







在elasticsearch官网中提供了各种语言的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html
1.Java操作ES官方帮助文档
ES提供了java语言的客户端,Java High Level REST Client 内部仍然是基于Java Low Level REST Client。它提供了更多的API,接受请求对象作为参数并返回响应对象,由客户端自己处理编码和解码。所以我们直接使用Java High Level REST Client 去执行ES操作。
2.创建Maven项目
①导入依赖:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
</dependency>
</dependencies>
②利用kibana创建索引库和映射字段
PUT /product
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float"
}
}
}
}
③编写映射实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Product {
private Long id;
private String title; //标题
private Double price; // 价格
private String images; // 图片地址
}
④编写测试类
未考虑集群,下一篇博客会讲述ES集群
private RestHighLevelClient client = null;
//获取连接
@Before
public void getClient() {
client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
}
//释放连接
@After
public void closeClient() throws IOException {
client.close();
}
3.操作文档
①.新增文档
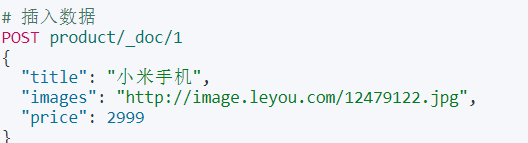
//新增文档
@Test
public void testCreateDocument() throws IOException {
//1. 准备文档
Product product = new Product(1L, "华为pro40手机", 4999D, "http://images.huawei.com/pro40.jpg");
//2.构建索引请求 ()里是之前用kibana创建的索引库
IndexRequest request = new IndexRequest("product");
//3.将文档绑定到请求中
request.id(product.getId().toString());
//4.设置数据和数据类型
request.source(JSON.toJSONString(product), XContentType.JSON);
//发送请求
client.index(request, RequestOptions.DEFAULT);
}
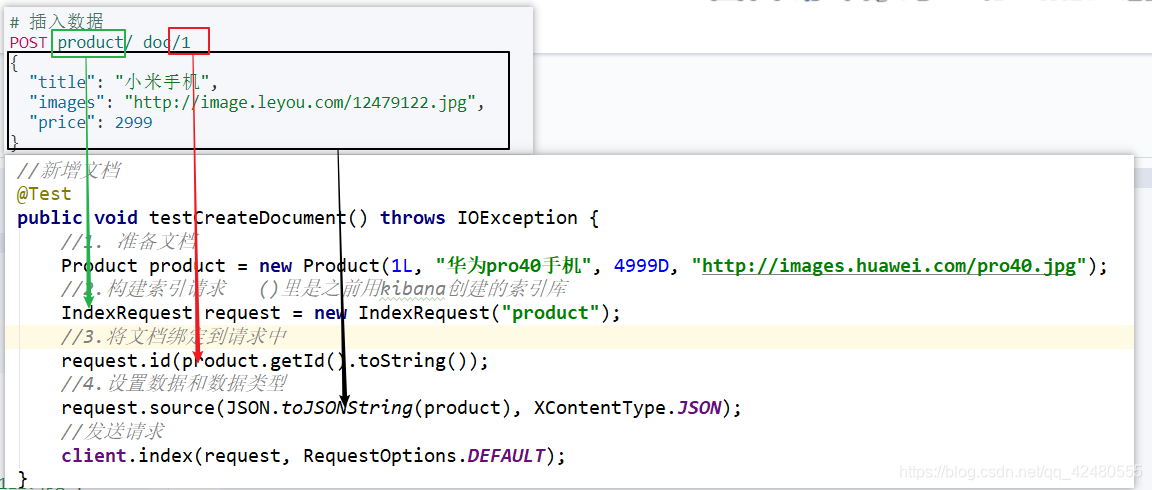
查看结果:

②.查看文档

//查看文档
@Test
public void testFindDocument() throws IOException {
//1.创建查询请求
GetRequest getRequest = new GetRequest("product", "1");
//2.执行请求
GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
//3.解析结果
String json = response.getSourceAsString();
Product product = JSON.parseObject(json, Product.class);
System.out.println(product);
}
结果:

③. 修改文档
新增时,如果传递的id是已经存在的,则会完成修改操作,如果不存在,则是修改。
④. 删除文档
//删除文档
@Test
public void testDeleteDocument() throws IOException {
//1.创建删除请求
DeleteRequest deleteRequest = new DeleteRequest("product", "1");
//2.执行请求
client.delete(deleteRequest,RequestOptions.DEFAULT);
}
查看结果:

⑤.批量操作
利用BulkRequest存放单次新增文档请求
//批量操作
@Test
public void testBulkDocument() throws IOException {
//0. 模拟数据
List<Product> list = new ArrayList<Product>();
list.add(new Product(11L, "小米手机", 3299.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(12L, "锤子手机", 3699.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(13L, "联想手机", 4499.00, "http://image.huawei.com/13123.jpg"));
list.add(new Product(14L, "红米手机", 4299.00, "http://image.huawei.com/13123.jpg"));
//1. 创建批量请求
BulkRequest bulkRequest = new BulkRequest();
//2.遍历文档加入到请求中
for (Product product : list) {
IndexRequest request = new IndexRequest("product");
request.id(product.getId().toString());
request.source(JSON.toJSONString(product),XContentType.JSON);
bulkRequest.add(request);
}
//3.执行批量操作
client.bulk(bulkRequest,RequestOptions.DEFAULT);
}
4.搜索数据
①查询所有

/**
* 搜索数据
*/
@Test
public void queryAll() throws IOException {
SearchRequest request = new SearchRequest("product");
//创建查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
//设置查询方式和条件
builder.query(QueryBuilders.matchAllQuery());
//将条件添加到查询请求中
request.source(builder);
//执行请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
System.out.println(response.getHits().getTotalHits().value);
SearchHit[] searchHits = response.getHits().getHits();
for (SearchHit searchHit : searchHits) {
String source = searchHit.getSourceAsString();
System.out.println(JSON.parseObject(source,Product.class));
}
}
②匹配查询
只需要将查询全部条件换成匹配查询条件
builder.query(QueryBuilders.matchQuery("title","小米")); //匹配查询
③范围查询range
只需要将查询全部条件换成范围查询
builder.query(QueryBuilders.rangeQuery("price").lte(4000).gte(2000)); //范围查询
④结果过滤
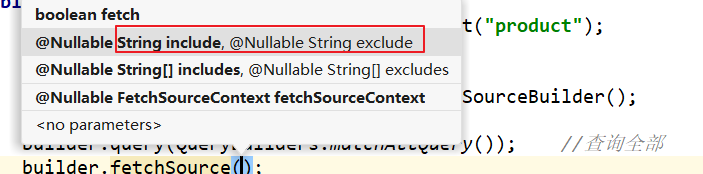
只需要在做查询的时候,指定返回列,利用
fetchSource(String include,String exclude)方法匹配字段
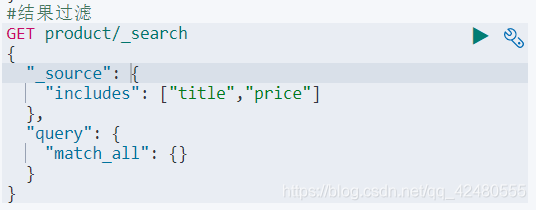
//设置查询方式和条件
builder.query(QueryBuilders.matchAllQuery()); //查询全部
builder.fetchSource(new String[]{"title","price"},null);
⑤排序
只需要添加排序条件
builder.sort("price", SortOrder.DESC);
⑥分页
fromsize字段实现分页
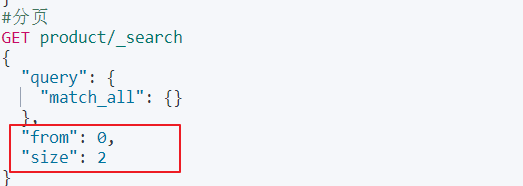
只需要添加分页条件
builder.from(0).size(2);
⑦高亮

//高亮
@Test
public void testHighLight() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest("product");
//创建查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("title","小米")); //匹配查询
//设置高亮效果
HighlightBuilder highlightBuilder =
new HighlightBuilder().field("title").preTags("<font color='red'>").postTags("</font>");
builder.highlighter(highlightBuilder);
searchRequest.source(builder);
//执行请求
SearchResponse response = client.search(searchRequest,RequestOptions.DEFAULT);
//4. 解析结果
SearchHit[] searchHits = response.getHits().getHits();
for (SearchHit searchHit : searchHits) {
//没有效果的对象
Product product = JSON.parseObject(searchHit.getSourceAsString(), Product.class);
//解析效果,替换上面对象中的title的值
String title = (searchHit.getHighlightFields().get("title").getFragments())[0].toString();
product.setTitle(title);
System.out.println(product);
}
}
结果:
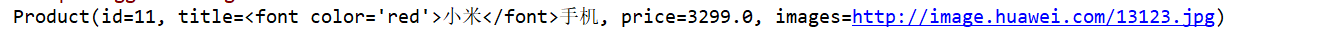
⑧分组
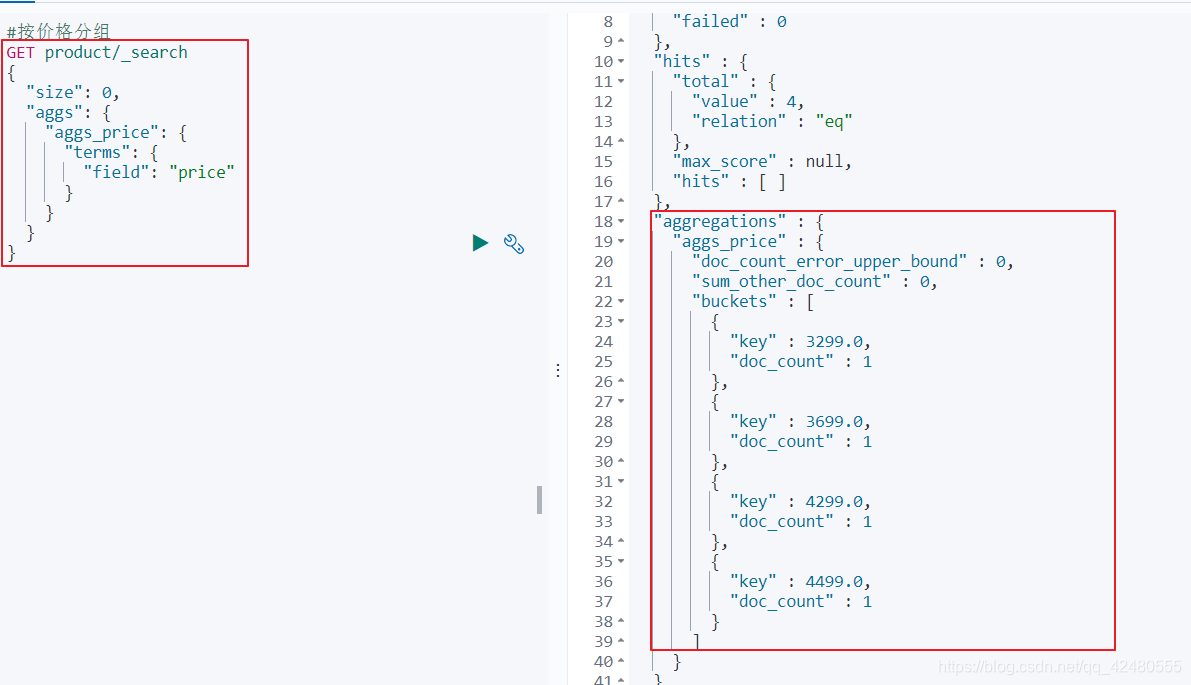
拿price举例 后期我们可以按照实际需求分组
@Test
public void queryByAggs() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest("product");
//创建查询器
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(
AggregationBuilders.terms("aggs_price").field("price")
);
searchRequest.source(builder);
//执行请求
SearchResponse response = client.search(searchRequest,RequestOptions.DEFAULT);
//4. 解析结果
Terms terms = response.getAggregations().get("aggs_price");
for (Terms.Bucket bucket : terms.getBuckets()) {
System.out.println(bucket.getKeyAsString());
System.out.println(bucket.getDocCount());
System.out.println("--------------------");
}
}

前一个博客说过通过Terms也就是词条分组之后,每一组会成为一个个桶,所以遍历terms的得到每个桶。结构如下:

⑨聚合 (不常用)
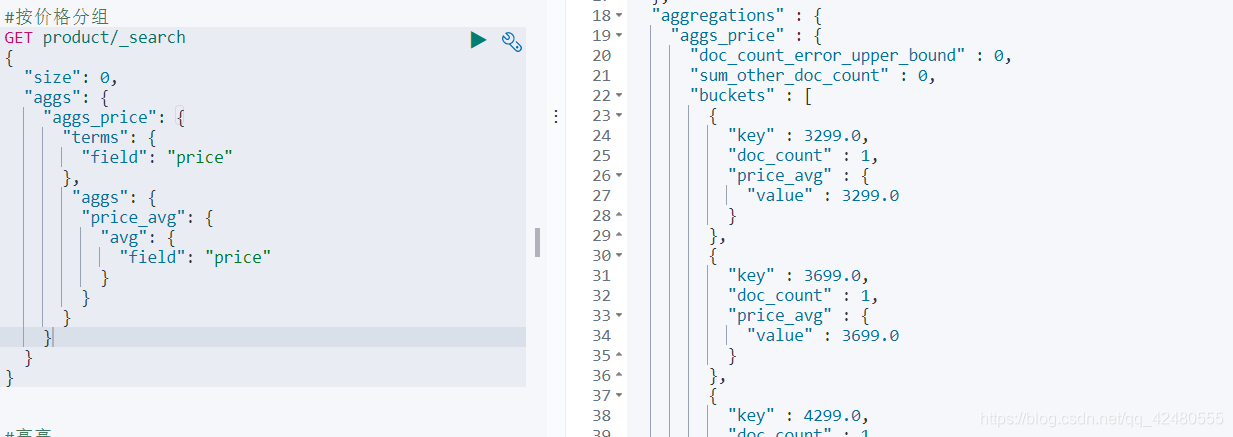
//聚合
@Test
public void testAgg() throws IOException {
//1. 构建查询请求
SearchRequest request = new SearchRequest("product");
//2. 构建条件,并添加到查询请求
SearchSourceBuilder builder = new SearchSourceBuilder();//查询器
builder.aggregation(
AggregationBuilders.terms("aggs_price").field("price")//按照价格分组
.subAggregation(AggregationBuilders.avg("price_avg").field("price"))//分组之后,根据价格请平均数
);
request.source(builder);
//3. 执行请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4. 解析结果
Terms terms = response.getAggregations().get("aggs_price");
for (Terms.Bucket bucket : terms.getBuckets()) {
System.out.println(bucket.getKeyAsString());
System.out.println(bucket.getDocCount());
ParsedAvg aggAvg = bucket.getAggregations().get("price_avg");
System.out.println("平均值"+aggAvg.getValue());
System.out.println("=======================================");
}
}
5.源码:
https://gitee.com/le-peng/java-high-level-rest-client_-esapi.git














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









