







最近在看大佬们的文章时,被许多python自动化办公的文章吸引,联想到自己平时的需求,尤其是前段时间做的体育健康测试数据分析,如果不会自动化编程,很难在对方规定的时间完成任务,所以对于这块真是深有感触
不得不说,在面对批量操作文件时,自动化办公能够大大的提高工作效率!
参考文章:上班摸鱼,先从批量处理 word 文档开始 !『附源码和数据集』
文章原来源:小张Python
文章原作者:zeroing
原文写的很详细,可以移步学习
批量读取word表格内容,并整理到excel文件
处理背景如下,公司现有许多员工的出差申请表,需要将所有人的出差申请汇总到一张excel表中。
这里以4个文件为例
每个文件内容结构都一样
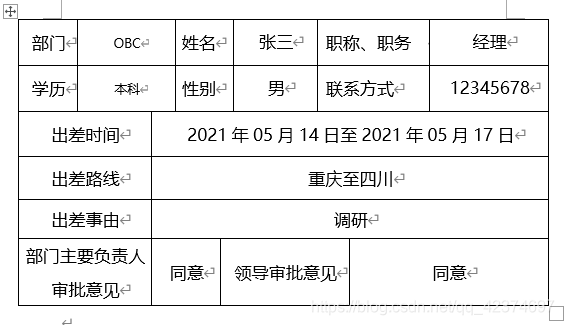

处理最终结果如下

结果均保存在word文件夹下
代码
import docx
import pandas as pd
import os
from win32com import client as wc
from openpyxl import load_workbook
def GetDesktopPath():
"""
获取桌面
-------
TYPE
DESCRIPTION.
"""
return os.path.join(os.path.expanduser("~"), 'Desktop')
DesktopPath = GetDesktopPath()+'\\'
def convertdoc_docx(path):
"""
doc 转化为 docx
@param path:
@return:
"""
path_list = os.listdir(path)
doc_list = [os.path.join(path, str(i)) for i in path_list if str(i).endswith('doc')]
word = wc.Dispatch('Word.Application')
for path in doc_list:
#print(path)
save_path = str(path).replace('doc', 'docx')
doc = word.Documents.Open(path)
doc.SaveAs(save_path, 12, False, "", True, "", False, False, False, False)
doc.Close()
#print('{} Save sucessfully '.format(save_path))
word.Quit()
def get_data_from_path(doc_path):
'''
获取数据
Generate Data form doc_path of word path
:param doc_path:
:return: col_keys 列键;
col_values 列名;
'''
document = docx.Document(doc_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 添加一个去重机制
fore_str = ''
for table in document.tables:
for row_index, row in enumerate(table.rows):
for col_index, cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
# 完整展身份证号码、电话号码等
col_values[5] = '\t'+col_values[5]
#print(f'col keys is {col_keys}')
#print(f'col values is {col_values}')
return col_keys, col_values
if __name__ == '__main__':
#注意你的路径
word_paths = os.getcwd() # 'C:\\Users\\ABC\\Desktop\\word'
convertdoc_docx(os.path.join(os.getcwd(), word_paths))
wordlist_path = [os.path.join(word_paths, i) for i in os.listdir(word_paths) if str(i).endswith('.docx')]
data_list = []
columns_list = []
for index, single_path in enumerate(wordlist_path):
col_names, col_values = get_data_from_path(single_path)
if index == 0:
columns_list.append(col_names)
#print(columns_list)
data_list.append(col_values)
else:
data_list.append(col_values)
# 输出
df_data = pd.DataFrame(data_list, columns=columns_list[0])
df_data.to_excel('result.xlsx',index=False)
wb = load_workbook('result.xlsx')
ws = wb[wb.sheetnames[0]] # 打开第一个sheet
ws.column_dimensions['F'].width = 20.0 # 调整列整1宽
ws.column_dimensions['G'].width = 30.0 # 调整列整1宽
ws.column_dimensions['H'].width = 20.0 # 调整列整1宽
ws.column_dimensions['j'].width = 30.0 # 调整列整1宽
ws.column_dimensions['K'].width = 20.0 # 调整列整1宽
#ws.row_dimensions[1].height = 40 # 调整行1高
wb.save('result.xlsx')
关于docx 的安装
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com docx
如果按照上面代码安装,会报如下的错误
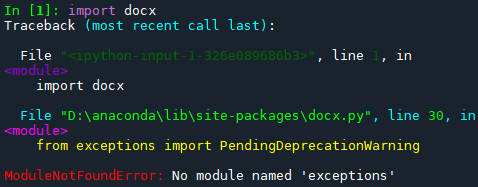
在网上找的方法,说是可以通过离线安装
在这个网站https://www.lfd.uci.edu/~gohlke/pythonlibs/下载好 python_docx-0.8.10-py2.py3-none-any.whl 这个文件,然后在cmd或者Anaconda Prompt中输入pip install 再把这个whl文件按住拖动到pip install 后面,回车安装。
看到有人在找包时,也很疑惑,直接ctrl+F查找即可

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









