






代码地址:https://github.com/songrise/CLIP-Count
论文地址:https://arxiv.org/abs/2305.07304
Abstract
VLM(视觉-语言)模型在Zero-shot Learning中很火,可以迁移到下游检测任务等。但是在物体计数上存在一些问题,提出端到端的CLIP-Count来解决这个问题。
1. 为了对齐文本embedding和密集视觉特征,采用patch-text contrastive loss,学习丰富的块(patch)级视觉表征。
2. 设计了 hierarchical patch-text interaction module 用于跨分辨率视觉特征交互语义信息。
Introduction
类无关对象计数(class-agnostic object counting),标注少量patch作为样例,然后计算参照和图像区域的相似度,取得了不错的成绩,如图a。但是他们都假设在训练和推理中很容易获得样本准确的边界框,因此需要手动标注感兴趣对象的样例,这不太友好。而且就算你标注了,高的类内方差(high intra-class variance,在同一类别中的对象之间存在较大的差异),可能导致统计结果的偏差。之后又提出reference-less counting 方法在推理时自动挖掘和计数显著对象。
reference-less counting 如图b,如果存在多个对象类,无法判别指定感兴趣区域。
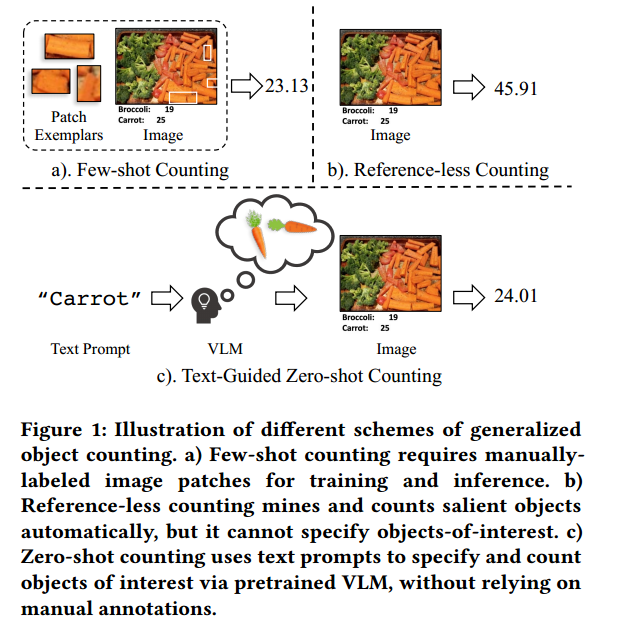
基于上述问题,提出clip-count,引入额外的自然语言prompt作为输入来查询图片中不同目标个数。如图c。用prompt的好处是:
1. 减少训练测试手工标注样例的需求,可扩展到更大的数据集。
2. 和patch样例相比,prompt更好的灵活性,可以涵盖食物这样的一般性描述,也可以是具体的“篮子里的红苹果”这样的描述。
利用prompt指导通用对象计数的几个问题是:
1. 与提供明确外观和形状信息的图像块示例不同,文本提示只包含查询对象的隐式描述。这意味着,仅通过文本描述可能很难获得足够的信息来准确识别和计数对象。
2. prompt准确定位输入图像中的感兴趣对象,关键是两种模式(文本和图像)之间有效的语义对齐,比较困难。
3. zero-shot目标计数需要对开放的prompt和对象类的能够泛化,但是目前没有大规模标注数据集。
因此,我们设计clip-count,具体来说,使用clip来做。一个patch-text contrastive loss用于对齐文本和patch embedding 空间。我们需要同时调整视觉和文本prompt来确保可以迁移预训练的clip模型数据。为了将文本信息指导密集图像特征,又设计了一个hierarchical patch-text interaction module,将文本和图像关联到不同的分辨率。在FSC-147 , CARPK , ShanghaiTech crowd counting上测试。
注:在相关工作中提到了这两篇相似文章,可以看一下。
Dingkang Liang, Jiahao Xie, Zhikang Zou, Xiaoqing Ye, Wei Xu, and Xiang Bai.
2023. CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model.
arXiv preprint arXiv:2304.04231 (2023).
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and
Tali Dekel. 2023. Teaching CLIP to Count to Ten. arXiv preprint arXiv:2302.12066
(2023)
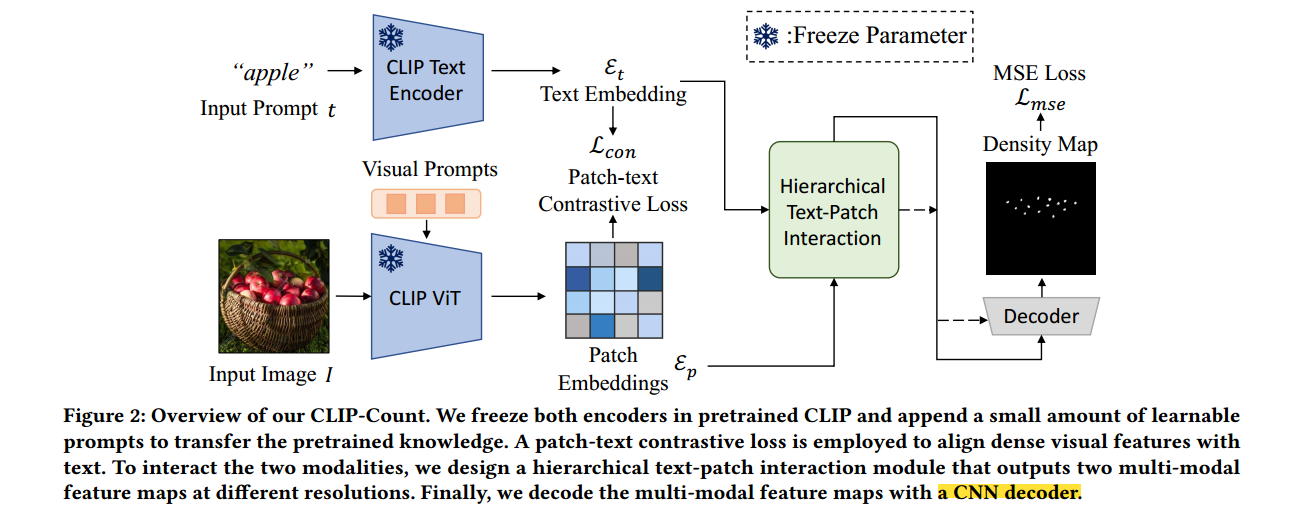
Method
3.1 CLIP
clip模型不过多介绍了,学习对齐的text和图像表征,然后计算对应embedding的点积。ε𝐼 ∈ R𝑛 表示图片I的embedding,ε𝑡 ∈ R𝑛 表示text t的embedding。n为512是clip的embedding维度。文本和图像对的余弦相似度可计算为:
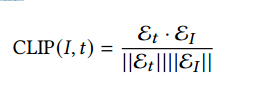
clip使用两个编码器对图像和文本进行编码。基于ViT的CLIP视觉编码器的最后一层输出一个全局图像特征 ![]() 和一个1/16分辨率的patch级特征图
和一个1/16分辨率的patch级特征图 ![]() ,其中 𝑝 = 14 表示每列和每行的图像补丁数,𝑑 = 768 代表ViT潜在维度。CLIP应用线性投影 𝜙𝑧 : Rᵈ ↦→ Rⁿ 在全局特征上以获得图像嵌入
,其中 𝑝 = 14 表示每列和每行的图像补丁数,𝑑 = 768 代表ViT潜在维度。CLIP应用线性投影 𝜙𝑧 : Rᵈ ↦→ Rⁿ 在全局特征上以获得图像嵌入![]() ,而patch级特征图 zₓ 被丢弃。在这项工作中,我们专注于利用 zₓ 进行密度估计。
,而patch级特征图 zₓ 被丢弃。在这项工作中,我们专注于利用 zₓ 进行密度估计。
3.2 Objective
目标是用prompt计数一切,给定图像![]() (含任意对象类)和一个prompt t指定感兴趣目标。我们的目标是估计感兴趣目标的密度图
(含任意对象类)和一个prompt t指定感兴趣目标。我们的目标是估计感兴趣目标的密度图 ![]() 。该对象的计数可以通过对密度图求和获得
。该对象的计数可以通过对密度图求和获得![]()
每个集合中包含的对象类记为 C𝑡𝑟𝑎𝑖𝑛, C𝑣𝑎𝑙, C𝑡𝑒𝑠𝑡.在类别无关设置下,测试集和验证集与训练集不重叠。C𝑡𝑟𝑎𝑖𝑛 ∩ C𝑣𝑎𝑙 = ∅ 以及C𝑡𝑟𝑎𝑖𝑛 ∩ C𝑡𝑒𝑠𝑡 = ∅。我们在训练集上优化![]() 并使用密度图真值y监督。在test和val上评估。
并使用密度图真值y监督。在test和val上评估。
特别的,在推理时使用text guidance是zero-shot object counting和clip一些方法的标准做法,另外”reference-less counting” 和 “zero-shot counting”经常混用,但是还是有区别的。我们将只使用图片输入的叫”reference-less counting”,引入text guidance的叫zero-shot counting",上面的图就是他们的区别。
3.3 Aligning Text with Dense Visual Features
CLIP在全局图像-文本相似度方面不错,但是像素级密度预测不太行。因为clip缺乏定位能力,我们打算调整CLIP视觉编码器以增强patch级特征图z𝑥的定位能力。
patch-text contrastive loss 损失最大化了prompt和与prompt相关的patch级特征之间的交互信息。为了实现这一点,我们首先应用线性投影 𝜙𝑝 : R𝑑 ↦→ R𝑛 将z𝑥映射到与文本嵌入ε𝑡相同的通道维度上。
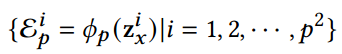
把重塑过的![]() 作为输入图片的patch embedding。这里的patch embedding和VIT不太一样,因为VIT每个patch直接是独立的,但是这儿的patch包含其他patch的信息,因为εp编码了全局注意力机制产生的跨patch信息。
作为输入图片的patch embedding。这里的patch embedding和VIT不太一样,因为VIT每个patch直接是独立的,但是这儿的patch包含其他patch的信息,因为εp编码了全局注意力机制产生的跨patch信息。
为了确定对象的位置,将真值 y 最大池化以获得一个patch级别的二值掩码![]() 用于表示对象性(objectness)。根据M的值,将φ定义为patch embedding的正样本,N为负样本。
用于表示对象性(objectness)。根据M的值,将φ定义为patch embedding的正样本,N为负样本。
与其他方法类似,引入InfoNCE-based [26] contrastive loss:
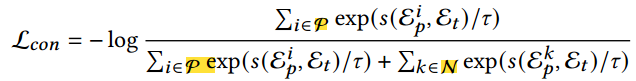
𝑠(., .) 是余弦相似度, 𝜏 = 0.07 是温度系数。这个对比损失函数通过将正patch embedding靠近固定的文本 embedding,推远负patch embedding,从而对齐patch embedding空间和文本 embedding空间。此外,同时调整patch and text embeddings比较有效。因为CLIP使用的prompt模板“a photo of {class}”通常将图像作为一个整体来描述,而不是在patch级别上描述。
该loss的整体演示图如下:
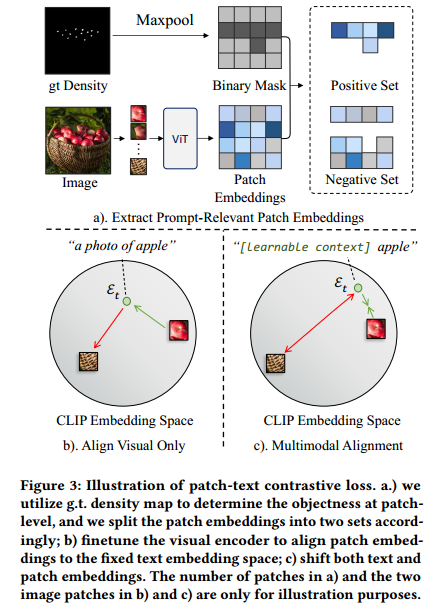
可以看到,先用gt确定patch的正负,b是只调图片,文本固定。c是patch和文本同时调,这样的效果更好。推远负样本,拉进正样本和文本patch。
3.4 Adapting CLIP for Density Estimation
OK,现在loss增强了patch级别的特征表示,提高定位能力了。但是怎么微调视觉编码器?如何将patch级特征图解码为text-conditional(文本导向)的密度图?
Visual Prompt Tuning:预训练+微调资源消耗大,为了有效地利用CLIP中预训练的知识,咱就是冻结CLIP ViT中的参数,并将少量可训练的参数作为visual prompt(来自 Visual prompt tuning,就是用nn.para在浅层或者指定层加参,不懂去看下)。这篇文章是将visual prompt加到每个transformer layer的input中,属于vpt deep的做法。
Hierarchical Text-Patch Interaction Module:一个场景里对象有不同尺度,传统transformer缺乏归纳偏差来有效地处理和模型在不同尺度上的特征。为此提出了轻量级 hierarchical transformer with cross-attention来使文本信息在不同尺度的图像特征中传播。
该块有两个类似的块,依次采用多头自注意(MHSA)、多头交叉注意(MHCA)和一个两层MLP (FFN)。多头就是捕获长距离依赖,MHCA将文本的语义信息传给视觉特征。两个MHCA之间有个带跳跃连接的卷积层。然后使用2x双线性插值使中间多模态![]() 分辨率变大。这里看图片比较好理解。
分辨率变大。这里看图片比较好理解。
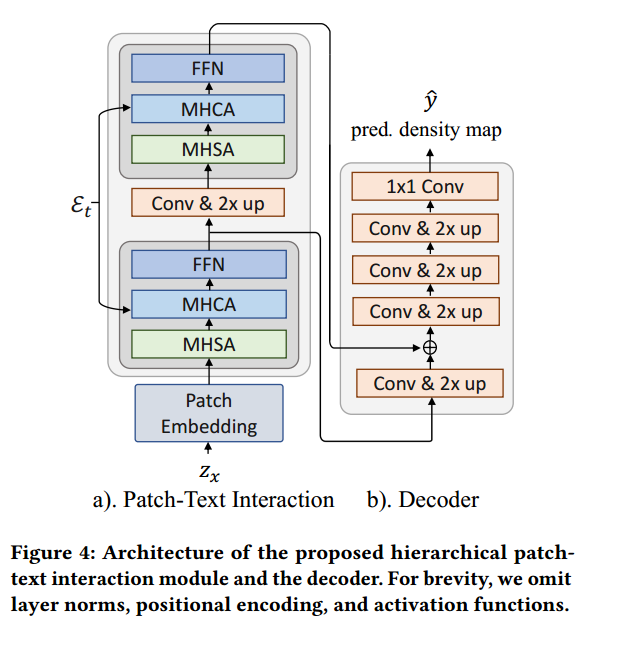
这样做的目的就是在更细的粒度上捕捉文本和图像之间的关系。Text-Patch Interaction Module输出有两个:粗跨模态特征![]() 和细粒度跨模态特征
和细粒度跨模态特征![]() 。
。
Density Map Regression: {𝑀𝑐, 𝑀𝑓}用CNN解码,如上图b, 多个卷积层和2x插值层组成,这些层依次将空间分辨率提高一倍,并将channel减少一半。为了解码来自交互模块的两尺度特征映射,我们首先对粗多模态映射𝑀𝑐进行卷积,并在第二次卷积之前通过求和将其与𝑀𝑓融合。
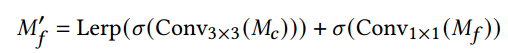
Lerp(.)为双线性插值,φ(.)为激活函数。解码器的最终输出是通过一个具有sigmoid激活的1 × 1卷积层得到的。
EXPERIMENTS
数据集:FSC-147,CARPK,ShanghaiTech
实现细节:pre-trained CLIP with ViTB/16 backbone,deep VPT with 20 visual prompts in each layer,context learning use 2 prefix tokens(不太懂),maxpooling在loss 中用的16的卷积核,16的stride,no padding. 解码器是3x3,stride=1,pad=1的卷积。每个卷积后面用的非线性的GELU
训练细节:在FSC-147训练的,用自己的loss train了30个epoch,然后用MSE loss train了200个epoch。![]()
batch是32,优化器AdamW,learning rate 1 × 10−4,每100epoch衰减系数为0.33。3090TI上训练3个小时。数据增强策略和CounTR这篇文章一致(除了里面的 mosaic augmentation策略)。训练图像下采样到224×224,而之前在FSC-147上的普通计数方法通常使用384 × 384的分辨率。
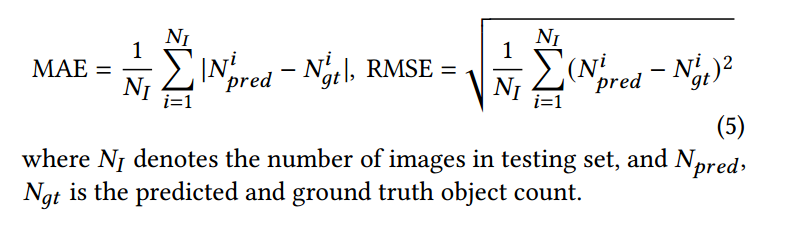
评估指标:MAE和RMSE
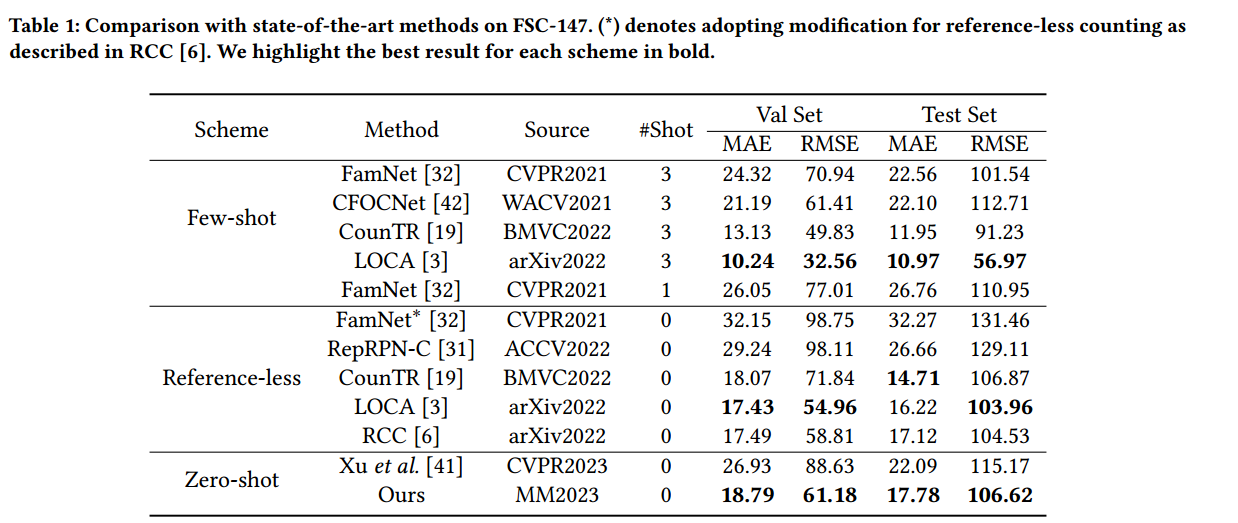
实验结果如下:
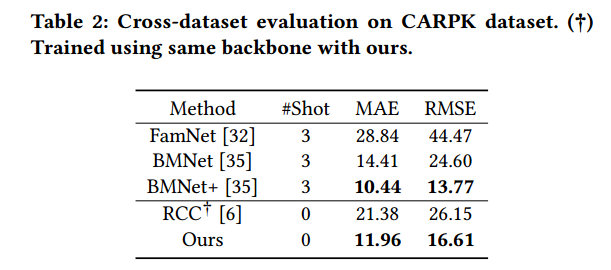
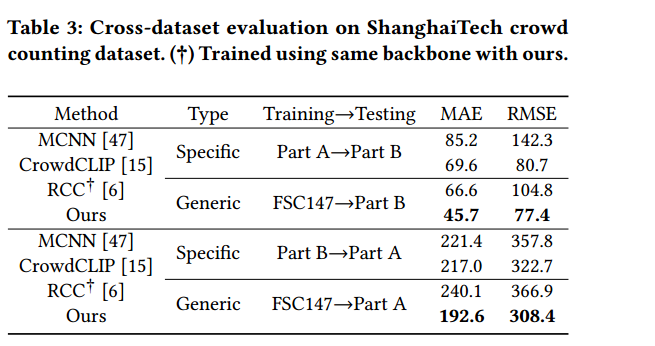
特别注意:表3中在 CrowdCLIP.这篇文章中,他们把clip用在人群计数,在they evaluate the ShanghaiTech 一部分做训练,一部分test。这篇文章也这么做了,不过没有在人群计数网络上微调。
可视化展示:

消融实验:
基线是A1,三个主要设计:(A)如何从CLIP中交互文本和图像特征;(B)如何微调CLIP ViT;(C)所提Loss影响。
A中,add指把text embedding加到patch embedding中去,navie表示使用一个没有分层设计的普通transformer。
B中,finetune就是微调所有VIT参数
C中,visual是只调patch embedding,multi-modal意思是同时调文本和patch embedding。结果见表4
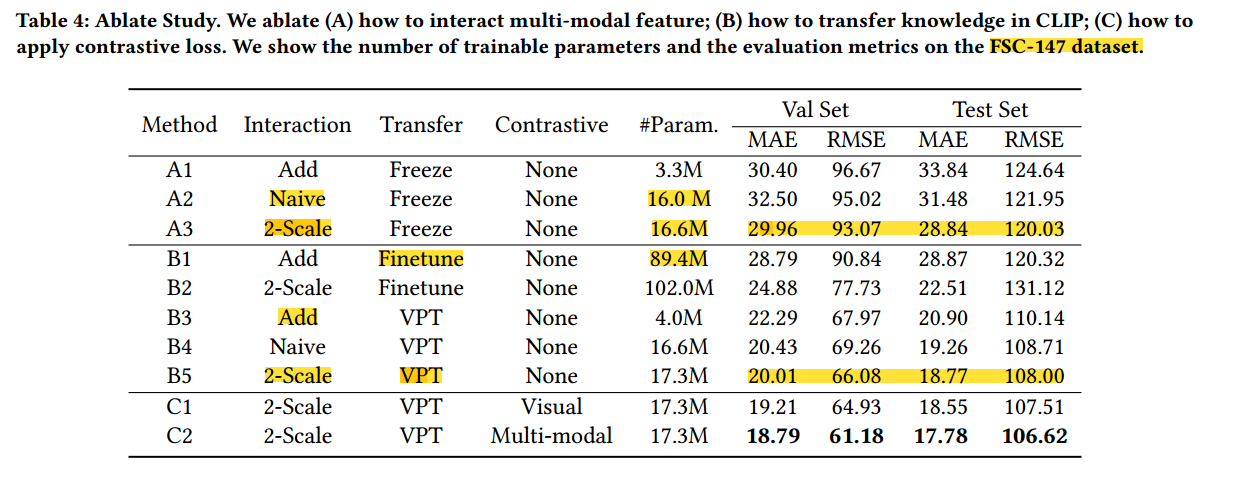
可以看出,A中2x效果不错,参数有所提高。B中VPT节省参数。C中就是loss更好,然后解释一下说是因为没有的话,模型可能会错误地将视觉上相似的物体当作计数目标。
消融可视化来证明一下观点,可以看到密集区域,交互模块学习的更好。对于相似的东西,loss更能分辨出。
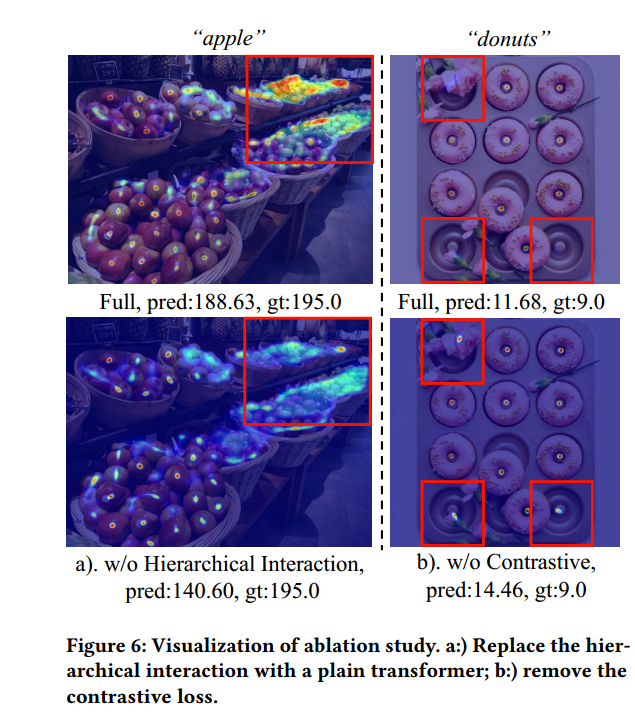
Limitations and Future Works
文本歧义问题,苹果指水果还是苹果图画。太阳镜有两个镜片,算在一起呢,还是单独计算。作者认为这是由于FSC-147中提示注释的不足导致,只有一般类名,没有更细粒度的数据集划分。需要这样的数据集来消除文本歧义。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









