







概述
需求
系统的物理内存是有限的,而对内存的需求是变化的, 程序的动态性越强,内存管理就越重要,选择合适的内存管理算法会带来明显的性能提升。
比如nginx, 它在每个连接accept后会malloc一块内存,作为整个连接生命周期内的内存池。 当HTTP请求到达的时候,又会malloc一块当前请求阶段的内存池, 因此对malloc的分配速度有一定的依赖关系。(而apache的内存池是有父子关系的,请求阶段的内存池会和连接阶段的使用相同的分配器,如果连接内存池释放则请求阶段的子内存池也会自动释放)。
目标
内存管理可以分为三个层次,自底向上分别是:
- 操作系统内核的内存管理
- glibc层使用系统调用维护的内存管理算法
- 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如使用引用计数std::shared_ptr,apache的内存池方式等等。
当然应用程序也可以直接使用系统调用从内核分配内存,自己根据程序特性来维护内存,但是会大大增加开发成本。
本文主要介绍了glibc malloc的实现,及其替代品
一个优秀的通用内存分配器应具有以下特性:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 缓存本地化友好
- 通用性,兼容性,可移植性,易调试
现状
目前大部分服务端程序使用glibc提供的malloc/free系列函数,而glibc使用的ptmalloc2在性能上远远弱后于google的tcmalloc和facebook的jemalloc。 而且后两者只需要使用LD_PRELOAD环境变量启动程序即可,甚至并不需要重新编译。
glibc ptmalloc2
ptmalloc2即是我们当前使用的glibc malloc版本。
ptmalloc原理
系统调用接口
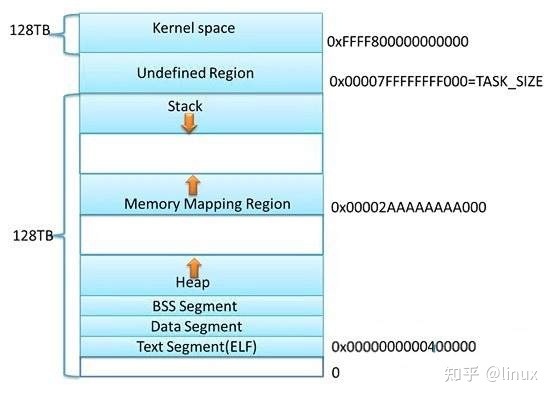
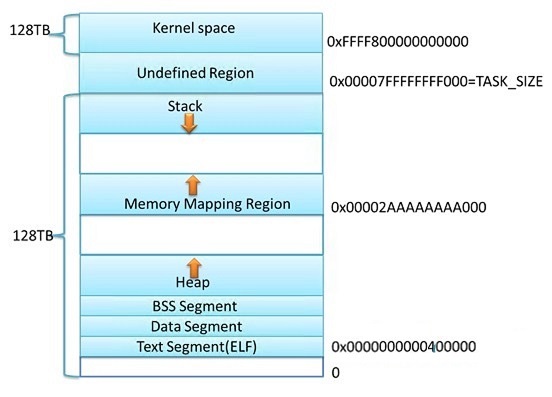
上图是 x86_64 下 Linux 进程的默认地址空间, 对 heap 的操作, 操作系统提供了brk()系统调用,设置了Heap的上边界; 对 mmap 映射区域的操作,操作系 统 供了 mmap()和 munmap()函数。
因为系统调用的代价很高,不可能每次申请内存都从内核分配空间,尤其是对于小内存分配。 而且因为mmap的区域容易被munmap释放,所以一般大内存采用mmap(),小内存使用brk()。
多线程支持
- Ptmalloc2有一个主分配区(main arena), 有多个非主分配区。 非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。
- free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









