






node只是一个平台(或运行时),这个平台扩展了js的功能
一、Node 可以做什么
- 轻量级、高性能的web服务器
- 前后端Js同构开发
- 便携高效的前端工程化
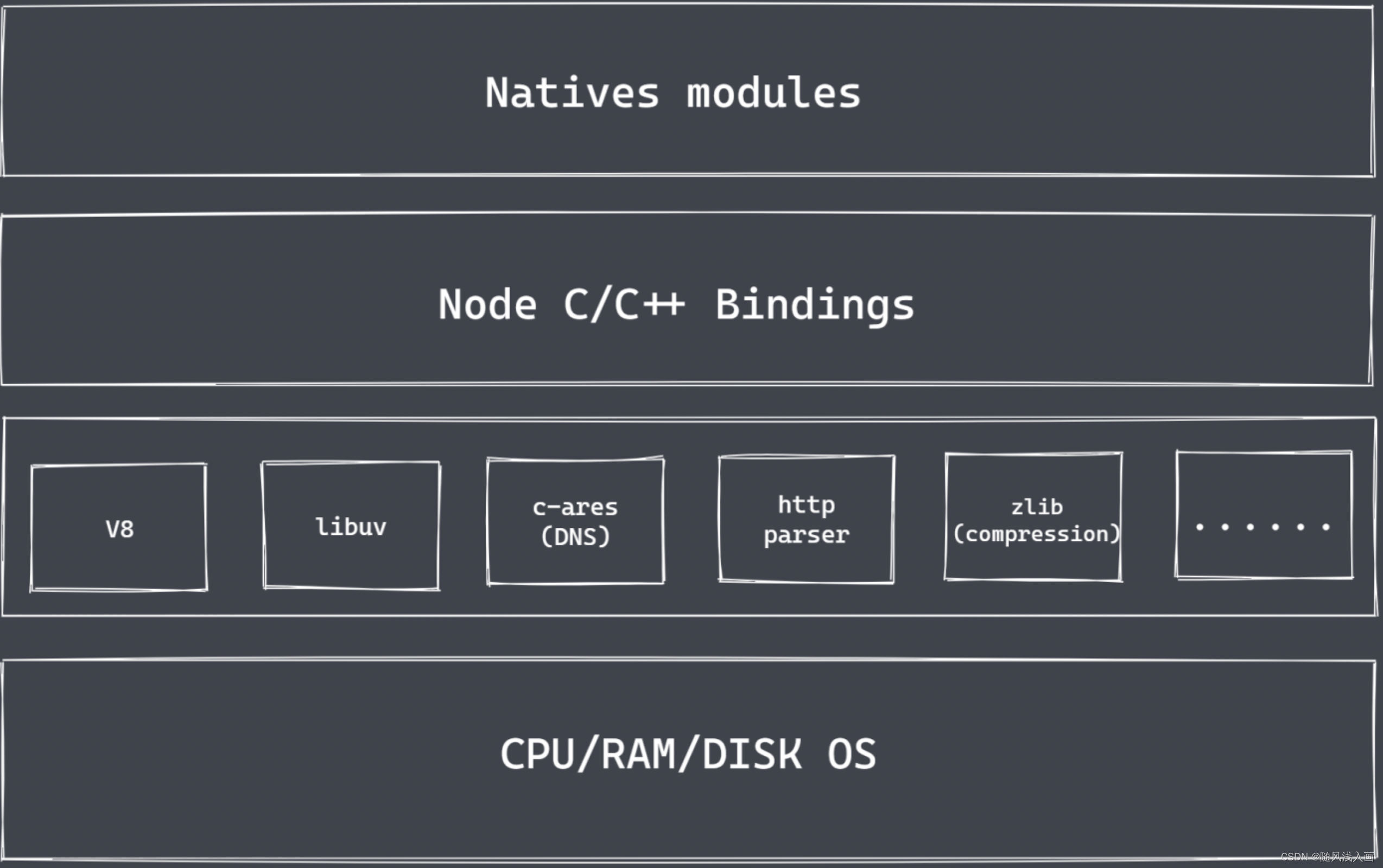
二、 NodeJs架构
上层 Natives modules
- 暴露相应的
JS功能接口,供开发者直接进行调用- 当前层由JS实现
- 提供应用层序可直接调用库,例如 fs、path、http等
- JS语言无法直接操作底层硬件设置,这里需要去到中层
中层 Node C/C++ Bindings
- 帮助
找到对应功能的Builtin modules层,这个过程需要V8引擎配合实现 - Builtin modules胶水层用来帮助调用对应功能的C++函数
底层
- V8引擎(虚拟机):
构建nodeJs运行环境,执行JS代码,提供桥梁接口 - Libuv: 处理node环境下执行过程中的许多
细节操作,如事件循环、事件队列、异步IO - 第三方相关模块: zlib、http、c-ares等,这些模块都对应着不同的功能.如此就能让js在node环境下实现浏览器平台下不能实现的功能
三、移植js到服务端的方案很多,但为什么是nodeJS?
先聊聊BS架构
在我们忽略网络带宽硬件性能条件之后,真正影响用户获取速度的是IO的时间消耗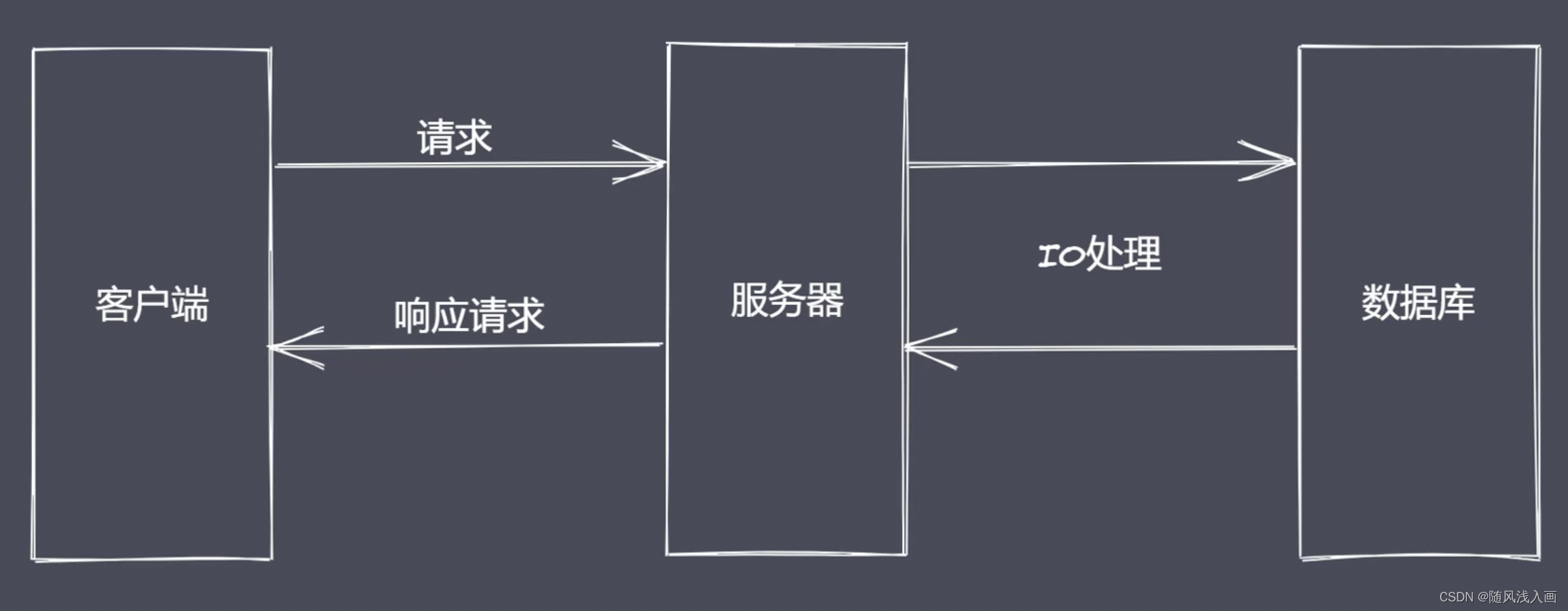
IO是计算机操作过程中最缓慢的环节
- 访问
Ram(内存)的IO时间消耗是纳米级别的 - 访问
Rom(硬盘)的IO时间消耗是毫秒级别的
NodeJs更适用于IO密集型高并发请求
传统高级语言并发处理用户请求采用多线程or多进程处理请求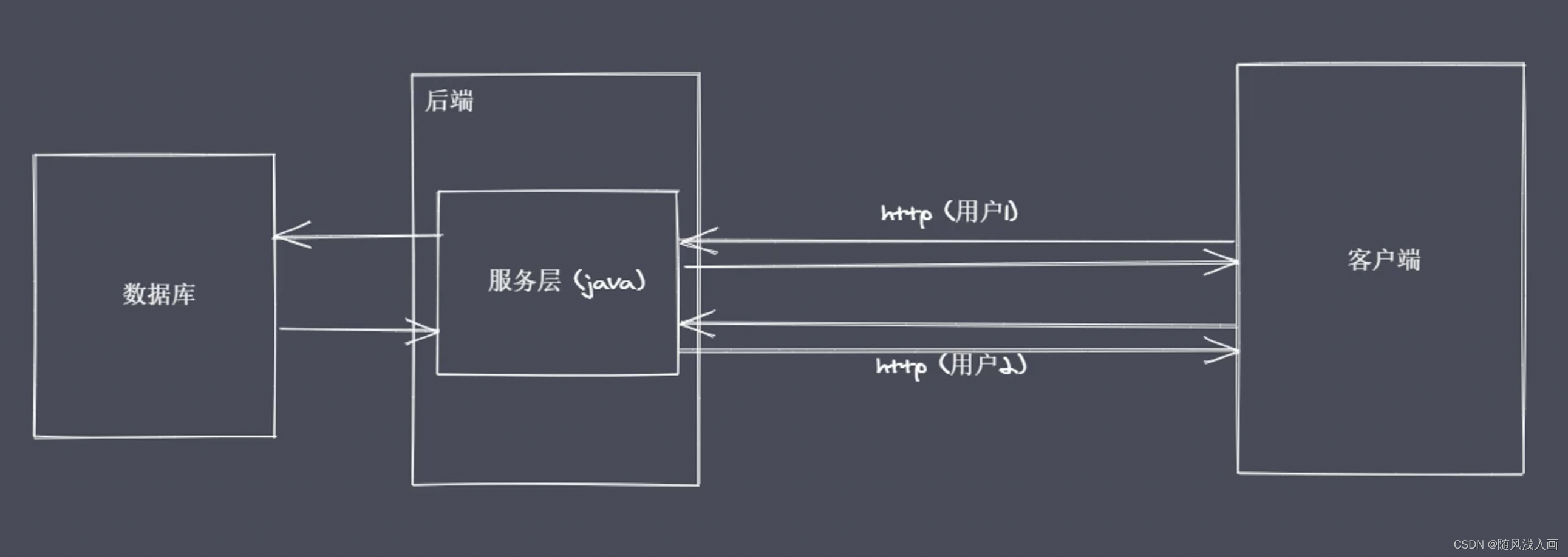
缺点
线程或进程数是有限的,当同一时间有很多耗时请求时就会出现无响应的状况.
解决
nodeJs采用Reactor模式
多线程情况下如果请求比较耗时,那么线程或进程是处于等待状态的.基于这种情况就有了Reactor模式,Reactor模式也称应答者模式,核心思想是只保留一个线程,等耗时操作完成之后再呼叫这个单线程.并且它是非阻塞的,每个请求过来时这个线程就会立马响应,只不过在作耗时操作的过程中线程不用等待.这样的话能避免多个线程之间在进行上下文切换的时候需要去考虑的状态保存、时间消耗、状态锁等问题.
nodeJs也正是基于Reactor模式.然后结合js语言本身具备的单线程、事件驱动的架构和异步编程这样的特性、让单线程可以远离阻塞.从而通过异步非阻塞IO来更好的使用CPU资源、并且实现高并发请求的处理. 这就是为什么移植js到服务端的方案很多但nodeJs最出彩的原因.
nodeJs的缺点
如果请求密集且耗时小,一个线程显然是不够的. 所以对于nodejs来说更适用于IO密集型高并发请求,并不适用于大量且复杂的业务逻辑处理. 但是这也并不影响nodejs应用于同构开发和前端工程化当中,它任然是大前端的基石
四、Nodejs异步IO实现思路
异步IO的优点
能节省时间消耗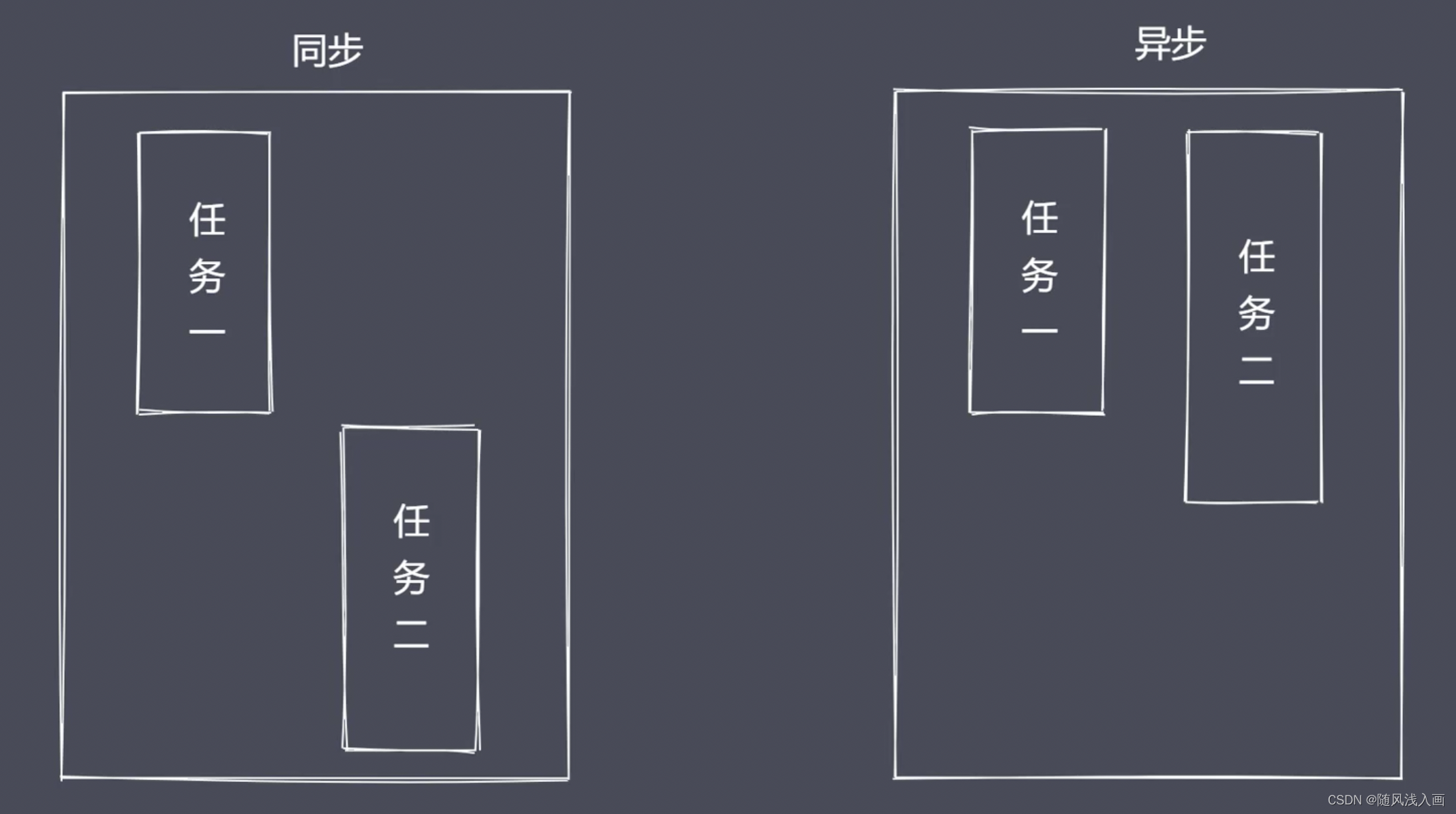
异步IO面临的问题
在操作系统中IO分为阻塞IO和非阻塞IO两种,当我们采用非阻塞IO时,CPU的时间片就可以拿出来去处理其他事情,那这个时候对于性能肯定是有所提升的,但是这种操作同样也有问题,因为立即返回的并不是业务层真正期望的实际数据,而仅仅是当前的调用状态,而操作系统为了获取完整的数据他就会使应用程序重复调用IO操作,判断IO是否结束,也就是轮询.虽然轮询技术能拿到最终需要的数据,但是对于代码它还是同步的效果,因为在轮询的过程中程序任然在等待IO的结果.
而我们期望代码能发起非阻塞的IO调用,但是无需通过唤醒的方式来轮询判断当前的IO是否结束了,而是可以在调用发起之后直接去进行下一个任务的处理,然后等待IO的结果处理完成之后,再通过某种回调的方式将数据回传给当前代码进行使用就可以了,这个时候nodejs中的核心库libuv就该出场了.libuv会根据不同的操作系统去调用对应的异步IO方法
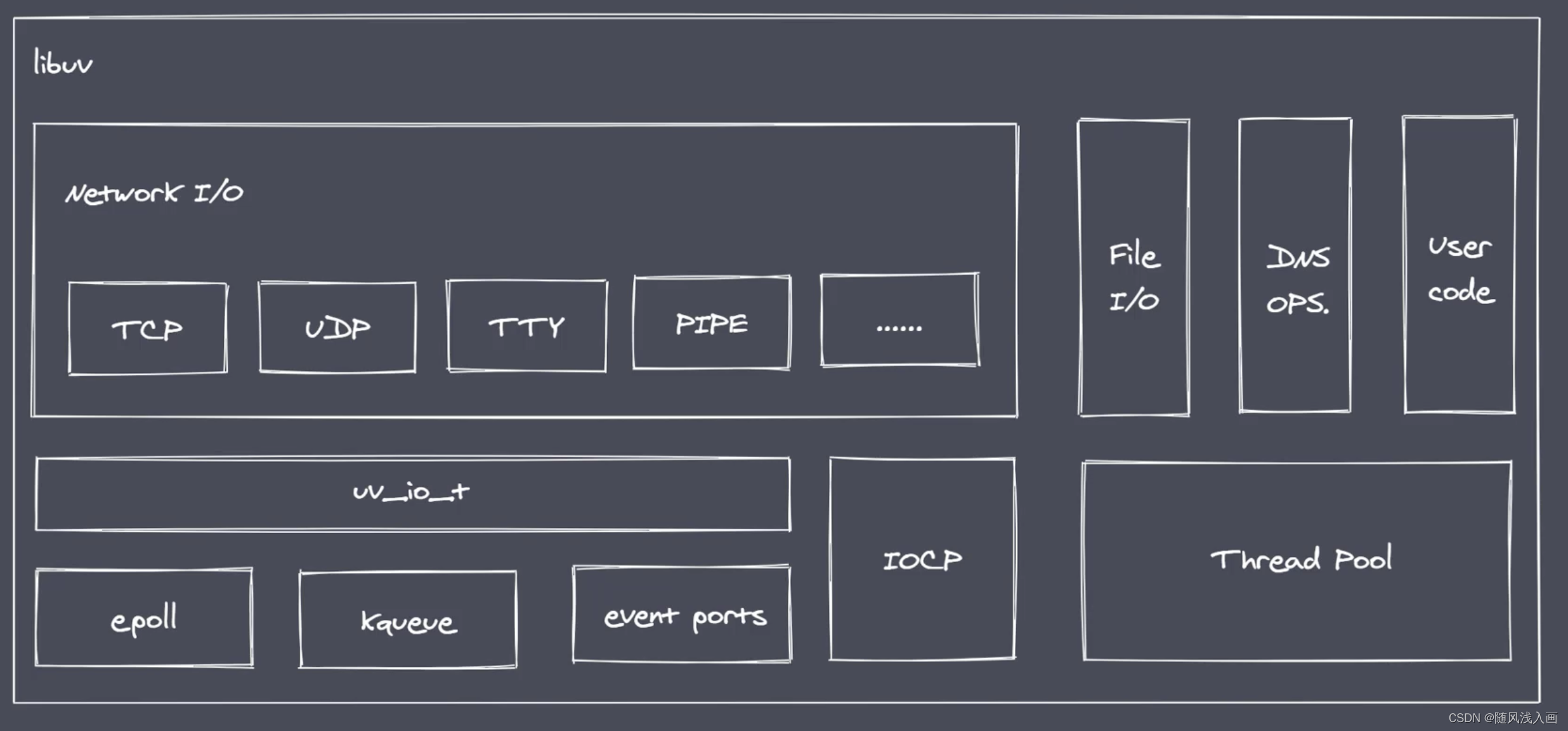
事件驱动架构
了解了这些操作系统对于IO的支持之后呢,再来看一下node如何通过事件驱动架构实现异步io的过程. 事件驱动架构是软件开发中的通用模式,事件驱动在使用过程中类似发布订阅、观察者模式,发布者广播消息,订阅者接受消息.但是需要强调的是事件驱动、发布订阅、观察者在实践中不是一回事.
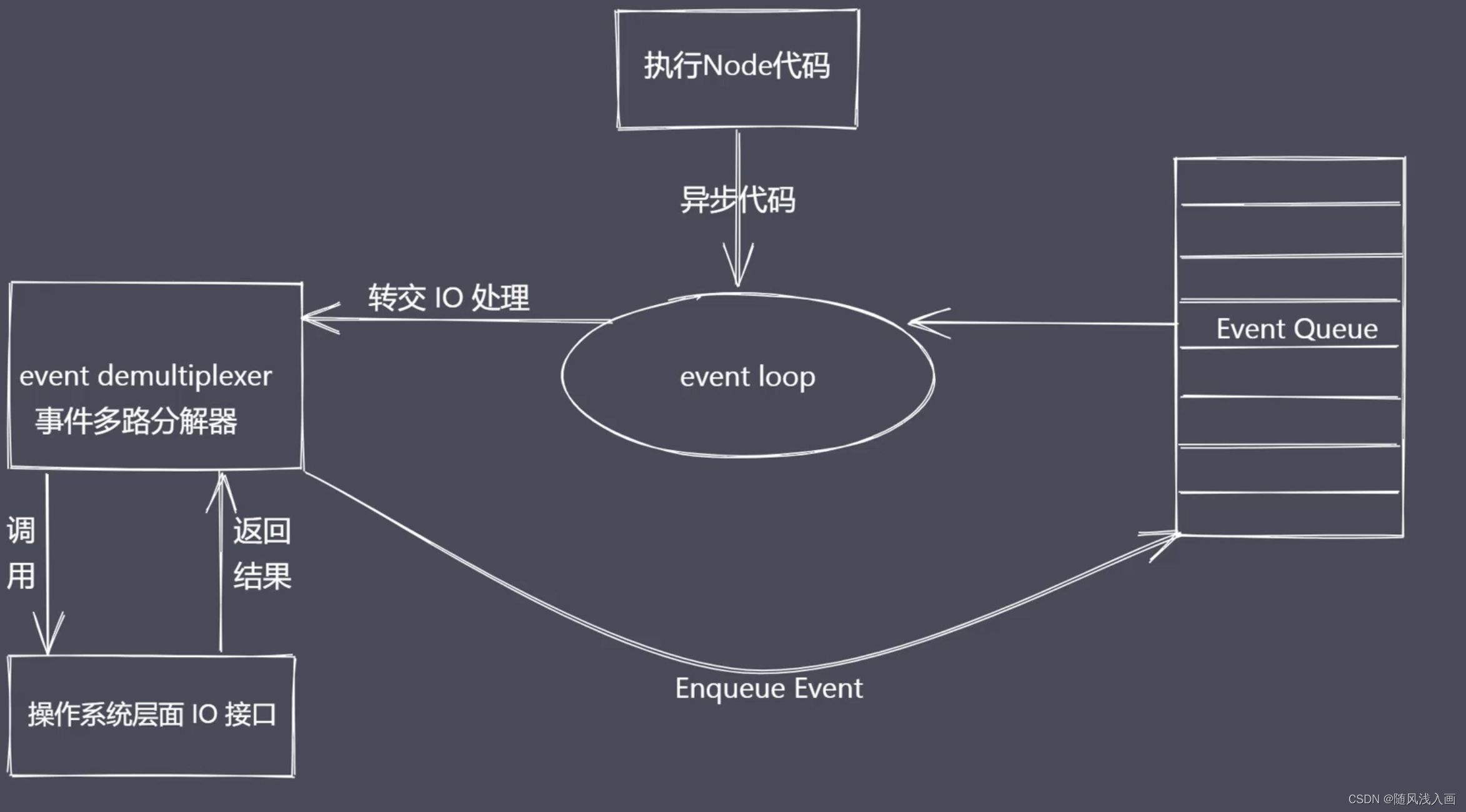
事件驱动架构代码层体现:
const EventEmitter = require('events')
const myEvent = new EventEmitter()
myEvent.on('事件1', () => {
console.log('事件1执行了')
})
myEvent.on('事件1', () => {
console.log('事件1-2执行了')
})
// 使用上类似一个发布订阅,但实际上不是一回事.
myEvent.emit('事件1')
// 事件1执行了
// 事件1-2执行了
总结
- IO是应用程序的瓶颈所在
- 异步IO无需原地等待结果返回,提高了性能
- IO操作属于操作系统级别的,平台都有对应的实现,而libuv库只是对他们做了一层抽象的封装
- NodeJs单线程配合事件驱动架构以及libuv库实现了异步IO
五、Nodejs单线程如何实现高并发?
在nodejs底层通过异步IO、事件循环、事件驱动架构,通过回调通知的方式实现非阻塞的调用以及并发. 具体的表现就是程序中出现多个请求的时候是无需阻塞的,它会从上自下去执行,然后等待libuv库去完成工作之后按顺序通知相应的事件回调去触发执行就可以了,这样的话单线程就完成了多线程的工作. 而我们所谓的单线程,其实是说nodejs的主线程是单线程,而libuv库里是有一个线程池的,其线程数默认大小为4,也可以修改环境变量进行修改.
这样的实现有什么劣势?
如下,运行js的主线程在处理cpu密集型任务(如复杂计算)时会过多的占用cpu,这样一来后面的逻辑就要等待了,而且单线程也无法体现出多核Cpu的优势.当然这些问题也在node后续的版本中给出了解决方案,比如常见的cluster集群.
const http = require('http')
function sleepTime (time) {
const sleep = Date.now() + time * 1000
while(Date.now() < sleep) {}
return
}
sleepTime(4)
const server = http.createServer((req, res) => {
res.end('server starting......')
})
server.listen(8080, () => {
console.log('服务启动了')
})
cluster集群
node实例是单线程作业的。在服务端编程中,通常会创建多个node实例来处理客户端的请求,以此提升系统的吞吐率。对这样多个node实例,我们称之为cluster(集群)。
借助node的cluster模块,开发者可以在几乎不修改原有项目代码的前提下,获得集群服务带来的好处。
集群有以下两种常见的实现方案,而node自带的cluster模块,采用了方案二。
方案一:多个node实例+多个端口
集群内的node实例,各自监听不同的端口,再由反向代理实现请求到多个端口的分发。
优点:实现简单,各实例相对独立,这对服务稳定性有好处。
缺点:增加端口占用,进程之间通信比较麻烦。
方案二:主进程向子进程转发请求
集群内,创建一个主进程(master),以及若干个子进程(worker)。由master监听客户端连接请求,并根据特定的策略,转发给worker。
优点:通常只占用一个端口,通信相对简单,转发策略更灵活。
缺点:实现相对复杂,对主进程的稳定性要求较高。
六、再了解一下进程与线程
Node.js的单线程指的是主线程是“单线程”
nodejs事件循环理论
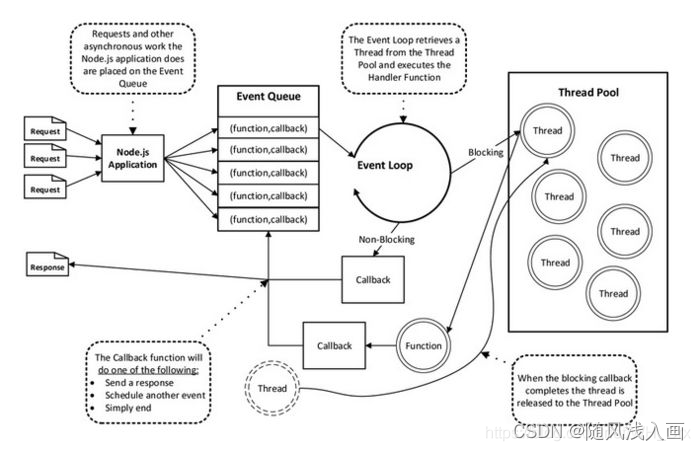
1、每个Node.js进程只有一个主线程在执行程序代码,形成一个执行栈(execution context stack)。
2、主线程之外,还维护了一个"事件队列"(Event queue)。当用户的网络请求或者其它的异步操作到来时,node都会把它放到Event Queue之中,此时并不会立即执行它,代码也不会被阻塞,继续往下走,直到主线程代码执行完毕。
3、主线程代码执行完毕完成后,然后通过Event Loop,也就是事件循环机制,去Event Queue的开头取出第一个事件,从线程池中分配一个线程去执行这个事件,接下来继续取出第二个事件,再从线程池中分配一个线程去执行,然后第三个,第四个。主线程不断的检查事件队列中是否有未执行的事件,然后通过线程依次去执行,执行完毕之后会通知主线程,主线程执行回调,线程归还给线程池,如此循环,直到事件队列中所有事件都执行完。
4、主线程不断重复上面的第三步。
nodejs事件循环实现
Libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API。
libuv中的高效队列是用c语言, 只使用宏定义封装而成,
Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,事件循环机制也是它里面的实现。
事件循环就是一个大的while循环
int uv_run(uv_loop_t* loop, uv_run_mode mode) { int timeout; int r; int ran_pending;//首先检查我们的loop还是否活着//活着的意思代表loop中是否有异步任务//如果没有直接就结束
r = uv__loop_alive(loop); if (!r)
uv__update_time(loop);//传说中的事件循环,你没看错了啊!就是一个大while
while (r != 0 && loop->stop_flag == 0) { //更新事件阶段
uv__update_time(loop); //处理timer回调
uv__run_timers(loop); //处理异步任务回调
ran_pending = uv__run_pending(loop);//没什么用的阶段
uv__run_idle(loop);
uv__run_prepare(loop); //这里值得注意了
//从这里到后面的uv__io_poll都是非常的不好懂的
//先记住timeout是一个时间
//uv_backend_timeout计算完毕后,传递给uv__io_poll
//如果timeout = 0,则uv__io_poll会直接跳过
timeout = 0; if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout); //就是跑setImmediate
uv__run_check(loop); //关闭文件描述符等操作
uv__run_closing_handles(loop); if (mode == UV_RUN_ONCE) { /* UV_RUN_ONCE implies forward progress: at least one callback must have
* been invoked when it returns. uv__io_poll() can return without doing
* I/O (meaning: no callbacks) when its timeout expires - which means we
* have pending timers that satisfy the forward progress constraint.
*
* UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from
* the check.
*/
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop); if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT) break;
} /* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0) loop->stop_flag = 0; return r;
}
1、Nodejs与操作系统交互,我们在 Javascript中调用的方法,最终都会通过 process.binding 传递到 C/C++ 层面,最终由他们来执行真正的操作。Node.js 即这样与操作系统进行互动。
2、nodejs所谓的单线程,只是主线程是单线程,所有的网络请求或者异步任务都交给了内部的线程池去实现,本身只负责不断的往返调度,由事件循环不断驱动事件执行。
3、Nodejs之所以单线程可以处理高并发的原因,得益于libuv层的事件循环机制,和底层线程池实现。
4、Event loop就是主线程从主线程的事件队列里面不停循环的读取事件,驱动了所有的异步回调函数的执行,Event loop总共7个阶段,每个阶段都有一个任务队列,当所有阶段被顺序执行一次后,event loop 完成了一个 tick。
进程
定义:进程是计算机分配资源调度的基本单元,每一个应用程序启动都会开启一个独立的进程。分配固定的资源以及一个进程ID,进程之间可以通过IPC通信,node中进程通过child_process 创建。
线程
定义:线程是计算机计算的最小单元,一个进程可以有多个线程,但一个线程只对应一个进程。线程可共享进程的部分资源,node是单线程应用(也就是一个线程对应一个进程)。 那么node是如何提高CPU利用率的呢? 也就是上面所说到的,创建一个主进程(master),以及若干个子进程(worker),每个子进程又会对应一个主线程(主线程是单线程), 从而实现多线程。
那么主进程,子进程,主线程,子线程。那么在node的整个生命周期中是什么时候被创建的呢?相互之间是怎么关联起来的呢?
进程与线程参考链接
七、 Node.js 做为中间层(BFF)
bff其实是 Backend for Frontend 首字母的缩写,也就是前端的后端。BFF通过网络协议连接到后端服务。BFF的技术实现可以多种多样,也可以是Java、Python、Go等。
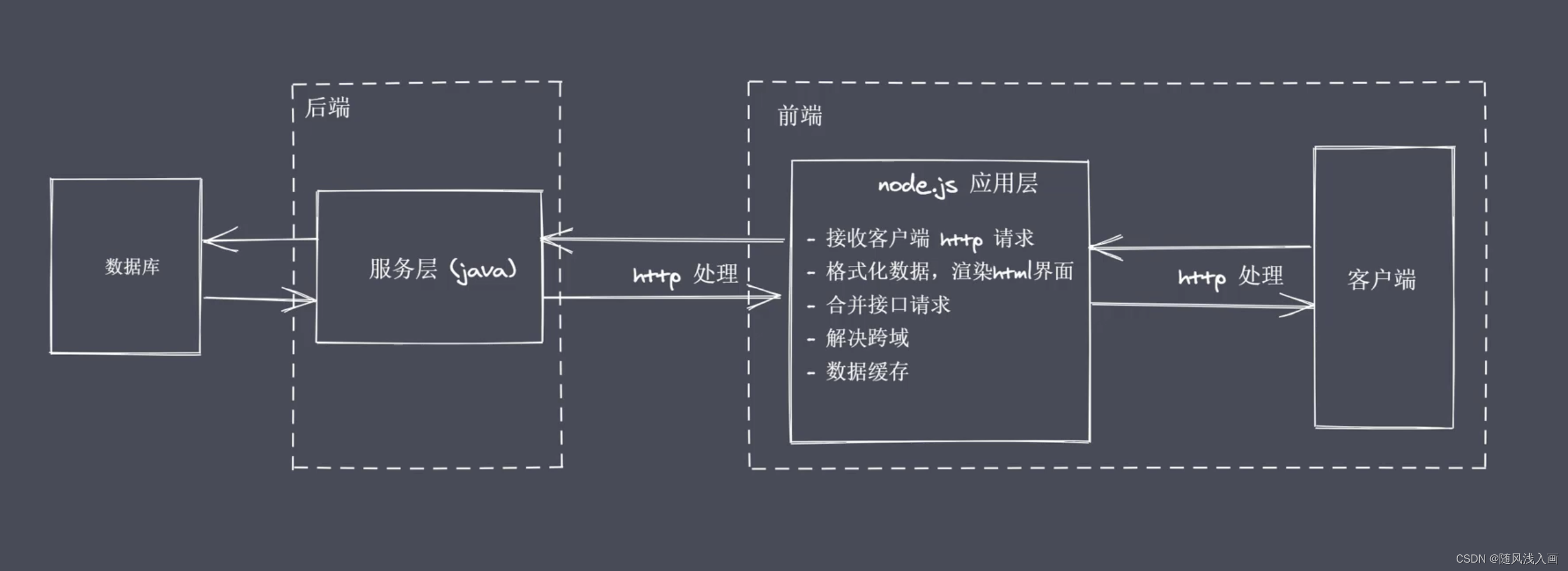
BFF的作用
1、聚合:通过聚合后端多个接口的数据为前端提供所需要的完整数据。
2、裁减:过滤掉对于前端应用无用的数据。比如,去掉一些前端用不到的字段。
3、适配:根据端的不同提供端特有的数据。如,根据移动端系统或应用的差别,生成不同的分享或跳转链接。
4、验权:负责前端身份与权限认证,会话状态保持等。
5、安全:提供应用层安全层,防止非法请求,保证数据安全。如,用户身份认证,防止CSRF攻击等。
6、解耦:关注点分离(separation of concerns),BFF关注前端用户体验,后端API关注业务领域模型。不应当包含特定或核心的业务逻辑,不应当保存核心业务数据。
7、复用:有助于避免重复开发带来的工作量,也可以节约运维成本。BFF一个重要作用就是聚合不同前端应用的重复代码。当你发现相同业务的不同前端应用,通过API获取到数据后请求多个接口,或转换或过滤了一些响应数据,或都进行了相同的基于结果数据的进一步计算,此时,你需要考虑把这些代码迁移到BFF。
8、控制:BFF应当有能力根据前端应用的性质不同,控制哪些数据应当或不应该提供给哪个应用。
9、统一:BFF可以承担后端到前端数据传输过程中协议不一致,统一协议的角色。如,有的是HTTP[S],有的是RPC。
10、提效:可以避免一个业务后台对接多个前端应用的困境,也可以避免一个前端应用需要对接多个业务后台的麻烦。
11、分流:可以用于分散用户端的并发请求。
一个完整的BFF应当是什么样的?
除了实现UX需要的基本业务功能数据和操作接口外,一个完整的BFF微服务也应当有监控、降级、熔断、调用链跟踪、A/B发布等等能力。
BFF的缺点有哪些?
1、由于在调用链路上又增加了一层,所以,会有网络延迟上的增加。
2、会增加微服务应用的数量,增加运维的难度。
bff参考链接















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









