







文章目录
简介
moviepy官方中文API
spleeter官方github
本文视频降噪原理为使用spleeter提取出人声,仅将人声写回视频并保存。
对于AudioClip和VideoClip使用完要close()来释放资源
VideoFileClip构建时最好指定fps_source=‘fps’(平均帧率),默认为tbr(帧率)
一次运行对多个视频进行降噪时,不要把Separator(‘spleeter:2stems’)放到频繁调用的函数里,否则可能因为频繁创建Separator(‘spleeter:2stems’)对象而卡死(可以放进__main__函数或使用单例模式等)
所有可能用到的文件同时放在百度网盘:
链接:https://pan.baidu.com/s/1jyKsR65QI7dpo9NIObGlhA?pwd=xyvk
提取码:xyvk
安装spleeter
# 创建虚拟环境【可选】
conda create -n sp python=3.7
# 激活虚拟环境【可选】
conda activate sp
# 在gpu上运行需要下列二者之一:
# 1) 执行代码conda install cudatoolkit=10.1 cudnn=7.6.5
# 2) 在本地安装CUDA10.1+cuDNN7.6.5(参考https://blog.csdn.net/qq_42283621/article/details/124095937)
# 否则将在cpu上运行
pip install moviepy==1.0.3
pip install spleeter-gpu==2.0.2
conda install ffmpeg==4.2.2
# 测试
# 在百度网盘下载audio_example.mp3,然后cd到其所占目录,例如:
cd C:\Users\shang\Desktop
# 命令spleeter separate [OPTIONS] -i INPUTS...
# 这里使用[OPTIONS] -p <预训练参数文件名> -o <输出路径>
# 第一次执行会在当前目录新建pretrained_models/2stems文件夹并下载4个预训练文件,若下载慢或网络错误可在百度网盘下载2stems.tar.gz将其中的4个文件复制到pretrained_models/2stems文件夹
spleeter separate -p spleeter:2stems -o . -i audio_example.mp3
# 若在<输出路径>下出现名为audio_example的文件夹(该名即为输入文件名),audio_example文件夹下包含vocals.wav(人声)和accompaniment.wav(背景声)则测试成功。
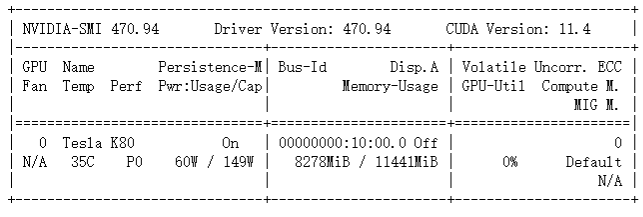
# 若使用了gpu则在下面的两个图中可以看到显存占用,否则显存占用保持在0。
windows: 任务管理器 -> 性能 -> GPU1

linux: 命令nvidia-smi
代码执行
在当前目录下放置1.mp4、2.mp4、audio_example.mp3(均在百度网盘)以及pretrained_models/2stems/4个预训练文件(网络不佳或运行失败时,否则第一次执行下列代码将自动下载pretrained_models/2stems/4个预训练文件)
若输出结果第一行为“Successfully opened dynamic library cudart64_101.dll”则说明使用了GPU,若“Could not load dynamic library 'cudart64_110.dll'”则说明使用了CPU。
from moviepy.editor import *
from moviepy.audio.AudioClip import AudioArrayClip
from spleeter.separator import Separator
def audioNoiseReduction(audio, separator):
"""
音频降噪(去除背景声保留人声)
注:AudioClip包含AudioFileClip和AudioArrayClip两个子类
:param audio: AudioClip或其子类对象
:param separator: 人声分离器对象
:return: AudioClip或其子类对象
"""
audiodata = audio.to_soundarray(fps=44100)
prediction = separator.separate(audiodata)
# 保存人声(其中fps 44100需和获取时一样,AudioFileClip('audio_example.wav')采用了缺省的默认fps 44100)
vocals = AudioArrayClip(prediction['vocals'], 44100)
return vocals
def videoNoiseReduction(video, separator):
"""
视频降噪(去除背景声保留人声)
注:VideoClip包含VideoFileClip和DataVideoClip两个子类
:param video: VideoClip或其子类对象
:param separator: 人声分离器对象
:return: VideoClip或其子类对象
"""
audio = audioNoiseReduction(video.audio, separator)
video_no = video.without_audio()
video_red = video_no.set_audio(audio)
audio.close()
video_no.close()
return video_red
def splitAndMergeVideo(pathList, savePath, timeList, separator, noiseReduction=False):
"""
截取&合并视频片段&视频降噪
调用示例:
splitAndMergeVideo('1.mp4', 'smv1.mp4', '00:05-00:17')
splitAndMergeVideo(['1.mp4', '1.mp4'], 'smv2.mp4', ['00:05-00:17', '00:00-00:10'], noiseReduction=True)
splitAndMergeVideo(['1.mp4', '2.mp4'], 'smv3.mp4', ['00:05-00:17', '00:00-00:10'])
:param pathList: 视频路径列表(str/str list)
:param savePath: 视频结果保存位置
:param timeList: 欲截取的视频片段起止时间列表(str/str list),格式为'开始时间-截止时间',
开始时间/截止时间需使用'分:秒'或者'时:分:秒'或者'秒’,时、分、秒均为2位整数,例如'12‘,'12:34','12:34:56'
:param separator: 人声分离器对象
:param noiseReduction: 开启降噪(去除背景声保留人声)
:return: 空
"""
# 若为str,转为str list
if isinstance(pathList, str):
pathList = [pathList]
if isinstance(timeList, str):
timeList = [timeList]
# 检查数据是否完整
if len(pathList) != len(timeList):
print('pathList 与 timeList 长度不匹配')
# 解析并标准化起止时间格式,标准格式为'hh:mm:ss'
startList = []
endList = []
for item in timeList:
t = item.split('-')
startList.append(t[0])
endList.append(t[1])
for index in range(len(startList)):
if startList[index].count(':') == 0:
startList[index] = '00:00:' + startList[index]
elif startList[index].count(':') == 1:
startList[index] = '00:' + startList[index]
for index in range(len(endList)):
if endList[index].count(':') == 0:
endList[index] = '00:00:' + endList[index]
elif endList[index].count(':') == 1:
endList[index] = '00:' + endList[index]
# 切割出每个视频的欲截取片段
videoFiles = []
for index in range(len(pathList)):
videoFiles.append(VideoFileClip(pathList[index], fps_source='fps').subclip(startList[index], endList[index]))
# 合并片段,写入新文件,关闭每个片段的操作句柄
finVideo = concatenate_videoclips(videoFiles)
# 降噪
if noiseReduction:
finVideo2 = videoNoiseReduction(finVideo, separator)
finVideo2.write_videofile(savePath)
finVideo2.close()
else:
finVideo.write_videofile(savePath)
for item in videoFiles:
item.close()
finVideo.close()
if __name__ == '__main__':
# Separator('spleeter:2stems')不要放到audioNoiseReduction函数里,否则可能因为频繁创建Separator('spleeter:2stems')对象而卡死
separator = Separator('spleeter:2stems')
# 测试audioNoiseReduction
audio = AudioFileClip('audio_example.mp3')
audio_red = audioNoiseReduction(audio, separator)
audio_red.write_audiofile('audio_example_red.wav')
audio.close()
audio_red.close()
# 测试videoNoiseReduction
video = VideoFileClip('1.mp4', fps_source='fps')
newVideo = videoNoiseReduction(video, separator)
newVideo.write_videofile('new_video.mp4')
video.close()
newVideo.close()
# 测试splitAndMergeVideo
splitAndMergeVideo('1.mp4', 'smv1.mp4', '00:05-00:17', separator)
splitAndMergeVideo(['1.mp4', '1.mp4'], 'smv2.mp4', ['00:05-00:17', '00:00-00:10'], separator, noiseReduction=True)
splitAndMergeVideo(['1.mp4', '2.mp4'], 'smv3.mp4', ['00:05-00:17', '00:00-00:10'], separator)
exit()
















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











