







目录
linux的目录结构
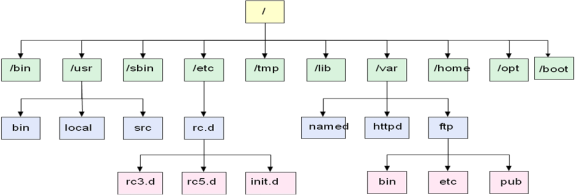
Linux文件系统是呈树形结构
| 目录 | 说明 |
|---|---|
/ | Linux文件系统的入口,也是处于最高一级的目录 |
/bin | 基本系统所需要的命令。功能和/usr/bin类似,这个目录中的文件都是可执行的,普通用户都可以使用的命令 |
/boot | 内核和加载内核所需要的文件。一般情况下,GRUB系统引导管理器也位于这个目录 |
/dev | 设备文件存储目录,比如终端、磁盘等 |
/etc | 所有的系统配置文件 |
/home | 普通用户家目录的默认存放目录 |
/lib | 库文件和内核模块所存放的目录 |
/media | 即插即用型存储设备的挂载点自动在这个目录下创建,比如u盘、CDROM/DVD自动挂载后,也会在这个目录中创建一个目录。 |
/mnt | 临时文件系统的挂载点目录 |
/opt | 第三方软件的存放目录 |
/root | Linux超级权限用户root的家目录 |
/sbin | 基本的系统维护命令,只能由超级用户使用 |
/srv | 该目录存放一些服务启动之后需要提取的数据 |
/tmp | 临时文件目录 |
/usr | 存放用户使用系统命令和应用程序等信息,比如命令、帮助文件等。 |
/var | 存放经常变动的数据,比如日志、邮件等。 |
几个特殊的文件系统
| 文件系统 | 挂载点 | 说明 |
|---|---|---|
root | / | Linux系统运行的基点,根文件系统不能被卸载 |
proc | /proc | 以文件系统的方式为访问系统内核数据的操作提供接口,适用于2.4和2.6内核 |
sysfs | /sys | 以文件系统的方式为访问系统内核数据的操作提供接口,2.6内核使用 |
tmpfs | /dev 、/var/run、/var/lock | 程序访问共享内存资源时使用的文件系统 |
usbfs | /proc/bus/usb | 访问usb设备时使用的文件系统 |
devpts | /dev/pts | 内核用来与伪终端(以远程方式登陆)进行交互的文件系统 |
swap | 内核使用的特殊文件系统,无挂载点 | 用来创建虚拟内存 |
常用命令
ls
# 显示目录
ls [参数] [目录名]
-a:显示所有文件,包括隐藏文件(以.开头的文件)
-l:以长格式显示
-t:按修改时间先后显示
-R:显示目录及下级子目录结构(递归)
-m: 横向输出文件名,并以“,”作分格符。
-S: 以文件大小排序。
#####################颜色代表不同文件#####################
白色:普通文件
红色:压缩文件
蓝色:目录文件
浅蓝色:链接文件
黄色:设备文件(/dev)
绿色:可执行文件(/bin、/sbin)
粉红色:图片文件
mkdir
# 建立目录
mkdir [参数] {目录名}
-p:可以一次性创建整个目录树
file
# 显示文件类型
file [参数] 文件名
-b :列出辨识结果时,不显示文件名称
-c:详细显示指令执行过程,便于排错或分析程序执行的情形
-i:显示MIME类别
-L :查看对应软链接对应文件的文件类型
-z:尝试去解读压缩文件的内容
shutdown
# 关机程序
shutdown [参数]
-t:设定在几秒钟之后进行关机程序。
-k:并不会真的关机,只是将警告讯息传送给所有使用者。
-r:关机后重新开机。
-h:关机后停机。
-n:不采用正常程序来关机,用强迫的方式杀掉所有执行中的程序后自行关机。
-c:取消目前已经进行中的关机动作。
alias
# 设置指令的别名
alias [别名]=[指令名称]
find
# 用来在指定目录下查找文件
find 路径 [参数] 文件名
-name :文件名称符合 name 的文件
-iname :文件名称符合 name 的文件,iname 会忽略大小写
-type:找出符合文件类型的文件
-pid:找出对应的进程id的文件
-size [+ -]:按照指定大小搜索文件(c为字节、k为KB单位、M为MB单位、G为GB单位)
-perm [/|-]mode:根据权限查找(mode:精确权限匹配;/mode:任何一类用户(u,g,o)的权限中的任何一位(r,w,x)符合条件即满足; -mode:每一类用户(u,g,o)的权限中的每一位(r,w,x)同时符合条件即满足。)
-uid :按照用户 ID 査找所有者是指定 ID 的文件
-gid :按照用户组 ID 査找所属组是指定 ID 的文件
-user :按照用户名査找所有者是指定用户的文件
-group :按照组名査找所属组是指定用户组的文件
#####################文件类型#####################
f/- 普通文件 保存数据 d 目录文件 存放文件 l 符号链接文件 指向其他文件 b 块设备 文件 访问设备 c 字符设备文件 访问设备 p 管道文件 进程间通信 s 套接字文件 进程间通信
history
# 显示用户以前执行过的历史命令
history
grep
# 用于查找文件里符合条件的字符串
grep [参数] 文件名
-c:输出匹配行的计数
-i:忽略字符大小写的差别
-n:显示匹配行及行号
-v:显示不包含匹配文本的所有行
sort
# 用于查找文件里符合条件的字符串
sort [参数] 文件名
-c:检查文件是否已经按照顺序排序
-n:依照数值的大小排序
-u:对输出的结果去重
-o:将排序后的结果存入指定的文件
-r:反向排序
uniq
# 用于检查及删除文本文件中重复出现的行列
uniq [参数] 文件名
-c:在每列旁边显示该行重复出现的次数
-d:仅显示重复出现的行列
wc
# 计算字数
uniq [参数] 文件名
-l:统计行数
-w:统计字数
which
# 在环境变量$PATH设置的目录里查找符合条件的文件
which 文件名
whereis
# 查找原始代码、二进制文件,或是帮助文件
whereis 文件名
ps
# 显示当前进程的状态
ps [参数]
-A:列出所有的进程
-w:显示加宽可以显示较多的资讯
-au:显示较详细的资讯
-aux:显示所有包含其他使用者的行程
-l:长格式输出
-r:显示运行中的进程
#####################ps输出解释#####################
USER 进程的属主 PID 进程ID PPID 父进程的ID %CPU 进程占用的CPU百分比 %MEM 占用内存的百分比 PRI 代表这个程序『可被执行的优先级』 NI 进程的NICE值,数值大,表示较少占用CPU时间 VSZ 进程占用的虚拟大小 RSS 驻留中页的数量 TTY 终端ID STAT 进程状态 WCHAN 正在等待的进程资源 START 启动进程的时间 TIME 进程消耗CPU的时间 COMMAND 所执行的指令
进程状态 解释 D无法中断的休眠状态 (经常 IO 的进程) R正在运行中的进程 S处于休眠状态的进程 T暂停执行态 W没有足够的记忆体分页可分配,进入内存交换 X死掉的进程 Z僵尸进程 <优先级高的进程 N优先级较低的进程 L有些内存分页被锁进内存 s进程的领导者(在它之下有子进程) l多线程,克隆线程 +位于后台的进程组
pgrep
# 用于查找文件里符合条件的字符串
pgrep [参数] 程序名
-l:列出程序名和进程ID
-o:表示如果该程序有多个进程正在运行,则仅查找最老的,即最先启动的(多个进程时即父进程PID)
-n:如果该程序有多个进程正在运行,则仅查找最新的,即最后启动的进程ID
-P:根据父进程PID,找出所有子进程的pid
kill
# 用于查找文件里符合条件的字符串
pgrep [参数] 进程ID
-1 (HUP):重新加载进程
-9 (KILL):强制杀死进程
-15 (TERM):正常停止一个进程
top
# 实时显示进程的动态
pgrep [参数] 进程ID
-d:刷新时间的间隔
-n:更新的次数,完成后将会退出 top
#####################top的基本视图#####################
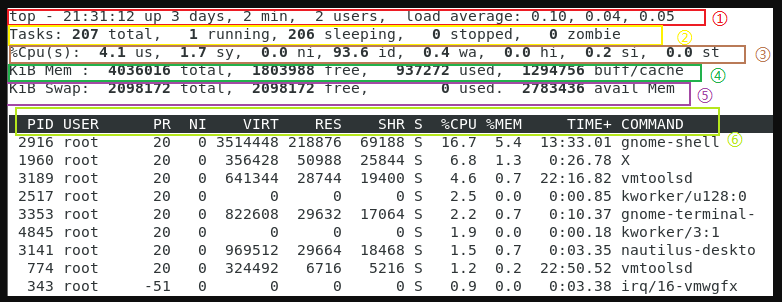
① 21:31:12 ===》 当前系统时间 up 3 days, 2 min ===》 系统已经运行了 3天2分钟(在这期间没有重启过) 2 users ===》 当前有2个用户登录系统 load average: 0.10, 0.04, 0.05 ===》三个数分别是1分钟、5分钟、15分钟的cpu负载情况(load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。)
② Tasks ===》任务(进程),系统现在共有207个进程,其中处于运行中的有1个,206个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个
③ %Cpu(s) ===》cpu状态 4.1% us — 用户空间占用CPU的百分比。 1.7% sy — 内核空间占用CPU的百分比。 0.0% ni — 改变过优先级的进程占用CPU的百分比 93.6% id — 空闲CPU百分比 0.4% wa — IO等待占用CPU的百分比 0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比 0.2% si — 软中断(Software Interrupts)占用CPU的百分比 0.0% st — 虚拟机占用百分比
④ KiB Mem ===》内存状态 4036016 total — 物理内存总量 937272 used — 使用中的内存总量 1803988 free — 空闲内存总量 1294756 buff/cache — 缓存的内存量 (使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心)
⑤ KiB Swap ===》交换分区 2098172 total — 交换区总量 0 used — 使用的交换区总量 2098172 free — 空闲交换区总量 2783436 avail Mem — 缓冲的交换区总量 (有个近似的计算公式:KiB Mem的free + KiB Mem的buff/cache + KiB Swap的avail Mem,按这个公式大概能得出服务器的可用内存) 对于内存监控,在top里我们要时刻监控KiB Swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap交换分区的数据交换,这是真正的内存不够用了。
⑥ 各进程(任务)的状态监控 PID — 进程id USER — 进程的所有者 PR — 进程的优先级 NI — nice值。负值表示高优先级,正值表示低优先级 VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR — 共享内存大小,单位kb S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 %CPU — 上次更新到现在的CPU时间占用百分比 %MEM — 进程使用的物理内存百分比 TIME+ — 进程使用的CPU时间总计,单位1/100秒 COMMAND — 命令名/命令行 WCHAN — 若该进程在睡眠,则显示睡眠中的系统函数名 Flags — 任务标志
gzip
# 压缩文件
gzip [参数] 文件名
-d:解压
-f:强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接
-l:列出压缩文件的相关信息
-L:显示版本与版权信息
-r:递归处理,将指定目录下的所有文件及子目录一并处理分别压缩
-t:测试压缩文件是否正确无误
-v:显示指令执行过程
-1~9:压缩比例是一个介于1-9的数值,预设值为"6",指定愈大的数值,压缩比例就会愈高
tar
# 文件归档,将文件归档可以把整个目录树保存在同一个文件中,归档文件通常也会一并压缩
tar [参数] 文件名
-c:创建归档文件
-x:从归档文件中还原文件
-v:显示详细信息
-f:指定文件名(可带路径)进行归档
-z:使用gzip压缩
-t:列出归档备份文件的内容
-U:解开压缩文件还原文件之前,先解除文件的连接
-W:把文件归档后,确认文件正确无误
进程
进程一般分为交互进程、批处理进程和守护进程三类。
进程ID(PID):是唯一的数值,用来区分进程
父进程的ID(PPID):他们的关系是管理和被管理的关系,当父进程终止时,子进程也随之而终止。但子进程终止,父进程并不一定终止。
进程状态:状态分为运行R、休眠S、僵尸Z
权限
| 字符表示法 | 八进制表示法 | 含义 |
|---|---|---|
| r | 4 | 读(查看文件) |
| w | 2 | 写(删建文件、重命名) |
| x | 1 | 执行(进入目录) |
软件管理
RPM
# RPM是软件管理程序,提供软件的安装、升级、查询、反安装的功能
rpm [参数] 软件包
- 优点
- 安装方便,软件中所有数据都经过编译和打包
- 查询、升级、反安装方便
- 缺点
- 缺乏灵活性
- 存在相依属性
-i:安装
-U:升级安装,如果不存在也安装
-F:更新安装,如果不存在不安装
-vv:详细显示指令执行过程,便于排错
-h:有进度条
–replacepkgs:强制覆盖安装
–nodeps:不考虑相互关联性
-q :查询
-a:查询所有
-l :列出软件的文件清单
-e :删除软件
YUM
主要功能是更方便的添加/删除/更新RPM包,它能自动解决包的倚赖性问题
- 特点
- 便于管理大量系统的软件包更新问题
- 可以同时配置多个资源库(Repository)
- 简洁的配置文件(/etc/yum.conf)
- 自动解决增加或删除rpm包时遇到的倚赖性问题
- 使用方便
- 保持与RPM数据库的一致性
#安装软件
yum install –y software
#更新软件
yum update -y software
#删除软件
yum remove -y software
#列出资源库中特定的可以安装或更新以及已经安装的rpm包
yum list
#列出所有软件包组
yum grouplist
#安装软件包群组
yum groupinstall ‘包群组名’
yum groupremove ‘包群组名
#查看软件包信息
yum info 软件包名
#搜索
yum search 软件包名
#清除yum缓存
yum clean all
APT
# 提供了查找、安装、升级、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记
apt [参数] 命令 软件包
#需要定期运行这一命令以确保您的软件包列表是最新的
apt update
#安装指定的软件
apt install package_name
#删除软件包
apt remove package_name
#删除已安装的软件包及配置文件
apt purge package_name
#清理不再使用的依赖和库文件
apt autoremove package_name
#更新所有已安装的软件包
apt upgrade
#显示软件包具体信息,例如:版本号,安装大小,依赖关系
apt show package_name
#查找软件包
apt search package_name
#列出所有已安装的包
apt list --installed
#列出所有已安装的包的版本信息
apt list --all-versions
Rsync
Rsync(Remote Synchronize) 是一个远程资料同步工具,可通过LAN/WAN快速同步多台主机,Rsync使用所为的“Rsync演算法”来使本地主机和远程主机之间达到同步,这个演算法并不是每次都整份传送,它只传送两台计算机之间所备份的资料不同的部分,因此速度相当快。
另外,与SCP相比,传输速度不是一个层次级的。在局域网时经常用Rsync和SCP传输大量Mysql数据,Rsync至少比Scp快20倍以上,所以如果需要在Linux/Unix服务器之间互传海量资料,Rsync是非常好的选择
- 优点
- 可以镜像保存整个目录树和文件系统
- 可以很容易的做到保持原来文件的许可权、时间、软链接等
- 无须特使许可权即可安装
- 拥有优化的流程,文件传输效率高
- 可以使用Rsh、SSH等方式来传输文件,当然也可以直接通过Socket连接
- 支持匿名传输
# 下载
rsync [参数] 远程文件(远程路径) 本地目录
# 上传
rsync [参数] 本地文件 远程目录
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性
-v, --verbose:详细模式输出
-r, --recursive:对子目录以返回模式处理。
-p, --perms:保持文件许可权
-o, --owner:保持文件属主信息
-g, --group:保持文件组信息
-t, --times:保持文件时间信息
–delete:删除哪些DST中存在而SRC中不存在的文件或目录
–delete-excluded:同样删除接收端哪些该选项制定排出的文件
-z, --compress:对备份的文件在传输时进行压缩处理
–exclude=PATTERN:制定排除不需要传输的文件
–include=PATTERN:制定不排除需要传输的文件
–exclude-from=FILE:排除FILE中制定模式的文件
–include-from=FILE:不排除FILE中制定模式匹配的文件
巨人的肩膀
从他人的工作中汲取经验来避免自己的错误重复,正如我们是站在巨人的肩膀上才能做出更好的成绩。
http://www.zixue.it
https://www.runoob.com/linux
VChat
一个没有哆啦A梦和静香的IT码农,不专业Gopher
















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









