






hive定义:
Hive是一个基于`Hadoop`的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理。这套Hive SQL 简称HQL。Hive的执行引擎可以是MR、Spark、Tez。
1、hive不能做数据存储,他需要依靠HDFS或者Hbase等来做数据存储。
2、Hive没有计算功能,他需要依靠mapreduce、tez、spark等。
3、hive能将HQL语句解析成mapreduce或者spark或者tez等程序。
hive应用:
用于做数据仓库(数据统计和分析)
hive优缺点
优点
学习成本低:提供了类SQL查询语言HQL,使得熟悉SQL语言的开发人员无需关心细节,可以快速上手.
海量数据分析:底层是基于海量计算到MapReduce实现.
可扩展性:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统),Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
良好的容错性:某个数据节点出现问题HQL仍可完成执行。
统一管理:提供了统一的元数据管理
缺点
Hive的HQL表达能力有限。
迭代式算法无法表达.
Hive的效率比较低.
Hive自动生成的MapReduce作业,通常情况下不够智能化.
Hive调优比较困难,粒度较粗.
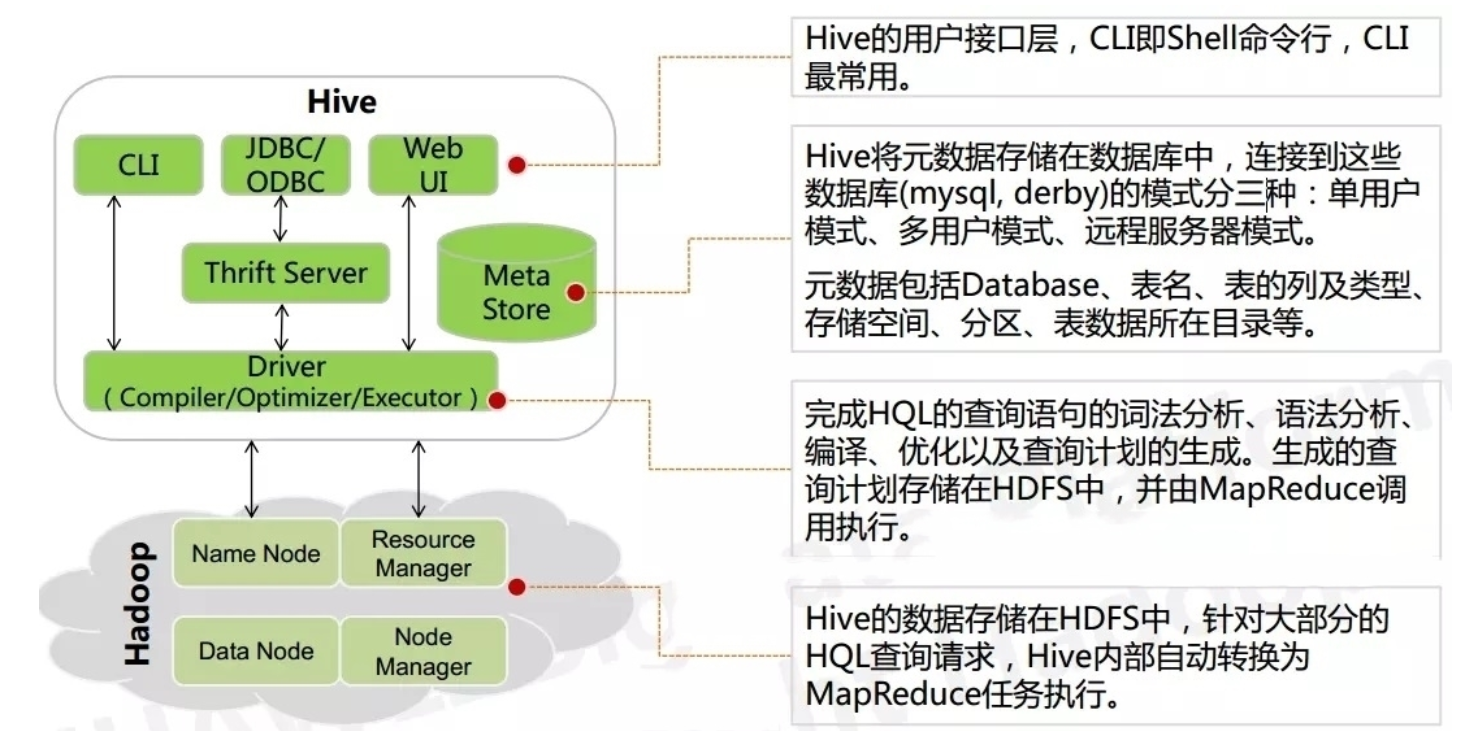
metaStore:库、表、表类型、数据存储位置、字段、类型、创建人、类型、分区、分桶等很多信息。元数据默认存储内置的derby数据库中,但是建议存储mysql。
Driver(解释器):将HQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
Compiler(编译器):对hql语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。
Optimizer(优化器):选择一个较好的执行计划并进行优化,(减少不必要的列、使用分区、使用索引等)。
Executor(执行器):将优化后的执行计划(所对应的代码)提交给hadoop的yarn上执行。
hive一般提供两个服务:hiveserver2(第三方服务:jdbc连接和beeline连接等)和metastore(提供元数据连接)。
hive与关系数据库的区别
 hive的数据格式:TextFile、SequenceFile、RCFile、ORC、Parquet
hive的数据格式:TextFile、SequenceFile、RCFile、ORC、Parquet
hive的数据更新:不支持局部更新,支持覆盖更新和追加更新。
Hadoop和hive的关系
1、Hive是基于Hadoop的。
2、Hive本身其实没有多少功能,hive就相当于在Hadoop上面加了一个外壳,就是对hadoop进行了一次封装。
3、Hive的存储是基于HDFS的,hive的计算是基于MapReduce。
在linux下的hive的安装部署
解压
[root@hadoop01 ~]# tar -zxvf /home/apache-hive-2.3.7-bin.tar.gz -C /usr/local/
[root@hadoop01 ~]# mv /usr/local/apache-hive-2.3.7-bin/ /usr/local/hive-2.3.7配置环境变量
[root@hadoop01 ~]# vi /etc/profile
#追加如下内容
export HIVE_HOME=/usr/local/hive-2.3.7/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:
#刷新环境变量
[root@hadoop01 ~]# source /etc/profile
#检查环境变量
[root@hadoop01 ~]# which hive
/usr/local/hive-2.3.7/bin/hive配置
在conf目录下创建hive-site.xml,然后覆盖如下内容即可:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 该参数主要指定Hive的数据存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 该参数主要指定Hive的临时文件存储目录 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/data/hive</value>
</property>
<!--配置mysql的连接字符串-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!--配置mysql的连接驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--配置登录mysql的用户-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置登录mysql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Root123456!</value>
</property>
<!--显示表列名-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--显示库名-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration> 复制mysql驱动包
[root@hadoop01 hive-2.3.7]# cp /home/mysql-connector-java-5.1.28-bin.jar /usr/local/hive-2.3.7/lib/初始化元数据
[root@hadoop01 hive-2.3.7]# schematool -initSchema -dbType mysql初始化 ,在navicat中查看,表如下:

启动
条件:保障hadoop可用、mysql可用。
hive --service metastore &连接hive
[root@hadoop01 hive-2.3.7]# hive














 2564
2564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









