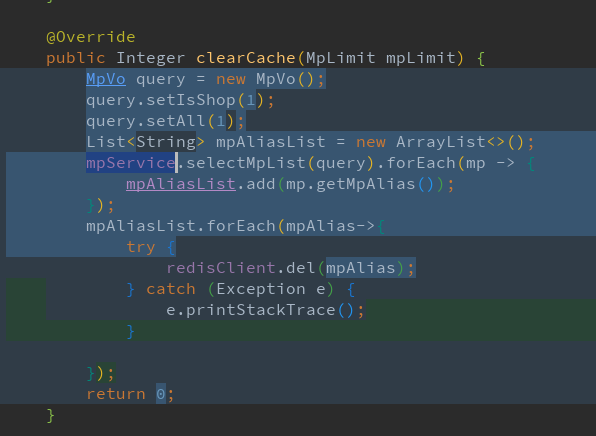
下面代码是更新了店铺选款列表的配置后, 清空对应所有店铺下的缓存, 这里使用了keys模糊查询导致线程阻塞
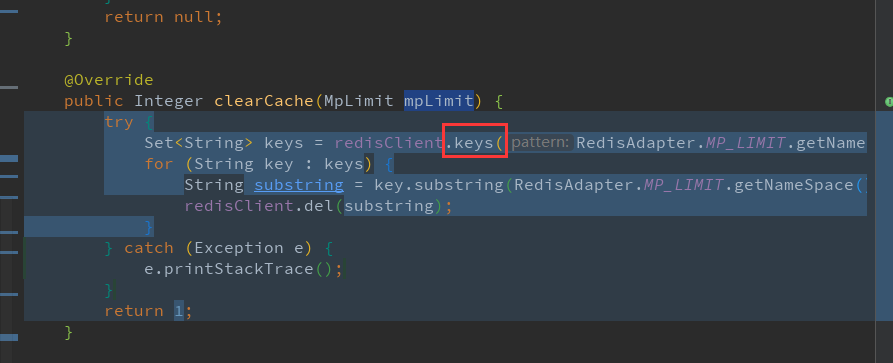
优化代码:
因为店铺数量本来就不多,最多也就10多个店铺, 索性全部查询出来循环删除
三 调用第三方接口查询超时问题
1 查询出的数据需要持久化
在使用上门取件功能时, 在调用下单接口会出现一定比例的接口超时, 超时原因是在调用第三方下单接口服务响应时长>5s, 成功响应后执行入库操作时, 因为超过了当前切面事务最大执行时间5s, 会抛出事务超时异常, 导致的问题是上门取件在服务商那边创建成功了, 但是在我们系统却找不到对应的订单, 后期用户也无法支付运费, 对平台造成一定的损失
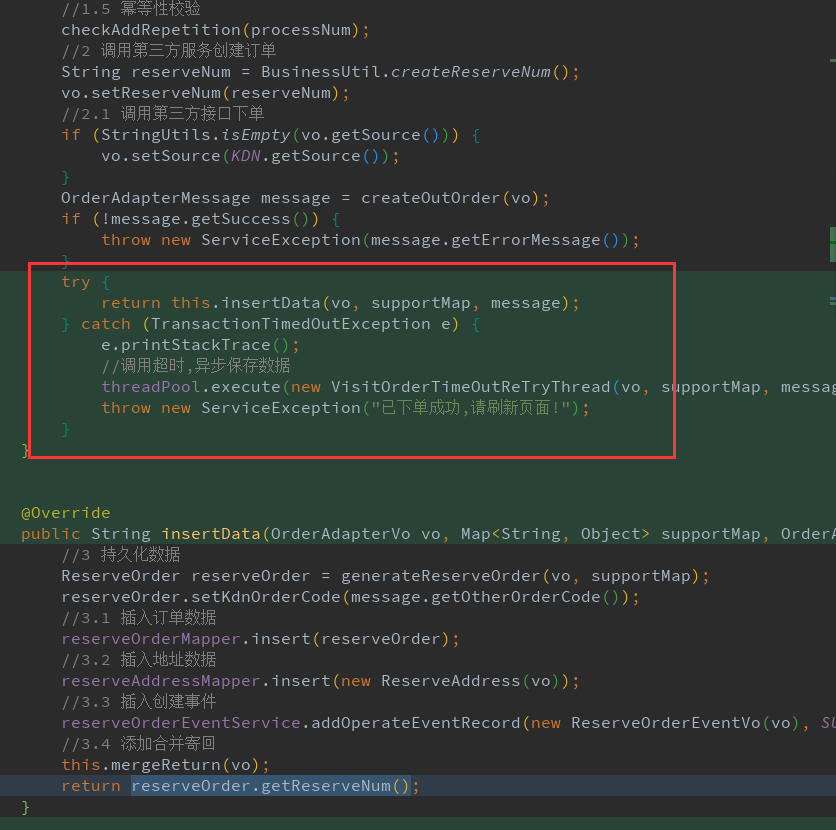
问题代码:
可以看到在执行操作数据库操作时, 并没有针对出现的异常做重试, 导致需要新增的数据没有落库

优化代码:
抽离出操作DB的方法insertData(), 在执行抛出事务超时异常时,会启动一个子线程重试调用insertData(), 后续提示用户"下单成功,刷新页面", 避免用户重复点击造成重复下单
2 查询出的数据不需要持久化
这种就是只针对于查询的需求了, 可能因为第三方接口不稳定导致接口响应慢, 在要求实时性不是很高时, 可以做一段时间的缓存, 减轻调用的qps
2 新增/更新类接口
1 批量操作代替循环操作
循环操作不管是DB还是OTS, 还有远程服务的调用, 每次循环都会产生的连接请求时间, 这都是一种资源的浪费, 优化方法就是请求数据在内存中整合好, 只调用一次持久化操作
2 大量数据分批操作
当需要新增或者更新几千条数据时, 一次性操作对数据库压力造成一定影响, 可以将需要操作的集合分片, 结合实际场景使用串行执行或者并行执行的方式
3 涉及复杂流程的单一操作可以并发执行
具体场景:
单独的新增业务复杂, 需要进行各种校验,不同状态执行不同流程, 这种情况下就不适合使用批量操作, 可以使用并发操作提高效率
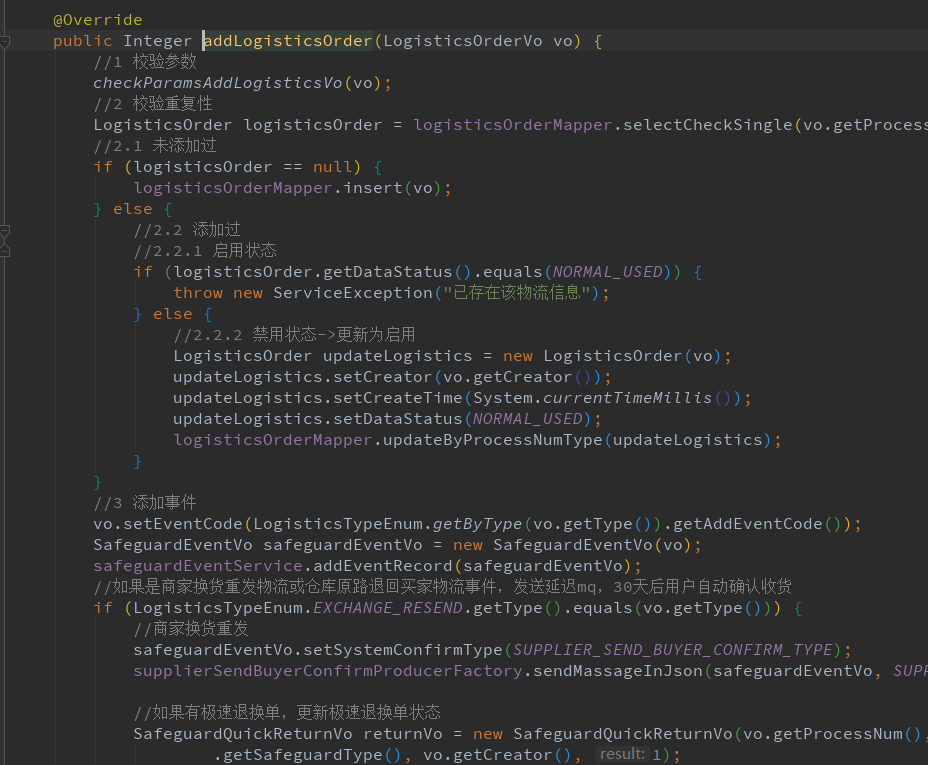
代码案例:
例如填写售后单物流方法,一个方法执行时长大概100ms左右, 要是批量填写几百个串行操作耗时过长
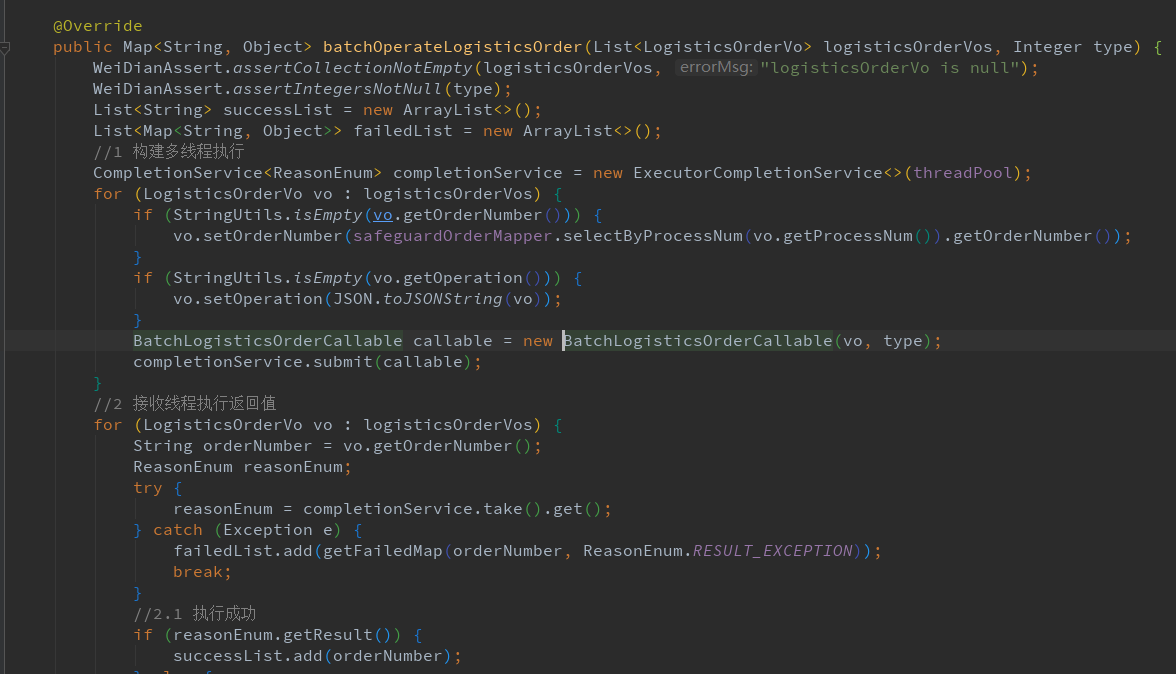
优化代码:
使用callback多线程执行方式, 并行操作填写物流流程,大大提升了串行执行的效率, 并且将修改成功失败结果标识响应给用户
3 调用远程接口响应超时
1 针对非核心逻辑可以使用异步方案处理降低总的接口调用时间
1 非核心逻辑 :
非核心逻辑可以理解为不需要和核心逻辑强绑定关系的逻辑, 可以不在一个事务里, 非核心逻辑的失败也不要影响核心逻辑的执行,
具体场景 :
1 例如下单扣减库存, 库存扣减(非核心逻辑)失败不要响应下单成功的结果
2 上门取件接单后给用户发送接单短信, 发短信(非核心逻辑)的失败不要影响取件单接单状态的变更
3 仓库收货错误商家原因处罚商家, 处罚商家(非核心逻辑)的失败不要影响仓库收货步骤
2 异步方案
消息队列:
消息队列是一种通知消息, 可以解除业务之间的耦合关系, 从接口调用的强耦合转为消息传递的松耦合, 上游不用关心下游成功与否, 都不影响主要流程执行, 一般作用在跨项目间业务的交互
案例1 : 下单扣减库存mq
下单时把对应的扣减库存参数传递个下游, 下游执行扣减库存逻辑, 不影响整个上游下单流程
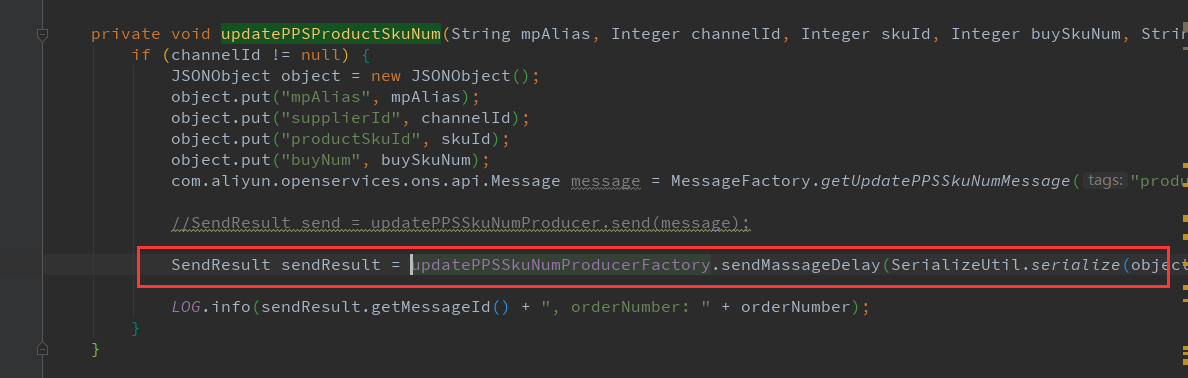
案例2 : 仓库收货错误生成处罚给商家
仓库收货后, 把生成处罚相关参数传递给处罚模块, 处罚模块根据通知执行新增处罚流程,处罚生成与否, 不影响仓库收货流程
子线程执行 :
子线程也是一种优化方法耗时的一种方法, 核心逻辑执行完成后, 直接给客户端响应回去, 后续流程可以启动子线程继续执行, 这种是针对于实时性要求不高, 可以提升接口响应效率的一种手段
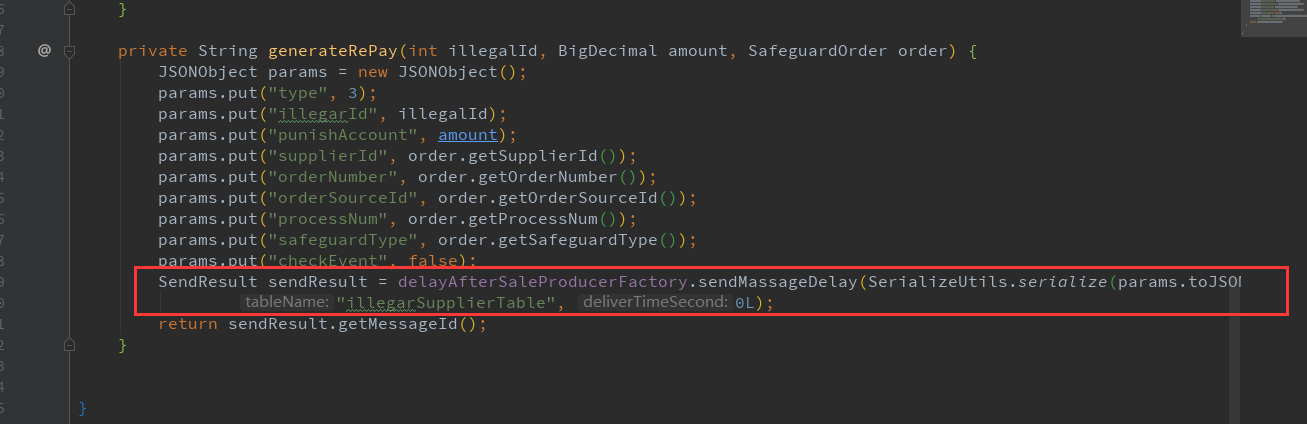
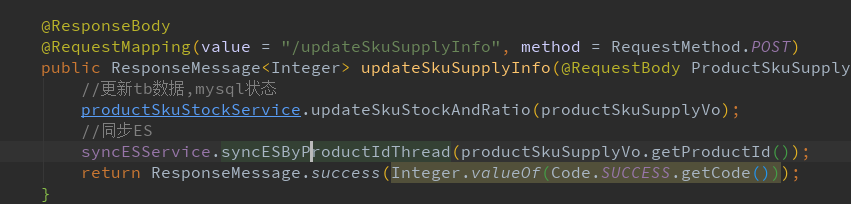
案例1 : 同步ES操作
更新库存接口中, 核心逻辑修改库存执行后, 启动一个子线程同步ES, 减少用户等待时间, 需要特别注意一下, 子线程内部一定要上报异常日志, 不然子线程内部报错后不能在loghub上看到
2 单独优化响应时长偏高的接口
有些接口业务很复杂, 调用了很多的远程调用, 偶尔就会不明原因的超时, 这时候可以去阿里云后台开一下接口整体执行时间, 看下到底是哪个接口执行耗时导致的
案例1 : 优化修改供货变更库存及库存状态逻辑
在整体调用链路中发现com.weidiango.pps.stock.impl.ProductSkuStockServiceImpl#batchAddSkuStockPlan接口时长占了总时长很大的比例, 在不影响整体业务流程的情况下, 保证这个接口入参,出参不变, 优化其中内部逻辑
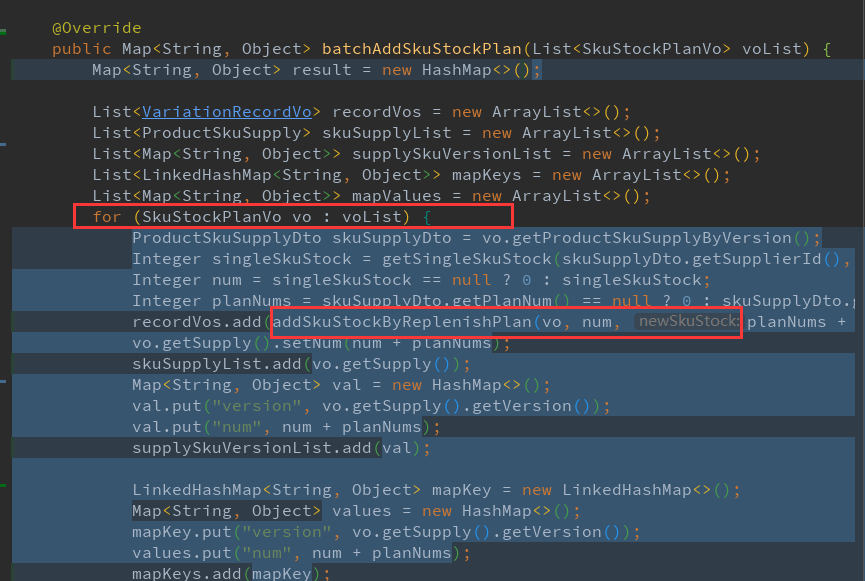
问题代码:
主要逻辑是for循环内串行执行添加补货计划核心逻辑(修改库存, 修改库存状态, 上报操作记录), 这个流程在sku量不大的情况下执行时间还可以接受, 当sku数量>100个时, 耗时会>5s 导致超时
优化代码:
采用callback多线程优化方式, 并行执行更新补货计划逻辑, 因为更新的sku都归属于一个产品, 把更新供货状态和上报操作记录放在外层, 保证只需要执行一次即可, 从原来100个sku时长6s左右 优化到1s左右

3 涉及到多次调用不同的远程服务,可以通过串行改并行的方式调用,统一获取返回值
具体场景:
比如在下单时,
需要用到用户地址信息, 需要远程调用用户地址信息, 产品信息,
需要远程调用产品详情快照保存起来, 优惠卷信息,
需要调用查询最终用户需支付金额 等一系列的接口,
在分布式项目下, 各个模快信息都需要远程调用查询, 一个接口就算100ms, 涉及到的接口多起来总体下单时长也是很长的
解决方案 :
可以使用callback线程模式并行查询, 统一接收返回值做后续流程处理
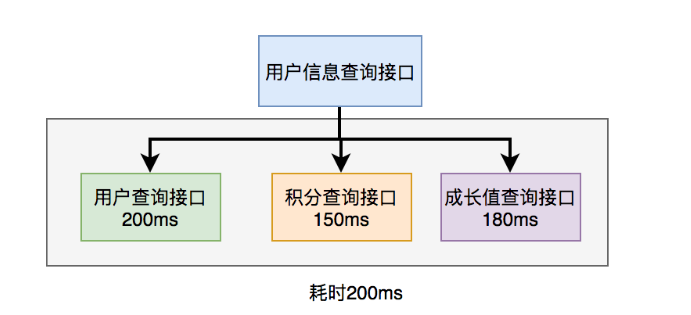
高并发下解决方案:
上面说到的用户信息查询接口需要调用用户查询接口、积分查询接口 和 成长值查询接口,然后汇总数据统一返回。
那么,我们能不能把数据冗余一下,把用户信息、积分和成长值的数据统一存储到一个地方,比如:redis,存的数据结构就是用户信息查询接口所需要的内容。然后通过用户id,直接从redis中查询数据出来,不就OK了?
如果在高并发的场景下,为了提升接口性能,远程接口调用大概率会被去掉,而改成保存冗余数据的数据异构方案。
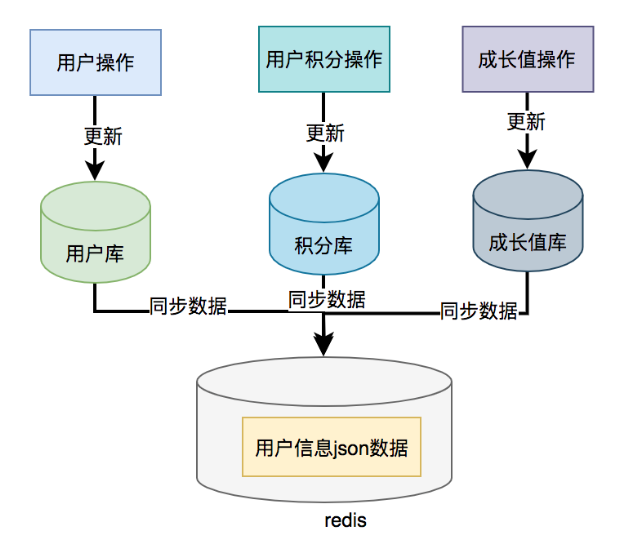
但需要注意的是,如果使用了数据异构方案,就可能会出现数据一致性问题。
用户信息、积分和成长值有更新的话,大部分情况下,会先更新到数据库,然后同步到redis。但这种跨库的操作,可能会导致两边数据不一致的情况产生。
4 避免在循环中调用远程方法,提供批量查询接口只调用一次
批量操作的这种思想不管是在前端调用后端接口, 后端远程接口调用, 操作DB, 操作OTS, 能使用批量执行尽量用批量执行, 除非接口层面不支持批量操作, 单针对于这种可以采用callback多线程方式优化
4 排查接口超时常用工具
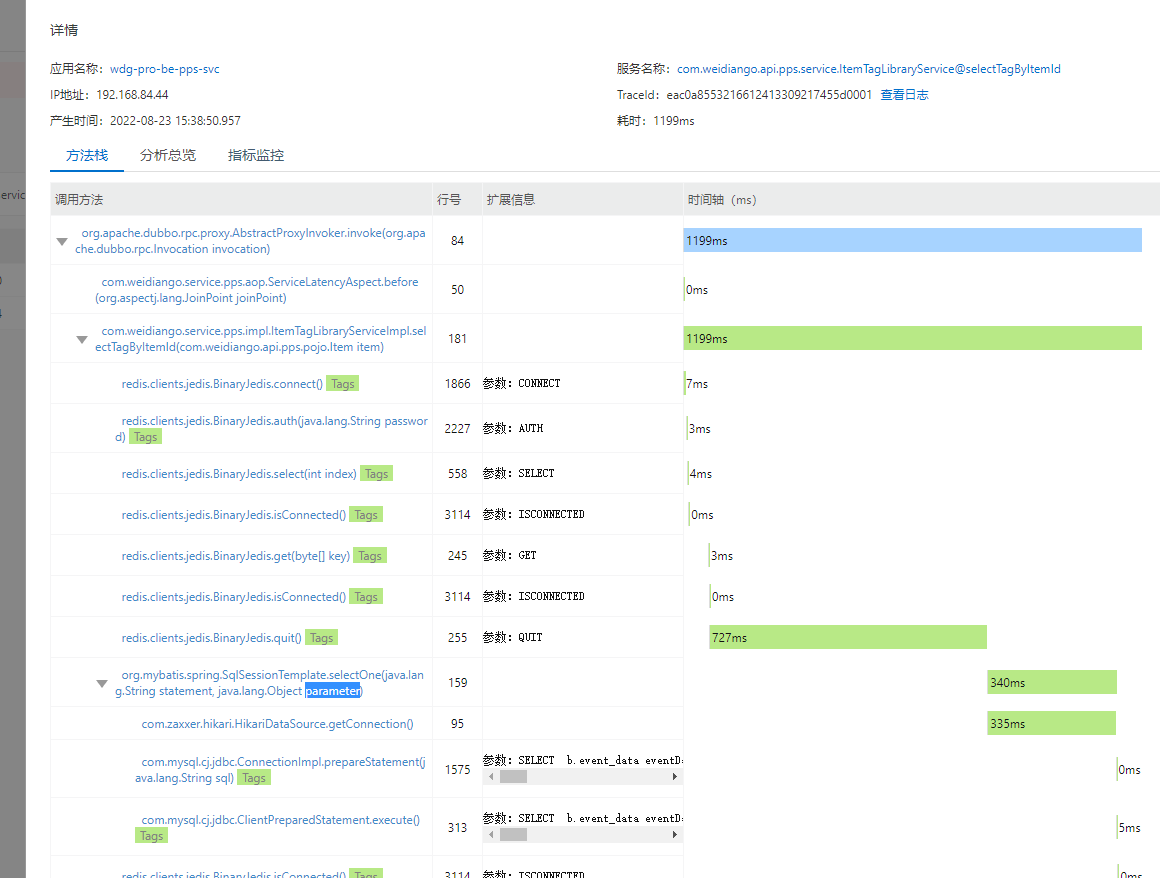
1 调用耗时剖析
一个接口超时, 先入为主的必然是这个接口的调用路径, 上下游调用链路, 每个链路执行耗时情况, 具体原因具体分析
以com.weidiango.api.pps.service.ItemTagLibraryService@selectTagByItemId接口为例可以看出该接口内部执行的耗时情况
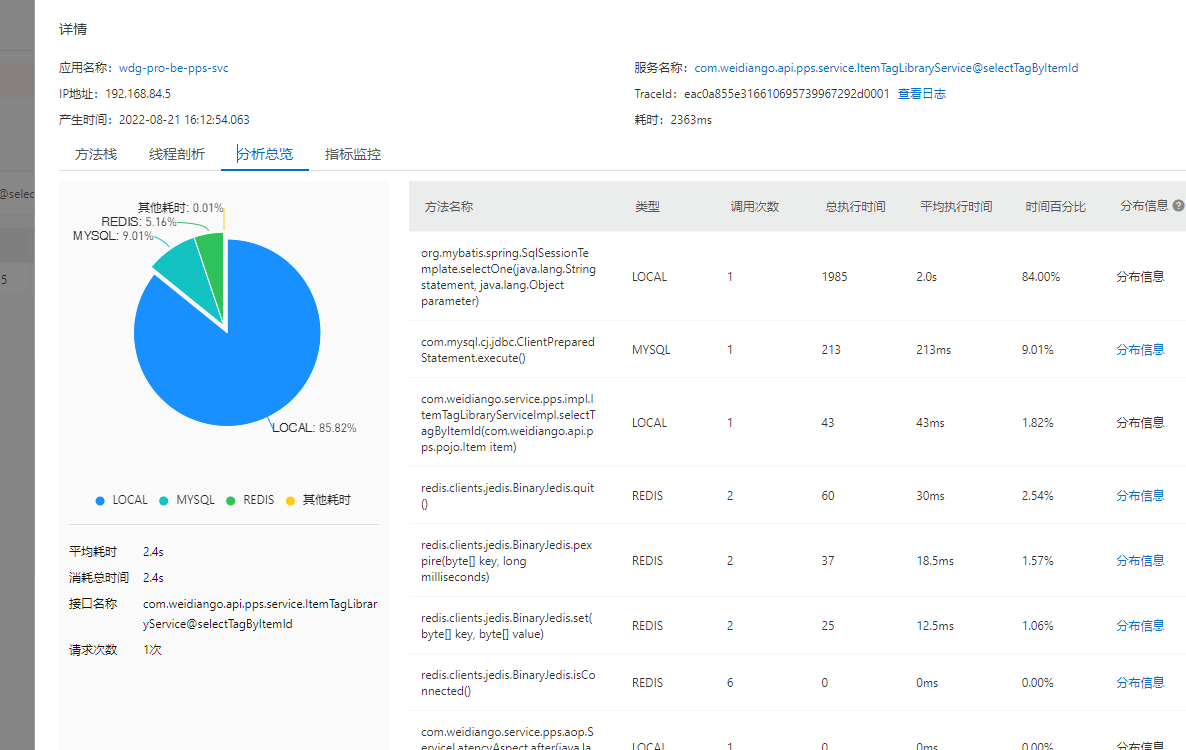
2 资源饼图分析
这里可以看出底层储存执行的耗时情况, 如果是mysql或者redis 耗时占比很大, 就要到对应的数据库下面看下数据库的cpu情况和慢SQL情况
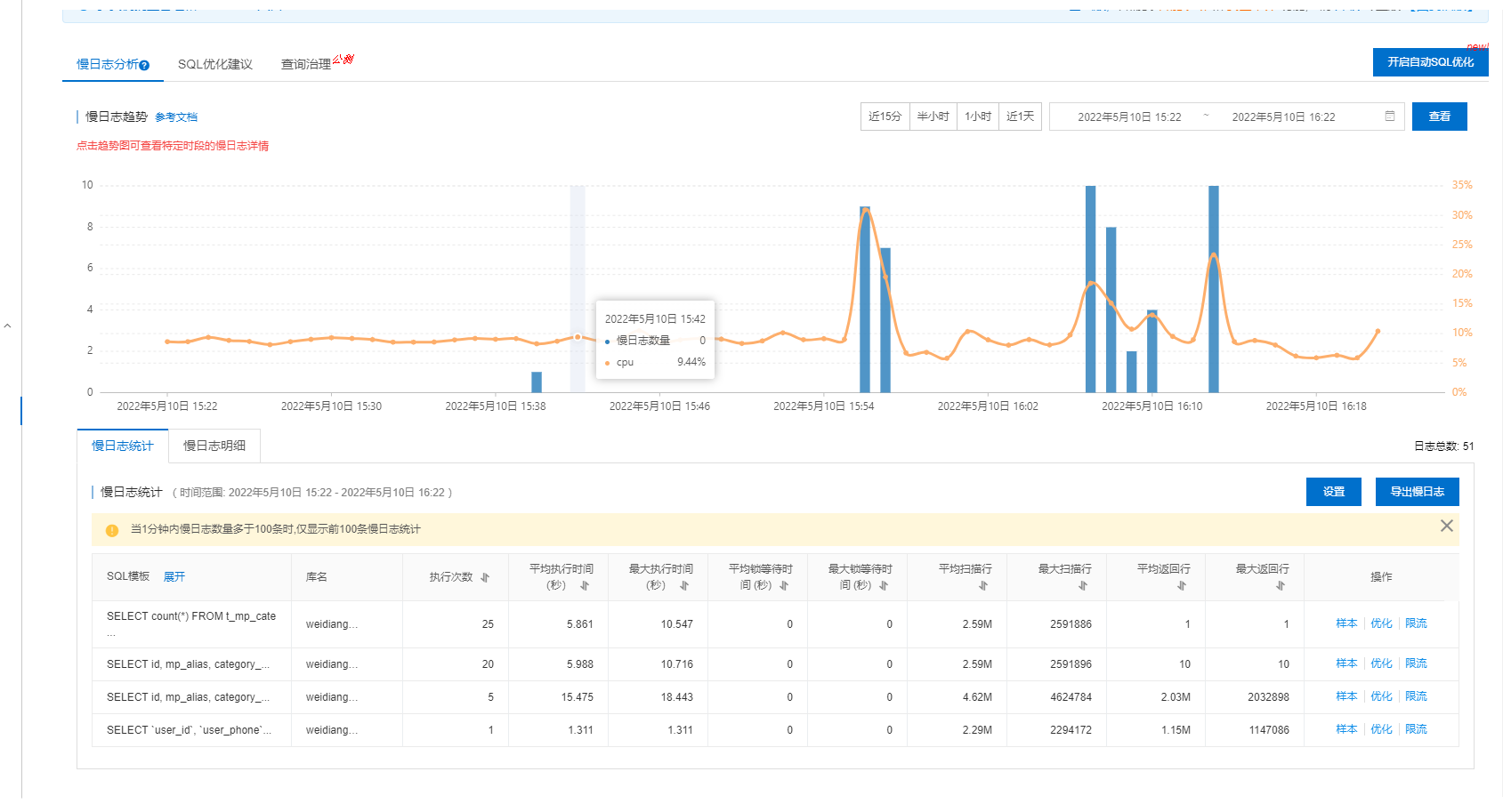
3 mysql实例的cpu和慢日志分析
主要关注在接口超时的时间范围内, 数据库cpu的波动和执行慢SQL的语句,
观察是因为超时接口的慢SQL导致cpu上升从而查询变慢,
还是其他的慢SQL执行导致cpu上升而影响了当前执行的接口耗时
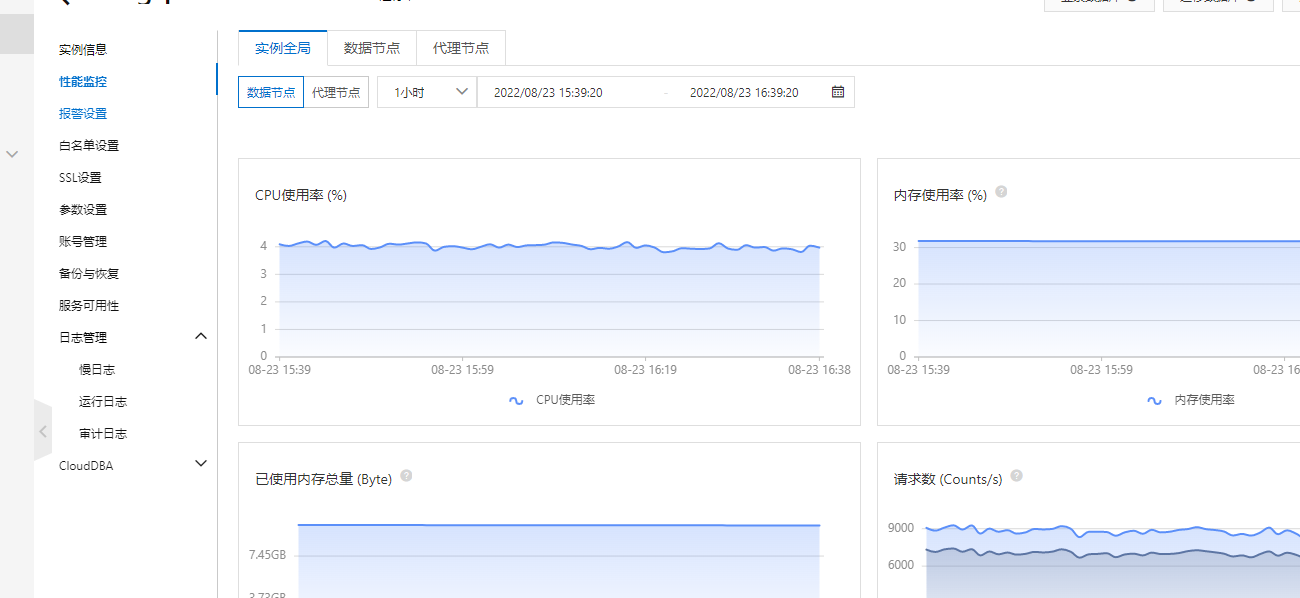
4 Redis实例的cpu和慢日志分析
当执行一条耗时的redis命令时(例如keys), 可以看到cpu会显著升高, 慢日志中也会打印出这条命令, 当前执行的方法会一直阻塞执行这条命令等待redis执行结束, 共享当前redis实例的其他请求会因为redis线程池满从而把请求拒绝掉, 影响其他操作redis的业务执行
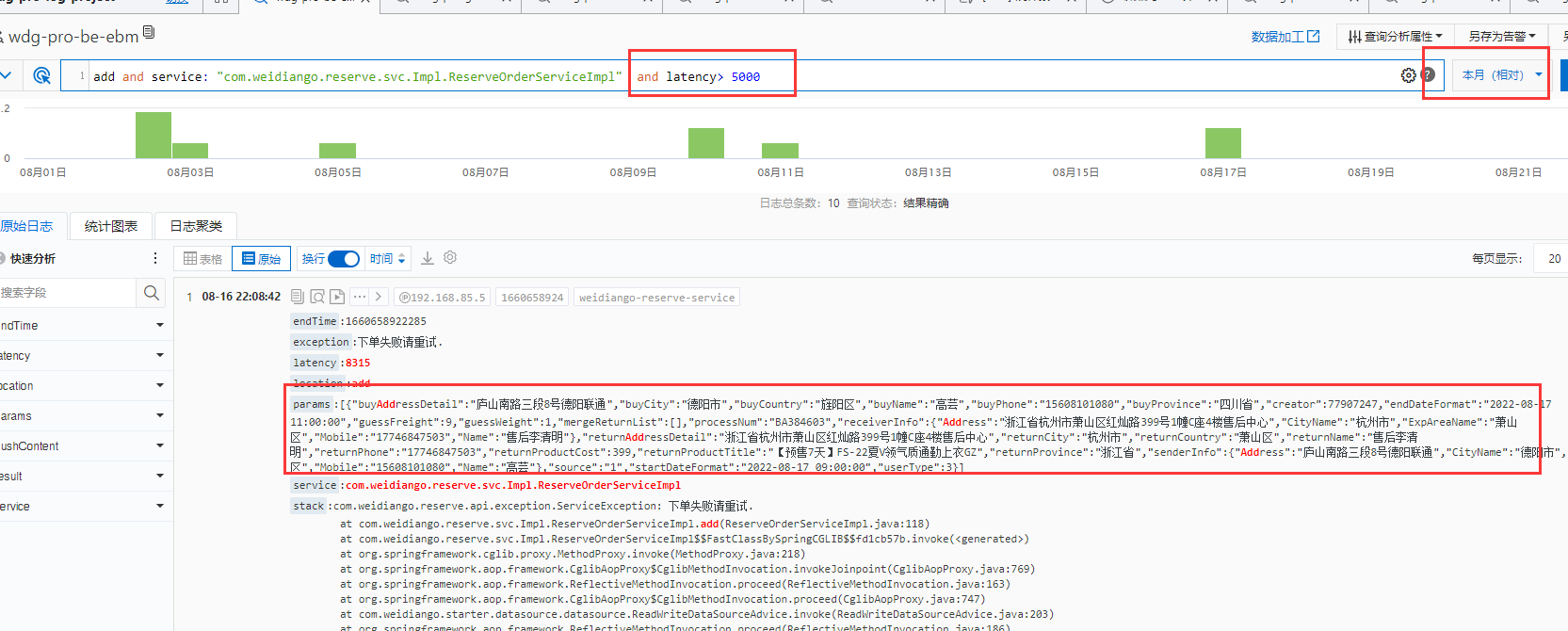
5 超时日志的比例与参数查看
可以通过loghub查询某个接口日志的总数与超时总数, 分析出大概的超时比例, 根据参数分析大概超时的原因
com.weidiango.reserve.svc.Impl.ReserveOrderServiceImpl#add 以这个接口为例














 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









