







Hadoop的安装与配置
一、 虚拟机的创建
-
单击“创建虚拟机”:

-
在弹出的界面中选择“自定义(高级)”单选按钮,然后单击“下一步”按钮:

-
在进入的界面中单击“下一步”按钮:

-
在进入的界面中选择“稍后安装操作系统”单选按钮,然后单击“下一步”按钮:

-
在进入的界面中选择“Linux(L)”单选按钮版本选择“CentOS 7 64位”,然后单击“下一步”按钮:

-
在进入的界面中将虚拟机名称改为masternode(可改为你想改的名字),设置你要将虚拟机存放的位置,单击“下一步按钮”:

-
在进入的界面中,选择默认配置,然后单击“下一步按钮”:
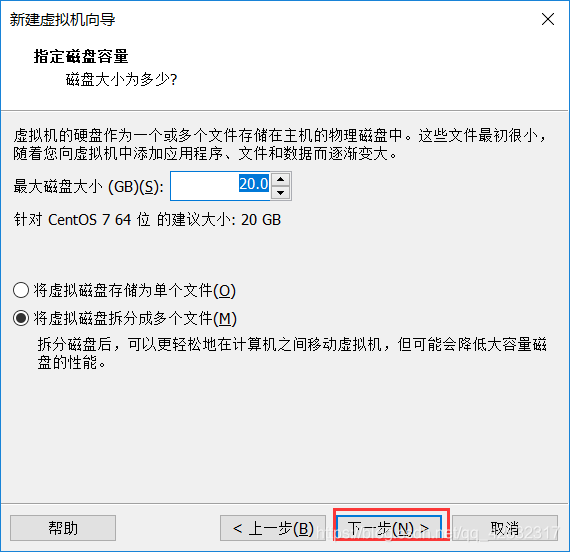
-
接着会出现创建虚拟机的信息,这里不做任何修改,采取默认设置(可点击“自定义硬件”更改想要的硬件配置),直接单击“下一步”按钮,在单击“完成”按钮:

-
之后就会出现如下结果,表示虚拟机安装完成:

二、 安装Linux系统
安装完虚拟机后,接下来就可以基于虚拟机安装CentOS系统了。
-
把CentOS 7 64位系统的版本放到光驱中,单击“CD/DVD”选项:

-
在弹出界面中选中“使用ISO映像文件”单选按钮,然后单击“浏览”按钮,指向CentOS映像文件,再单击“确定”按钮:

-
单击“开启此虚拟机”按钮:

-
单击键盘上的“Enter”按钮,准备安装:

-
点击选中左侧的“中文”,右侧的“简体中文(中国)”,在点击“继续”按钮:
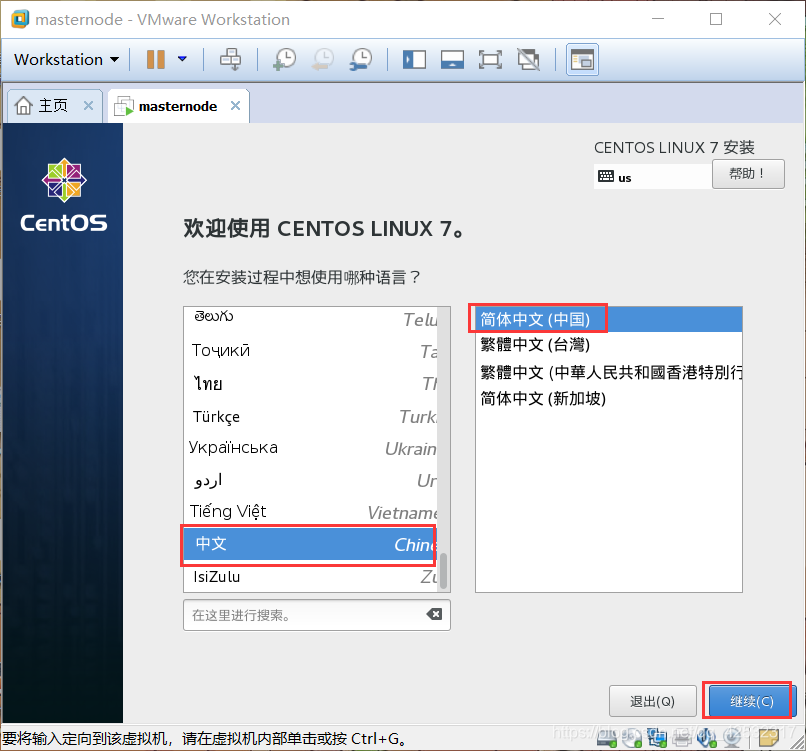
-
等到页面中图标全部点亮后,点击“安装位置”:

-
点击本地标准磁盘下“20GB”图标,点击“完成”按钮:

-
点击“开始安装”按钮:

-
点击“ROOT密码”按钮,设置root密码:

-
设置好密码后,点击“完成”按钮:

-
安装完成后,点击“重启”按钮:

-
输入用户名“root”,设置的密码“admin”后,点击回车即可进入系统:

三、 配置网络信息
前面我们已经成功创建了CentOS系统,但是由于系统还没有配置网络,所以无法访问外网,也无法进行内网机器之间的通信。为了后续搭建集群和访问外网,这里需要进行网络信息的配置。
-
先要设置虚拟机虚拟网络配置信息,点击“编辑”按钮,点击“虚拟网络编辑器”按钮:

-
在弹出的窗口中点击“更改设置”按钮:

-
在新的窗口中点击“添加网络”按钮:

-
在新的窗口中点击“确定”按钮,等待初始化虚拟网络:

-
在最上面的名称单击选中添加的网络名称“VMnet8”,选择“NAT模式”单选按钮,勾选“将主机虚拟适配器连接到此网络”复选框按钮,将子网IP更改为“192.168.88.0”(与我们的虚拟主机在同一网段):

-
点击“NAT设置”按钮,在打开的窗口中将“网关IP”更改为“192.168.88.2”,点击“确定”按钮:
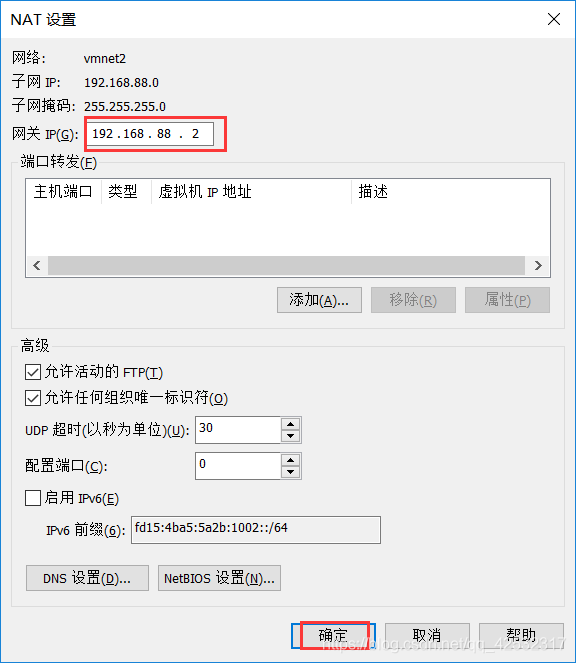
-
回到虚拟网络编辑器窗口,点击“应用按钮”,在点击“确定”按钮即可,现在虚拟网络配置好了,可以继续配置虚拟主机网络了:

-
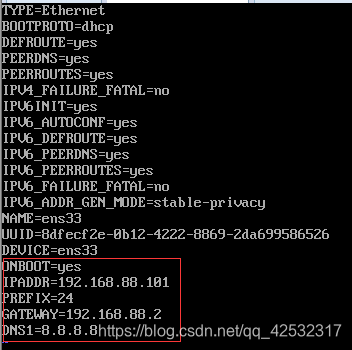
修改配置信息。使用命令“vi /etc/sysconfig/network-scripts/ifcfg-ens33”打开配置文件,将ONBOOT的值更改为“yes”,在末尾添加以下信息“
IPADDR=192.168.88.101
PREFIX=24
GATEWAY=192.168.88.2
DNS1=8.8.8.8
”。
-
重启网络服务。使用命令“service network restart”重启网络服务,结果显示为OK时表示重启成功:

-
测试,访问外网(使用命令“ping www.baidu.com”访问百度),出现如下情形说明访问成功:

四、 克隆服务器
有时为了方便使用,减少重复配置,可以直接将配置好的节点进行克隆,克隆节点时必须在被克隆的节点处于关机状态下。下面我们开始克隆创建出来的masternode。
-
点击“masternode”后鼠标右击,选中“管理”,在选中“克隆”按钮:

-
在弹出的窗口中,选择“虚拟机中的当前状态”,点击“下一步”按钮:

-
在弹出的窗口中,选择“创建完整克隆”,点击“下一步”按钮

-
在弹出的窗口中,在虚拟机名称处填写“slave1node”,在位置处点击“浏览”按钮选择克隆服务器的存储位置,点击“完成”按钮

-
克隆完成:

-
克隆完成之后,由于克隆的信息与被克隆机器完全一致,所以需要将克隆的机器重新进行网络、主机名等信息的设置。网络信息的更改主要是更改克隆节点的IP地址,具体操作,参照上面命令(将slave1node服务器IP设置为“192.168.88.102”)。
-
修改主机名(hostname)。打开克隆服务器slave1node。使用命令“hostnamectl set-hostname slave1node”可将主机名修改为slave1node(可在mastername服务器上将主机名字设masternode):

-
查看主机名。使用命令“hostname”可查看主机名:

-
修改完主机名后,需要重新启动系统生效。重新启动系统,使用命令“init 6”or“reboot”。
-
修改主机(host)文件,这样做的目的是将IP地址和机器名相映射,这样在masternode和slave1node相互通信时,可以直接使用主机名,也可以使用IP地址。使用命令“vi /etc/hosts”对hosts文件进行编辑。在文件最后增加“
192.168.88.102 slave1node
”,代码格式为:虚拟服务器IP地址+空格+主机名称:

-
修改完master主机上的hosts文件后,就可以尝试在masternode上通过ping的方式与slave节点通信,使用命令“ping slave1node”:

五、 SSH免密码登录
在前面已经创建好了两台机器,并且相互之间可以进行通信,这时就需要进行文件的相互传输,如从masernode(节点)传到slave1node(节点),这样就需要用到scp(拷贝)等命令来完成。但是在多态服务器之间操作文件传输时总是需要输入密码,每次都输入密码很麻烦,而且有些安全系统高的机器,密码相当难记,而SSH免密码登录无疑能大大地提高工作效率。
总的来说,服务器A如果要免密码登录到服务器B时,需要在服务器A上生成密匙对,将生成的公匙上传到服务器B上,并把公匙追加到服务器B的authorized_keys信任文件中。具体步骤如下:
-
在服务器A上使用命令“ssh-keygen -t rsa -P ‘’”,创建密匙对:

-
使用命令“scp .ssh/id_rsa.pub root@192.168.88.102:~”传递公匙。(在执行完上述命名后,在执行命令的.ssh文件夹下会生成一个扩展名为.pub的文件。用scp命令将.pub文件复制到slave1node(B服务器)节点上):

需要注意的是,第一次将文件传到slave1node节点时是需要输入密码的,一旦免密码配置完成后,后续在传文件时就不需要再输入密码了。
关闭防火墙
为了使两台机器之间进行通信,还需将每个节点的防火墙都关闭。关闭防火墙有两种方法,一种是永久生效;另一种是立即生效,重启后无效。
-
关闭防火墙,即时生效,重启后无效,使用命令“service iptables stop”(开启为“service iptables start”)
-
关闭防火墙,重启后永久生效,使用命令“chkconfig iptables off”(开启为“chkconfig iptables on”)
出现错误:

-
错误原因:我的虚拟机使用的是CentOS 7。CenOS 7开始默认用的是firewalld,这个是基于iptables的,虽然有iptables的核心,但是iptables的服务是没安装的。所以你只要停止firewalld服务即可
-
解决方法:1)停止firewalld服务,使用命令“sudo systemctl stop firewalld.service”和“sudo systemctl disable firewalld.service”(sudo是linux系统管理指令,是允许系统管理员让普通用户执行一些或者全部的root命令的一个工具):

-
解决方法:2)安装iptables服务使用命令“sudo yum install iptables-services”:


-
解决方法:3)设置开机启动,使用命令“systemctl enable iptables.service”

-
之后就可以使用命令关闭防火墙了:

六、 安装和配置JDK
上传安装包
-
打开软件Xftp,输入masternode主机的IP,输入用户名密码点击“确定”按钮,最后点击“连接”按钮:

-
在左边界面找到需要上传到虚拟机的安装包,选中将它拖到右边界面,等待下方传输完成,即为上传成功:

解压缩JDK压缩包
-
使用命令“mkdir –p /test/hadoop/jdk”创建安装JDK目录

-
使用命令“tar -C /test/hadoop/jdk -zxvf jdk-8u261-linux-x64.tar.gz”将JDK安装到上述目录:
配置环境变量
环境变量是一个具有特定名字的对象,它包含一个或者多个应用程序会使用到的信息。通过使用环境变量,可以很容易地修改涉及的一个或多个应用程序的配置信息。Linux是一个多用户、多任务的操作系统,通常每个用户默认的环境都是相同的,这个默认环境实际上就是一组环境变量的定义。
-
使用命令“vi /etc/profile” 进入修改profile配置文件,在文件的末尾添加“
export JAVA_HOME=/test/hadoop/jdk/jdk1.8.0_261
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
”:

-
使用命令“source /etc/profile”使配置文件生效:

-
使用命令“java -version”查看版本信息,显示版本信息则安装成功:

七、 Hadoop环境变量配置
解压缩Hadoop压缩包(安装Hadoop 2.x版本)
将Hadoop压缩包上传到服务器后,就需要进行解压缩了。
-
使用命令“mkdir -p /test/hadoop/hadoop2”创建安装Hadoop目录:

-
使用命令“tar -C /test/hadoop/hadoop2 -zxvf hadoop-2.7.7.tar.gz”将Hadoop安装到上述目录:

配置Hadoop的bin和sbin文件夹到环境变量中
解压完Hadoop后,就可以修改etc目录下的profile配置文件,将Hadoop的环境信息写到配置文件中。其中需要注意,要将Hadoop下的bin文件夹和sbin文件夹都写入配置文件中,其中sbin文件夹中是管理命令,如启动和关闭集群等。
-
使用命令“vi /etc/profile” 进入修改profile配置文件,在文件的末尾添加“
export HADOOP_HOME=/test/hadoop/hadoop2/hadoop-2.7.7
export PATH=$PATH: H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin
”:

-
使用命令“source /etc/profile”使配置文件生效:
修改/etc/hadoop/hadoop-env.sh
接着需要在/etc/hadoop/hadoop-env.sh中配置JAVA_HOME,否则调用start-dfs.sh启动时会报错(Error: JAVA_HOME is not set and could not be found)。
- 使用命令“vi /test/hadoop/hadoop2/hadoop-2.7.7/etc/hadoop/hadoop-env.sh”进入hadoop-env.sh文件,将export JAVA_HOME=的值修改为jdk安装路径,如“export JAVA_HOME=/test/hadoop/jdk/jdk1.8.0_261”:

八、 Hadoop分布式安装
Hadoop安装可以是单节点、伪分布式和完全分布式。
伪分布式安装
伪分布式是在一台机器上模拟分布式,主要用于测试
-
使用命令“cd /test/hadoop/hadoop2/hadoop-2.7.7/etc/hadoop/”进入Hadoop安装目录的配置文件目录:

-
修改core-site.xml文件。这个文件主要配置了访问Hadoop集群的主要信息,其中masternode代表主机名称,也可以使用IP替换,9000代表端口。外部通过配置的hdfs://masternode:9000信息,就可以找到Hadoop集群。使用命令“vi core-site.xml”,在里面的configuration标签内添加如下信息:“
fs.defaultFS
hdfs://masternode:9000
”:

-
修改hdfs-site.xml。这个配置文件中配置了HDFS的相关信息,其中dfs.replication代表副本数,这里设置为1。使用命令“vi hdfs-site.xml”,在配置文件里面的configuration标签内添加如下信息:“
dfs.replication
1
”:

-
格式化HDFS。作用是初始化集群,基本配置完成后,使用命令“cd /test/hadoop/hadoop2/hadoop-2.7.7/”进入Hadoop安装目录,然后就可以通过使用命令“hdfs namenode -format”初始化集群了,从以下显示信息中可以看到/name has been successfully formatted(名字已成功格式化),代表格式化成功:

-
启动HDFS。使用命令“start-dfs.sh”启动HDFS,然后访问网页http://192.168.88.101:50070/查看是否安装成功。出现下图显示的页面则代表伪分布式集群搭建成功:

-
使用命令“jps”也能测试是否启动成功,出现SecondaryNameNode和NameNode即为启动成功,如下图:

完全分布式安装
完全分布式是由两个及两个以上的节点完成Hadoop集群搭建,是真正的分布式。下面基于两个节点完成,一个节点名字是masternode,另一个节点名字是slave1node。关于搭建伪分布式和完全分布式,主要区别体现在core-site.xml和hdfs-site.xml的配置不一样,完全分布式会包含更多信息,下面来逐步说明。
-
修改core-site.xml文件。这个配置文件中,hadoop.tmp.dir是Hadoop文件系统依赖的基础设置,默认存放在/tmp/{$user}下。但是存放在/tmp下是不安全的,因为系统重启后文件可能被删除,所以会指向另外的路径,这里我们指定为Hadoop安装目录下的tmp文件夹。使用命令“cd /test/hadoop/hadoop2/hadoop-2.7.7/etc/hadoop/”进入Hadoop安装目录的/etc/hadoop目录下,使用命令“vi core-site.xml”打开配置文件,在configuration标签中写入以下信息“
fs.defaultFS
hdfs://masternode:9000
hadoop.tmp.dir
/test/hadoop/hadoop2/tmp
”:

-
修改hdfs-site.xml文件。这里主要配置了Secondary NameNode的信息,其中slave1node是从节点机器名。使用命令“vi hdfs-site.xml”打开配置文件,在configuration标签中写入以下信息“
dfs.namenode.secondary.https-address
slave1node:50090
dfs.namenode.secondary.https-address
slave1node:50091
”:

-
配置masters和slaves文件。接着需要在配置文件目录也就是Hadoop安装目录下的/etc/hadoop/下生成masters和slaves文件,并在masters文件中写入masternode,在slaves文件中写入masternode和slave1node,其中slaves文件存放的是datanode,也就是数据节点。需要注意的是,这里的masternode和slave1node是节点名称,需要与/etc/hosts中的配置相映射。
-
使用命令“vi masters”在文件里面写入“masternode”:


-
使用命令“vi slaves”在文件里面写入“masternode slave1node”:

-
使用命令“vi /etc/hosts”在最后面添加如下内容“
192.168.88.101 masternode
192.168.88.102 slave1node
”,使IP与主机名相映射:


-
在/hadoop2目录下创建存放Hadoop文件系统依赖的基础设置文件夹tmp,使用命令“cd /test/hadoop/hadoop2/”进入hadoop2目录,使用命令“mkdir tmp”创建tmp文件夹:

-
相关文件的复制。在完全分布式的环境中,masternode和slave1node节点上的文件需要一致,因此这里需要将masternode节点中的文件复制到slave节点中,主要包括以下文件:
Hadoop整个文件夹,如/test/hadoop/hadoop2下面的所有文件;
JDK整个文件夹,如/test/hadoop/jdk下面的所有文件;
系统配置文件,如/etc/profile文件,其中包含各类环境变量的配置;
/etc/hosts文件。 -
在slave1node节点上,使用命令“mkdir -p /test/hadoop”创建/test/hadoop目录:

-
回到masternode节点,复制Hadoop整个文件夹。使用命令“scp -r /test/hadoop/hadoop2 root@192.168.88.102:/test/hadoop”复制文件,部分截图如下:

-
复制JDK整个文件夹。使用命令“scp -r /test/hadoop/jdk root@192.168.88.102:/test/hadoop”复制文件,部分截图如下:

-
复制系统配置文件。使用命令“scp /etc/profile root@192.168.88.102:/etc/profile”:

-
复制/etc/hosts文件。使用命令“scp /etc/hosts root@192.168.88.102:/etc/hosts”:

-
进入slave1node节点,使用命令“source /etc/profile”使slave1node节点配置文件生效:

-
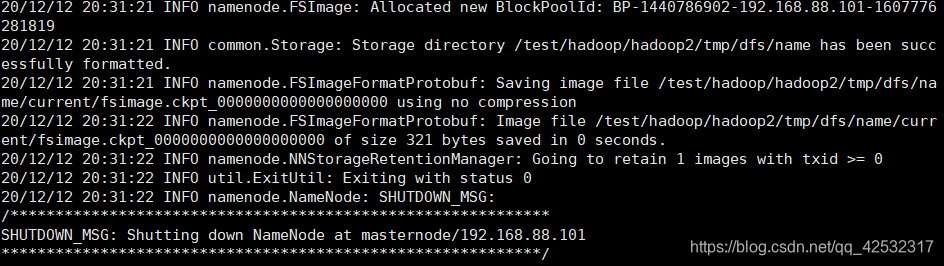
格式化HDFS。使用命令“hdfs namenode -format”初始化集群:
-
启动HDFS集群。使用命令“start-dfs.sh”启动HDFS:
-
在浏览器访问http://ip:50070/,进行测试。例如:访问网页http://192.168.88.101:50070/查看是否安装成功。出现下图显示的页面则代表完全分布式集群搭建成功:

-
使用命令“jps”也能测试是否启动成功,如下图:

Slave1node节点“jps”如下,(结束进程:kill -9 3678):

其他Hadoop相关文件
1.Hadoop的安装与配置(伪分布式+完全分布式)
https://download.csdn.net/download/qq_42532317/14928491
2.Hadoop 3 HDFS完全分布式搭建
https://download.csdn.net/download/qq_42532317/14928492
3.虚拟机安装Hadoop集群(3个集群)
https://download.csdn.net/download/qq_42532317/14929113
4.大数据Hadoop完全分布式搭建(3个集群、Zookeeper、Hive、HBase)
https://download.csdn.net/download/qq_42532317/14929020














 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









