






爬虫案例:股吧,使用Selenium
实用工具关注公众号爬虫探索者获取。
发送对应关键词:
1.运行环境
pip install selenium==4.9.1
pip install pymysql
1.1.高版本Chrome问题
1.2.最终效果

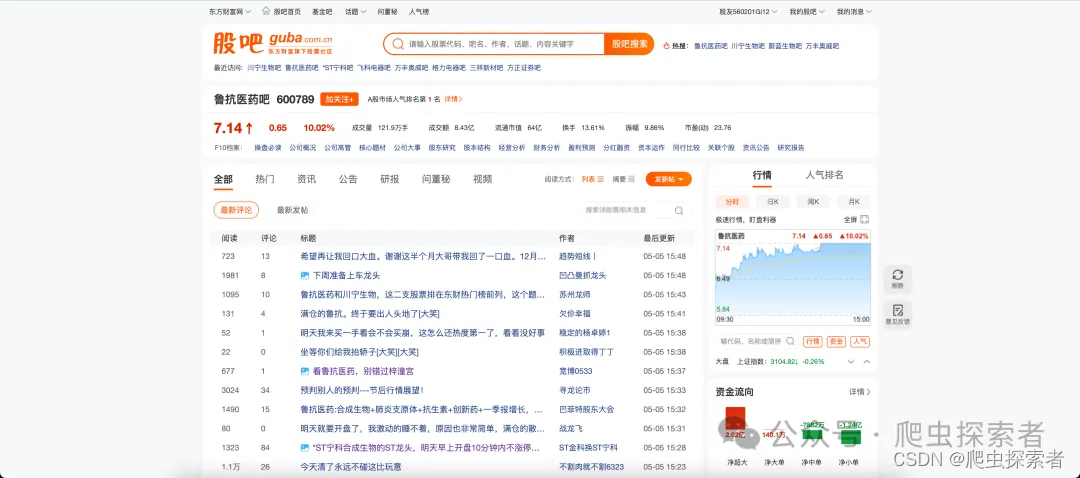
2.目标网站
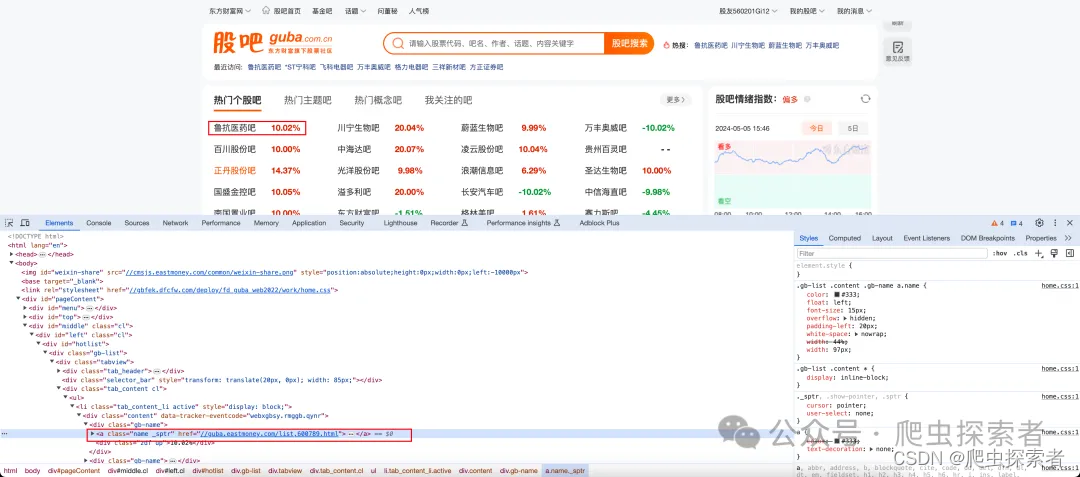
3.参数介绍
BASE_URL = 'https://guba.eastmoney.com/list,600789_{page}.html'
# page:当前页码
# 600789:股票代码
来源
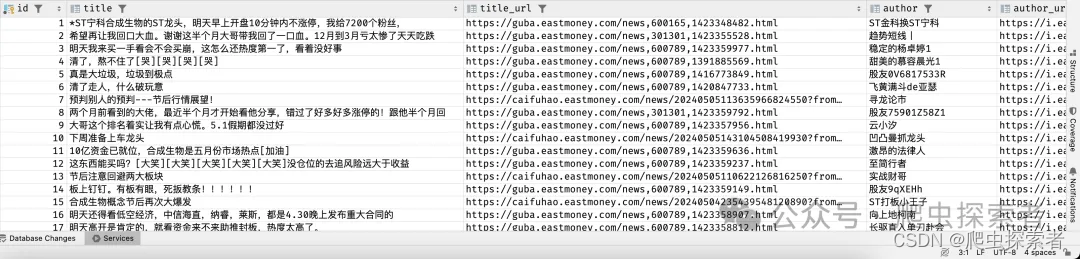
4.获取的信息
title = item.find_element(by=By.CSS_SELECTOR, value='td .title a').text # 标题
title_href = item.find_element(by=By.CSS_SELECTOR, value='td .title a').get_attribute('href') # 对应标题的地址
author = item.find_element(by=By.CSS_SELECTOR, value='td .author a').text # 作者
author_url = item.find_element(by=By.CSS_SELECTOR, value='td .author a').get_attribute('href') # 作者主页地址
read_count = item.find_element(by=By.CSS_SELECTOR, value='td .read').text # 阅读数量
reply_count = item.find_element(by=By.CSS_SELECTOR, value='td .reply').text # 评论数量
update_time = item.find_element(by=By.CSS_SELECTOR, value='td .update').text
5.完整内容
import logging
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, timeout=10)
BASE_URL = 'https://guba.eastmoney.com/list,600789_{page}.html'
db = pymysql.connect(host='localhost', user='root', password='<PASSWORD>', database='<DATABASE>', port=3306)
def get_info(url):
logging.info('获取的URL: %s', url)
browser.get(url)
wait.until(ec.visibility_of_all_elements_located((By.CSS_SELECTOR, '.listbody')))
items = browser.find_elements(by=By.CSS_SELECTOR, value='.listitem ')
for item in items:
title = item.find_element(by=By.CSS_SELECTOR, value='td .title a').text # 标题
logging.info('解析的当前信息:%s', title)
title_href = item.find_element(by=By.CSS_SELECTOR, value='td .title a').get_attribute('href') # 对应标题的地址
author = item.find_element(by=By.CSS_SELECTOR, value='td .author a').text # 作者
author_url = item.find_element(by=By.CSS_SELECTOR, value='td .author a').get_attribute('href') # 作者主页地址
read_count = item.find_element(by=By.CSS_SELECTOR, value='td .read').text # 阅读数量
reply_count = item.find_element(by=By.CSS_SELECTOR, value='td .reply').text # 评论数量
update_time = item.find_element(by=By.CSS_SELECTOR, value='td .update').text
save_info(0, title, title_href, author, author_url, read_count, reply_count, update_time)
def save_info(*args):
"""
保存信息
:param args:
id: 默认0,自增列
title
title_href
author
author_url
read_count
reply_count
update_time
:return:
"""
with db.cursor() as cursor:
sql = """
insert into guba_comments values (%s, %s, %s, %s, %s, %s, %s, %s)
"""
title = args[1]
try:
cursor.execute(sql, args)
logging.info('数据插入成功 %s', title)
db.commit()
except Exception as e:
logging.error('数据插入失败 %s', title)
db.rollback()
def create_table():
sql = """
create table if not exists guba_comments (
id int primary key auto_increment,
title varchar(400),
title_url varchar(400),
author varchar(400),
author_url varchar(400),
read_count int,
reply_count int,
update_time varchar(100)
)
"""
with db.cursor() as cursor:
try:
cursor.execute(sql)
logging.info('创建表成功!guba_comments')
except Exception:
logging.error('创建表失败!', exc_info=True)
def main():
create_table()
for page in range(1, 51):
get_info(url=BASE_URL.format(page=page))
db.close()
if __name__ == '__main__':
main()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











