







1. HPA控制器
1.1 HPA水平伸缩简介
HPA(Horizontal Pod Autoscaler)是一种自动扩展机制,用于根据负载自动调整应用程序的副本数量(流量高峰自动扩容,流量降低自动缩容)。
HPA可根据CPU利用率、内存使用率或自定义指标等指标来自动扩展或收缩应用程序的Pod副本数量,以确保应用程序具有所需的计算资源,并能够适应流量的变化。
HPA一般是用来伸缩deployment或者StatefulSet控制器的,也可以结合其他类型控制器,比如cronjob等。
但是它不适用于无法伸缩的控制器,比如daemonset。
公有云支持node级别的弹性伸缩。
1.2 动态伸缩控制器类型
1.2.1 水平pod自动缩放器(HPA)
基于pod资源利用率横向调整pod副本数量。
1.2.2 垂直pod自动缩放器(VPA:Vertical Pod Autoscaler)
不常用
基于pod资源利用率,调整对单个pod的最大资源限制,不能与HPA同时使用。
它与HPA类似,但是不是水平扩展Pod的数量,而是自动调整每个Pod的资源限制(Resource Limits)和请求(Resource Requests)。
1.2.3 集群伸缩(Cluster Autoscaler,CA)
基于集群中node资源使用情况,动态伸缩node节点,从而保证有CPU和内存资源用于创建pod。
1.3 HPA控制器常用参数介绍
下面所有的参数都是通过kube-controller-manager进行配置的
Horizontal Pod Autoscaling (HPA)控制器,根据预定义好的阈值及pod当前的资源利用率,自动控制在k8s集群中运行的pod数量(自动弹性水平自动伸缩)。
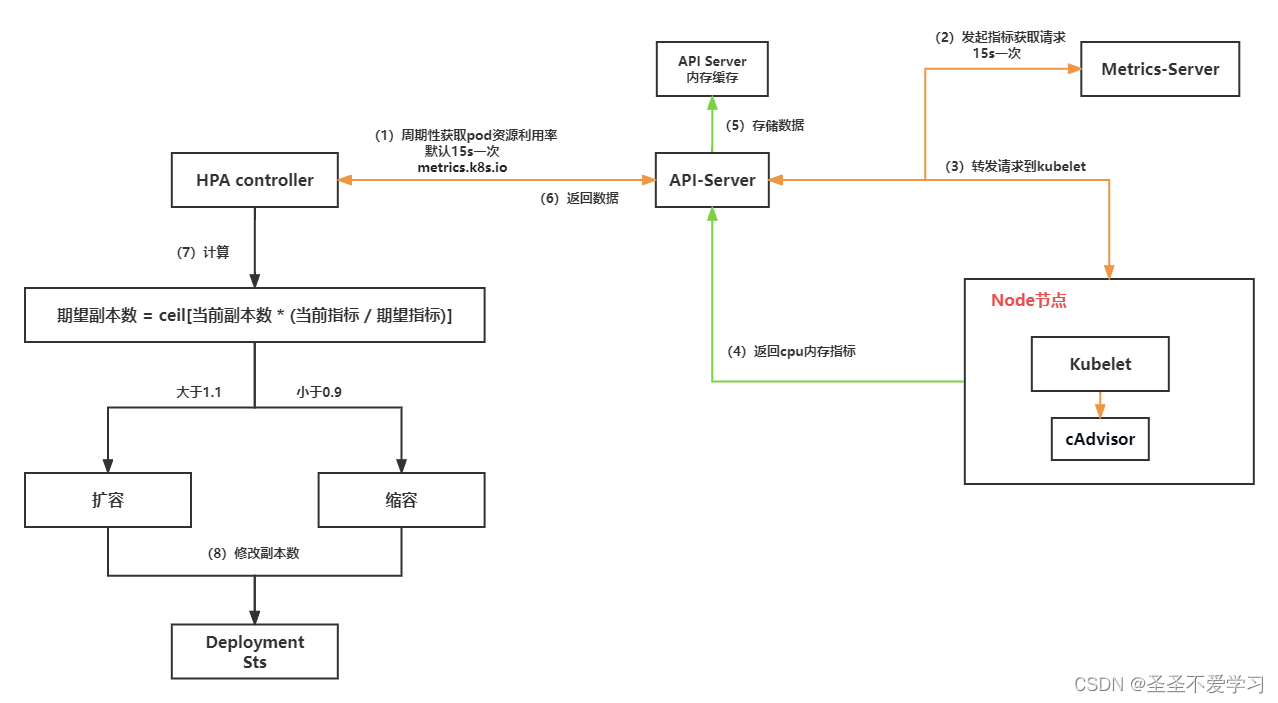
(1)–horizontal-pod-autoscaler-sync-period :HPA控制器同步pod副本数的间隔周期(包含查询metrics的资源使用情况), 默认15s。
(2)–horizontal-pod-autoscaler-downscale-stabilization:缩容间隔周期,默认5分钟(就是pod流量下去后,不会立即进行缩容操作,因为有可能是某写原因导致的流量抖动,可能过一会儿流量又变高, 所以默认会等待5分钟,只有5分钟过后,流量使用没有上升,才会进行缩容操作)。
(3)–horizontal-pod-autoscaler-cpu-initialization-period:初始化延迟时间,在此时间内pod的CPU资源指标将不会生效,默认为5分钟(就是pod刚启动的那会儿,cpu和内存利用率都会比较高,因为在加载各种配置,所以这个时候采集的数据是不准的,因为启动成功后,资源利用率都会下降,所以默认5分钟后才会采集数据)。
(4)–horizontal-pod-autoscaler-initial-readiness-delay:用于设置pod准备时间,在此时间内的pod统统被认为未就绪及不采集数据,默认为30秒(和上面的参数搭配使用的,也就是5分钟+30s,实际要5分30秒后才会开始采集数据,进行扩缩容)。
(5)–horizontal-pod-autoscaler-tolerance :HPA控制器能容忍的数据差异(浮点数,默认为0.1),即新的指标要与当前的阈值差异在0.1或以上, 即要大于1+0.1=1.1,或小于1-0.1=0.9。
比如阈值为CPU利用率50%,当前为80%,那么80/50=1.6 > 1.1则会触发扩容,否则之会缩容。
即触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9=把N个pod的数据相加后根据pod的数量计算出平均数除以阈值,大于1.1就扩容,小于0.9就缩容。
这种设置方式是为了避免在期望值和实际值之间的微小变化时频繁地进行扩缩容操作,从而达到更加平滑和稳定的扩缩容效果。
1.4 HPA的计算公式
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
期望副本数 = 向上取整函数[当前副本数 * (当前指标 / 期望指标)]
文字解释
期望指标:比如我希望pod的cpu使用率不要超过50%
当前指标:但是因为某些原因,pod实际的cpu使用率处于80%-90%之间(如pod 1 当前实际的cpu使用率为85%,pod 2 当前实际的cpu使用率为75%,pod 3 当前实际的cpu使用率为80%,那么当前3个pod的平均cpu使用率为80%,)
当前指标 / 期望指标:那么我们期望的为50%,实际当前平均指标已经80%,所以就需要80 除以 50 = 1.6
当前副本数:3 * 1.6 = 4.8
ceil函数进行向上取整:ceil[4.8] = 5
通过上述运算得出的结果大于默认的1.1,就会触发扩容操作。
1.5 metrics-server 部署
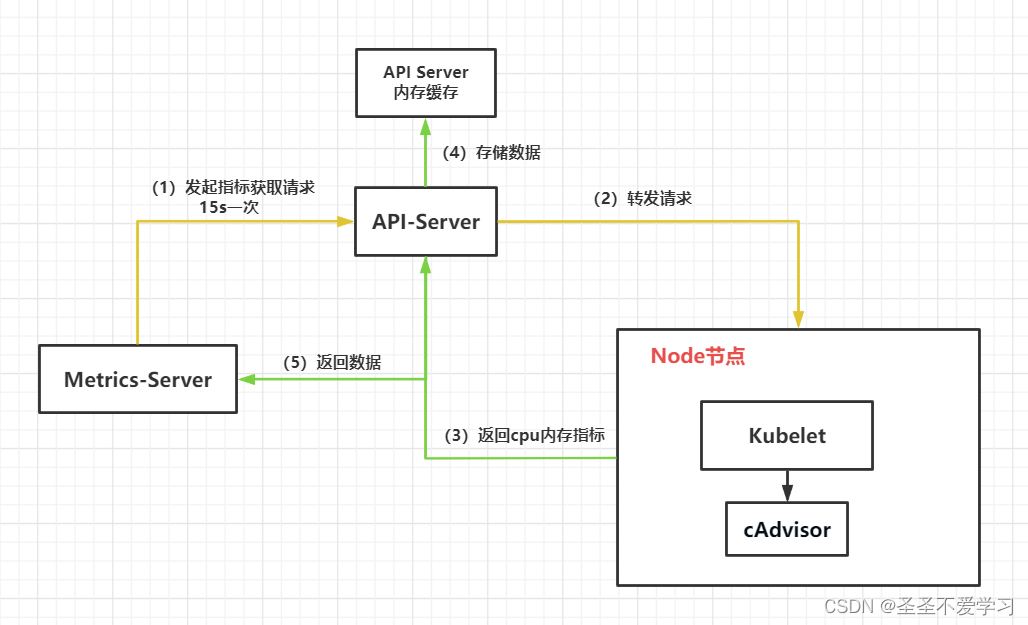
指标数据需要部署metrics-server,即HPA使用metrics-server作为数据源。
Metrics Server是K8s内置的容器资源指标来源,用来统计cpu和内存指标。
Metrics Server从node节点上的Kubelet收集资源指标,并通过Metrics API在K8s apiserver中公开指标数据,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用,
也可以通过访问kubectl top node/pod 查看指标数据。
1.5.1 metrics-server工作原理
1.5.1 metrics-server与k8s版本兼容性说明
官网:https://github.com/kubernetes-sigs/metrics-server

1.5.2 下载yaml
我的k8s版本是1.26.1,所以可以下载0.6.x的。
官网:https://github.com/kubernetes-sigs/metrics-server/releases
https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.3/components.yaml

1.5.3 编辑yaml
[root@k8s-harbor01 metrics-server]# grep image: deploy.yaml
image: registry.k8s.io/metrics-server/metrics-server:v0.6.3 # 官方的镜像可能在国内拉不下来,直接在dockerhub上找到对应版本的替换一下(或者直接上传到自己的镜像仓库)
[root@k8s-harbor01 metrics-server]# sed -i 's#image: registry.k8s.io\/metrics-server\/metrics-server:v0.6.3#image: bitnami\/metrics-server:0.6.3#g' deploy.yaml
[root@k8s-harbor01 metrics-server]# grep image: deploy.yaml
image: bitnami/metrics-server:0.6.3
1.5.4 部署metrics-server
[root@k8s-harbor01 metrics-server]# kubectl apply -f deploy.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
[root@k8s-harbor01 metrics-server]# kubectl get po -A |grep metrics-server
kube-system metrics-server-8c7f58775-btz6v 1/1 Running 0 3m1s
1.5.5 验证
[root@k8s-harbor01 metrics-server]# kubectl top no
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 115m 5% 1055Mi 63%
k8s-master02 98m 4% 1115Mi 66%
k8s-master03 127m 6% 1049Mi 62%
k8s-node01 91m 4% 1291Mi 35%
k8s-node02 114m 5% 1119Mi 30%
k8s-node03 96m 4% 1223Mi 33%
[root@k8s-harbor01 metrics-server]# kubectl top po -n myserver
NAME CPU(cores) MEMORY(bytes)
minio-5cc5fc9498-lmzwh 3m 166Mi
temp-ubuntu 0m 0Mi
[root@k8s-harbor01 metrics-server]# kubectl api-versions |grep metrics
metrics.k8s.io/v1beta1 # 部署好metrics-server后,生成的api接口
1.6 部署HPA
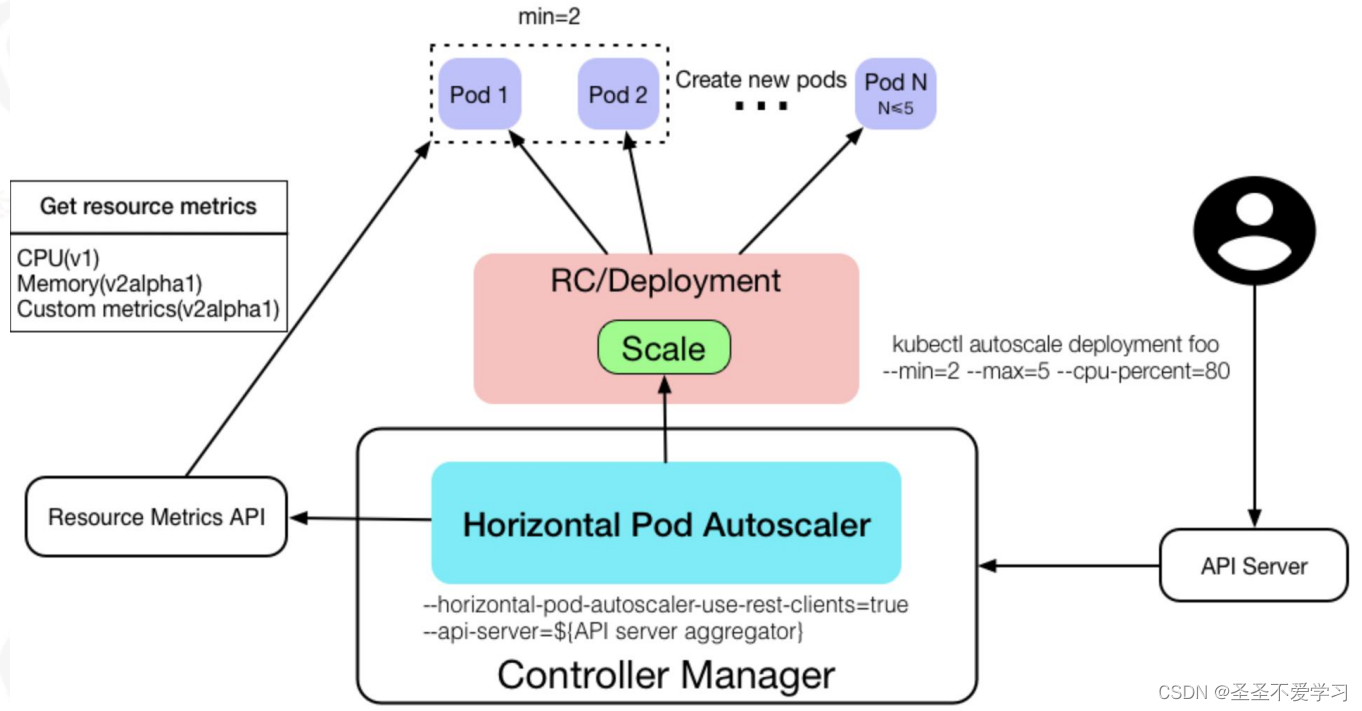
1.6.1 HPA效果图
1.6.2 创建HPA
1.6.2.1 命令行创建讲解
不推荐直接使用命令创建,因为能传递的配置较少
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
--min=2: 最小值2
--max=5:最大值5
--cpu-percent=80:cpu利用率百分比
# 如何计算pod cpu百分比?
HPA有个要求,就是在创建资源(如deployment)的时候,必须指定limits值,否则hpa获取不到相关数据。
假设pod limits cpu为1,当前使用了600m,那就是600 / 1000 = 60%。
创建好了hpa后,它会去找resource metrics api获取某一个控制器(如deployment)下pod的指标,所以我们创建hpa的时候,需要指定我们要检查的控制器的类型(如deployment),以及还需要把hpa创建在该控制器相同名称空间下。
1.6.2.2 yaml文件创建讲解
apiVersion: autoscaling/v2beta1 # 不同的apiVersion不同,写法也不同
#apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
namespace: magedu # HPA控制器必须和被采集数据的资源对象在同一个ns,否则无法实现自动水平伸缩
name: magedu-tomcat-app1-deployment
labels:
app: magedu-tomcat-app1
version: v2beta1
spec: # 这里的写法是针对metrics-server默认的cpu 内存指标来进行扩缩容操作
scaleTargetRef: # 定义水平伸缩的目标对象
apiVersion: apps/v1 # api版本,和被采集数据的资源对象api版本相同
#apiVersion: extensions/v1beta1
kind: Deployment # 目标对象类型
name: magedu-tomcat-app1-deployment # deployment的具体名称
minReplicas: 3 # 最小pod数。一般就是业务低峰期的最小副本数,维持业务日常响应
maxReplicas: 10 # 最大pod数。业务高峰期最多能有10个pod对外提供服务
targetCPUUtilizationPercentage: 60 # 目标CPU利用率百分比。触发水平伸缩的标准,这里达到60%就会扩容,低于60%就缩容
################## 下面的配置,是hpa调用Prometheus来获取相关metrics数据,进行扩缩容
#metrics: # 调用metrics数据定义
#- type: Resource # 类型为Resource
# resource: # 定义资源
# name: cpu # 资源名称
# targetAverageUtilization: 60 # cpu平均利用率
#- type: Resource
# resource:
# name: memory
# targetAverageValue: 1024Mi # 内存平均利用率
1.6.2.3 创建测试pod
[root@k8s-harbor01 metrics-server]# cat tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: tomcat-app1
name: tomcat-app1
namespace: myserver
spec:
replicas: 2
selector:
matchLabels:
app: tomcat-app1
template:
metadata:
labels:
app: tomcat-app1
spec:
containers:
- name: tomcat-app1
image: tsk8s.top/tsk8s/tomcat-app1:v1
#image: lorel/docker-stress-ng
#args: ["--vm", "2", "--vm-bytes", "256M"]
##command: ["/apps/tomcat/bin/run_tomcat.sh"]
imagePullPolicy: IfNotPresent
##imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources: # 使用hpa必须的字段
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
imagePullSecrets:
- name: dockerhub-image-pull-key
---
kind: Service
apiVersion: v1
metadata:
labels:
app: tomcat-app1
name: tomcat-app1-nodeport
namespace: myserver
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: tomcat-app1
[root@k8s-harbor01 metrics-server]# kubectl apply -f tomcat-app1.yaml
deployment.apps/tomcat-app1 created
service/tomcat-app1-nodeport created
[root@k8s-harbor01 metrics-server]# kubectl get po -n myserver |grep tomcat
tomcat-app1-59b496dfd8-cfzz9 1/1 Running 0 28s
tomcat-app1-59b496dfd8-mlrpq 1/1 Running 0 28s
1.6.2.4 创建hpa
[root@k8s-harbor01 myserver]# pwd
/root/yaml/deployment/hpa/myserver
[root@k8s-harbor01 myserver]# cat hpa.yaml
#apiVersion: autoscaling/v2beta1
apiVersion: autoscaling/v1 # 不同的api版本写法不同
kind: HorizontalPodAutoscaler
metadata:
namespace: myserver
name: hpa
labels:
app: tomcat-app1
version: v2beta1
spec:
scaleTargetRef: # metrics-server数据源
apiVersion: apps/v1
#apiVersion: extensions/v1beta1
kind: Deployment
name: tomcat-app1 # deployment控制器名称
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 60
# prometheus数据源
#metrics:
#- type: Resource
# resource:
# name: cpu
# targetAverageUtilization: 60
#- type: Resource
# resource:
# name: memory
[root@k8s-harbor01 myserver]# kubectl apply -f hpa.yaml
horizontalpodautoscaler.autoscaling/hpa created
[root@k8s-harbor01 myserver]# kubectl get hpa -n myserver # 这里需要注意TARGETS下面 0%/60%,如果0%哪里长时间显示是<unknown>,需要检查deployment的yaml有没有设置resources
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa Deployment/tomcat-app1 0%/60% 2 5 2 48s
1.6.2.5 hpa Replicas 和其他控制器Replicas优先级问题
假设deployment Replicas为2,hpa minReplicas为3,谁的优先级更高?
答:hpa 优先级更高,创建hpa后,会根据相关配置对deployment 副本数进行扩容。
1.7 测试hpa自动扩缩容
1.7.1 测试扩容
1.7.1.1 调整测试pod yaml
[root@k8s-harbor01 metrics-server]# cat tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: tomcat-app1
name: tomcat-app1
namespace: myserver
spec:
replicas: 2
selector:
matchLabels:
app: tomcat-app1
template:
metadata:
labels:
app: tomcat-app1
spec:
containers:
- name: tomcat-app1
#image: tsk8s.top/tsk8s/tomcat-app1:v1
image: lorel/docker-stress-ng # 这是一个压测专用镜像
args: ["--vm", "2", "--vm-bytes", "256M"] # 创建2个工作进程,每个进程消耗2核cpu,但是limits只配置了1核cpu,所以这里就会触发扩容,但是由于资源消耗一直超过100%,所以会一直扩容到hpa配置的最大副本数
##command: ["/apps/tomcat/bin/run_tomcat.sh"]
imagePullPolicy: IfNotPresent
##imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
imagePullSecrets:
- name: dockerhub-image-pull-key
---
kind: Service
apiVersion: v1
metadata:
labels:
app: tomcat-app1
name: tomcat-app1-nodeport
namespace: myserver
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: tomcat-app1
[root@k8s-harbor01 metrics-server]# kubectl apply -f tomcat-app1.yaml
deployment.apps/tomcat-app1 configured
service/tomcat-app1-nodeport unchanged
[root@k8s-harbor01 metrics-server]# kubectl get po -A |grep tomcat
myserver tomcat-app1-5456845b74-ghgr8 1/1 Running 0 3s
myserver tomcat-app1-5456845b74-rv5tj 1/1 Running 0 3s
1.7.1.2 观察扩容情况
[root@k8s-harbor01 metrics-server]# kubectl get po -A -w |grep tomcat # 通过-w参数可以看到扩容过程
myserver tomcat-app1-5456845b74-ghgr8 1/1 Running 0 39s
myserver tomcat-app1-5456845b74-rv5tj 1/1 Running 0 39s
myserver tomcat-app1-5456845b74-xnn4z 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-24pkx 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-xnn4z 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-24pkx 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-24pkx 0/1 ContainerCreating 0 0s
myserver tomcat-app1-5456845b74-xnn4z 0/1 ContainerCreating 0 0s
myserver tomcat-app1-5456845b74-xnn4z 1/1 Running 0 2s
myserver tomcat-app1-5456845b74-24pkx 1/1 Running 0 3s
myserver tomcat-app1-5456845b74-89qd5 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-89qd5 0/1 Pending 0 0s
myserver tomcat-app1-5456845b74-89qd5 0/1 ContainerCreating 0 0s
myserver tomcat-app1-5456845b74-89qd5 1/1 Running 0 3s
^C
[root@k8s-harbor01 metrics-server]# kubectl get po -A |grep tomcat
myserver tomcat-app1-5456845b74-24pkx 1/1 Running 0 92s
myserver tomcat-app1-5456845b74-89qd5 1/1 Running 0 77s
myserver tomcat-app1-5456845b74-ghgr8 1/1 Running 0 2m11s
myserver tomcat-app1-5456845b74-rv5tj 1/1 Running 0 2m11s
myserver tomcat-app1-5456845b74-xnn4z 1/1 Running 0 92s
[root@k8s-harbor01 metrics-server]# kubectl describe deploy -n myserver tomcat-app1 # describe也能看到扩容
……省略部分内容
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m46s deployment-controller Scaled up replica set tomcat-app1-5456845b74 to 2
Normal ScalingReplicaSet 2m7s deployment-controller Scaled up replica set tomcat-app1-5456845b74 to 4 from 2
Normal ScalingReplicaSet 112s deployment-controller Scaled up replica set tomcat-app1-5456845b74 to 5 from 4
[root@k8s-harbor01 metrics-server]# kubectl top po -n myserver|grep tomcat # 可以看到每个pod消耗的cpu基本都达到了1核
tomcat-app1-5456845b74-24pkx 938m 424Mi
tomcat-app1-5456845b74-89qd5 958m 355Mi
tomcat-app1-5456845b74-ghgr8 942m 430Mi
tomcat-app1-5456845b74-rv5tj 966m 320Mi
tomcat-app1-5456845b74-xnn4z 1001m 286Mi
[root@k8s-harbor01 metrics-server]# kubectl get hpa -n myserver # 可以看到我们期望的cpu使用率是60,但是当前实际已经达到了192
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa Deployment/tomcat-app1 192%/60% 2 5 5 34m
1.7.2 测试缩容
1.7.2.1 调整测试pod yaml
[root@k8s-harbor01 metrics-server]# cat tomcat-app1.yaml
……省略部分内容
spec:
replicas: 3 # 修改副本数为3,方便观察缩容
image: tsk8s.top/tsk8s/tomcat-app1:v1 # 换回这个正常的镜像测试
#image: lorel/docker-stress-ng
#args: ["--vm", "2", "--vm-bytes", "256M"]
1.7.2.2 观察缩容情况
[root@k8s-harbor01 metrics-server]# kubectl apply -f tomcat-app1.yaml
[root@k8s-harbor01 metrics-server]# kubectl get po -n myserver|grep tomcat
tomcat-app1-59b496dfd8-2qs7m 1/1 Running 0 10s
tomcat-app1-59b496dfd8-65p29 1/1 Running 0 6s
tomcat-app1-59b496dfd8-d5zt2 1/1 Running 0 10s
tomcat-app1-59b496dfd8-f27dr 1/1 Running 0 10s
tomcat-app1-59b496dfd8-slmkc 1/1 Running 0 8s
[root@k8s-harbor01 metrics-server]# kubectl get hpa -n myserver
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa Deployment/tomcat-app1 194%/60% 2 5 5 17h
为什么我副本数写的3个,创建出来却是5个?注意看hpa的REPLICAS哪里也是5,主要是因为hpa缩容需要持续观察pod指标一段时间,默认5分钟,只有5分钟持续资源使用都没有超过我们指定值,才会进行缩容
[root@k8s-harbor01 metrics-server]# kubectl get po -n myserver|grep tomcat # 可以看到5分钟的时候,缩容了多余的pod,保留hpa配置的最小副本数
tomcat-app1-59b496dfd8-2qs7m 1/1 Running 0 5m4s
tomcat-app1-59b496dfd8-65p29 1/1 Terminating 0 5m
tomcat-app1-59b496dfd8-d5zt2 1/1 Running 0 5m4s
tomcat-app1-59b496dfd8-f27dr 1/1 Terminating 0 5m4s
tomcat-app1-59b496dfd8-slmkc 1/1 Terminating 0 5m2s
[root@k8s-harbor01 metrics-server]# kubectl get hpa -n myserver
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa Deployment/tomcat-app1 0%/60% 2 5 2 17h
1.7.3 自动扩缩容过程
1.8 hpa收集Prometheus数据进行伸缩
github:https://github.com/zhangshijle/prometheus-adapter-hpa-files/blob/main/7.2.sample-httpserver-hpa.yaml
hpa默认情况下是基于metrics-server收集的指标进行扩缩容的,但是它收集的指标都比较简单,一般都是根据cpu内存来进行扩缩容。
结合Prometheus就能指定其他类型的指标,进行伸缩,如网卡速率、接口请求次数、tomcat线程数等。
1.9 HPA可以使用的Metrics API
官网:https://v1-26.docs.kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-metrics-apis
(1)对于资源指标,将使用 metrics.k8s.io API,一般由 metrics-server 提供。 它可以作为集群插件启动。
(2)对于自定义指标,将使用 custom.metrics.k8s.io API。 它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。 检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。
(3)对于外部指标,将使用 external.metrics.k8s.io API。可能由上面的自定义指标适配器提供。















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









