







 本文介绍Hadoop2.2.0版本中HDFS的高可用性实现方式,通过设置两个NameNode节点,其中一个处于活动状态,另一个处于备用状态。两个NameNode之间通过共享数据保持状态同步,确保在主节点故障时可以无缝切换。
本文介绍Hadoop2.2.0版本中HDFS的高可用性实现方式,通过设置两个NameNode节点,其中一个处于活动状态,另一个处于备用状态。两个NameNode之间通过共享数据保持状态同步,确保在主节点故障时可以无缝切换。
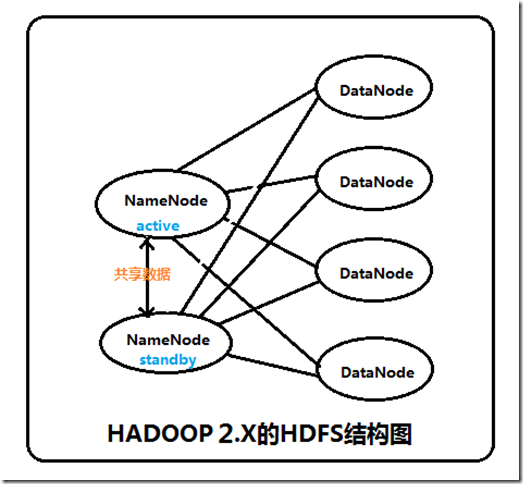
hadoop2.2.0(HA)中HDFS的高可靠指的是可以同时启动2个NameNode。其中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Nnetwork File System或者Quorum Journal Node。前者是通过linux共享的文件系统,属于操作系统的配置;后者是hadoop自身的东西,属于软件的配置。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务,如图:
通过浏览器虽然可以查看HDFS的NameNode的状态,如果感觉不方便,可以直接使用命令来查看(前提是HDFS已经启动):
[root@CentOSA ~]# hdfs haadmin -getServiceState nn1 active [root@CentOSA ~]# hdfs haadmin -getServiceState nn2 standby [root@CentOSA ~]#

















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









