







第四期:神经网络如何得到精准的预测?:
进行精准预测的方法:
我们知道要判断模型预测的值是否准确,就是要让下图中的dz更接近0。

也就是说,预测值与实际值直接的误差越小,预测的结果就越准确。所以我们为了使人工神经网络模型预测的值接近实际值。我们可以用到如下的一些方法:
1.最简单的就是方差计算法:

此数值越小,代表整体来讲,预测值更准确。
2.不过在人工智能神经网络中,我们最常使用的方法是信息熵:

一条信息的信息量的多少与其不确定性有着直接的关系。比如说,我们要搞清楚一件非常不确定的事,或者我们一无所知的事就需要大量的信息。相反,我们对已知事物有较多了解,则不需要太多的信息就能把它搞清楚。从这个角度来说,信息量就等于不确定的多少。
不确定性跟事情可能结果的数量以及不同结果的概率分布两个因素有关。
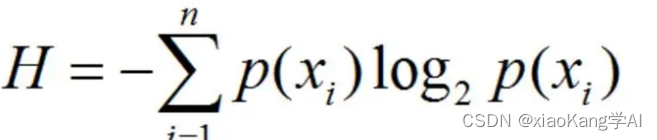
1)不同结果的概率相等
熵的统计学定义是所有可能结果的数量取对数,即信息熵H=logW。
- 不同结果的概率不等
除了可能的结果数量,还要看初始的概率分布(概率密度函数)。例如一开始我就知道小明在电影院的有15*15个座位的A厅看电影。小明可以坐的位置有225个,可能结果数量算多了。可是假如我们一开始就知道小明坐在第一排的最左边的可能是99%,坐其它位置的可能性微乎其微,那么在大多数情况下,你再告诉我小明的什么信息也没有多大用,因为我们几乎确定小明坐第一排的最左边了(摘自知乎)。
更准确的信息量的定义由香农提出。信息熵H=E(-logpi)=-(p1logp1+p2logp2+…+pn*logpn),其中p1,p2,pn分别代表不同结果对应的概率大小。利用上式可以推导出当不同结果的出现概率相等时的特殊结果。

数学上,信息熵其实是信息量的期望。
在研究神经网络模型对结果预测是否准确的过程中,如果信息熵越小,也就意味着,不确定性越小,事物越接近真相,也就是说,更加准确了。
我们这里讲解一种熵增益的变体表达形式:交叉熵。
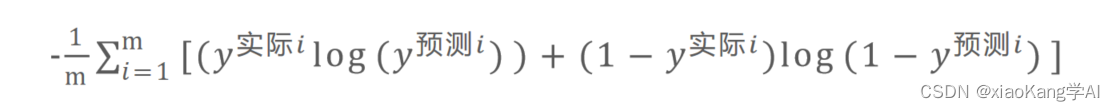
这个交叉熵的值越小,那么说明我们模型的预测值就越精确。
在之后的学习中。
小康会记录,如何使用上述方法来进行相关人工智能应用的实战操作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











