







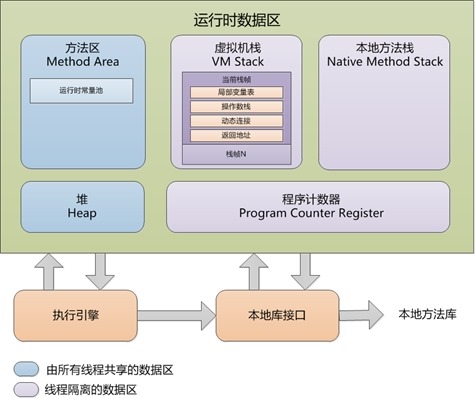
1. JVM中内存结构模型
JVM的内存结构大概分为:
堆(Heap):线程共享。所有的对象实例以及数组都要在堆上分配。回收器主要管理的对象。
方法区(Method Area):线程共享。存储类信息、常量、静态变量、即时编译器编译后的代码。
方法栈(JVM Stack):线程私有。存储局部变量表、操作栈、动态链接、方法出口,对象指针。
本地方法栈(Native Method Stack):线程私有。为虚拟机使用到的Native 方法服务。如Java使用c或者c++编写的接口服务时,代码在此区运行。
程序计数器(Program Counter Register):线程私有。有些文章也翻译成PC寄存器(PC Register),同一个东西。它可以看作是当前线程所执行的字节码的行号指示器。指向下一条要执行的指令。
2. Java中多线程在哪些项目中用到了
3. 活锁死锁问题分析,什么是活锁,什么是死锁.出现的原因是什么?如何避免?
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。处于活锁的实体是在不断的改变状态,活锁有可能自行解开。
解决协同活锁的一种方案是调整重试机制。比如引入一些随机性。例如如果检测到冲突,那么就暂停随机的一定时间进行重试。这回大大减少碰撞的可能性。 典型的例子是以太网的CSMA/CD检测机制。
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁的发生必须具备以下四个必要条件。
1)互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
2)请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
3)不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
4)环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
产生原因:竞争资源引起进程死锁
当系统中供多个进程共享的资源,其数目不足以满足诸进程的需要时,会引起诸进程对资源的竞争而产生死锁。
解决方法:
在系统中已经出现死锁后,应该及时检测到死锁的发生,并采取适当的措施来解除死锁。
死锁预防。
这是一种较简单和直观的事先预防的方法。方法是通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。预防死锁是一种较易实现的方法,已被广泛使用。但是由于所施加的限制条件往往太严格,可能会导致系统资源利用率和系统吞吐量降低。
死锁避免。
系统对进程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源;如果分配后系统可能发生死锁,则不予分配,否则予以分配。这是一种保证系统不进入死锁状态的动态策略。
死锁检测和解除。
先检测:这种方法并不须事先采取任何限制性措施,也不必检查系统是否已经进入不安全区,此方法允许系统在运行过程中发生死锁。但可通过系统所设置的检测机构,及时地检测出死锁的发生,并精确地确定与死锁有关的进程和资源。检测方法包括定时检测、效率低时检测、进程等待时检测等。
然后解除死锁:采取适当措施,从系统中将已发生的死锁清除掉。
这是与检测死锁相配套的一种措施。当检测到系统中已发生死锁时,须将进程从死锁状态中解脱出来。常用的实施方法是撤销或挂起一些进程,以便回收一些资源,再将这些资源分配给已处于阻塞状态的进程,使之转为就绪状态,以继续运行。死锁的检测和解除措施,有可能使系统获得较好的资源利用率和吞吐量,但在实现上难度也最大。
4. 多线程下如何做到数据共享?(可扩展数据共享的使用场景)
java中线程的两种实现方式,一种是Thread类,一种实现runable接口,实现runable接口可以实现数据共享
使用thread类在操作多线程时无法达到资源共享的目的,而使用runable接口实现多线程操作可以实现资源共享
5. 多线程下如何保证线程安全?(可扩展两种锁)
美团技术团队: 不可不说的Java“锁”事 - 美团技术团队
6. HashMap的底层详细介绍?(1.7和1.8前后区别)
HashMap的实现原理:
1.HashMap的结构是数组+链表 或者 数组+红黑树 的形式
2.HashMap底层的Entry[ ]数组,初始容量为16,加载因子是0.75f,扩容按约为2倍扩容
3.当存放数据时,会根据hash(key)%n算法来计算数据的存放位置,n就是数组的长度,其实也就是集合的容量
4.当计算到的位置之前没有存过数据的时候,会直接存放数据
5.当计算的位置,有数据时,会发生hash冲突/hash碰撞
6.解决的办法就是采用链表的结构,在数组中指定位置处以后元素之后插入新的元素
7.也就是说数组中的元素都是最早加入的节点
8.如果链表的长度>8时,链表会转为红黑树,当链表的长度<6时,会重新恢复成链表
在JDK1.6,JDK1.7中,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个链表的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
7. ArrayList和LinkList的区别?(使用场景和特性分析)
相同点: ArrayList和LinkList分别实现了List接口,元素都有下标,数据有序,允许存放重复元素
不同点:
ArrayList底层通过数组,数组扩容实现,默认构造方法新建一个空数组,调用add方法添加数据时扩容为10,空间不足时以1.5倍扩容.扩容时需申请新的连续空间,把旧数组复制过去,添加新的数据,回收旧数组.
LinkList底层是链表结构,不需要连续的空间,大小不固定
因为ArrayList是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的,可以直接返回数组中index位置的元素,因此在随机访问集合元素上有较好的性能。但是要插入、删除数据却是开销很大的,因为这需要移动数组中插入位置之后的的所有元素。
相对于ArrayList,LinkedList的随机访问集合元素时性能较差,因为需要在双向列表中找到要index的位置,再返回;但在插入,删除操作是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组。
8. ConCurrentHashMap和HashMap的区别,分段锁机制?(理论)
HashMap底层通过数组+链表 或者 数组+红黑树实现,可以存储null键和null值,线程不安全,并发情况下不可用
在JDK1.7中ConcurrentHashMap采用了分段的数组+链表方式实现,线程安全
通过把整个Map分为N个Segment,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问, 可以提供相同的线程安全,但是效率提升N倍,默认提升16倍
jdk7:
数据结构: ReentrantLock+Segment +HashEntry, 一个segment 中包含一个HashEntry 数组, 每个HashEntry 又是一个链表结构
元素杳询: 二次hash, 第一次Hash定位到segment, 第二次Hash 定位到元素所在的链表的头部
锁: segment 分段锁 segment 继承了ReentrantLock, 锁定操作的segment ,其他的segment 不受影响,并发度为segment 个数,可以通过构造函数指定,数组扩容不会影响其他的segment
get 方法无需加锁, volatile保证
jdk8 :
数据结构: synchronized+CAS+Node+红黑树, Node的vaI和next 都用volatile 修饰, 保证可见性
查找, 替换,赋值操作都使用CAS
锁: 锁链表的head 节点, 不影响其他元素的读写, 锁粒度更细, 效率更高, 扩容时, 阻塞所有的读写操作、并发
读操作无锁:
Node 的val和next 使用volatile 修饰, 读写线程对该变量互相可见
数组用volatile 修饰, 保证扩容时被读线程感知
9. NIO和AIO,BIO三者区别?(理论)
BIO (Blocking I/O):同步阻塞I/O模式。请求数据过程,始终与服务器保持连接,一个链接使用一个线程,造成线程阻塞。
NIO (New I/O):同步非阻塞I/O模式。请求数据过程,如果服务器没有数据返回,采用轮询机制,需要进行I/O处理时,才会使用一个线程去处理,避免了BIO模型下大量线程处于阻塞等待状态。
AIO ( Asynchronous I/O):异步非阻塞I/O模式。异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。AIO相对于NIO的区别在于,NIO需要使用者线程不停的轮询IO对象,来确定是否有数据准备好可以读了,而AIO则是在数据准备好之后,才会通知数据使用者,这样使用者就不需要不停地轮询了。
10. 介绍下Spring框架?(从框架简介,到框架核心,到框架特性)
Spring是一个为了解决企业应用开发的复杂性而创建的开源框架,
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
轻量——从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。此外,Spring是非侵入式的:典型地,Spring应用中的对象不依赖于Spring的特定类。
控制反转——
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









