







读写分离是为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。
原理:让主数据库(master)处理事务性增、改、删操作,而从数据库(slave)处理select查询操作。
注意:
- Sharding-JDBC 通过 sql 语句语义分析,实现读写分离过程,不会做数据同步。
- 数据同步需要数据库搭建主从集群架构,来做数据之间的主从同步。
关于数据库的主从集群架构自行搭建,下面从 Sharding-JDBC 的应用层来做数据的读写分离。
一、读写分离
1、application.properties 配置文件
在 application.properties 配置文件中进行
# 配置真实数据源
spring.shardingsphere.datasource.names=db1,db2
# 配置第1个数据源
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://localhost:3306/sharding_db1?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=123456
# 配置第2个数据源
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://localhost:3306/sharding_db2?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=123456
##配置主从逻辑数据源,读写分离规则, db1主库,db2从库
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=db1
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=db2
#基于读写分离的表分片
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds0.course_$->{1..2}
# 指定表的主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=id
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#表策略
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{id%2+1}
# 打开shardingsphere的sql日志输出。
spring.shardingsphere.props.sql.show=true
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
2、测试
1)保存
@Test
public void testSave() throws InterruptedException {
for (int i = 0; i < 4; i++) {
Course course = new Course();
course.setGmtCreate(new Date());
course.setName("java");
course.setUserId(1001L + i);
course.setStatus("1");
TimeUnit.MILLISECONDS.sleep(50);
int count = courseMapper.insert(course);
System.out.println("id ->" + course.getId());
}
}
从日志中看到,保存操作的数据库都是主库(db1)。
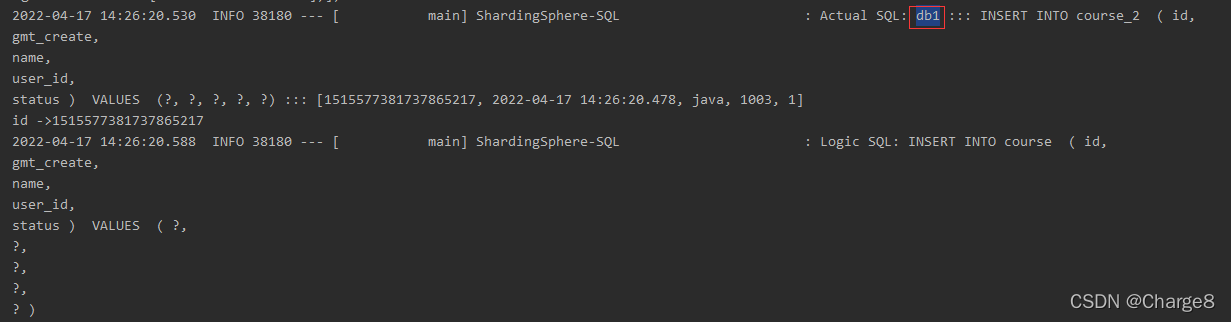
2)查询
@Test
public void testIN() {
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
wrapper.in("id",1515577381737865217L, 1515492164109004802L, 1515576508269936641L);
List<Course> courses = courseMapper.selectList(wrapper);
System.out.println(courses.size());
courses.forEach(course -> System.out.println(course));
}
从日志中看到,查询操作的数据库都是从库(db2)。

因为 id=1515577381737865217记录在主库(db1)中。数据还没有同步到从库(db2),所以查不到。
– 求知若饥,虚心若愚。















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









