










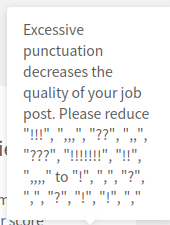
遇到个需求,前端提取出一段话中的重复或者连续多次的字符比如 ??? !!! , 之类的.
假设这句话为
const content = 'o?.!!!a,,sd,,,o??o??o,,o???,!!!!!!!d!!as!!ds,,,,ad';
先用正则判断下这段话是不是有重复的符号
const duplicatedRegex = /,(?=,)|!(?=!)|\?(?=\?)/;
const punctuationError = duplicatedRegex.test(content);
然后找出这段话中的所有符合条件的进行分组
const symbolRegex = /(\?{2,})|(!{2,})|(,{2,})/g;
const arr = descriptionData.descriptionUsedForVerify.match(symbolRegex);
一定要记得正则最后的/g,代表全局匹配,且是贪婪匹配,匹配所有的符合条件的
然后把得到的数组去重,这里使用es6的方法去重,当然也可以用老方法
const matches = arr.filter((item, index, self) => self.indexOf(item) === index);
// item : 数组每一项的值
// index: 每一项的下标
// self: 当前数组
这边的箭头函数类似于Java8的的lambda表达式, 得到去重后的数组.
最后将有错误的符号和修改替换建议的内容整合显示给用户
const irregularPunctuation = [];
const replacedPunctuation = [];
matches.forEach((item) => {
irregularPunctuation.push(`"${item}"`);
const replaced = [...new Set(item)].join('');
replacedPunctuation.push(`"${replaced}"`);
});
这里的Set是es6的新set 这一句的作用是字符串的去重
注意,不可以这么写
const replaced = new Set(item).join('');
如果这么写会报错,说是.join(’’) not a function

最后整理格式输出就好了















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









