







redis
- redis主要数据结构,比如简单动态字符串,双端链表,字典,压缩列表,整数集合.然而redis并没有直接使用这些数据来实现键值对的数据库,而是在这些数据结构之上包装了一层RedisObject(对象),RedisObject有五种对象:字符串对象,哈希对象,列表对象,集合对象和有序集合对象.
- RedisObject源码(C语言)如下:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
1. redisObject各字段的含义:
1) type:
- type记录了对象的类型;对于Redis数据库保存的键值对来说,键一定是一个字符串对象,而值则可以是五种对象的任意一种.

2) encoding:
- encoding表示ptr(指针)指向的具体数据结构,即这个对象使用了什么数据结构作为底层实现.
- encoding的取值范围如下:

- 对象和编码的对应关系(每种类型的对象都至少使用了两种不同的编码)如下:

- 对象和编码的对应关系(每种类型的对象都至少使用了两种不同的编码)如下:
3) lru:
- 表示对象最后一次被命令程序访问的时间.
4) refcount:
- refcount表示引用计数,由于C语言并不具备内存回收功能,所以Redis在自己的对象系统中添加了这个属性,当一个对象的引用计数为0时,则表示该对象已经不被任何对象引用,则可以进行垃圾回收了.
5) ptr指针:
- 指向对象的底层实现数据结构.
2.String类型在redis内部结构分:
1). 整数,存储字符串长度小于21且可以转化为整数的字符串.
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型标识,那么字符串对象会讲整数值保存在 ptr 属性中,并将 encoding 设置为 int。
假设有如下命令:set number 10086。那么 number 键对象的示意图如下:

2). SDS(简单动态字符串-Simple Dynamic String);
- 二进制安全:C/java字符串以’\0’来标识字符串结束(遇零为止),不可以保存图片,视频等二进制文件.而SDS中判断是否到达字符串结尾的依据是SDS中的len属性来决定的.
- SDS转内部结构存储(redis字符串两种存储方式),分为embstr(嵌入式字符串-Embedded String)和raw两种存储方式.
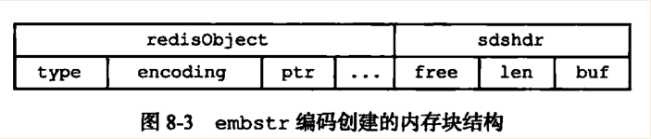
embstr(Embedded-String):可以存储的最大字符串长度是44字节.
- embstr存储形式: RedisObject和SDS内存地址是连续的
- 如果字符串对象保存的是一个字符串值,并且这个字符串的长度 <= 44字节(redis3.2版本之后),那么字符串对象将使用embstr编码的方式来保存这个字符串.
- 使用 embstr 存储字符串的示意图(redis3.2版本以前)如下:
raw:存储字符串长度超过44字节的都采用raw方式存储.
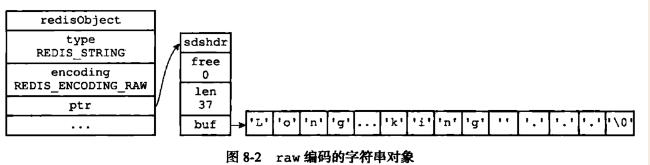
- raw存储形式:RedisObject和SDS内存地址是不连续的
- 如果字符串对象保存的是一个字符串值,并且这个字符串长度 >= 44字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的encoding设置为raw.
- 使用raw存储字符串的示意图(redis3.2版本以前)如下:
embstr编码方式 存储的优势:
- embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次.
- 释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数.
- 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里,所以这种编码的字符串对象比起raw,embstr编码的字符串对象能够更好的利用缓存带来的优势.
SDS(redis3.2版本之前)定义:

SDS(redis3.2版本之后)定义:

- len 表示sds字符串的长度
- alloc 表示buf指针分配空间的大小(不包括header和最后的空终止字符)
- flags 表示当前sds类型(0 : sdshdr5, 1 : sdshdr8, 2 : sdshdr16, 3 : sdshdr32, 4 : sdshdr64)

- buf[] 表示sds实际存放的数据
3.list类型在redis内部结构
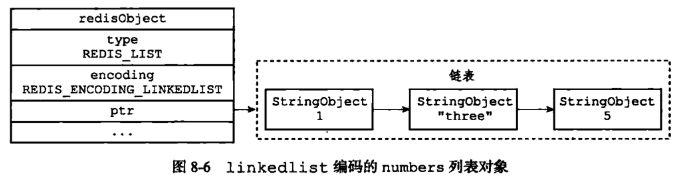
1). 由LinkedList(双向链表)和ZipList(压缩列表)组成(3.2版本之前)
- ZipList 主要是为节省内存而设计的内存结构,它的优点就是节省内存,但缺点就是比其他结构要消耗更多的时间,所以Redis在数据量小的时候使用压缩列表存储.
- 当列表的长度(size)小于512,并且所有元素的长度都小于64字节时,使用压缩列表存储;否则使用LinkedList存储.
- 压缩列表对应示意图(redis3.2版本之前):

ZipList(压缩列表)详细解释:请点击这里 - 链表对应示意图(redis3.2版本之前):
2). 由QuickList构成(3.2版本之后)
QuickList 基本结构:quickList是 zipList 和 linkedList 的混合体, 它将linkedList 按段切分, 每一段使用 zipList 来紧凑存储, 多个zipList之间使用双向指针串接起来.

// 快速列表
typedef struct quicklist {
/* 整个链表的头部节点 */
quicklistNode *head;
/* 整个链表的尾部节点 */
quicklistNode *tail;
/* 整个链表中的所有的entry的数量 */
unsigned long count;
/* quicklistNode的数量 */
unsigned int len;
/* 保存ziplist的大小,配置文件设定,占16bits
* ziplist 的长度由配置参数 list-max-ziplist-size 决定。
*/
int fill : 16;
/* 保存压缩程度值,配置文件设定,占16bits,0表示不压缩
* 存放list-compress-depth参数的值
*/
unsigned int compress : 16;
} quicklist;
// 快速列表节点
typedef struct quicklistNode {
/* 指向前面的quicklistNode */
struct quicklistNode *prev;
/* 指向后面的quicklistNode */
struct quicklistNode *next;
/* 如果对数据进行压缩,zl指向ziplist;
* 如果不对数据进行压缩,zl指向quicklistLZF
*/
unsigned char *zl;
/* zl指向的ziplist的总大小(包括zlbytes,zltail,zllen,zlend和各个entry的长度之和);
* 如果ziplist被压缩了,那么这个sz值仍然是表示压缩前的ziplist的大小;
* ziplist没有被压缩时,sz表示的就是ziplist占据的字节数
*/
unsigned int sz;
/* ziplist内部entry的个数 */
unsigned int count : 16;
/* 是否可以对ziplist的压缩;
* encoding = QUICKLIST_NODE_ENCODING_LZF,表示可以压缩;
* encoding = QUICKLIST_NODE_ENCODING_RAW, 表示不压缩;
*/
unsigned int encoding : 2;
/* quicklistNode是否作为一个容器使用;
* 如果quicklistNode不作为容器使用,container = QUICKLIST_NODE_CONTAINER_NONE;
* 如果quicklistNode作为容器使用, container = QUICKLIST_NODE_CONTAINER_ZIPLIST;
* 设计quicklist的目的就是为了避免单独使用adlist和ziplist,所以quicklistNode一般
* 用作容器,指向一个包含少量entry的ziplist或者是quicklistLZF
*/
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
/* 当使用lindex这样的命令查看某一项本来压缩的数据的时候,需要把数据暂时解压,
* 这时就设置recompress=1做一个标记,等有机会再把数据进行压缩
*/
unsigned int recompress : 1;
/* 只用于redis的自动化测试 */
unsigned int attempted_compress : 1;
unsigned int extra : 10;
} quicklistNode;
............
quickList(快速列表)详细解释::请点击这里
4.hash类型在redis内部结构
redis的哈希对象的底层存储使用两种数据结构:ziplist(压缩列表)和hashtable.当hash对象可以同时满足以下两个条件时,hash对象使用ziplist编码.
- 1.hash对象保存的所有键值对的键和值得字符串长度都小于64字节.
- 2.hash对象保存的键值对数量小于512个
1.hashTable结构:

hashtable中是有两个存储桶(hash桶):ht[0] 和 ht[1]; h[0]正常情况下使用,h[1]扩容/收缩的时候使用.
- rehash操作过程:
1). 为ht[1]哈希表分配空间,让字典同时持有ht[0]和ht[1]两个哈希表.(ht[1]空间大小取决于要执行的操作,以及ht[0]当前包含的键值对的数量). 扩展 : ht[1]的大小等于ht[0].used(已使用桶数量)*2; 收缩 : ht[1]的大小等于ht[0].used(已使用桶数量)/2
2). 在字典中维持一个索引计数器变量rehashidx, 并将它的值设置为0,表示rehash工作正式开始.
3). 在rehash进行期间,每次对字典执行添加/删除/查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到h[1]上,当rehash工作完成之后,程序将rehashidx属性的值增一.(表示下次将rehash下一个键值对)
4). 随着字典操作的不断执行,最终在某个时间点上, ht[0]的所有键值对都会被rehash至ht[1], 这时程序将rehashidx属性的值设为-1, 表示rehash所有操作已经完成.
5). 当ht[0]全部迁移到ht[1]之后,释放ht[0],将ht[1]设置为ht[0]表,并将创建新的ht[1],为下次rehash做准备. - 扩容条件:
负载因子 = 哈希表保存的key的数量 / 哈希表的大小
1).当前哈希表中保存的key的数量超过了哈希表的大小size,并且redis服务当前允许执行rehash(指的是当前没有子进程在执行AOF文件重写或者生成RDB文件的 持久化操作).
2).或者保存的节点数与哈希表的大小的比例超过了安全阀值(默认5).
即,当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
1).服务器目前没有在执行bgSave命令(快照)或者bgRewriteAOF命令(aof文件重写),并且哈希表的负载因子>=1;
2).服务器目前正在执行bgSave命令(快照)或者bgRewriteAOF命令(aof文件重写),并且哈希表的负载因子>=5;
如果程序正在进行持久化, 这个时候进行rehash会导致数据不一致. - 缩容条件: 元素个数低于数组长度的10%.缩容不会考虑redis是否正在做bgsave.
2. ziplist结构:

每个key/value存储结果中key用一个zipEntry存储,value用一个zipEntry存储.
5.set类型在redis内部结构
redis的set对象的底层存储使用两种数据结构:intset和hashtable.
- intset整数集合: 主要是为节省内存而设计的内存结构,优点就是节省内存, 但缺点就是比其他结构要消耗更多的时间,所以redis在数据量小的时候使用整数集合存储.(当集合的长度小于512,并且所有元素都是整数时,使用整数集合存储,否则使用hashtable存储)

6.zset类型在redis内部结构
redis的zset对象的底层存储使用两种数据结构:ziplist 和 (skiplist/跳表 + hashtable/dict).
- ziplist: 同时满足以下条件时,使用ziplist编码
1). 元素个数小于128个;
2). 所有member(成员/元素)的长度都小于64字节.
以上两个条件的上限值可通过 zset-max-ziplist-entries和zset-max-ziplist-value来修改.
ziplist编码的有序集合使用压缩列表作为底层实现,每个集合元素使用两个紧凑在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值.并且压缩列表内的结合元素按分值从小到大的顺序进行排列,小的放置在表头位置,大的放置在靠近表尾的位置.
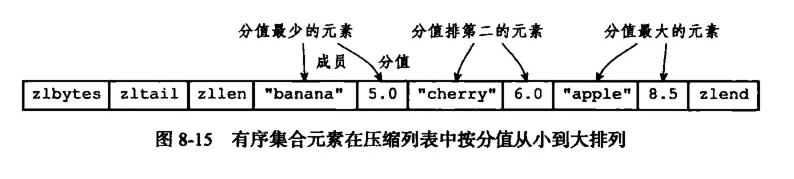
- skiplist + hashtable/dict 结构:

其中dict保存key(元素)/value(分值), 便于通过key(元素)获取score(分值).skiplist保存有序的元素列表,便于执行range(范围)之类的命令.
跳表的第一层为双向链表,其他层是单向链表,且元素只保存在第一层.

skiplist(跳表)详细解释::请点击这里















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









