






介绍
Protobuf全称是Google Protocol Buffer,看看官方文档给出的定义和描述:
它是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。它是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
protobuf提供了高效率的序列化和反序列化机制,序列化就是把对象转换成二进制数据发送给服务端,反序列化就是将收到的二进制数据转换成对应的对象。
总的来说就是protobuf是一个结构数据序列化的方法,类似于XML,并且更加的高效,扩展性好,而且可以兼容很多的语言
protobuf的简单🌰
举个[emoji],创建一个.proto文件,定义数据结构
message ProtobufExample{
optional string strVal = 1;
optional bytes bytVal = 2;
message Embedd {
int32 intVal = 1;
string strVal = 2;
}
optional Embedd embedd = 3;
repeated int32 repeatedInt = 4;
repeated string repeatedStr = 5;
}
这个例子很简单,就是在关键字 message 后跟上消息名称
message xxx {
}
在这个结构中定义了它所具有的字段,基本语法定义:
-
消息message :使用message定义一个消息类型
-
字段:可分为
-
required 字段只能而且只能出现1次
-
optional字段可以出现0次或者1次
-
repeated字段可出现0,1或者多次
-
-
类型: 消息中的字段,包括整形(int32,int64,uint32,uint64),浮点数,字符串,布尔值等等
-
变量名:定义该属性的变量名称
-
字段编号:0~536870911 除去19000到19999之间的数字
message xxx {
//字段 : required -> 字段只能而且只能出现1次
//字段 : optional -> 字段可以出现0次或者1次
//字段 : repeated -> 字段可出现0,1或者多次
//类型 : int 32, int 64, sint32, string...
//字段编号: 0~536870911除去19000到19999之间的数字
//字段规则
类型 名称 = 字段编号
}
在这个示例中,定义了:
1.类型为string,名为strVal,字段为 optional 可出现0或1次,字段编号为1
2.类型为 bytes ,名为bytVal,字段为 optional 可出现0或1次,字段编号为2
3.类型为自定义内嵌Embedd类型,名为embedd,字段为optional 可出现0或1次,字段编号为3
4.类型为int32,名为repeatedInt,字段为 repeated 可出现0,1或多次,字段编号为4
5.类型为string,名为 repeatedStr,字段为 repeated 可出现0,1或多次,字段编号为5
至此,我们在.proto文件中定义了一个简单的protobuf的数据结构
为什么protobuf这么快
在protobuf结构中有一个字段编号,在序列化的时候会把编号写入二进制文件中去,在反序列化的时候也会通过这个编号找到对应的结构体字段。拿optional string strVal = 1;举一个例子,如果是JSON,就会存储整个变量strVal,但是如果使用protobuf,只需要存储编号就好了,最多使用一个字节即可。但是如果存储这个strVal,它有6个字符,这个时候如果变量的名称比较长,那么使用JSON存储就会存储很多字节。
protobuf的序列化方式
protobuf对于不同数据类型,会采用不同的序列化方式,如下图所示
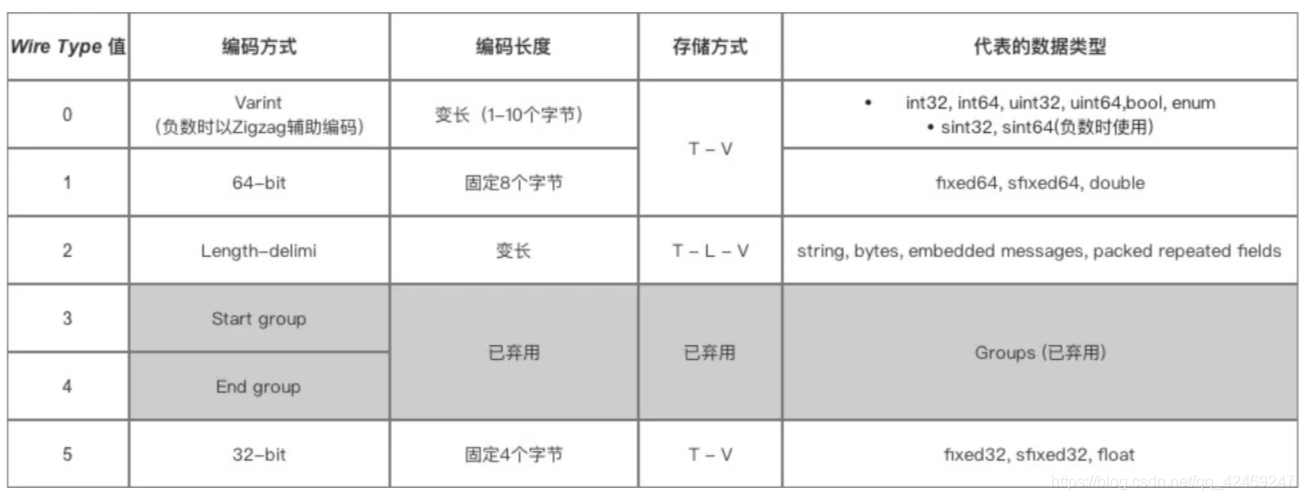
由这个表可以看出
-
对于存储Varint编码数据存储方式为T-V方式,也就是不需要Length长度
-
对于其他编码方式则采用的是T-L-V
因为protobuf对于数据字段的独特编码方式------T-L-V数据存储方式使得protobuf序列化后数据量十分小
Tag-Length-Value编码格式
Tag-Length-Value编码格式简称TLV格式。
定义:Tag作为该字段的唯一的标示,Length代表Value数据域的长度,Value是数据本身
作用:以 标识 - 长度 - 字段值 表示单个数据,最终将所有数据拼接成一个 字节流,从而 实现 数据存储 的功能。
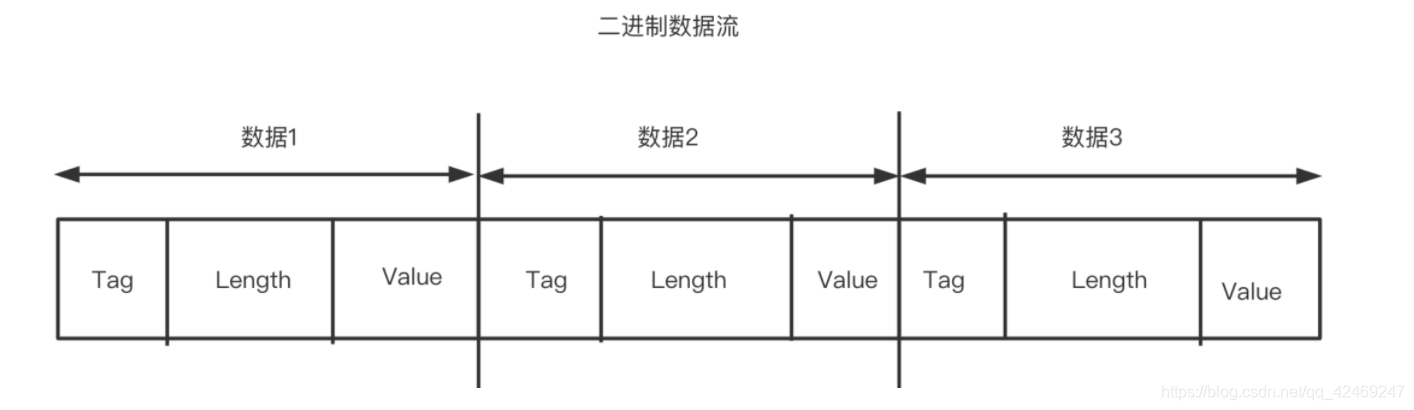
(在这里Length是可选的,因为在Varint编码方式中采用的是T-V方式)
由上图可以得出,TLV存储方式的优点
不需要分隔符 就能 分隔开字段,减少了 分隔符 的使用
各字段 存储得非常紧凑,存储空间利用率非常高
若字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要编码














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









