









设计文档的Excel转换为对象结构POJO-简式尺规工具箱
问题描述
在项目开发中我遇到了如下情况:
项目流程:设计 -> 写设计文档 -> 开发
在设计文档转换为对应代码的过程中我发现了问题,那就是
-
如果系统设计上下游
-
如果系统上下游交互使用
JSON -
那么把设计文档中的命名方式改为
Java的驼峰命名,然后再加上@JsonAlias,@JsonProperty等信息,手动粘贴复制效率有点低。
需求描述
可以把设计文档中的表格数据转换为对应的Java POJO,支持@JsonAlias,@JsonProperty,@JsonFormat(pattern = "yyyy-MM-dd", timezone = "GMT+8"),可以定制化,支持扩充。
效果演示
使用说明
使用python3环境
打开命令行,安装所需依赖
pip install -r .\requirement.txt
导入数据
剪贴板导入数据
- 把设计文档中的数据拷贝到临时excel中,再从excel中拷贝: ctrl + c【为了确保格式的统一,因为某些文档不是标准的excel,无法转换】
- 打开从剪贴板导入数据
# 从剪贴板读取数据
df = pandas.read_clipboard()
# 从excel读取数据
# df = pandas.read_excel('data.xlsx')
print(df)
保存为Excel,导入数据
- 把设计文档中的数据拷贝到excel中,保存excel到当前项目路径下
- 打开从excel导入数据
- 输入文件路径
# 从剪贴板读取数据
# df = pandas.read_clipboard()
# 从excel读取数据
df = pandas.read_excel('文件路径.xlsx')
print(df)
指定类名和索引列
# 类名,无需带.java后缀
class_name = 'Tmp'
field_index_config = {
# 字段名 在excel中列的索引,从0开始计数
'field_name_index': 0,
# 字段类型 在excel中列的索引,从0开始计数
'field_type_index': 1,
# 字段注释 在excel中的列索引,从0开始计数
"field_mean_index": 4
}
指定是否过滤指定前缀,如去除字段前面的 .或者+号
"""
2. 过滤数据名称前缀,
比如表格的数据都是
data.nodes[].data.id
data.nodes[].data.name
我想去掉前缀 data.nodes[].data.
只保留 id name
那么可以在这里配置
"""
for field_data in field_data_list:
if CommonUtil.is_none_or_nan(field_data['field_name']):
continue
field_data['field_name'] = field_data['field_name'].removeprefix("+")
field_data['field_name'] = field_data['field_name'].removeprefix("")
配置作者名、开启注解信息等
"""
4. 配置元信息
目前可以配置的都在下面列出了
"""
config_metadata = {
# 当前作者名称
'author': '尺规kit',
# 文件编写日期,默认今天
'date': datetime.date.today().isoformat(),
# jackson
'jackson': {
'enable': True,
'alias.enable': True,
'property.enable': True,
'dateformat.enable': True
}
}
执行即可
示例数据
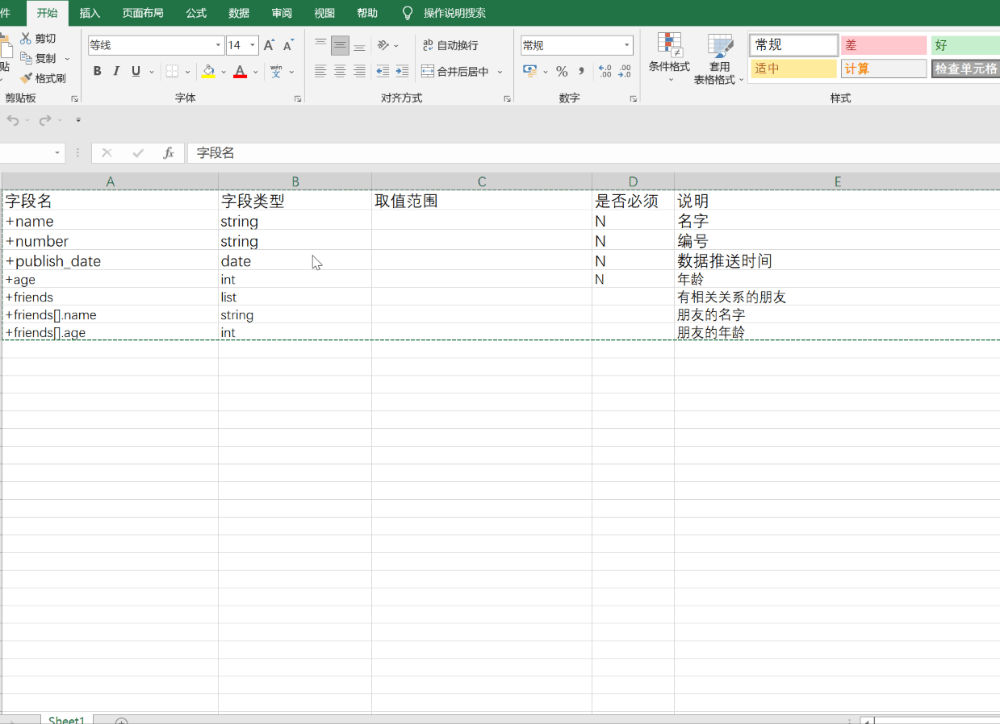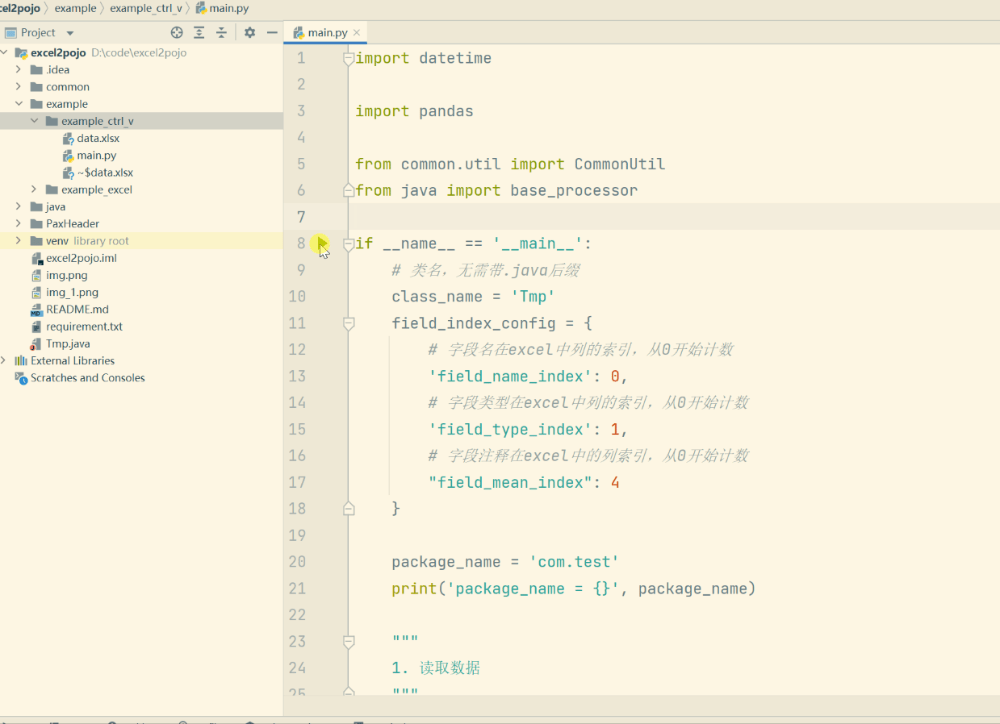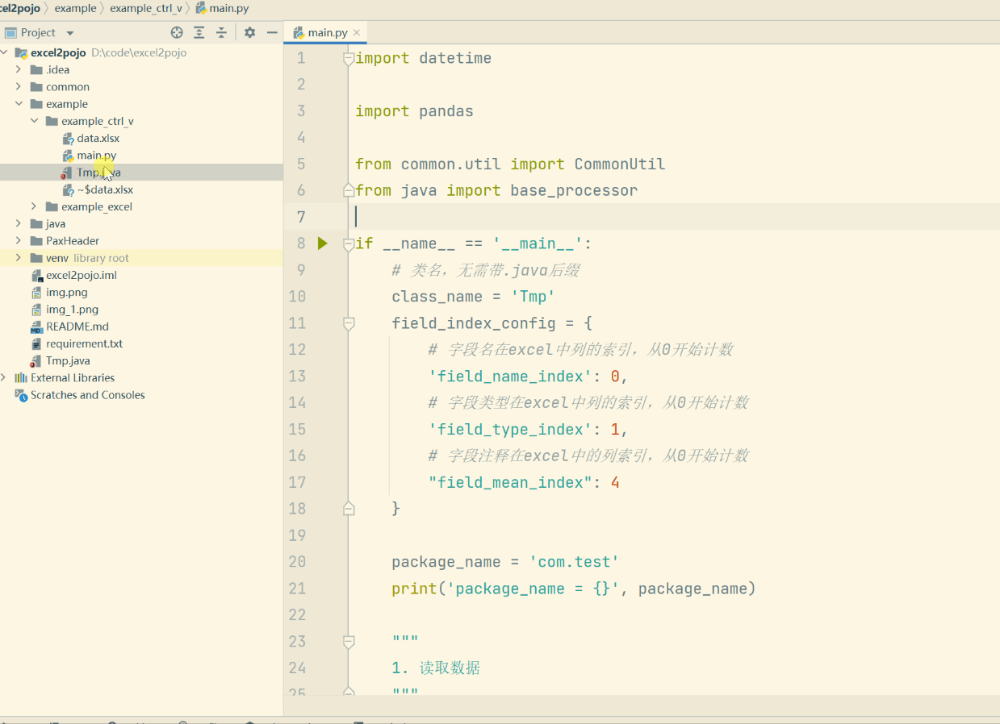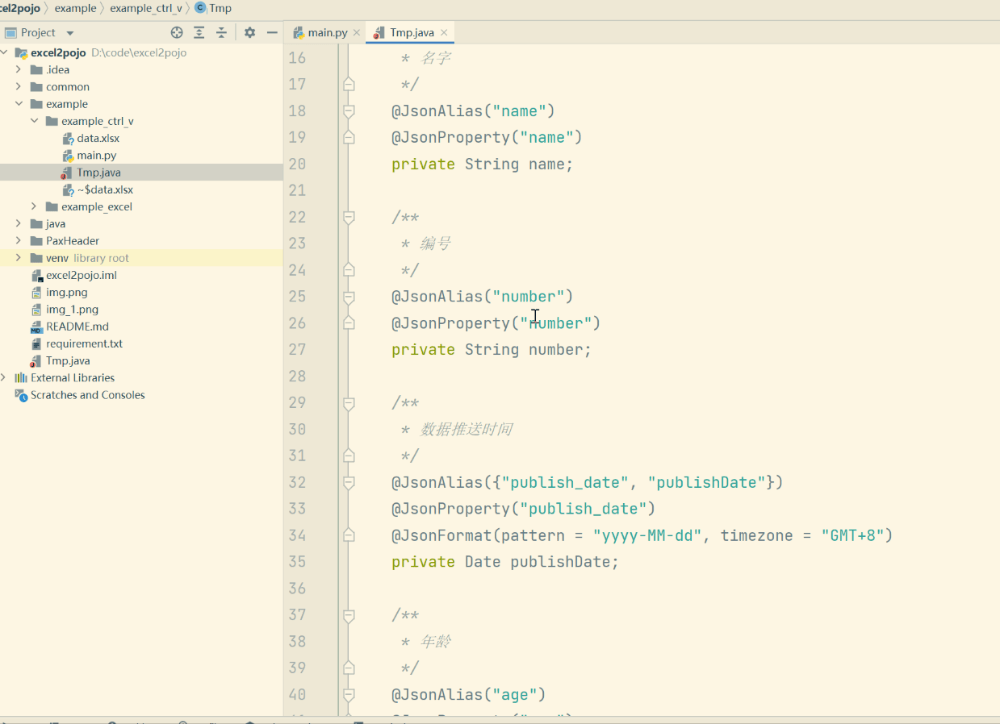
| 字段名 | 字段类型 | 取值范围 | 是否必须 | 说明 |
|---|---|---|---|---|
| data_id | str | Y | 数据id | |
| operation_type | string | ADD DELETE | Y | 操作类型 新增 删除 |
| original | 被操作数据信息 | |||
| +id | string | Y | 被操作数据id | |
| +type | string | PERSON ANIMAL | 数据的类型 PERSON-人 ANIMAL-动物 | |
| +name | string | N | 名字 | |
| +number | string | N | 编号 | |
| +publish_date | date | N | 数据推送时间 | |
| +age | int | N | 年龄 |
生成的Java类
package com.test;
import lombok.Data;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.annotation.JsonAlias;
/**
* @author 尺规kit
* @date 2022-07-14
*/
@Data
public class Tmp {
/**
* 数据id
*/
@JsonAlias({"data_id", "dataId"})
@JsonProperty("data_id")
private String dataId;
/**
* 操作类型
新增
删除
*/
@JsonAlias({"operation_type", "operationType"})
@JsonProperty("operation_type")
private String operationType;
/**
* 被操作数据信息
*/
@JsonAlias("original")
@JsonProperty("original")
private Object original;
/**
* 被操作数据id
*/
@JsonAlias("id")
@JsonProperty("id")
private String id;
/**
* 数据的类型
*/
@JsonAlias("type")
@JsonProperty("type")
private String type;
/**
* 名字
*/
@JsonAlias("name")
@JsonProperty("name")
private String name;
/**
* 编号
*/
@JsonAlias("number")
@JsonProperty("number")
private String number;
/**
* 数据推送时间
*/
@JsonAlias({"publish_date", "publishDate"})
@JsonProperty("publish_date")
@JsonFormat(pattern = "yyyy-MM-dd", timezone = "GMT+8")
private Date publishDate;
/**
* 年龄
*/
@JsonAlias("age")
@JsonProperty("age")
private Integer age;
}
目前已经支持的情况
// 字段名
person_name -> personName
age -> age
// 字段类型
str, string, String -> String
date, Date -> Date
List, list, arr, array, Array -> List
int, integer -> Integer
float -> Float
double -> Double
无 -> Object
结构描述
common/ - 公共的类
processor/ - 处理器
field_info_processor/ 字段信息处理器
field_info_reader/ 从dataframe中读取数据
generator/ 文件生成器
standardized/ 字段名称标准化器
processor/ 处理器
name/ 字段名称标准化
type/ 字段类型标准化
StandarderManager.py 标准化管理器
util/ 工具类
example/ 示例
java/ java工程
field/annotation/ 字段上面的注解
generator/ 根据class_name和字段信息生成类和字段信息
base_processor.py 基本处理通用类
流程描述
















 2827
2827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









