







XPath可以帮助我们很方便地从html代码中提取我们想要的内容,比如href,文本等
@ : 用于选择属性
//li : 当前路径下所有的li标签:
span/text():获取span标签下的文本(获取不到span标签内层标签的文本)
span//text():获取span标签下的所有文本(可以获取span标签所有内层标签的文本)
/html/head/meta/@content:根据节点关系选择内容
//p : 获取整个html中的p标签内容
//ul[@id=“detail-list”]/li : 选中id为detail-list的ul标签下的li
//ul[@id=“detail-list”]/li//h1/p : 选取指定li下的所有h1标签中的p标签
案例
1、获取所有页面的url
//div[@id="page"]/a/@href

可以看到,在插件XPath helper的帮助下,很快提取到了10个页面的href
2、利用文本进行定位
选中文本为“下一页”的a标签
//a[text()="下一页>"]

可以看见,插件已经帮助我们把这部分内容高亮
3、获取指定标签下的文本
//div[@id="7"]/h3/a/text()
 那如果我们想要获取a标签,以及子标签下所有的文本怎么办呢
那如果我们想要获取a标签,以及子标签下所有的文本怎么办呢
//div[@id="7"]/h3/a//text()

4、按序号获取标签
获取第3个a标签
//div[@id="page"]//a[3]

获取倒数第3个a标签
//div[@id="page"]//a[last()-2]

获取前3个a标签
//div[@id="page"]//a[position()<4]

获取a标签下子节点的文本大于4的标签
//div[@id="page"]//a[span/text()>4]
等效写法(应该是默认取text()吧)
//div[@id="page"]//a[span>4]

可以看到只有文本为"5-10"的才被选中,而文本为"1-4"或"下一页"的都没有被选中
5、或 “|”的用法
选中文本为3和倒数第二个a标签
//div[@id="page"]//a[span=3]|//div[@id="page"]//a[last()-1]

在python中xpath的用法
from lxml import etree
def main():
text = """
<nav id="nav" class="clearfix">
<div class="clearfix">
<div class="nav_com">
<ul>
<li class="active"><a>推荐</a></li>
<li class=""><a href="/nav/watchers">动态</a></li>
<li class=""><a href="/nav/career">程序人生</a></li>
<li class=""><a href="/nav/python">Python</a></li>
<li class=""><a href="/nav/java">Java</a></li>
</ul>
</div>
</div>
</nav>
"""
# 此方法可以自动修正html代码,补全标签等
html = etree.HTML(text)
print(etree.tostring(html, encoding="utf-8").decode("utf-8"))
if __name__ == '__main__':
main()
etree.HTML() 方法帮助我们把html代码补充完整,但可能会将html修改错误。使用 etree.tostring() 方法观察修改后的代码再使用

可以看到,etree.HTML() 方法帮助我们把html代码补充完整了。加上了外层标签
接下来,我们将文本内容和对应的href组成一个字典
# 获取所有的href
href_res = html.xpath("//ul//li//a/@href")
# 获取所有的文本
text_res = html.xpath("//ul//li//a/text()")
# 把href和文本组成字典
for i in range(len(href_res)):
dic = {}
dic["title"] = text_res[i]
dic["href"] = href_res[i]
print(dic)
运行结果
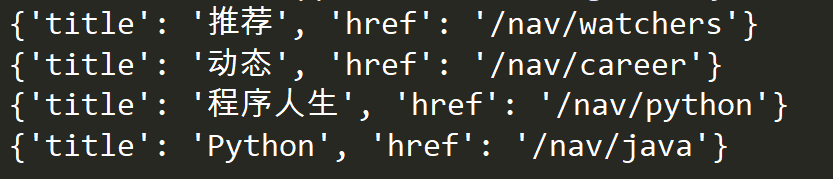
嗯?这里好像不太对,我们对应的文本为“推荐”没有对应的href,此代码将文本和href对应错误。
为了避免由于获取的内容为空,而将对应关系弄错的问题,我们采用下面的方法构造字典
res = html.xpath("//ul//li")
for i in res:
dic = {
"title": i.xpath("./a/text()")[0] if len(i.xpath("./a/text()")) > 0 else None,
"href": i.xpath("./a/@href")[0] if len(i.xpath("./a/@href")) > 0 else None
}
print(dic)

好了,完美对应
















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











