






关于防止出现手机微信投票怎么刷票、微信刷票会不会被发现的技术,越来越多的人在平常生活中使用微信,以微信为载体的许多功能就被开发和使用了起来,比如——微信投票。于是乎,微信上兴起了各种投票,从小学生到gov部门的投票活动都有,,刷票交易也越来越火。刷票单纯在请求的技术手段上,都是正常的访问请求,基本是没法识别的,但它真的像吃瓜群众一样说的没法认出来吗?未必!
1.水军为了做更多生意自曝身份,在微信昵称上用了显而易见的刷票词语,比如用“票”筛选投票数据,就得到了大量的刷票信息,见图:
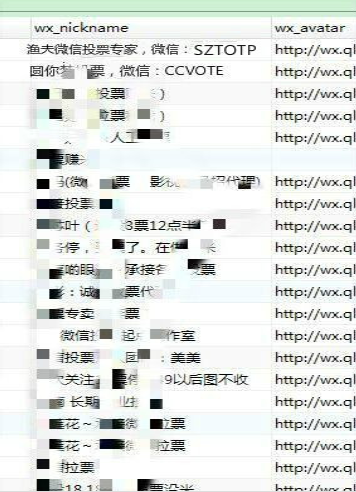
这样,只要通过一定的规则来匹配投票人的微信昵称,判断出投票人是否是刷票的,如果是进入黑名单。如果一个被投票的有大量黑名单的人给他投票,那么他就有花钱买票嫌疑。
2.每天投票量统计分析,如果是持续几天的投票。我们设想被投票人每天都在努力地拉票,从开始到结束应该是一个影响力越来越大或者影响力在结束的时候弱一点,所以每天的投票量统计曲线是先抑后扬或呈正态分布。把每个选 手的每天投票量曲线做出来,和其他人不一样的就一眼看出来了。
3.时段投票量统计分析,这个应该比较容易理解,投票时间应该符合一般人的作息时间,如果在凌晨一、两点某个选手出现大量的投票,而他白天投票量反正少,这就很难用正常投票解释了。
4.投票数爆发点与超越关系的分析。买票是需要成本的,被投票人买票的话当然是想用最少的成本取得第一。如果他被别人超越了的话,不想让自己先期投入变成“沉没成本”,只能加钱再买票再次超越别人。所以,如果一个选手多次被别人超越后投票数立马上升,特别是上升的票数都差不多(想象一下每次都是一百一百地买票),那就基本是刷票了。
5. 多人刷票的情况。这种情况下就有点好玩了,发展的结果是:
a.谁也不服谁,杠上了,超越关系明显。最后钱多的2,3个人超过其他人好多倍的票;
b.为了节约成本,保持第二或第三,在最后时段为了夺冠冲刺刷票,产生了一个非常异常的投票量曲线。
由于我没有长期接触过 Python 网络方面的编程。以前也只是看着用Requests库爬了一些小网站的数据。
1.水军为了做更多生意自曝身份,在微信昵称上用了显而易见的刷票词语,比如用“票”筛选投票数据,就得到了大量的刷票信息,见图:
这样,只要通过一定的规则来匹配投票人的微信昵称,判断出投票人是否是刷票的,如果是进入黑名单。如果一个被投票的有大量黑名单的人给他投票,那么他就有花钱买票嫌疑。
2.每天投票量统计分析,如果是持续几天的投票。我们设想被投票人每天都在努力地拉票,从开始到结束应该是一个影响力越来越大或者影响力在结束的时候弱一点,所以每天的投票量统计曲线是先抑后扬或呈正态分布。把每个选 手的每天投票量曲线做出来,和其他人不一样的就一眼看出来了。
3.时段投票量统计分析,这个应该比较容易理解,投票时间应该符合一般人的作息时间,如果在凌晨一、两点某个选手出现大量的投票,而他白天投票量反正少,这就很难用正常投票解释了。
4.投票数爆发点与超越关系的分析。买票是需要成本的,被投票人买票的话当然是想用最少的成本取得第一。如果他被别人超越了的话,不想让自己先期投入变成“沉没成本”,只能加钱再买票再次超越别人。所以,如果一个选手多次被别人超越后投票数立马上升,特别是上升的票数都差不多(想象一下每次都是一百一百地买票),那就基本是刷票了。
5. 多人刷票的情况。这种情况下就有点好玩了,发展的结果是:
a.谁也不服谁,杠上了,超越关系明显。最后钱多的2,3个人超过其他人好多倍的票;
b.为了节约成本,保持第二或第三,在最后时段为了夺冠冲刺刷票,产生了一个非常异常的投票量曲线。
谁最清楚哪个人是刷票水军呢?应该是疼xun。如果是专门做投票系统,积累了大量数据的话,是可以建立模型识别是刷票行为的(至于为了点击量是否愿意做这个,或者做了这个不启用就不得而知了),小公司的话也可以用第1点做简单地判断,另外可以加验证码,增加投票时间操作,提高刷票水军的时间成本,另外验证码看多了眼睛也会花的偷笑。

延伸阅读:
这几天朋友参加比赛需要,就写了个脚本帮忙.投票
我们首先来到要投票的网站上来看看。
随便找一个投上一票

居然不用登陆,当然是每个IP只能投一票。
打开Chrome dev tools, 看一下
Get请求。
那直接把Request URL复制下来,这个就是用于刷票的URL
按理来说只要把这个URL 发给任何一个人诱惑他点开,就是帮你投票了。

他返回了一个Json数据格式。告诉我们已经投过票了。
然后我们登VPN 换一个IP 试试看。

Json “Total” 名称 就是当前的票数。“result”为true 显然告诉我们投票成功了。
那的确是这样的。
然后想要刷票呢,我们需要找一些开放HTTP代理的IP。我找了半天然后推荐这个网站 可以直接抓取IP到这种格式。
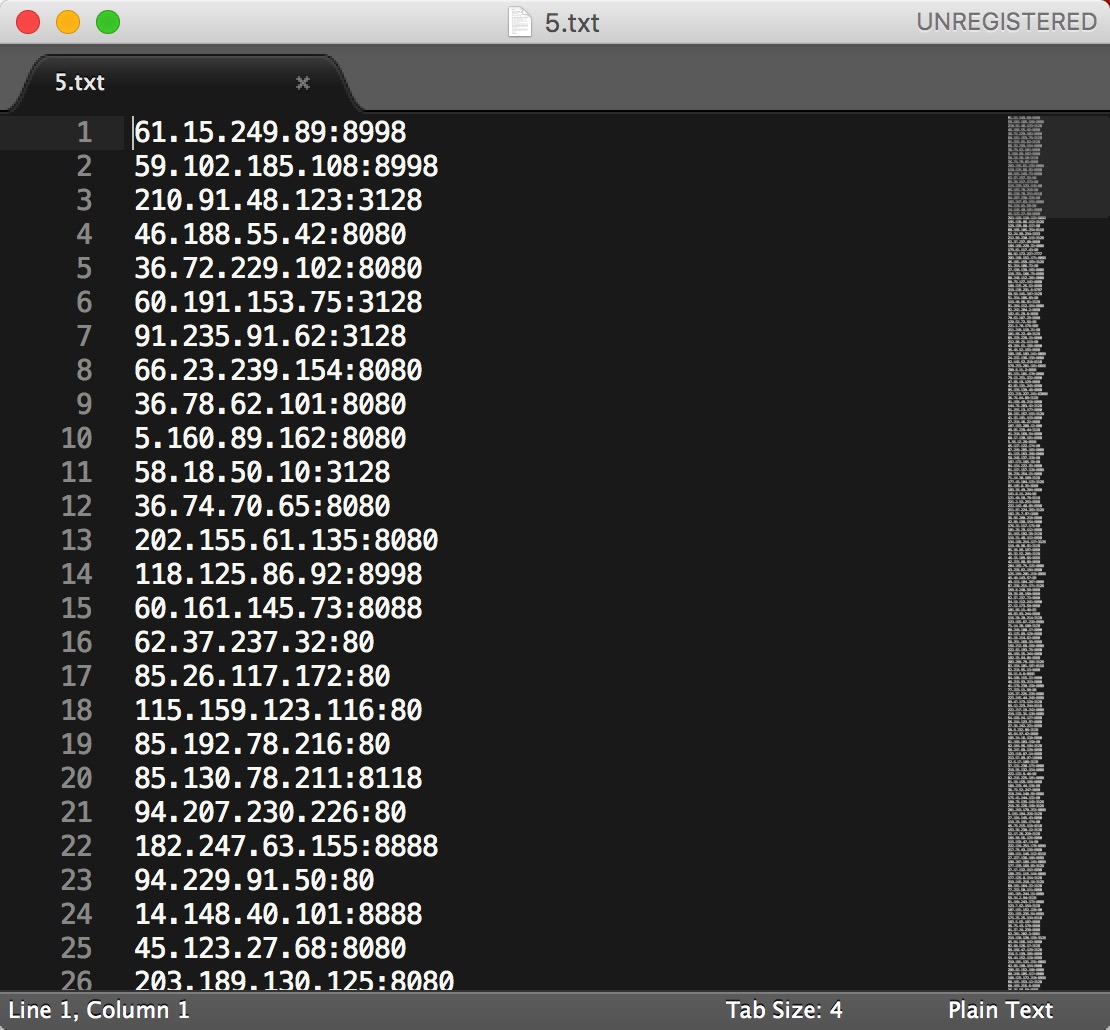
由于我没有长期接触过 Python 网络方面的编程。以前也只是看着用Requests库爬了一些小网站的数据。
- #coding=utf-8
- import urllib2
- import urllib
- import re
- import threading
- import sys
- from time import ctime
- import time
- rlock = threading.RLock()
- def vote(proxyIP,i,urls):
- try:
- #print "voting...%d..." % i
- #使用代理IP
- proxy_support = urllib2.ProxyHandler(proxyIP)
- opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
- #定义Opener
- urllib2.install_opener(opener)
- #把opener绑定到全局
- sendt = '投票'.decode('utf-8').encode('gb2312')
- #设置刷票地址
- #post数据bn
- values = {}
- req = urllib2.urlopen(urls)
- #直接打开这个URL
- html = req.read()
- #读取返回数据
- if html.find('true'.decode('utf-8').encode('gb2312')):
- print "投票 [%d] 成功" % i
- return 1
- else:
- print "投票 [%d] 失败" % i
- return 0;
- except Exception:
- return False
- if __name__ == "__main__":
- args = sys.argv
- if(len(args) == 3):
- ipFile = open(args[1]);
- ipList = ipFile.readlines()
- ipFile.close()
- length = range(len(ipList))
- threads = []
- for i in length:
- ipLine = ipList[i]
- ip=ipLine.strip()
- proxy_ip = {'http': ip}
- t = threading.Thread(target=vote,args=(proxy_ip,i,args[2]))
- print "get ",args[2],ip
- threads.append(t)
- for i in length:
- threads[i].start();
- if i%100:
- time.sleep(5)
- #每100个线程等待 5秒
- for i in length:
- threads[i].join()
- else:
- print """刷票工具
- python brush.py IP文件 Get地址:
- """
然后我们运行来看看结果
原来的票数
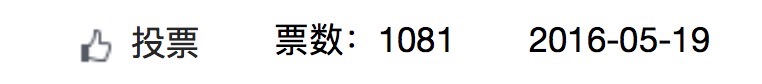
运行了15分钟之后
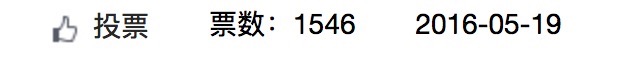

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









