







2.1 二分类
1.学习目标
- 学习不使用for循环来遍历m个样本的方法
- 神经网络的计算过程为何分为
正向传播与反向传播
2.训练集的理解
图片在计算机中表示:为了保存一张图片,需要保存三个矩阵,
它们分别对应图片中的红、绿、蓝三种颜色通道,如果你的图片大小为 64x64 像素,那么你就有三个规模为64x64 的矩阵(64 *64 *3)
注意将这些像素值放到一个特征向量的方法:竖着放(x就是一个n维的向量)
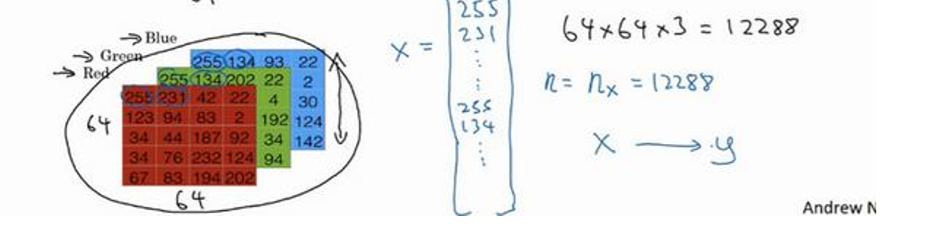
于是:
(x,y):代表一个单独的向量样本,x表示之前的n维向量,y表示对应的预测值(0或者1)
训练集由m个向量样本组成的
(
x
1
,
y
1
)
表
示
向
量
样
本
一
,
(
x
2
,
y
2
)
表
示
向
量
样
本
二
(x^1,y^1)表示向量样本一,(x^2,y^2)表示向量样本二
(x1,y1)表示向量样本一,(x2,y2)表示向量样本二
最后用更紧凑的符号X来表示整个训练集(一列为一个训练样本,多个列组成训练集)

行数:nx的维数
列数:训练集中的样本数量
二对应的表示Y的矩阵则是(1*m的矩阵)

2.2logistic回归
有了X的输入,还要有W(也是nx维的向量),b(是一个实数)如何来表示出y^呢?
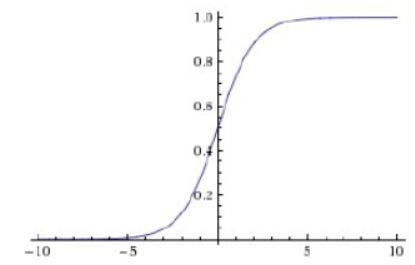
如果是直接的线性表示Y=W*X+b的话,结构可能会>1,也有可能会是负数,所以引入sigmoid函数
公式: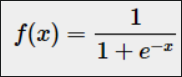
sigmoid函数的缺点:
1.饱和的神经元会"杀死"梯度,指离中心点较远的x处的导数接近于0,停止反向传播的学习过程:当输入非常大或者非常小的时候(saturation),这些神经元的梯度是接近于0的(看图)
2.sigmoid的输出不是以0为中心,而是0.5,这样在求权重w的梯度时,梯度总是正或负的(如果数据进入神经元的时候是正的,那么计算出的梯度也会始终都是正的。)
3.指数计算耗时。
2.3logistic回归损失函数(loss function)
𝐿(𝑦 ^,𝑦) = −𝑦log(𝑦 ^) − (1 − 𝑦)log(1 − 𝑦 ^)
讨论:
当y=1的时候我需要让上式尽可能地小,上式变为−log(𝑦 ^),则log(𝑦 )尽可能地大,`及y^尽量大`,而y最大为1
同理当y=0的时候,我们希望y^尽可能的小,即为0
损失函数
注意平方差函数与交叉熵损失函数的区别:
平方差函数主要使用在回归问题中,而交叉熵损失函数会使用在分类问题中:在激活函数是sigmoid之类的函数的时候,用平方损失的话会导致误差比较小的时候梯度很小,这样就没法继续训练了,这时使用交叉熵损失就可以避免这种衰退。如果是线性输出或别的激活函数神经元的话完全可以用平方损失。
2.4 梯度下降法
损失函数(loss function):衡量单一样本训练的结果
成本函数(cost function):在全部的数据集上衡量训练的结果
成本函数=m个样本的损失函数的和 / m
成本函数必须是一个凸函数,这样才能使用梯度下降法在多次迭代的过程中寻找出唯一的一个全局最优解
在迭代中的公式:𝑤 = 𝑤 − 𝑎*𝑑𝐽(𝑤)/𝑑𝑤
例子:loss = x 2 x^2 x2+sin(x)
*梯度下降法的过程就是$x_{new}=x_{origin}-dx learning_rate $(dx是loss的导数)
其中的𝑎为学习率,用来控制每次迭代中梯度下降法的步长。
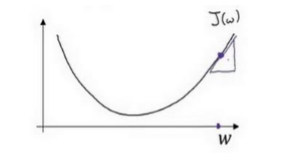
这样的话:
当w开始很大的话,根据𝑤 = 𝑤 − 𝑎*𝑑𝐽(𝑤)/𝑑𝑤,w会逐渐变小;
当w开始很小的话,根据𝑤 = 𝑤 − 𝑎*𝑑𝐽(𝑤)/𝑑𝑤,w会逐渐变大;
最终都会使得新的w达到最小。
2.5 m个样本的梯度下降
之前的成本函数是m个样本的损失函数的和 / m,而要是考虑w的全局梯度值的话,则需要对成本函数进行求导:也就是将之前的每个样本的梯度值求和后 / m
过程:
-
对各个w以及b值进行初始化
-
使用for循环遍历各个样本,在遍历中计算

缺点:
1.需要编写两个for循环,第一个for循环用来进行样本的遍历;第二个for循环用来遍历所有特征的for循环(w1 w2·······)
解决方法:使用向量化的方法解决
2.6 向量化
使用向量化的方法就是:
z
=
n
p
.
d
o
t
(
w
,
x
)
+
b
z=np.dot(w,x)+b
z=np.dot(w,x)+b
其中w,x都是(1*n_x)维的数据
例子:
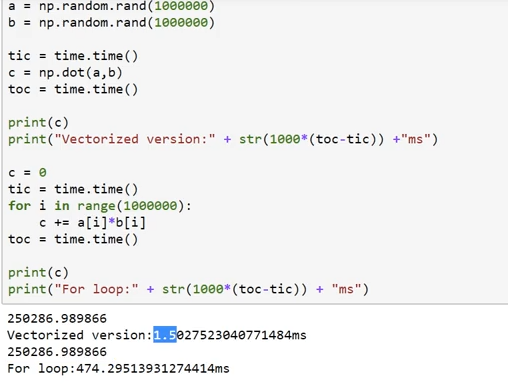
可以看到使用向量化的话会快很多
原因:使用numpy等方法可以进行CPU、GPU等合理的数据并行处理,从而加快代码的运行。
在梯度下降法中高效计算激活函数
首先可以使用dw=np.zeros((n_x,1)来代替内层的循环
而外层的循环使用之前说过的X矩阵来解决:(得到一个大写的Z矩阵)
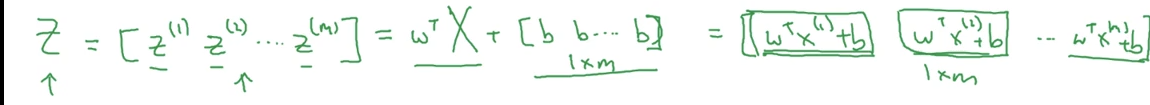
即:
Z
=
n
p
.
d
o
t
(
W
t
,
X
)
+
b
Z=np.dot(W^t,X)+b
Z=np.dot(Wt,X)+b
由于b实际上是一个实数,但是在它与前面计算完成后的矩阵相加的时候,python就会将这个实数自动变为一个1*m的矩阵(这称为python中的广播)
在梯度下降法中的后向传播中使用向量化
通过向量化的方法来同时计算m个训练样本的梯度
开始没有使用向量化的代码:
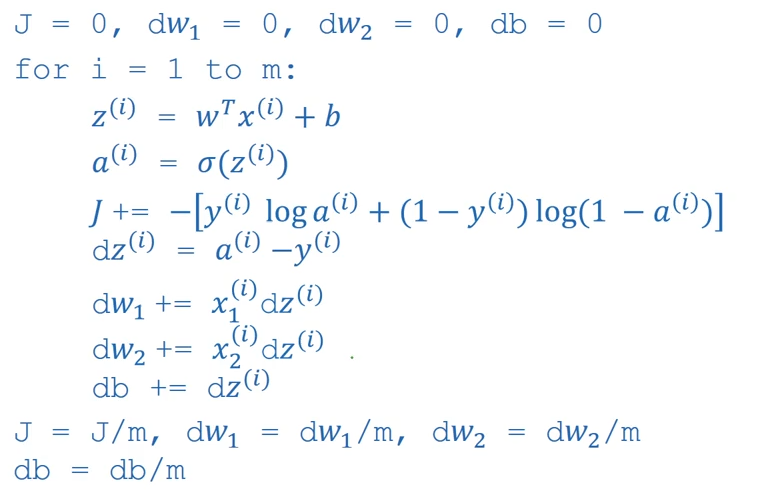
使用向量化的代码:

多次迭代梯度下降法
在进行多次的梯度下降的迭代时,还是需要一个for循环来控制迭代的次数,而这个迭代的for循环是没有办法去掉的
2.7 numpy中的向量说明
在编程的时候不要使用类似a=np.random.randn(5)这样的秩为一的数组( a.shape=(5,) ),因为当进行矩阵a*矩阵a的转置的时候结果不是一个矩阵而是一个数,所以建议使用a=np.random.randn(5,1) a.shape=(5,1)
a=np.random.randn(1,5) a.shape=(1,5)














 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









