







笔记
参考
1.《R数据科学》
2. 小洁详解《R数据科学》–第十五章 向量
1.准备工作
library(tidyverse)
2.向量基础
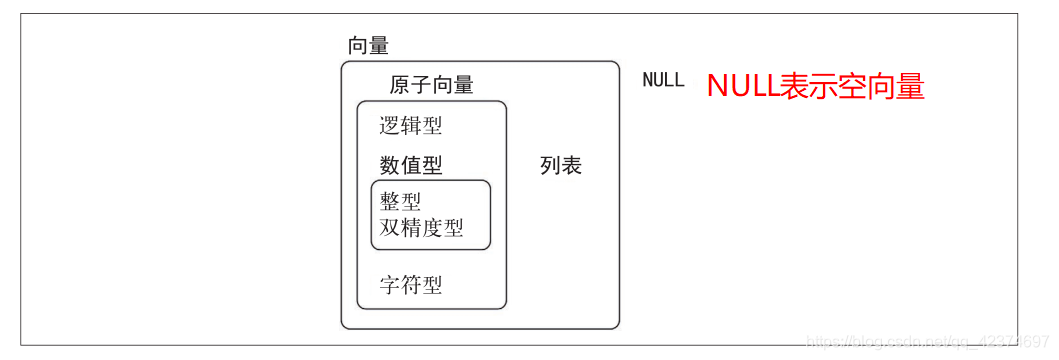
向量的类型主要有两种。
- 原子向量——c(),其共有6种类型:逻辑型、整型、双精度型、字符型、复数型和原始型。整型和双精度型向量又统称为数值型向量。
- 列表——list(),有时又称为递归向量,因为列表中也可以包含其他列表。
原子向量与列表之间的主要区别:
- 原子向量中的各个值都是同种类型的
- 列表中的各个值可以是不同类型的
每个向量都有两个关键属性。
- 类型。可以使用typeof()函数来确定向量的类型:
class(letters)
#[1] "character"
typeof(letters)
#[1] "character"
typeof(1:10)
#[1] "integer"
- 长度。可以使用length()函数来确定向量的长度:
#对列表做一个尝试,同样的几个元素用c和list分别组合,他们的长度是不同的
x <- c("a", "b", 1:10)
length(x)
#[1] 12
x2 <- list("a", "b", 1:10)
length(x2)
#[1] 3
3.重要的原子向量
4种最重要的原子向量类型是逻辑型、整型、双精度型和字符型。
3.1 逻辑型
只有 3 个可能的取值: FALSE、 TRUE 和 NA。
1:5 %% 2 == 0
# [1] FALSE TRUE FALSE TRUE FALSE
a=c(TRUE,FALSE,NA)
a
# [1] TRUE FALSE NA
3.2 数值型
整型与双精度型向量统称为数值型向量。
R默认双精度型——如果要创建整数型数值,可以在数字后面加一个 L
typeof(1)#默认是双精度型
#[1] "double"
typeof(1L)#指定为整型
#[1] "integer"
### 整型和双精度型之间的区别
1.双精度型是近似值,双精度型表示的是浮点数,不能由固定数量的内存精确表示。
sqrt(2) ^ 2
# [1] 2
sqrt(2)^2 - 2
# [1] 4.440892e-16
在处理浮点数时,这种现象非常普遍:多数计算都包括一些近似误差。
在比较浮点数时,不能使用==,而应该使用dplyr::near(),这可以容忍一些数据误差。
dplyr::near(sqrt(2)^2,2)
#[1] TRUE
2.特殊值
整形数据有1一个特殊值NA(空值)
双精度型数据有4个特殊值: NA、 NaN(非数字)、 Inf(正无穷) 和 -Inf(负无穷)
C(-1,0,1)/0
#[1]-Inf NaN Inf
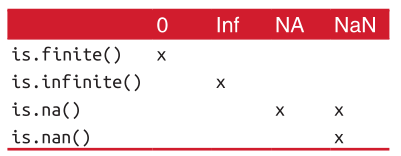
不要使用==来检查这些特殊值,而是用is.finite()、 is.infinite() 和is.nan()鉴定这些特殊值类型。
1.is_infinite 判断是否为无限值
> is.infinite(3/0)
#[1] TRUE
2.is_nan -- 判断是否为合法数值
> is.nan(0/0)
#[1] TRUE
3.is_finite 判断是否为有限值
> is.finite(1/9999999999)
#[1] TRUE
3.3 字符型
R使用的是全局字符串池。
R对每个唯一的字符串只保存一次,节省内存。
3.4 缺失值
每种类型的原子向量都有自己的缺失值:
NA有多种类型
1.逻辑型
NA
#> [1] NA
2.整形
NA_integer_
#> [1] NA
3.双精度型
NA_real_
#> [1] NA
3.字符型
NA_character_
#> [1] NA
4.使用原子向量
如何将一种原子向量转换为另一种,以及何时系统会自动转换。
4.1 强制转换
将一种类型的向量强制转换成另一种类型的方式有两种。
- 显式转换
as.logical()、 as.integer()、 as.double() 、 as.character()、 - 隐式转换
在数值环境中使用逻辑向量,TRUE 转换为 1, FALSE 转换为 0。
意味着对逻辑向量求和的结果就是其中真值的个数,逻辑向量的均值就是其中真值的比例:
所以sum成了计数,mean成了比例!
x<-sample(20,100,replace=TRUE)
大于10的数有多少个?
sum(x>18)
# [1] 10
大于10的数的比例是多少?
mean(x>18)
# [1] 0.1
用c()将两种不同类型的元素放到一起,转换为最复杂的元素类型。
x <- c("a", 1.5, 1:10)
typeof(x)
#> [1] "character"
typeof(c(TRUE, 1L))
#> [1] "integer"
typeof(c(1L, 1.5))
#> [1] "double"
typeof(c(1.5, "a"))
#> [1] "character"
原子向量中不能包含不同类型的元素,因为类型是整个向量的一种属性,不是其中单个元素的属性。
如果需要在同一个向量中包含混合类型的元素,那么就需要使用列表。
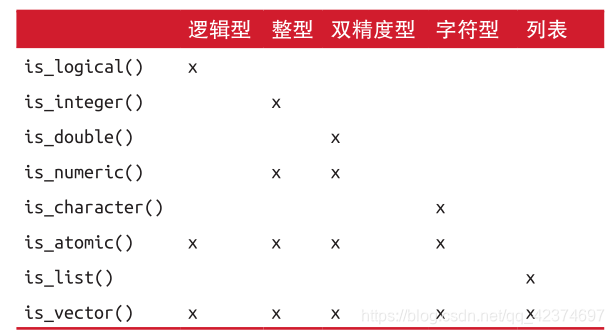
4.2 检验函数
4.3 标量与循环规则
向量循环–对向量长度进行强制转换。
R会将较短的向量重复(或称循环)到与较长的向量相同的长度。
> sample(10)+100
[1] 103 108 106 104 102 101 109 107 110 105
> runif(10)>0.5
[1] FALSE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE
如果两个长度不同的向量相加,R会自动扩展较短的向量,使其与较长的向量一样长,这个过程就称作向量循环
> 1:6 + 1:2
# [1] 2 4 4 6 6 8
除非较长向量的长度不是较短向量长度的整数倍:
1:5 + 1:2
# [1] 2 4 4 6 6
# Warning message:
# In 1:5 + 1:2 :
# longer object length is not a multiple of shorter object length
向量循环在tibble中则会直接报错,需要手动rep。
rep有两个用法:times和each。默认是times。
tibble(x = 1:4, y = rep(1:2, times = 2))#times不写也一样的。
#> # A tibble: 4 x 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 2
#> 3 3 1
#> 4 4 2
tibble(x = 1:4, y = rep(1:2, each = 2))
#> # A tibble: 4 x 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 1
#> 3 3 2
#> 4 4 2
4.4 向量命名
可以在使用c()函数创建向量时进行命名:
c(x = 1, y = 2, z = 4)
#> x y z
#> 1 2 4
也可以在向量创建完成后,使用purrr::set_names()函数来命名:
set_names(1:3, c("a", "b", "c"))
#> a b c
#> 1 2 3
4.5 向量取子集
- 按位置提取
x <- c("one", "two", "three", "four", "five")
x[c(3, 2, 5)]#按照位置提取
#> [1] "three" "two" "five"
x[c(1, 1, 5, 5, 5, 2)]#竟然可以重复
#> [1] "one" "one" "five" "five" "five" "two"
x[c(-1, -3, -5)]#除了某几个
#> [1] "two" "four"
x[c(1, -1)] 不可以正负混合
- 用逻辑向量取子集
x <- c(1,NA,5,NA,10)
x[!is.na(x)]#x中的所有非缺失值
# [1] 1 5 10
x[x %% 2 == 0]#偶数和缺失值
# [1] NA NA 10
- 按名字取
x=c(a=1,b=2,c=3)
x[c("c","b")]
# c b
# 3 2
[ 有一个重要的变体 [[
[[ 从来都是只提取单个元素,并丢弃名称。当想明确表明需要提取单个元素时,就应该使用[[
比如在一个for循环中。[ 和 [[ 的区别对于列表来说更加重要
5.递归向量
可以用list()创建列表
创建原子向量-c()
x <- c(1, 2, 3)
# [1] 1 2 3
创建列表 list()
x <- list(1, 2, 3)
# [[1]]
# [1] 1
#
# [[2]]
# [1] 2
#
# [[3]]
# [1] 3
查看列表结构
str(x)
#> List of 3
#> $ : num 1
#> $ : num 2
#> $ : num 3
命名列表
x <- list(a=1,b=2,c=3)
# $a
# [1] 1
#
# $b
# [1] 2
#
# $c
# [1] 3
与原子向量不同,list()中可以包含不同类型的对象:
> y<-list("a",1L,1.5,TRUE)
> str(y)
List of 4
$ : chr "a"
$ : int 1
$ : num 1.5
$ : logi TRUE
列表中还可以多个嵌套列表
> z<-list(list(1,2),list(3,4))
[[1]]
[[1]][[1]]
[1] 1
[[1]][[2]]
[1] 2
[[2]]
[[2]][[1]]
[1] 3
[[2]][[2]]
[1] 4
> str(z)
List of 2
$ :List of 2
..$ : num 1
..$ : num 2
$ :List of 2
..$ : num 3
..$ : num 4
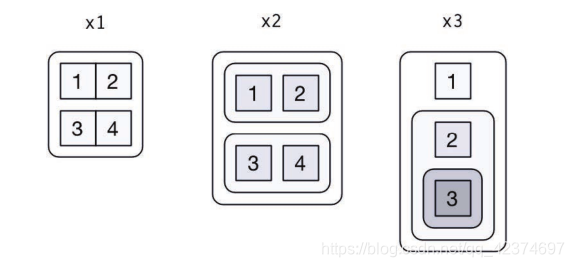
5.1 列表可视化
x1<-list(c(1,2),c(3,4))
x2<-list(list(1,2),list(3,4))
×3<-list(1,list(2,list(3)))
5.2 列表取子集
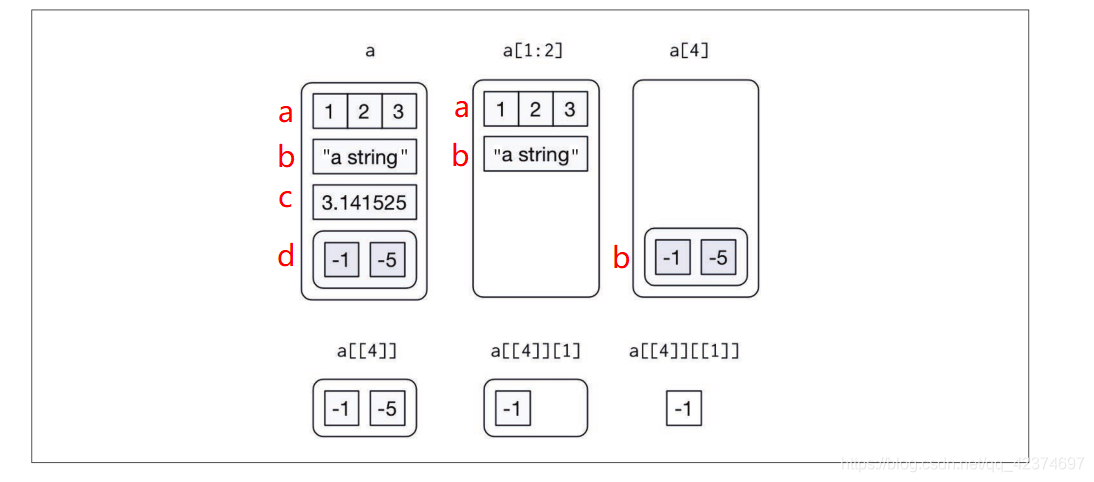
a <- list(a = 1:3, b = "a string", c = pi, d = list(-1, -5))
# $a
# [1] 1 2 3
#
# $b
# [1] "a string"
#
# $c
# [1] 3.141593
#
# $d
# $d[[1]]
# [1] -1
#
# $d[[2]]
# [1] -5
- 用[ 提取子列表
a[1]
# $a
# [1] 1 2 3
a[1:2]
# $a
# [1] 1 2 3
#
# $b
# [1] "a string"
str(a[1:2])
#> List of 2
#> $ a: int [1:3] 1 2 3
#> $ b: chr "a string"
str(a[4])
#> List of 1
#> $ d:List of 2
#> ..$ : num -1
#> ..$ : num -5
- [[]] 从列表中提取单个元素。这种方式会从列表中删除一个层次等# 1.准备工作
library(tidyverse)
2.向量基础
向量的类型主要有两种。
- 原子向量——c(),其共有6种类型:逻辑型、整型、双精度型、字符型、复数型和原始型。整型和双精度型向量又统称为数值型向量。
- 列表——list(),有时又称为递归向量,因为列表中也可以包含其他列表。
原子向量与列表之间的主要区别:
- 原子向量中的各个值都是同种类型的
- 列表中的各个值可以是不同类型的
0
每个向量都有两个关键属性。
- 类型。可以使用typeof()函数来确定向量的类型:
class(letters)
#[1] "character"
typeof(letters)
#[1] "character"
typeof(1:10)
#[1] "integer"
- 长度。可以使用length()函数来确定向量的长度:
#对列表做一个尝试,同样的几个元素用c和list分别组合,他们的长度是不同的
x <- c("a", "b", 1:10)
length(x)
#[1] 12
x2 <- list("a", "b", 1:10)
length(x2)
#[1] 3
3.重要的原子向量
4种最重要的原子向量类型是逻辑型、整型、双精度型和字符型。
3.1 逻辑型
只有 3 个可能的取值: FALSE、 TRUE 和 NA。
1:5 %% 2 == 0
# [1] FALSE TRUE FALSE TRUE FALSE
a=c(TRUE,FALSE,NA)
a
# [1] TRUE FALSE NA
3.2 数值型
整型与双精度型向量统称为数值型向量。
R默认双精度型——如果要创建整数型数值,可以在数字后面加一个 L
typeof(1)#默认是双精度型
#[1] "double"
typeof(1L)#指定为整型
#[1] "integer"
### 整型和双精度型之间的区别
1.双精度型是近似值,双精度型表示的是浮点数,不能由固定数量的内存精确表示。
sqrt(2) ^ 2
# [1] 2
sqrt(2)^2 - 2
# [1] 4.440892e-16
在处理浮点数时,这种现象非常普遍:多数计算都包括一些近似误差。
在比较浮点数时,不能使用==,而应该使用dplyr::near(),这可以容忍一些数据误差。
dplyr::near(sqrt(2)^2,2)
#[1] TRUE
2.特殊值
整形数据有1一个特殊值NA(空值)
双精度型数据有4个特殊值: NA、 NaN(非数字)、 Inf(正无穷) 和 -Inf(负无穷)
C(-1,0,1)/0
#[1]-Inf NaN Inf
不要使用==来检查这些特殊值,而是用is.finite()、 is.infinite() 和is.nan()鉴定这些特殊值类型。
1.is_infinite 判断是否为无限值
> is.infinite(3/0)
#[1] TRUE
2.is_nan -- 判断是否为合法数值
> is.nan(0/0)
#[1] TRUE
3.is_finite 判断是否为有限值
> is.finite(1/9999999999)
#[1] TRUE
1
3.3 字符型
R使用的是全局字符串池。
R对每个唯一的字符串只保存一次,节省内存。
3.4 缺失值
每种类型的原子向量都有自己的缺失值:
NA有多种类型
1.逻辑型
NA
#> [1] NA
2.整形
NA_integer_
#> [1] NA
3.双精度型
NA_real_
#> [1] NA
3.字符型
NA_character_
#> [1] NA
4.使用原子向量
如何将一种原子向量转换为另一种,以及何时系统会自动转换。
4.1 强制转换
将一种类型的向量强制转换成另一种类型的方式有两种。
- 显式转换
as.logical()、 as.integer()、 as.double() 、 as.character()、 - 隐式转换
在数值环境中使用逻辑向量,TRUE 转换为 1, FALSE 转换为 0。
意味着对逻辑向量求和的结果就是其中真值的个数,逻辑向量的均值就是其中真值的比例:
所以sum成了计数,mean成了比例!
x<-sample(20,100,replace=TRUE)
大于10的数有多少个?
sum(x>18)
# [1] 10
大于10的数的比例是多少?
mean(x>18)
# [1] 0.1
用c()将两种不同类型的元素放到一起,转换为最复杂的元素类型。
x <- c("a", 1.5, 1:10)
typeof(x)
#> [1] "character"
typeof(c(TRUE, 1L))
#> [1] "integer"
typeof(c(1L, 1.5))
#> [1] "double"
typeof(c(1.5, "a"))
#> [1] "character"
原子向量中不能包含不同类型的元素,因为类型是整个向量的一种属性,不是其中单个元素的属性。
如果需要在同一个向量中包含混合类型的元素,那么就需要使用列表。
4.2 检验函数
2
4.3 标量与循环规则
向量循环–对向量长度进行强制转换。
R会将较短的向量重复(或称循环)到与较长的向量相同的长度。
> sample(10)+100
[1] 103 108 106 104 102 101 109 107 110 105
> runif(10)>0.5
[1] FALSE TRUE TRUE TRUE FALSE FALSE FALSE TRUE FALSE FALSE
如果两个长度不同的向量相加,R会自动扩展较短的向量,使其与较长的向量一样长,这个过程就称作向量循环
> 1:6 + 1:2
# [1] 2 4 4 6 6 8
除非较长向量的长度不是较短向量长度的整数倍:
> 1:5 + 1:2
# [1] 2 4 4 6 6
# Warning message:
# In 1:5 + 1:2 :
# longer object length is not a multiple of shorter object length
向量循环在tibble中则会直接报错,需要手动rep。
rep有两个用法:times和each。默认是times。
tibble(x = 1:4, y = rep(1:2, times = 2))#times不写也一样的。
#> # A tibble: 4 x 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 2
#> 3 3 1
#> 4 4 2
tibble(x = 1:4, y = rep(1:2, each = 2))
#> # A tibble: 4 x 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 1
#> 3 3 2
#> 4 4 2
4.4 向量命名
可以在使用c()函数创建向量时进行命名:
c(x = 1, y = 2, z = 4)
#> x y z
#> 1 2 4
也可以在向量创建完成后,使用purrr::set_names()函数来命名:
set_names(1:3, c("a", "b", "c"))
#> a b c
#> 1 2 3
4.5 向量取子集
- 按位置提取
x <- c("one", "two", "three", "four", "five")
x[c(3, 2, 5)]#按照位置提取
#> [1] "three" "two" "five"
x[c(1, 1, 5, 5, 5, 2)]#竟然可以重复
#> [1] "one" "one" "five" "five" "five" "two"
x[c(-1, -3, -5)]#除了某几个
#> [1] "two" "four"
x[c(1, -1)] 不可以正负混合
- 用逻辑向量取子集
x <- c(1,NA,5,NA,10)
x[!is.na(x)]#x中的所有非缺失值
# [1] 1 5 10
x[x %% 2 == 0]#偶数和缺失值
# [1] NA NA 10
3.按名字取
x=c(a=1,b=2,c=3)
x[c("c","b")]
# c b
# 3 2
[ 有一个重要的变体[[。
[[从来都是只提取单个元素,并丢弃名称。当想明确表明需要提取单个元素时,就应该使用[[
比如在一个for循环中。[和[[的区别对于列表来说更加重要
5.递归向量
可以用list()创建列表
创建原子向量-c()
x <- c(1, 2, 3)
# [1] 1 2 3
创建列表 list()
x <- list(1, 2, 3)
# [[1]]
# [1] 1
#
# [[2]]
# [1] 2
#
# [[3]]
# [1] 3
查看列表结构
str(x)
#> List of 3
#> $ : num 1
#> $ : num 2
#> $ : num 3
命名列表
x <- list(a=1,b=2,c=3)
# $a
# [1] 1
#
# $b
# [1] 2
#
# $c
# [1] 3
与原子向量不同,list()中可以包含不同类型的对象:
> y<-list("a",1L,1.5,TRUE)
> str(y)
List of 4
$ : chr "a"
$ : int 1
$ : num 1.5
$ : logi TRUE
列表中还可以多个嵌套列表
> z<-list(list(1,2),list(3,4))
[[1]]
[[1]][[1]]
[1] 1
[[1]][[2]]
[1] 2
[[2]]
[[2]][[1]]
[1] 3
[[2]][[2]]
[1] 4
> str(z)
List of 2
$ :List of 2
..$ : num 1
..$ : num 2
$ :List of 2
..$ : num 3
..$ : num 4
5.1 列表可视化
x1<-list(c(1,2),c(3,4))
x2<-list(list(1,2),list(3,4))
×3<-list(1,list(2,list(3)))
3
5.2 列表取子集
a <- list(a = 1:3, b = "a string", c = pi, d = list(-1, -5))
# $a
# [1] 1 2 3
#
# $b
# [1] "a string"
#
# $c
# [1] 3.141593
#
# $d
# $d[[1]]
# [1] -1
#
# $d[[2]]
# [1] -5
- [] 提取子列表
a[1]
# $a
# [1] 1 2 3
a[1:2]
# $a
# [1] 1 2 3
#
# $b
# [1] "a string"
str(a[1:2])
#> List of 2
#> $ a: int [1:3] 1 2 3
#> $ b: chr "a string"
str(a[4])
#> List of 1
#> $ d:List of 2
#> ..$ : num -1
#> ..$ : num -5
- [[]] 从列表中提取单个元素。这种方式会从列表中删除一个层次等级
> a[1]
# $a
# [1] 1 2 3
> a[[3]]
# [1] 3.141593
> a["c"]
# $c
# [1] 3.141593
> a[["c"]]
# [1] 3.141593
或者 $ 提取元素
a$c
# [1] 3.141593
[ 和 [[ 之间的区别非常重要,但二者很容易混淆
对于列表来说,[和[[之间的区别是非常重要的,因为[[会使列表降低一个层级,而
[则会返回一个新的、更小的列表。
记住 [[]] 会降低层级!!!
[[]][[]] 这个层级中里面的元素
4
6 特性
任何向量都可以通过其特性来附加任意元数据。
可以将特性看作可以附加在任何对象上的一个向量命名列表。
可以使用attr()函数来读取和设置单个特性值,也可以使用attributes()函数同时查看所有特性值:
x <- 1:10
attr(x, "greeting") <- "Hi!"
attr(x, "farewell") <- "Bye!"
attributes(x)
#$greeting
#[1] "Hi!"
#>
#$farewell
#[1] "Bye!"
- 名称:用于命名向量元素。
- 维度:使得向量可以像矩阵或数组那样操作。
- 类:用于实现面向对象的S3系统。
y <- c(1,3,5)
attr(y,"names") <- c("a","b","c")
y
#a b c
#1 3 5
这就是命名操作,和之前讲的效果一样
set_names(c(1,3,5),c("a","b","c"))
#a b c
#1 3 5
7.扩展向量
(1)因子
x <- factor(c("ab", "cd", "ab"), levels = c("ab", "cd", "ef"))
typeof(x)
#[1] "integer"
class(x)
#[1] "factor"
attributes(x)#不仅能展示levels还能展示class
#$levels
#[1] "ab" "cd" "ef"
#
#$class
#[1] "factor"
(2)tibble
tibble 是扩展的列表,有 3 个class: tbl_df、 tbl 和 data.frame。它的特性有 2 个:(列)
names 和 row.names。
tb <- tibble::tibble(x = 1:5, y = 5:1)
typeof(tb)
#> [1] "list"
> a[1]
# $a
# [1] 1 2 3
> a[[3]]
# [1] 3.141593
> a["c"]
# $c
# [1] 3.141593
> a[["c"]]
# [1] 3.141593
级或者 $ 提取元素
a$c
# [1] 3.141593
== [ 和 [[ 之间的区别非常重要,但二者很容易混淆==
对于列表来说,[和[[之间的区别是非常重要的,因为[[会使列表降低一个层级,而
[则会返回一个新的、更小的列表。
记住 [[]] 会降低层级!!!
[[]][[]] 这个层级中里面的元素
6 特性
任何向量都可以通过其特性来附加任意元数据。
可以将特性看作可以附加在任何对象上的一个向量命名列表。
可以使用attr()函数来读取和设置单个特性值,也可以使用attributes()函数同时查看所有特性值:
x <- 1:10
attr(x, "greeting") <- "Hi!"
attr(x, "farewell") <- "Bye!"
attributes(x)
#$greeting
#[1] "Hi!"
#>
#$farewell
#[1] "Bye!"
- 名称:用于命名向量元素。
- 维度:使得向量可以像矩阵或数组那样操作。
- 类:用于实现面向对象的S3系统。
y <- c(1,3,5)
attr(y,"names") <- c("a","b","c")
y
#a b c
#1 3 5
这就是命名操作,和之前讲的效果一样
set_names(c(1,3,5),c("a","b","c"))
#a b c
#1 3 5
7.扩展向量
(1)因子
x <- factor(c("ab", "cd", "ab"), levels = c("ab", "cd", "ef"))
typeof(x)
#[1] "integer"
class(x)
#[1] "factor"
attributes(x)#不仅能展示levels还能展示class
#$levels
#[1] "ab" "cd" "ef"
#
#$class
#[1] "factor"
(2)tibble
tibble 是扩展的列表,有 3 个class: tbl_df、 tbl 和 data.frame。它的特性有 2 个:(列)
names 和 row.names。
tb <- tibble::tibble(x = 1:5, y = 5:1)
typeof(tb)
#> [1] "list"


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









