







服务器一般可以解构为三个主要模块
- I/O处理单元:四种I/O模型,两种高效时间处理模式
- 逻辑单元:两种高效并发模式,逻辑状态机
- 存储单元:略
同步需要按顺序执行,执行不了就硬等,串行;异步方法一旦开始,立即返回,调用者无需等待其中方法执行完成,就可以继续执行后续方法,并发。
8.1 服务器模型
8.1.1 C/S模型
- C/S(client/server,客户/服务器模型)。
- 逻辑:服务器启动,创建一个或多个
监听socket,调用bind函数绑定到特定端口,调用listen函数等待客户连接。客户端可以调用connect函数像服务器发起连接。 - 因为客户端的连接请求是随机到达的异步事件,需要某种I/O模型来监听这一事件。
- 下图展示select系统调用的I/O复用技术,
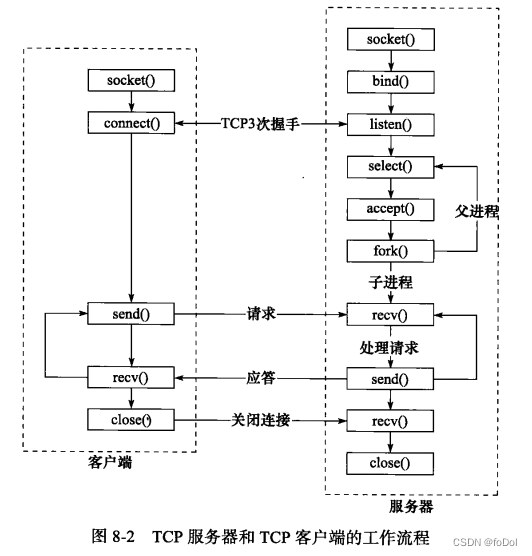
- C/S模型适合资源相对集中的场合,实现简单。缺点在于访问量过大时,用户得到的响应可能变慢。
8.1.2 P2P模型
- 所有主机地位对等,每台机器在消耗服务的同时,也给其他机器提供服务。
- 传统的P2P模型主机之间很难发现,所以P2P模型通常有一个发现服务器,专门用来提供给查找服务,使得客户能够很快找到自己的资源。
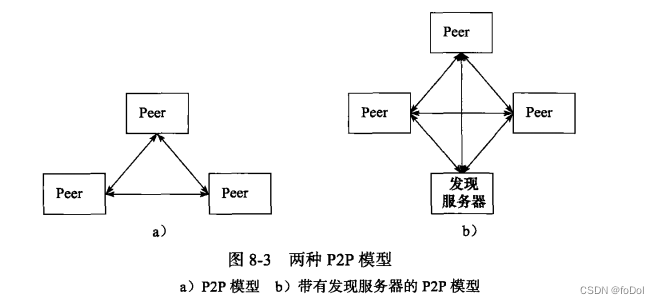
- 从编程角度,P2P可以看成C/S模型的扩展,每台主机既是C又是S。
8.2 服务器编程框架
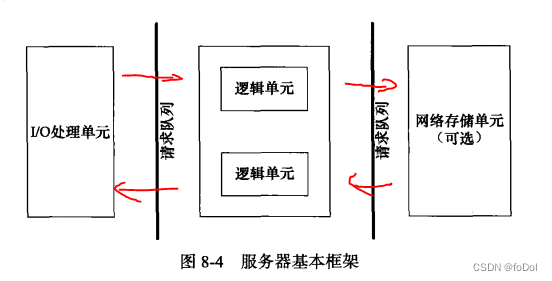
- I/O处理单元:
- 管理客户连接模块。
- 等待并接收新的客户连接
- 接收客户数据
- 将服务器响应返回给客户端
- 数据的收发也可能在逻辑单元中执行。
- 逻辑单元:
- 通常是一个进程或线程
- 分析并处理客户数据,结果传递给I/O处理单元或直接发送给客户端。
- 对于多个逻辑单元的服务器,可以实现并行处理。
- 存储单元:
- 数据库、缓存、文件、独立的服务器
- 并不是必须的。例如ssh和telnet就不需要
- 请求队列:
- 各个单元之间通信方式的抽象。
- I/O处理单元接收到客户请求时,需要以某种方式通知逻辑单元来处理请求。
- 多个逻辑单元访问一个存储单元时,也需要以某种机制协调处理静态条件。
- 请求队列通常被实现为池的一部分。
8.3 I/O模型
- socket创建时默认是阻塞的。
- 阻塞的文件描述符称为阻塞I/O,非阻塞文件描述符称为非阻塞I/O。
- 针对阻塞I/O的系统调用可能因为无法立刻完成被系统挂起,直到等待的事件发送。
- 例如客户端的connect调用,如果服务器的确认文报没有到达客户端,那么connect将会被挂起,直到客户端收到确认文报唤醒。
- accept、send、recv和connect系统调用都可能会被阻塞。
- 对于非阻塞I/O的系统调用会立刻返回,不管事件是否发送,如果没发送,返回-1。
- 在事件已经发生的情况下操作非阻塞I/O才能提高程序效率。因此非阻塞I/O通常要和其他I/O通知机制一起使用。
-
I/O复用
- 应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序。
- Linux常用I/O复用函数是select、poll、epoll_wait
- I/O复用本身是阻塞的,因为他们可以同时监听多个I/O事件,所以才提高效率。
- 阻塞I/O,I/O复用,型号驱动I/O都是同步I/O模型。I/O的读写操作,都是在I/O事件发生后,由应用程序来完成。
- 对于异步I/O而言,用户可以直接对I/O执行读写操作。
- 同步I/O向应用程序通知的是
I/O就绪事件,异步I/sO向应用程序通知的是I/O完成事件。

8.4 两种高效的事件处理模式
- Reactor和Proactor
- 同步I\O模型通常用于事件Reactor模式
- 异步I\O通常用于实现Proactor模式,但是同步I\O也能实现Proactor模式。
8.4.1 Reactor模式
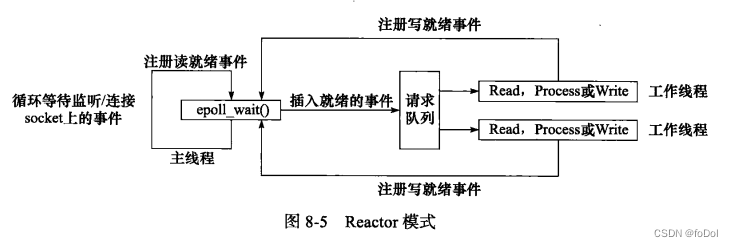
- 主线程(I/O处理单元)只负责监听事件是否发生,事件发生立刻通知到工作线程。
- 读写数据、接收新连接、处理用户请求均在工作线程完成。
- 使用同步I/O(例如epoll_wait)实现的Reactor模式:
- 主线程往epoll内核事件表注册socket可读就绪事件
- 主线程调用epoll_wait等待socket上有数据可读
- socket有数据,epoll_wait通知主线程,主线程将socket可读事件放入请求队列。
- 某个工作线程被唤醒,从socket中读取数据,处理客户请求,往epoll内核事件表注册socket上的
写就绪事件。 - 主线程调用epoll_wait等待socket可写
- 当socket可写时,epoll_wait通知主线程,主线程将socket可写事件放入请求队列。
- 某个工作线程被唤醒,往socket写入服务器处理客户请求的结果。
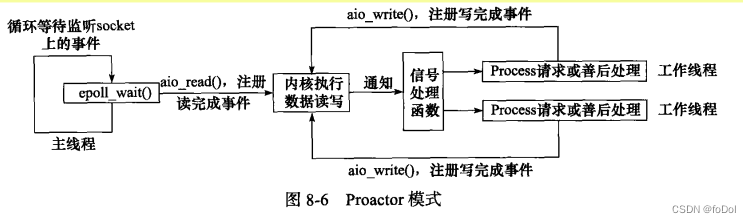
8.4.2 Proactor模式
- Proator模式把所有I/O操作交给主线程和内核处理,工作线程处理逻辑业务。
- 使用异步I/O(aio_read和aio_write)实现的Proactor模式工作流程:
- 主线程调用aio_read函数向内核
注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时候如何通知应用程序。 - 主线程继续处理其他罗i就
- 当socket上的数据被读入用户缓冲区后,内核向应用程序发送信号,通知应用程序数据以及可用。
- 选择一个工作线程处理用户请求。
- 处理完用户请求,使用aio_write函数向内核注册socket写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序。
- 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入socket之后,内核向应用程序发送一个信号,通知应用程序数据发送完毕。
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后工作,例如决定是否关闭socket。
- 主线程调用aio_read函数向内核
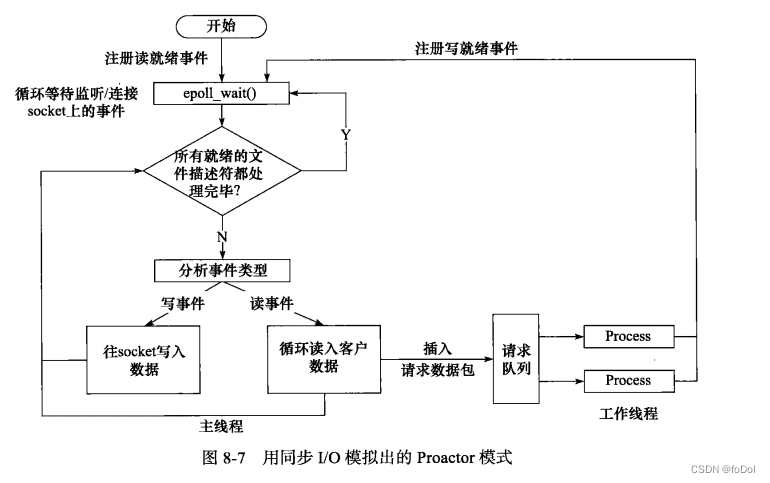
8.4.3 模拟Proactor模式
- 使用同步IO也能模拟Proactor模式,原理在于主线程执行数据读写操作,当读写完成后,主线程向工作线程通知完成事件,所以从工作线程角度看,他直接获得了数据读写的结果,只需要对结果进行逻辑处理。
- 使用同步IO(例如epoll_wait)模拟Proactor模式的工作流程如下:
- 主线程往epoll内核事件表注册socket 读就绪事件
- 主线程调用epoll_wait函数等待socket上有数据可读
- 当socket上有数据可读时,epoll_wait通知主线程,主线程从socket循环读取数据,将读取到的数据封装成请求并加入请求队列。
- 请求队列某个工作线程被唤醒,获得请求对象并处理客户请求,之后往epoll内核事件表注册socket写就绪事件、
- 主线程调用epoll_wait等待socket可写
- socket可写时,epoll_wait通知主线程,主线程往socket写入处理结果。
8.5 两种高效的并发模式
- 计算密集型,并发编程并无优势,反倒由于任务切换使得效率降低。
- I/O密集型,并发可以提高CPU利用率。
8.5.1 半同步/半异步模式
- 同步:程序按代码顺序执行
- 异步:程序执行需要事件驱动
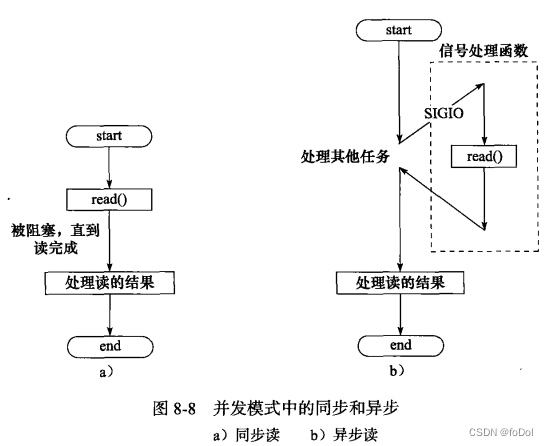
- 同步线程用于处理客户逻辑,异步线程用于处理I/O事件
8.5.1.1 半同步/半反应堆 模式
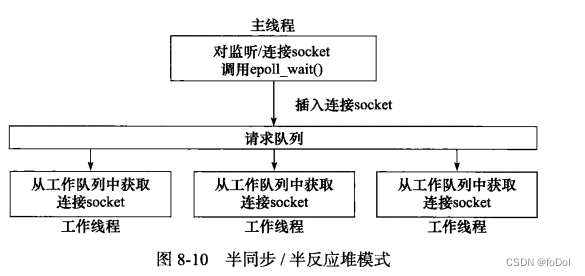
- 主线程为异步线程,负责监听socket事件
- 采用Reactor模式,工作线程自己从socket中读取客户请求,以及往socket中写入服务器应答。
- 也可以采用Proactor模式
- 缺点:
- 主线程和工作线程共享请求队列,所以主线程加任务到请求队列,或者工作线程从主线程中取出任务,都要加锁解锁。
- 工作线程只能处理一个客户请求,客户数量多而工作线程少, 客户端响应速度会降低。
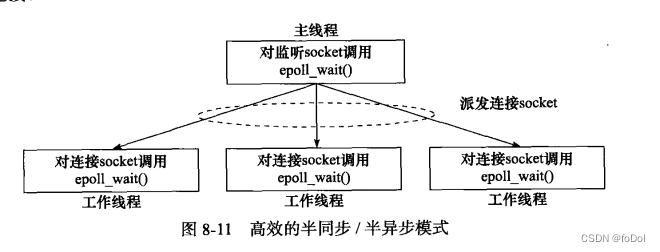
- 相对高效的半同步半异步:
- 主线程监听socket,连接socket有工作线程来处理
- 与上边的半同步半反应堆的区别在于,上边是在主线程的epoll注册事件,这个是在工作线程epoll注册事件
8.5.2 领导者/追随者模式
- 程序只有一个领导者线程,负责监听IO事件,其他线程是追随者,休眠在线程池中等待成为新的领导者。
- 如果当前领导者线程检测到IO事件,需要首先从线程池中选出新的领导者线程,如何处理IO事件,新的领导者线程等待新的IO事件,而原来的领导者则处理IO事件, 实现并发。
8.6 有限状态机
- 逻辑单元内部的高效编程方法
- 状态独立的有限状态机:状态之间没有转移

- 带状态转移的有限状态机:
- 三种状态type_A,type_B和type_C
- 状态转移是A->B->C
STATE_MACHINE(){ State cur_state = type_A; while(cur_state != type_C){ package _pack = getNewPackage(); switch(cur_state){ case type_A: process_package_state_A(_pack); cur_state = type_B; break; case type_B: process_package_state_B(_pack); cur_state = type_C; break; } } }
8.6.1 HTTP请求的读取和分析可以用有限状态转移机实现。
#include "../create_sockfd.h"
#include "stdio.h"
#include "stdlib.h"
#include "errno.h"
//读缓冲区大小,HTTP请求不能超过4096字节
#define BUFFER_SIZE 4096
//主状态机的两种可能的状态,正在分析请求行、正在分析头部字段
enum CHECK_STATE{ CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER};
//从状态机的三种可能状态,也就是读取的行的情况:完整行、行出错、行数据不完整
enum LINE_STATUS{LINE_OK = 0, LINE_BAD, LINE_OPEN};
//服务器处理HTTP请求的结果:
//NO_REQUEST表示请求不完整,需要继续读取客户数据;GET_REQUEST表示获取到了一个完整的客户请求;
//BAD_REQUEST表示客户请求有语法错误;FORBIDDEN_REQUEST表示客户对资源没有足够的访问权限;
//INTERNAL_ERROR表示服务器内部错误;CLOSE_CONNECTION表示客户端已经关闭连接
enum HTTP_CODE {NO_REQUEST = 0, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSE_CONNECTION};
//出于简化考虑,本程序没有给客户端发送完整HTTP报文,只是根据处理结果发送如下成功/失败信息。
static const char* szret[] = {"HTTP/1.1 200 OK\r\nContent-Type: text/html; charser=UTF-8\r\n\r\n", "HTTP/1.1 404 ERROR\r\n\r\n"};
//从状态机,用于解析一行的内容。buffer是需要分析的数据,checked_index指向当前正在分析的字节,read_index指向buffer中客户数据尾部的下一个字节。
//buffer中,0~check_index的数据都已经分析完毕
//一个行的分割,最后字符是"\r\n",而且'\r'后边如果不是'\n',则说明语法有误。
LINE_STATUS parse_line(char* buffer, int& checked_index, int& read_index){
char temp;
for(; checked_index < read_index; ++checked_index){
//当前分析字符
temp = buffer[checked_index];
//如果当前字符是'\r',且下一个字符是'\n'则说明是一个完整的行,如果'\r'刚好是最后一个字符,那说明这个行还不完整
//如果当前字符是'\n',且上一个字符是'\r',说明也是一个完整的行
if(temp == 'r'){
//刚好是最后一个字节,说明行不完整
if((checked_index + 1) == read_index){
return LINE_OPEN;
} else if(buffer[checked_index + 1] == '\n'){ //读到了一个完整的行,把原来字符串中的'\r\n'替换成\0\0
buffer[checked_index++] = '\0';
buffer[checked_index++] = '\0';
return LINE_OK;
}
//否则说明语法有问题.'\r'后边如果不是'\n',则说明语法有误。
return LINE_BAD;
} else if(temp == '\n'){
//为什么是>1,第0个不能是'\r'? 因为http有头部,头部不能为空
if(checked_index > 1 && buffer[checked_index - 1] == '\r') {
buffer[checked_index - 1] = '\0';
buffer[checked_index++ ] = '\0';
return LINE_OK;
}
//否则说明语法有问题.'\n'前边如果不是'\r',则说明语法有误。
return LINE_BAD;
}
}
//如果分析完了也没有遇到'\r'字符,则说明还需要继续读取数据
return LINE_OPEN;
}
//分析请求行,请求行分析完之后把CHECK_STATE转移到头部分析
//请求行结构:请求方法|'\t'或者空格|URL|'\t'或者空格|协议版本|\r\n|
HTTP_CODE parse_requestline(char *temp, CHECK_STATE& checkstate){
//strptr(s1, s2)用于s1中查找有没有s2字符串中的某个字符,有的话返回指向字符的指针,没找到返回NULL
//请求行肯定有'\t'换行符或者空格,如果没有则说明有问题
char *point = strpbrk(temp, " \t");
if(!point){
//语法有问题
return BAD_REQUEST;
}
//把'\t'字符替换成'\0'
*point++ = '\0';
//由于吧'\t'替换成了'\0',所以temp就是"GET"和"POST"
char *method = temp;
//strcasecmp(s1, s2)比对s1和s2字符串,相同返回0,s1大于s2返回大于0的值,s1小于s2返回小于0的值。
if(strcasecmp(method, "GET") == 0) {
printf("The request method is GET\n");
} else {
//只支持GET方法
return BAD_REQUEST;
}
//size_t strspn(const char *str1, const char *str2) 检索字符串 str1 中第一个不在字符串str2中出现的字符,的下标。
//这里相当于防止中间有多个\t,直接把point指到第一个不是空格或\t的地方
point += strspn(point, "\t");
//先跳过URL的分析,获取版本号
char *version = strpbrk(point, " \t");
if(!version){
//语法有问题
return BAD_REQUEST;
}
*version++ = '\0';
//这里相当于防止中间有多个\t,直接把version指到第一个不是空格或\t的地方
version += strspn(point, "\t");
//只支持HTTP/1.1
if(strcasecmp(version, "HTTP/1.1") != 0){
return BAD_REQUEST;
}
//获取URL
char *url = point;
//检查URL是否合法,url是不是以http://起头
if(strncasecmp(url, "http://", 7) == 0){
//跳过开头http://
url += 7;
//char *strchr(char *s1,char c1):从字符串s1中寻找字符c1第一次出现的位置。找到返回指针,没找到返回NULL
url = strchr(url, '/');
}
if(!url || url[0] != '/'){
return BAD_REQUEST;
}
printf("The request URL id: %s\n", url);
//HTTP请求行处理完毕,状态转移到头部字段的分析。
checkstate = CHECK_STATE_HEADER;
//因为只分析了请求行,还需要分析头部
return NO_REQUEST;
}
//分析头部字段
/*头部字段结构:
头部字段名|:|值|\t
...
头部字段名|:|值|\t
\r\n
*/
HTTP_CODE parse_headers(char *temp){
//如果第一个是\0说明已经把头部字段结构分析完成了
if(temp[0] == '\0'){
return GET_REQUEST;
}
//处理Host头部字段
if(strncasecmp(temp, "Host:", 5) == 0){
temp += 5;
//跳过中间可能存在的空格和\t
temp += strspn(temp, " \t");
printf("The request host id %s\n", temp);
} else { //其他头部字段暂时不处理
printf("Can not handle this header.\n");
}
//继续分析下一个头部
return NO_REQUEST;
}
//分析HTTP请求的入口函数
HTTP_CODE parse_content(char *buffer, int &check_index, CHECK_STATE &checkstate, int &read_index, int &start_line){
//当前行的读取状态
LINE_STATUS linestate = LINE_OK;
//记录HTTP请求处理结果
HTTP_CODE retcode = NO_REQUEST;
//主状态机,从buffer中取出所有完整的行
while((linestate = parse_line(buffer, check_index, read_index)) == LINE_OK) {
//start_line是行在buffer中的起始位置,因为有可能不是从buffer的起始位置开始分析,但是这样上边的parse_line为什么不加上?check_index的意思不就是之前的字节已经分析好了。
char *temp = buffer + start_line;
start_line = check_index;
//选择分析请求行还是头部
switch(checkstate){
//分析请求行
case CHECK_STATE_REQUESTLINE:
{
retcode = parse_requestline(temp, checkstate);
//分析请求行失败
if(retcode == BAD_REQUEST){
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER://分析头部
{
retcode = parse_headers(temp);
//获取到了GET请求
if(retcode == GET_REQUEST){
return GET_REQUEST;
}
break;
}
default://不支持其他
{
return INTERNAL_ERROR;
break;
}
}
}
//没有读取到完整的行,需要继续读取客户数据
if(linestate == LINE_OPEN){
return NO_REQUEST;
} else {
return BAD_REQUEST;
}
}
int main(int argc, char* argv[]){
if(argc <= 2){
printf("Ussage: %s ip_address port_number.\n", basename(argv[0]));
}
createSockfd sockfd(argv[1], atoi(argv[2]));
sockfd.bindSockfd();
sockfd.listenfd();
sockfd.acceptfd();
if(sockfd.connfd < 0){
printf("Accept error, errno is: %d.\n", errno);
} else {
char buffer[BUFFER_SIZE];
memset(buffer, '\0', BUFFER_SIZE);
int data_read = 0;
int read_index = 0; //当前已经读取了多少字节用户数据
int checked_index = 0; //当前已经分析了多少字节用户数据
int start_line = 0; //行在buffer中的起始位置
CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE;
//循环读取客户请求
while(1){
data_read = recv(sockfd.connfd, buffer + read_index, BUFFER_SIZE - read_index, 0);
//读取失败
if (data_read == -1){
printf("Reading failed\n");
break;
} else if(data_read == 0){ //关闭了socket连接
printf("Remote client has close the connection.\n");
break;
}
read_index += data_read;
//分析目前已经获取道德所有客户数据
HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line);
//还没完整读到一个HTTP请求
if(result == NO_REQUEST){
continue;
}
//获得了一个GET请求
else if(result == GET_REQUEST){
send(sockfd.connfd, szret[0], strlen(szret[0]), 0);
break;
}
//其他情况代表错误发生
else{
send(sockfd.connfd, szret[1], strlen(szret[1]), 0);
break;
}
}
}
return 0;
}
8.7 提高服务器性能的其他建议
8.7.1 池
- 提高服务器性能的一个直接方法,就是以空间换事件。
- 池:一组资源的集合,在服务器启动之初就被创建并初始化,也就是静态资源分配。当开始处理请求时,如果需要相关资源,直接从池中获取,无需动态分配。
- 因为分配系统资源你的系统用调用很耗时,当服务器处理完请求,可以把资源放回池里,无需动态进行资源的获取和释放,减少服务器对内核的频繁访问。
- 常见的池有:内存池、进程池和连接池。
8.7.2 数据复制
- 高性能服务器应该避免不必要的数据复制。
- 如果内核可以直接处理从socket或者文件中读入数据,程序就没必要将这些数据从内核缓冲区复制到应用程序缓冲区。
- 例如ftp,不需要直到资源具体内容,不需要复制到缓存再send发送,而是可以直接sendfile来直接发送到客户端。
8.7.3 上下文切换和锁
- 上下文切换问题:进程切换或线程切换导致的系统开销问题。
- 为一个客户连接创建一个工作线程是不可取的,一个线程应该允许处理多个客户连接。
- 如果可以,避免锁的使用。















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









