







一、优化的范围
代码优化的目标是在编译时发现有关程序运行时行为的信息,并利用该信息来改进编译器生成的代码。改进可能有许多种形式。优化最常见的目标是提高编译后代码的运行速度。但对于某些应用程序来说,编译后代码的长度要比其执行速度更重要。例如,考虑某个将烧录到只读存储器的应用程序,其代码长度会影响整个系统的成本。优化的其他目标包括降低执行的能耗、提高代码对实时事件的响应、降低对内存的总访问量、优化寄存器的使用等。
一般来说,变换和支持变换的分析作用于四种不同的范围之一:局部的、区域性的、全局的或整个程序。
1.1 局部方法
基本程序块:简称基本块,其中只有一个入口和一个出口,入口就是其中的第—个语句,出口就是其中的最后一个语句。对一个基本块来说,执行时只从其入口进入,从其出口退出。
局部方法作用于单个基本程序块:最长的一个无分支代码序列。在一个ILOC程序中,基本程序块从一个带标号的操作开始,结束于一个分支或跳转操作。在ILOC中,分支或跳转之后的操作必须加标号,否则将成为执行无法到达的“死代码”;而其他类型的符号表示法允许使用“落空”分支,所以分支或跳转之后的操作不必加标号。与包含分支和循环的代码相比,无分支代码的行为更易于分析和理解。
在基本程序块内,有两个重要的性质。第一,语句是顺序执行的。第二,如果任一语句执行,那么整个程序块必定也执行,除非发生运行时异常。与更大的代码范围相比,这两个性质使得编译器能够利用相对简单的分析来证明更强的事实。因而,局部方法有时能够作出在更大范围上无法达到的改进。但是,局部方法只能改进出现在同一基本程序块中的各个操作。
1.2 区域性方法
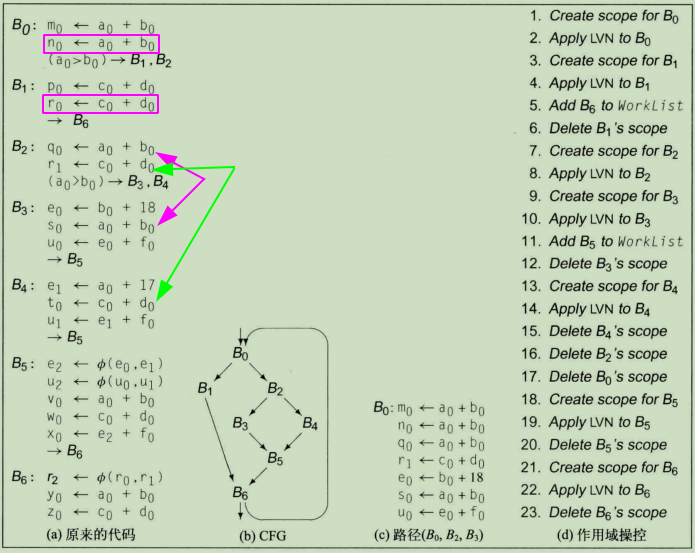
区域性方法的作用范围大于单个基本程序块,而小于一个完整的过程。在下图的控制流图(CFG)例子中,编译器可能将整个循环{B0,B1,B2,B3,B4,B5,B6}作为一个区域考虑。有时候,与考虑整个过程相比,考虑完整过程代码的一个子集,能够进行更敏锐的分析并得到更好的变换结果。例如,在循环嵌套内部,编译器也许能证明一个大量使用的指针是不变量(单值),尽管该指针可能在过程中其他地方修改。这样的知识能够用来进行一些优化,比如将该指针引用的值保持在寄存器中等。
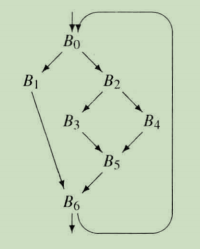
一组基本程序块集合{
β
\beta
β1、
β
\beta
β2、… 、
β
\beta
βn},其中
β
\beta
β1具有多个CFG前趋结点,而其他每个
β
\beta
βi都只有一个CFG前趋结点,且前趋结点为集合中的
β
\beta
βj。我们将符合这种定义的基本程序块集合,称为扩展基本程序块(ExtendedBasicBlock, EBB)。
编译器可以用许多不同的方式来选择需要优化的区域。编译器可以考察区域中形成扩展基本程序块的基本程序块集合。上图例子CFG包含3个EBB:{B0,B1,B2,B3,B4}、{B5}和{B6} 。虽然两个单程序块的EBB相对于纯粹的局部视图并没有什么优势,但较大的那个EBB是可以提供优化时机的(如3.1 超局部值编号)。最后,编译器可以考虑通过某种图论性质定义的CFG子集,如CFG中的支配关系或强连通分量。
1.3 全局方法
这种方法也称为过程内方法,它使用整个过程作为上下文。全局方法的动机很简单:局部最优的决策,在更大的上下文中可能带来坏的结果。对于分析和变换来说,过程为编译器提供了一个自然的边界。过程是一种抽象,封装和隔离了运行时环境。同时,过程在许多系统中也充当了分离编译的单位。
全局方法通常的工作方法是:建立过程的一个表示(如CFG),分析该表示,然后变换底层的代码。如果CFG有环,则编译器必须首先分析整个过程,然后才能确定在特定基本程序块的入口上哪些事实是成立的。因而,大多数全局变换的分析阶段和变换阶段是分离的。分析阶段收集事实并对其进行推断。变换阶段使用这些事实来确定具体变换的安全性和可获利性。借助于全局视图,这些方法可以发现局部方法和区域性方法都无法发现的优化时机。
1.4 过程间方法
这些方法有时称为全程序方法,考虑的范围大于单个过程。任何涉及多于一个过程的变换,我们都认为其是过程间变换。正如从局部范围移动到全局范围会揭示新的优化时机一样,从单个过程转移到多个过程也能够暴露新的优化时机。它也提出了新的挑战。例如,参数结合规则使得用于支持优化的分析大大复杂化。
至少在概念上,过程间分析和优化作用于程序的调用图。有时候,这些技术会分析整个程序;在其他情况下编译器可以只考察源代码的一个子集。过程间优化的两个经典例子是内联替换(inline substitution)和过程间常数传递(inte rprocedural constant propagation),前者将过程调用原地替换为被调用者过程体的一个副本,后者在整个程序中传播并合并有关常数的信息。
二、局部优化
局部优化常用的主要有两种方法:一个是值编号(value numbering),用于查找基本程序块中的冗余表达式(如果在通向位置p的每条代码路径上,表达式e都已经进行过求值,那么表达式e在位置p处是冗余的),通过重用此前计算过的值来替换冗余的求值。另一个是树高平衡(tree-height balancing),用于重新组织表达式树,以揭示更多指令层次的并行性。
2.1 局部值编号
考虑下图所示包含4条语句的基本程序块,我们将该块称之为B。一个表达式(如b+c或a-d),当且仅当它在B中此前已经计算过,且在此之间并无其他运算重新定义组成表达式的各个参数值时,我们称它在B中是冗余的。在B中,第3个运算中出现的b+c不是冗余的,因为第2个运算重新定义了b。第4个运算原来的基本程序块中出现的a-d是冗余的,因为在第2和第4个运算之间B没有重新定义a或d。

编译器可以重写该基本程序块,使之只计算a-d一次,如上图所示。a-d的第二次求值被替换为b的一个副本。另一个策略是将后来使用的d替换为b。但这种方法需要进行分析,来确定在d的某次使用之前b是否被重新定义过。实际上更简单的做法是:让优化器先插人一个复制操作,接下来由后续的一趟处理来判断,哪些复制操作实际上是否是必需的,哪些复制操作的源和目标名是可以合并的。
一般来说,将冗余的求值替换为对先前计算值的引用是有利可图的,即由此生成的代码总是比原来运行得更快速。但这种可获利性是不能保证的。将d = a - d替换为d = b,有可能会扩展b的生命周期并缩短a或d的生命周期(一个名字的生命周期是介于其定义位置和各个使用位置之间的代码区域。这里,定义意味着赋值。)。在任何一种情况下,生命周期的延长与缩短都取决千对相应值的最后一次使用所处的位置。根据具体细节情况的不同,各个重写可能会提高对寄存器的需求、减少对寄存器的需求或保待不变。如果将冗余计算替换为引用会导致寄存器分配器逐出基本程序块中的某个值,那么这种重写很可能是无利可图的。
人们已经开发出了许多用于发现并消除冗余的技术,局部值编号是这些变换中最古老也最强大的技术之一。它可以发现基本程序块内部的冗余,并重写该程序块以避免冗余。它为其他局部优化(如常量合并和使用代数恒等式进行的化简)提供了一套简单且高效的框架。
2.1.1 算法
值编号背后的思想很简单。算法遍历基本程序块,并为程序块计算的每个值分配一个不同的编号。该算法会为值选择编号,使得给定两个表达式ei和ej,当且仅当对表达式的所有可能的运算对象,都可以验证ei和ej具有相等的值时,二者具有相同的值编号。
下图给出了基本的局部值编号 ( Local Value Numbering , LVN ) 算法。

LVN的输入是一个具有n个二元运算的基本程序块,每个运算形如Ti = Li OPi Ri ,LVN算法会按顺序考察每个运算。它使用一个散列表来将名字、常数和表达式映射到不同的值编号,该散列表最初是空的。
为处理第i个运算,LVN在散列表中查找Li和Ri,获取与二者对应的值编号。如果算法找到对应的表项,LVN将使用该项包含的值编号;否则,算法将创建一个表项并分配一个新的值编号。
给出Li和Ri的值编号,分别记作VN(Li)和VN(Ri),LVN算法会基于{ VN(Li),Opi,VN(Ri) }构造一个散列键,并在表中查找该键。如果存在对应的表项,那么该表达式是冗余的,可以将其替换为对此前计算值的引用;否则,运算i是该程序块中对此表达式的第一次计算,因此LVN会为对应的散列键创建一个散列表项,并为该表项分配一个新的值编号。算法还将散列键的值编号(新的或现存的)分配给对应于Ti的表项。因为LVN使用值编号而非名字来构造表达式的散列键,它实际上可以通过复制和赋值操作来跟踪值的流动,如前面标题为“赋值的效果”的小例子。
将3.1中的例子带入算法
下图的版本以上标的形式给出了LVN分配的值编号。在第一个运算时,维护值编号的散列表为空,b和c分别获得新的值编号0和1。LVN会构造出文本字符串“0+1”作为表达式b+c的散列键,在表中进行查找。由于找不到对应该键的表项,查找将失败。因此,LVN将为键“0+1”创建一个新的表项,为其分配值编号2。LVN接下来为a创建一个表项,并将表达式的值编号2分配给它。顺次对每个运算重复此处理过程,将生成如右侧所示的其余值编号。

值编号正确地揭示出,b+c的两次出现分别会产生不同的值,因为二者之间重新定义了b。另一方面,a-d的两次出现将生成同样的值,因为这两个表达式具有相同的输入值编号和运算符。LVN算法会发现这一事实,并通过为b和d分配相同的值编号4将其记录下来。这个知识使LVN能够将第4个运算重写为d=b,如上图所示。后续的各趟处理可能会消除掉这个复制操作。
2.1.2 扩展LVN算法
LVN提供了一个自然的框架,可以在此基础上为LVN算法添加一些扩展。
- 交换运算:对于可交换的运算来说,如果两个运算只是运算对象出现顺序不同(如
axb和bxa),那么二者应该分配同样的值编号。在LVN为当前运算的右侧表达式构造散列键时,它可以使用某种方便的方案对各个运算对象排序,如按照值编号排序。这个简单的操作将会确保“同一”交换运算的不同变体分配到同一个值编号。 - 常量合并:如果一个运算的所有运算对象都具有已知的常数值,那么LVN可以(在编译时)执行该运算并将结果直接合并到生成的代码中。LVN可以在散列表中存储有关常数的信息,包括其值。在构造散列键之前,算法可以判断运算对象是否为常数,如有可能,可以对运算对象求值。如果LVN发现一个常量表达式,它可以将表达式替换为对相应结果的立即数加载操作。后续的复制合并(copy folding)会清理代码(消除不必要的复制操作)。
- 数恒等式:LVN可以应用代数恒等式来简化代码。例如,
x+0和x应该分配同样的值编号。遗憾的是,LVN需要为每个恒等式增加特例处理代码。这需要一系列的条件判断(每个恒等式一个判断),而过多的条件判断语句很容易导致代码的运行速度降低到让人无法接受的程度。为改善这个问题,LVN应该将这些条件判断组织到特定于运算符的决策树中。因为每个运算符只有少量恒等式,这种方法可以使开销保持在比较低的水平。下图给出了可以用这种方法处理的部分恒等式。

2.1.3 命名的作用
变量和值的名称的选择可能会限制值编号算法的有效性。考虑一下将LVN算法用于下图给出的基本程序块时,将会发生何种情况。同样,上标表示分配给每个名字和值的值编号。
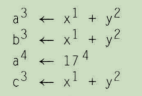
在第一个运算中,LVM将1分配给x,2分配给y,3分配给x+y和a。在处理第二个运算时,算法发现x+y是冗余的,已经分配了值编号3。因此,它重写b = x+y,将其替换为b = a。第三个运算比较简单,并不冗余。在处理第四个操作时,算法再次发现x+y是冗余的,已经分配了值编号3。但它无法将该运算重写为c = a,因为a的值编号已经不再是3了。
可以用两种不同的方法来解决这个问题:
- 一种方法是,修改LVN,使之维持一个从值编号到名字的映射。在对某个名字(比如说a)赋值时,算法必须将a从其旧的值编号对应的列表中删除,并将其添加到新的值编号对应的列表中。这样,在进行替换时,算法可以使用当前对应于所述值编号的任何名字。这种方法对各个赋值操作的处理增加了一些代价, 且使得基本算法的代码变得杂乱。
- 另一种方法是,编译器重写代码,为每个赋值操作分配一个新的不同的名字。如下图所示,为每个名字添加一个下标来保持唯一性就足够了。在加入这些新的名字之后,代码对每个值都有且只有一次定义。因而,不会有值因重新定义而“丢失”或“被杀死”。如果我们对该基本程序块应用LVN,算法将生成所需要的结果。该算法可以证明第二和第四个操作是冗余的:二者都可以被替换为以a0为源的复制操作。按照这种方法重写后的代码其实就是SSA(静态单赋值)形式的代码。

2.1.4 间接赋值的影响
前面的讨论都假定赋值操作是直接且显然的,如a = bxc。但许多程序包含了间接赋值,其中编译器可能不知道需要修改哪个值或哪个内存位置。这样的例子包括通过指针进行的赋值(如C语言中的*p=0),或对结构成员或数组元素进行的赋值(如FORTRAN中的a(i, j)=0)。间接赋值使得值编号及其他优化复杂化,因为它们导致编译器对值流动的推测出现误差。
考虑前一节给出的利用下标命名方案进行的值编号算法。为管理下标,编译器需要维护一个从基本变量名(假定为a)到其当前下标的映射。在进行赋值操作时(如a = b+c),编译器只是对a的当前下标加1,而值表(值编号的哈希表必须反映出带下标的名字,射到下标)中对应于前一个下标的项保持不变。在进行间接赋值时(如*p = 0),编译器可能不知道需要对哪个基本名的下标加1。
没有对p可能指向的内存位置的具体知识,编译器必须对该赋值操作可能修改的每个变量的下标都加1,这可能涉及所有变量的集合。类似地,诸如a(i, j)=0这样的赋值操作,如果i或j的值是未知的,那么编译器在处理时,必须假定该操作改变了a中每个元素的值。不过编译器可以进行分析来消除指针引用的歧义,即缩小编译器认为指针能够访问的变量集合的范围。类似地,编译器可以使用各种技术来推断数组中元素访问的模式,同样可以缩减编译器必须假定的、为单个元素赋值时可能被修改的内存位置的集合。
2.2 树高平衡
许多现代处理器有多个功能单元,因而可以在每个周期中执行多个独立的操作。如果编译器可以通过对指令流的编排使之包含独立的多个操作,并以适当的特定于机器的方法进行编码,那么应用程序会运行得更快。考虑下图给出的用于处理表达式a+b+c+d+e+f+g+h的代码:

从左到右的求值过程将生成如下图a所示的左结合树,其他允许的求值方式对应的树包括下图b和下图c中给出的那些。每棵不同的树都意味着在执行次序上施加了一些加法规则不需要的约束。左结合树意味着,在程序执行涉及g或h的加法之前,它必须先求a+b的值。右递归语法将建立对应的右结合树,意味着在程序执行涉及a或b的加法之前,它必须先求g+h的值。平衡树施加的约束相对较少,但与实际的运算相比,其中仍然隐含着一种求值顺序,相当于增加了约束。
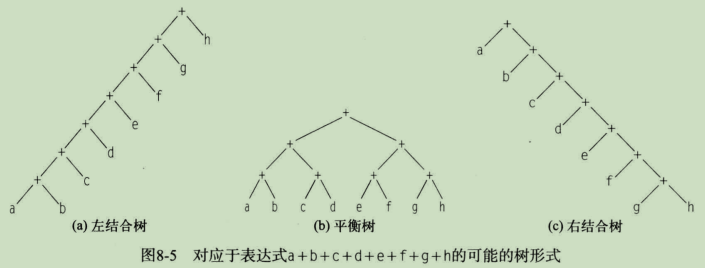
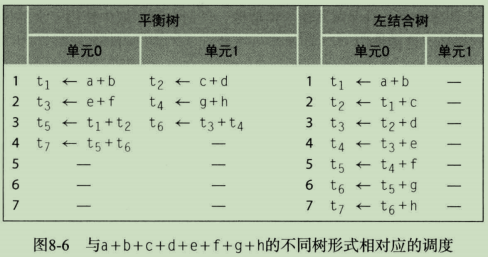
如果处理器每次可以执行多个加法,那么平衡树应该能让编译器为所述计算生成一个较短的调度。图8-6给出了平衡树和左结合树在具有两个单周期加法器的计算机上可能的调度。平衡树可以用4个周期执行完成,其中第4个周期有一个单元是空闲的。相比之下,左结合树需要7个周期,在整个计算过程中第二个加法器都处于空闲状态,左结合树的形式迫使编译器串行执行各个加法运算。
以上这个小例子暗示了一种重要的优化:利用运算的交换律和结合律,来揭示表达式求值中额外的并行性。本节的余下部分将给出一个重写代码的算法,以建立树型近似于平衡树的表达式。这种特定的变化意在向编译器的指令调度器揭示更多的并发操作即指令级并行,从而改进执行时间。算法的主要步骤分为找到候选树、调整候选树使之具有平衡形式。
2.2.1 找到候选树
找到候选树的其实就是找代码块中的数据依赖关系图,即值从创建之处(定义)到使用之处(使用)的流动。在查找树的阶段还需要知道,对程序块中定义的每个名字Ti,以及何处引用了Ti。算法假定有一个集合Uses(Ti),其中包含了程序块中使用Ti的每一个操作/指令的索引。如果Ti在该程序块之后使用,那么Uses(Ti),应该包含两个额外的项,这两项都是一个大于程序块中操作数目的任意整数。这个技巧确保:当且仅当x作为局部临时变量使用时,才有|Uses(x)I = 1。
以下是用于平衡基本程序块算法的第一阶段,算法的这一阶段将遍历程序块中的各个操作。它会判断每一个操作,看是否一定要将该操作作为其自身所属树的根结点。在找到根结点时,它会将该操作定义的(值的)名字添加到由名字组成的优先队列中,该队列按根结点运算符的优先级排序,即优先队列。
// Rebalance a block b of n operations, each of form "T_i <- L_i Op_i R_i"
// Phase 1: build a queue,Roots,of the candidate trees
Roots <- new queue of names
for i <- 0 to n-1
Rank(T_i) <- -1;
if Op_i is commutative and assoiative and (|Uses(T_i)| > 1 or (|Uses(T_i)| = 1 and Op_Uses(T_i) != Op_i)) then
mark T_i as a root;
Enqueue(Roots, T_i, precedence of Op_i);
识别根结点的判断包括两部分。假定操作i形如Ti <- Li Opi Ri,首先,Opi必须是可交换和可结合的。其次,下列两个条件之一必须成立。
- 如果Ti使用多次,那么操作
i必须标记为根结点,以确保对所有使用Ti的操作,Ti都是可用的。对Ti的多次使用使之成为一个可观察量。 - 如果Ti只在操作
j中使用一次,但Opi != Opj,那么操作i必定是一个根结点,因为它不可能是包含Opi的树的一部分。
对于上述两种情况,第一阶段都将Opi标记为根结点,并将其加入优先队列。
2.2.2 重构程序块使之具有平衡的形式
算法的第二阶段以第一阶段收集到的候选树根结点的队列作为输入,并根据每个根结点建立一个大体上平衡的树。第二阶段从一个while循环开始,对每一个候选树根结点调用Balance,Balance分配一个新队列,然后调用Flatten递归遍历树,为每个操作数指派等级并将其添加到队列中。在候选树进行了“扁平化”处理并为各个操作数设定了等级后,Balance将调用Rebuild来重构原来的代码。
Rebuild使用了一个简单的算法来构造新的代码序列,它重复地从树中移除两个等级最低的项。该函数将输出一个操作来合并这两项。它会为结果分配一个等级,然后将结果插回到优先队列中。这个过程会待续下去,直至队列变空为止。
// Phase 2: remove a tree from Roots and rebalance it
while (Roots is not empty)
var <- Dequeue(Roots);
Balance(var);
// 从root开始,构建一个平衡树, T_i in "T_i <- L_i Op_i R_i"
Balance(root)
if Rank(root) >= 0 then
return; // 已经处理过这个树
q <- new queue of names; // First, flatten the tree
Rank(root) <- Flatten(L_i, q) + Flatten(R_i, q);
Rebuild(q, Op_i); // 重构一个平衡树
// Flatten计算var的rank并构建队列
Flatten(var, q)
if var is a constant then // Cannot recur further
Rank(var) <- 0;
Enqueue(q, var, Rank(var));
else if var in UEV_AR(b) then // Cannot recur past top of block
Rank(var) <- 1;
Enqueue(q, var, Rank(var));
else if var is a root then // New queue for new root
Balance(var); // Recur to find its rank
Enqueue(q, var, Rank(var));
else // var is T_j in j-th op in block
Flatten(L_j, q); // Recur on left operand
Flatten(R_j, q); // Recur on right operand
return Rank(var);
// 建立平衡的表达
Rebuild(q, Op)
while (q is not empty)
NL <- Dequeue(q); // Get a left operand
NR <- Dequeue(q); // Get a right operand
if NL and NR are both constants then // 折叠(Fold)常量表达式
NT <- Fold(op, NL, NR);
if q is not empty then
Emit("root <- NT");
Rank(NT) = 0;
else
Enqueue(q, NT, 0);
Rank(NT) = 0;
else // op不是常量表达式
if q is empty then // 获取结果的name
NT <- root;
else
NT <- new name;
Emit("NT <- NL op NR");
Rank(NT) <- Rank(NL) + Rank(NR) // 计算其rank
if q is not empty then // q中还有操作,将NT加入q
Enqueue(q, NT, r);
这个方案中,有几个细节比较重要。
- 在遍历候选树时,Flatten可能会遇到另一棵树的根结点。此时,它会递归调用Balance而非Flatten,以便为候选子树的根结点创建一个新的优先队列,并确保编译器在输出引用子树值的代码之前,先对优先级较高的子树输出代码。回想算法第一阶段按优先级递增顺序为Roots队列设定等级的做法,该做法刚好使得这里的求值顺序必定是正确的。
- 程序块包含3种引用:常数、在本程序块中先定义后使用的名字和向上展现(在程序块b中,如果对名字x的第一次使用引用了在进入b之前计算的一个值,那么x在程序块b中是向上展现的)的名宇。Flatten例程分别处理每种情形。它假定集合UEVar(b)包含了程序块b中所有向上展现的名字。UEVar的计算会在后续讲解。
- 算法的第二阶段以一种谨慎的方法来为操作数设定等级。常数等级为零,这迫使它们移动到队列的前端,这里Fold会对操作数均为常数的运算求值,为结果创建新的名字并集成到树中。叶结点的等级为1。内部结点的等级等于其所在子树所有结点等级之和,即该子树中非常数操作数的数目。这种指派等级的方法将生成一种近似于平衡二叉树的树状结构。
2.2.3 例子
第一个例子,如果对3.2开头的例子应用该算法,会发生什么。假定t7在退出该程序块时仍然是活跃的(live),t1到t6则不再活跃,而Enqueue会将数据项插入到优先级相等的第一个队列成员之前。在这种情况下,算法的第1阶段只会找到一个根结点t7,第二阶段对t7调用Balance,再调用Flatten,然后调用Rebuild。Flatten建立了以下队列:
{(h,1),(g,1),(f,1)(,e,1),(,d,1),(c,1),(b,1),(a,1)}
Rebuild从队列中取出(h,1)和(g,1),输出"n0 <- h + g",将(n0,2)加入队列。接下来,它从队列取出(f,1)和(e,1),输出"n1 <- f+ e",并将(n1,2)加人队列。然后,它从队列取出(d,l)和(c,1),输出"n2 <- d + c",并将(n2,2)加入队列。接下来,它将(b,1)和(a,1)取出队列,输出"n3 <- b + a",并将(n3,2)加入队列。下一个迭代从队列取出(n3,2)和(n2,2),输出"n4 <- n3 + n2",并将(n4,4)加入队列。最终输出的代码如下:

第二个例子,我们来考虑如图8-9a所示的基本程序块。该代码可能是局部值编号算法生成的,常数已经合并,冗余计算巳经消除。该程序块包含几个相互交织的计算。图8-9b给出了该程序块中的各个表达式树。请注意,其中通过名字重用了t3和t7。最长的计算路径链是以t6为根结点的树,包括六个运算。
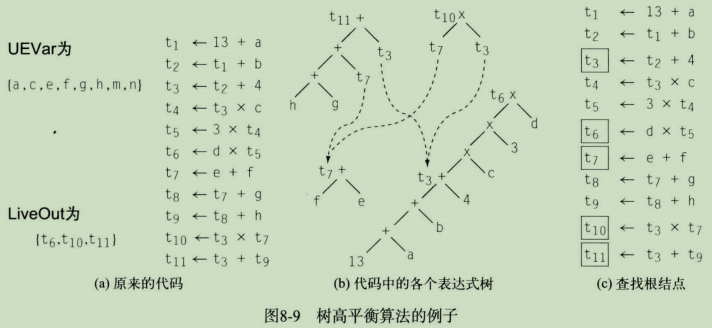
在我们对图8-9中的程序块应用树高平衡算法的第一阶段时,算法会找到5个根结点,如图8-9c中的方框所示。其中标记了t3和t7,因为二者都会使用多次。同时也标记了t6、t10和t11,因为这些值都属于LiveOut(b)集合。在第一阶段结束时,优先队 列Roots包含以下数据项:
{(t11,1),(t7,1),(t3,1),(t10,2),(t6,2))
假定+的优先级为1,*的优先级为2。
算法的第二阶段会不断地从Roots队列移除一个结点并调用Balance来处理该结点,Balance进而使用Flatten创建操作数的一个优先队列,然后使用Rebuild根据这些操作数建立一个平衡的计算。(每棵树都只包含一种运算。)
第二阶段从对t11调用Balance开始,回忆图8-9,t11是t3和t7的和。Balance对这些结点分别调用Flatten,而这些结点本身又是其他树的根结点。因而,对Flatten(t3,q)的调用会对t3调用Balance,而后对t7的处理也会对t7调用Balance。
Balance(t3)使对应的树扁平化,变为队列{(4,0),(13,0),(b,1),(a,1)},并对该队列调用Rebuild。Rebuild从该队列取出(4,0)和(13,0),合并这两项,将(17,0)加入队列。接下来,它从队列取出(17,0)和(b,1),输出"n0 <- 17 + b",并将(n0,1)加入队列。在处理t3子树的最后一次迭代中,Rebuild从队列取出(n0,1)和(a,1),并输出"t3 <- n0 + a"。它将t3标记为等级2并返回。

对t7调用Balance会建立一个平凡的队列{(e,1),(f,1)}并输出操作"t7 <- e + f"。这样,就完成了第2阶段中while循环的第一个迭代。
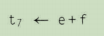
接下来,第二阶段对根结点为t11的树调用Balance。它调用Flatten,该函数会建立队列{(h,1),(g,1),(t1,2),(tJ,2)}。接下来,Rebuild输出代码"n1 <- h + g",并将n1标记为等级2后加入队列。然后,它输出代码"n2 <- n1 + t7’',并将n2标记为等级4后加入队列。最后,它输出代码"t11 <- n2 + t3",并将t11标记为等级6。
第二阶段从Roots队列取出的下两个数据项是t7和t3,二者都已经被处理过,因而具有非零的等级。因此,Balance遇到二者会立即返回。
第二阶段对Balance的最后一次调用传递了根结点t6。对于t6,Flatten会构造出以下队列:{(3,0),(d,1),(c,1),(t3,2)}。Rebuild输出代码"n3 <- 3 + d",并将n3标记为等级1后加入队列。接下来,它输出"n4 <- n3 + c",并将n4标记为等级2后加入队列。最后,它输出t6 <- n4 + t3",并将t6标记为等级4。

最终生成的树如下图所示,以t6为根结点的子树现在的高度是 3个操作, 而不再是6个。

三、区域优化
为说明区域优化技术,这里阐述其中两种优化技术。第一种是超局部值编号(Superlocal Value Numbering, SVN)技术,是将局部值编号算法向更大区域的扩展。第二种是则是循环展开。
3.1 超局部值编号
局部值编号算法进行改进,将其范围从单个基本程序块延伸到一个扩展基本程序块(Extended Basic Block, EBB),如下图a所示。为处理一个EBB,改进算法应该对穿越EBB的每条代码路径进行值编号,我们将由此形成的算法称为超局部值编号 ( Superlocal Value Numbering , SVN ) 算法。
应用SVN算法对下例做处理,SVN可以将三条执行路径(B0,B1)、(B0,B2,B3)、(B0,B2,B4)分别作为单个基本程序块处理,也就是分别当作线性代码。为处理(B0,B1),编译器可以先将LVN算法应用到B0,然后使用由此生成的散列表将LVN算法应用到B1。同样的方法可以用来处理(B0,B2,B3)和(B0,B2,B4),只需按顺序处理EBB中的各个基本程序块,并将LVN算法处理各个基本程序块生成的散列表不断向前传递。
思考一个问题!
- 问:处理的第一条执行路径为什么是(B0,B1)而不是(B0,B1,B6)呢?明明B6和B1一样都在这条执行路径上?
- 答:B6确实在(B0,B1,B6)的执行路径上,而且也必定会走,但是B6和B1不同。从下图b可以看出,B1只有一个前驱块B0,意味着B1的优化只受到B0中代码的影响。B6中的优化则会分别受到B1、B5中代码的影响,根据B1优化的B6可能会影响(B5,B6)的执行结果。由于SVN算法本身的限制,无法找到B5和B6中的冗余,算法将错失这些优化时机。所以对于B6这种有多个前驱块的基本块,不能把它和它的前驱基本块一起做超局部值编号,从它开始重新再用SVN。为捕获此类时机,我们需要一种能够考虑更多上下文的算法。
但是上面SVN处理每条路径的这种处理方法并不高效,如(B0,B1)中已经处理了B0,在(B0,B2,B3)和(B0,B2,B4)中又要对B0做处理,一个基本块分析了三次。
为使SVN高效执行,对于以前缀形式出现在穿越EBB的多条路径上的程序块,编译器必须重用分析这种程序块的结果。该算法需要一种方法来撤销处理程序块的影响。在算法处理(B0,B2,B3)之后,它必须重建(B0,B2)末尾处的状态,以便重用该状态来处理B4。
编译器可以有多种方法达到这种效果,其中最高效的一种是:利用为词法上作用域化的散列表开发的机制来实现值表,即实现值表同前端parse时的符号表机制相似。在编译器进入一个程序块时,它可以创建一个新的作用域,为撤销该程序块的影响,删除该程序块的作用域即可。使用作用域化的值表可以产生最简单、最快速的实现,特别是在编译器能够重用前端的(作用域化散列表)实现的情况下。
下图给出了SVN算法的高层概述,其中使用了作用域化的值表,将其应用到上图a的代码,将产生如上图d所示的操作序列。它假定LVN算法已经修订为可以接受两个参数:一个基本程序块和一个作用域化的值表。在处理每个基本程序块b时,算法为b分配一个值表,将其连接到前趋程序块的值表(将前趋块的值表当成是外层作用域),并用这个新的值表和程序块b为参数调用LVN。在LVN返回时,SVN必须决定如何处理b的每个后继程序块。

对于b的后继s,有两种情况。如果s只有一个前趋b,那么应该利用自b积累而来的上下文信息来处理s。于是,SVN算法利用包含程序块b上下文信息的表,递归到s上执行。如果s具有多个前趋,那么算法对s的处理必须从一个空的上下文开始。因而,SVN将s增加到Worklist中,外层循环以后会找到它,并对s和空表调用SVN。
这里还有一个复杂之处。名字的值编号是由与EBB中定义该名字的第一个操作相关联的值表记录的,这会给我们使用作用域机制带来困难。在我们的例子CFG中,如果B0、B3、B4中都定义了名字x,那么其值编号将记录在B0中的作用域化值表中。在SVN处理B3时,它会将x来自B3的新的值编号记录到对应于B0的表中。在SVN删除对应于B3的表并创建一个对应于B4的新表时,由B3定义的值编号仍然保留在对应于B0的表中。
为避免这种复杂情况,编译器可以在只定义每个名字一次的表示法上运行SVN算法。静态单赋值形式(SSA)正具有所需的性质,其中的每个名字都只在代码中的一个位置上定义。使用SSA,可以确保SVN算法将对应于某个定义的值编号,记录到包含该定义的程序块对应的表中。在使用SSA的情况下,删除对应于一个程序块的表将撤销该程序块的所有影响,并将值表恢复到从该程序块在CFG中前趋程序块退出时的状态。
3.2 循环展开
循环展开是一种程序变换,通过增加每次迭代计算元素的数量,减少循环迭代次数。以求和函数为例:
//非循环展开
for(int i = 1; i <= n; i++)
sum += a[i];
//2*1循环展开
int i;
for(i = 1; i <= n - 1; i += 2) {
sum += a[i];
sum += a[i + 1];
}
for(; i <= n; i++)
sum += a[i];
//3*1循环展开
int i;
for(i = 1; i <= n - 2; i += 3) {
sum += a[i];
sum += a[i + 1];
sum += a[i + 2];
}
for(; i <= n; i++)
sum += a[i];
//2*2循环展开
int i, sum0, sum1, sum;
for(i = 1; i <= n - 1; i += 2) {
sum0 = sum0 + a[i];
sum1 = sum1 + a[i + 1];
}
for(i; i <= n; i++)
sum0 += a[i];
sum = sum0 + sum1;
循环展开对编译器为给定循环生成的代码有着直接和间接的影响,就直接效益而言,展开应该可以减少完成循环所需操作的数目。控制流的改变减少了判断和分支代码序列的总数,展开还可以在循环体内部产生重用,减少内存访问。
但是,展开的一个危害是它会增大程序的长度,无论是IR形式还是以可执行代码出现的最终形式。IR长度的增大会增加编译时间;可执行代码长度的增加没什么影响,除非针对展开的循环生成的代码撑爆了指令高速缓存,这种情况下,性能的降低可能会远远超出任何直接效益。
编译器还可能为寻求间接效果而展开循环,这也会影响性能。循环展开的关键副效应是增加了循环体内部的操作数目。其他优化可能在几个方面利用这一改变,如:
- 增加循环体中独立操作的数目,可以生成更好的指令调度。在操作更多的情况下,指令调度器有更高的几率使多个功能单元保待忙碌,并隐藏长耗时操作(如分支和内存访问)的延迟。
- 循环展开可以将连续的内存访问移动到同一迭代中,编译器可以调度这些操作一同执行。这可以提高内存访问的局部性,或利用多字操作进行内存访问(以提高效率)。
- 展开可以暴露跨迭代的冗余,而这在原来的代码中是难于发现的。在展开后的循环中,局部值编号算法会找到并消除这些冗余。而在原来的代码中,该算法是无法找到这些冗余的。
- 与原来的循环相比,展开后的循环能以不同的方式进行优化。例如,增加一个变量在循环内部出现的次数,可以改变寄存器分配器内部逐出代码选择中使用的权重。改变寄存器逐出的模式,可能在根本上影响到为循环生成的最终代码的速度。
- 与原来的循环体相比,展开后的循环体可能会对寄存器有更大的需求。如果对寄存器增加的需求会导致额外的寄存器逐出(存储到内存和从内存重新加载),那么由此导致的内存访问代价可能会超出循环展开带来的潜在效益。
四、全局优化
全局优化处理整个过程或方法。因为其作用域包括有环的控制流结构(如循环),全局优化在修改代码之前通常会先进行一个分析阶段。
本节给出全局分析和优化方面的两个例子。第一个例子是利用活跃信息查找未初始化变量,严格说来它并不是一种优化。这个例子实际上是使用全局数据流分析技术,来揭示一个过程中有关值的流动的有用信息。我们利用该例子的讨论来介绍活跃变量(Live Variable)信息的计算,这一计算在许多优化技术中都会发挥作用,包括树高平衡、静态单赋值形式信息的构建和寄存器分配。第二个例子是全局代码置放问题,该例子使用从运行编译后代码中收集到的剖析信息,来重新安排可执行代码的布局。
4.1 利用活跃信息查找未初始化变量
如果过程p在为某个变量v分配一个值之前能够使用v的值,我们就说v在此次使用时是未初始化的。使用未初始化变量,几乎总是表明被编译的过程中存在逻辑错误。如果编译器能够识别出这些情况,它应该通知程序员代码中存在问题。
通过计算有关活跃情况的信息,我们可以找到对未初始化变量的潜在使用。对于变量x和程序点p,如果在CFG中沿着p开始能找到一条或多条会引用变量x在p点的值的路径,且变量x在该路径中没有被重新定义时,则称变量x在点p是活跃(live)的,否则称变量x在点p不活跃(dead)。
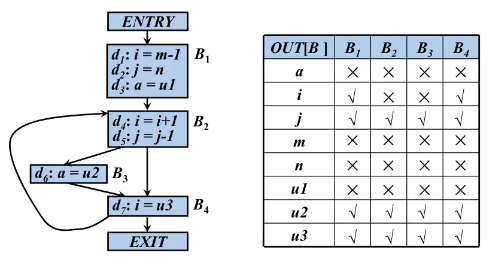
我们通过计算,将过程中每个基本程序块b对应的活跃信息编码到集合 L i v e O u t ( b ) LiveOut(b) LiveOut(b)中,该集合包含在从程序块b退出时所有活跃的变量。给定CFG入口结点n0的LiveOut集合, L i v e O u t ( n 0 ) LiveOut(n_0) LiveOut(n0)中的每个变量都有一次潜在的未初始化使用。
4.1.1 定义数据流问题
计算LiveOut集合是全局数据流分析中的一个经典问题。对于过程的CFG中每个结点n来说,定义LiveOut集合的方程如下:
L i v e O u t ( n ) = ⋃ m ∈ s u c c ( n ) ( U E V a r ( m ) ∪ ( L i v e O u t ( m ) ∩ V a r K i l l ( m ) ‾ ) ) LiveOut(n)= \bigcup_{m \isin succ(n)} (UEVar(m) \cup (LiveOut(m) \cap \overline{VarKill(m)})) LiveOut(n)=⋃m∈succ(n)(UEVar(m)∪(LiveOut(m)∩VarKill(m)))
其中:
- n n n表示CFG中的任意一个结点。
- s u c c ( n ) succ(n) succ(n)表示结点 n n n的所有后继结点。
- U E V a r ( m ) UEVar(m) UEVar(m)表示 m m m中向上展现的变量,即那些在 m m m中引用后又被重新定义的变量。
- V a r K i l l ( m ) VarKill(m) VarKill(m)表示结点 m m m中定义的所有变量。
- V a r K i l l ( m ) ‾ \overline{VarKill(m)} VarKill(m)表示 V a r K i l l ( m ) VarKill(m) VarKill(m)的补集,即所有未在结点 m m m中定义的变量。
- ⋃ m ∈ s u c c ( n ) ( e q u a t i o n ) \bigcup_{m \isin succ(n)} (equation) ⋃m∈succ(n)(equation)表示每个 m m m带入 e q u a t i o n equation equation所得集合的并集。
L i v e O u t ( n ) LiveOut(n) LiveOut(n)只是CFG中结点 n n n的各个后继程序块 m m m入口处活跃变量的并集,该定义只要求一个值在某条路径(而非所有路径)上都是活跃的。因而,将结点 n n n在CFG中各个后继结点的贡献并起来就形成了 L i v e O u t ( n ) LiveOut(n) LiveOut(n)。n的特定后继结点m对 L i v e O u t ( n ) LiveOut(n) LiveOut(n)的贡献是:
U E V a r ( m ) = ⋃ ( L i v e O u t ( m ) ∩ V a r K i l l ( m ) ‾ ) UEVar(m)= \bigcup(LiveOut(m) \cap \overline{VarKill(m)}) UEVar(m)=⋃(LiveOut(m)∩VarKill(m))
如果变量v在程序块 m m m入口处是活跃的,那么它必定符合以下两个条件之一。
- 一种情况是,v进入 m m m时是活跃,退出 m m m时是不活跃,也就是 m m m中对v引用之后,又重新定义了v,在这种情况下 v ∈ U E V a r ( m ) v \isin UEVar(m) v∈UEVar(m)。
- 另一种情况是,v在从程序块 m m m进入和退出时都是活跃的,也就是在 m m m中没有重新定义v,在这种情况下 v ∈ L i v e O u t ( m ) ∩ V a r K i l l ( m ) ‾ v \isin LiveOut(m) \cap \overline{VarKill(m)} v∈LiveOut(m)∩VarKill(m)。
用 U U U合并这两个集合,就给出了程序块m对 L i v e O u t ( n ) LiveOut(n) LiveOut(n)的贡献。为计算 L i v e O u t ( n ) LiveOut(n) LiveOut(n),分析程序需要合并 n n n的所有后继结点(记作 s u c c ( n ) succ(n) succ(n))的贡献。
4.1.2 解决这个数据流问题
为对一个过程及其CFG计算各结点的LiveOut集合,编译器可以使用一个三步算法。
- 构建CFG,这个步骤在概念上很简单,虽然语言和体系结构特性可能会使问题复杂化,参见根据线性代码建立控制流图。
- 收集初始信息,分析程序在一趟简单的遍历中分别为每个程序块b计算一个UEVar和VarKill集合,如下图8-14a所示。
- 求解方程式,为每个程序块b生成LiveOut(b)集合。下图8-14b给出了一个简单的迭代不动点算法,可以求解方程式。

以下是一个求解LiveOut方程式的例子,在数据流分析章节中还会进行更深入的研究。
给定UEVar和VarKill集合,编译器可以应用上图8-14b中的算法来对CFG中的每个结点计算LiveOut集合。它将所有的LiveOut集合都初始化为 ∅ \emptyset ∅。接下来,编译器为从B0到B4的每个基本程序块计算LiveOut集合。编译器会重复该过程,按顺序为每个结点计算LiveOut合,直至各个LiveOut集合不再改变为止。
下图8-15c中的表给出了在求解程序的每次迭代时各个LiveOut集合的值。标记为Initial的行给出了各个初始值。第一次迭代计算各个LiveOut集合的初始近似值,因为算法按程序块标号的升序来处理各个程序块,B0、B1和B2的LiveOut集合得到的值完全取决于其在CFG中后继结点的UEVar集合。在算法到达B3时,由于已经为LiveOut(B1)计算了一个近似值,因而算法对LiveOut(B3)计算的值反映了LiveOut(B1)新值的贡献。LiveOut(B4)为
∅
\emptyset
∅,B4是CFG中的出口程序块,这是适宜的。

在第二次迭代中,值s添加到LiveOut(B0),因为s存在于LiveOut(B1)的近似值中,这一轮迭代没有出现其他改变。第三次迭代不会改变任何LiveOut集合的值,所以算法的执行到此停止。
算法处理各程序块的顺序会影响到各个中间集合的值。如果算法按标号降序访问各个基本程序块,那么处理的趟数将减少一趟。但各个LiveOut集合的最终值与求值顺序无关。
该算法最终会停止,因为各个LiveOut集合都是有限的,而对一个程序块的LiveOut集合的重新计算只会增加其中的变量名。在方程中消除变量名的唯一方法,是求变量与 V a r K i l l ( m ) ‾ \overline{VarKill(m)} VarKill(m)集合的交集。因为VarKill集合在该计算期间不会改变,所以对每个LiveOut集合的更新是单调递增的,因而该算法最终必定会停止下来。
4.1.3 查找为初始化的变量
在编译器为过程的CFG中每个结点都计算出了LiveOut集合后,查找对可能未初始化的变量的使用就变得简单了。考虑某个变量v,如果v ∈ \isin ∈ LiveOut(n0),其中n0是过程CFG的入口结点,那么通过构建LiveOut(n0),必定存在一条从n0到v的某个使用之处的路径,而v在该路径上未被定义。因而,v ∈ \isin ∈ LiveOut(n0)意味着,对v的某次使用可能会接收到一个未初始化的值。
这种方法将会识别出使用潜在未初始化值的变量。编译器应该识别出这种情形,并将其报告给程序员。但由于几个原因,这种方法可能会得出假警报。
-
如果可以通过另一个名字访问且已经通过该变量名初始化,那么对变量的活跃分析将无法关联起这种初始化和对应的使用。在将指针设置为指向某个局部变量的地址时就会出现这种情况,如下图代码片断所示。

-
如果v在当前过程被调用之前就已存在,那么它此前可能已经用分析程序不可见的某种方式进行过初始化。对于当前作用域中的静态变量或声明在当前作用域以外的变量,可能会出现这种情况。
-
从变量活跃分析的方程组可能会发现:在从过程的入口点到使用变量v的某个位置之间的路径上,v没有被定义。如果该路径在运行时是不可能出现的,那么虽然实际的执行不会使用到未初始化值,但v仍然将出现在LiveOut(n0)中。例如,下图C语言程序总是在使用s之前初始化它,但仍然有s ∈ \isin ∈ LiveOut(n0)。
4.1.4 对活跃变量的其他使用
除了查找未初始化变量之外,编译器还会在许多上下文中使用变量活跃情况。
- 在全局寄存器分配(后续会在新的博客中专门总结)中,活跃变量的信息发挥了关键作用。除非值是活跃的,否则寄存器分配器不必将其保待在寄存器中;当一个值从活跃转变为不活跃时,分配器可以因其他用途而重用其寄存器。
- 活跃变量信息也用于改进SSA的构建;对一个值来说,在它不活跃的任何程序块中,它都不需要 ϕ \phi ϕ函数。用这种方法使用变量活跃信息,可以显著地减少编译器在构建程序的SSA时必须插入的 ϕ \phi ϕ函数数目。
- 编译器可以使用活跃变量信息来发现无用的store操作。如果一个操作将v存储到内存,而v是不活跃的,那么该store操作是无用的。这种简单的技术对无歧义的标量变量(即那种只有一个名字的变量)非常有效。
4.2 全局代码置放
许多处理器的分支指令代价不对称,比如落空分支(fall-throught branch,控制流直接往下走)比采纳分支(taken branch,控制流需要跳跃到该分支)更快。因此需要移动代码,让执行频度更高的分支控制流走落空分支,执行频度更低的分支控制流走采纳分支。
我个人理解的是:落空分支之所以执行更快,主要还是受指令Cache的局部性原理的影响,缓存命中率高;还可能与分支预测有关,这个算法不同影响结果不同。
如下图所示:(B0,B2)和(B2,B3)的执行频度为100,(B0,B1)和(B1,B3)的执行频度为1。慢速布局将B1放在了B0的落空分支,B2放在了B0的采纳分支,将B3放在了B1的落空分支,B3放在了B2的采纳分支,快速布局则与之相反。假设落空指令的速度比采纳指令快一倍,这里快速布局要比慢速布局快100倍。
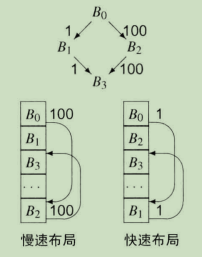
代码置放具有独立的分析和变换阶段。分析阶段收集分支执行频度数据,变换阶段利用这些数据来对基本块进行排序。以下是收集剖析信息有几种方法:
- 装有测量机制的可执行文件。编译器往生成的代码中插入统计信息,如进入和退出过程或采纳分支等。在运行时,数据被写出到一个外部文件,由另一个工具离线处理。
- 定时器中断。定时器以较高的频率中断程序的执行,统计中断时程序计数器pc的位置。
- 性能计数器。如果处理器提供硬件计数器来统计事件,如处理器周期数,缓存失效或采纳分支,则可直接使用。
装有测量机制的可执行文件可以测量执行过程的几乎任何性质,而谨慎的工程实践也可以限制这种方法的开销。基于定时器中断的系统具有更低的开销,但只能定位那些频繁执行的语句(而非通向这些语句的代码路径)。硬件计数器精确且高效,但依赖于特定处理器体系结构和实现所提供的具有特异性的方法。
4.2.1 获取剖析数据
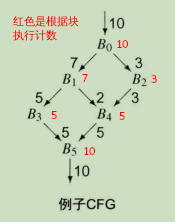
编译器应该统计CFG各条边的执行次数,而不是基本块的执行次数。如下图,黑色数字是统计的各条边的执行次数,能够判断出(B1,B3)作为落空分支会更好。而如果按照红色数字各个基本块执行次数的方式统计,则B3和B4会具有同等重要性。
4.2.2 以链的形式在CFG中构建热路径
得到每条边的执行次数后,就需要构建出执行最频繁的路径,即热路径(hot path)。编译器使用贪婪算法查找热路径,下图给出了算法伪代码。

开始,它为每个程序块创建一条退化的链,其中只包含对应的程序块本身。算法将每个退化链的优先级设置为一个大数,如CFG中边的总数或最大的可用整数。
接下来,该算法遍历CFG中的各条边,逐渐建立与热路径相对应的各条链。它按执行频度的顺序采用各条边,使用得最频繁的边优先。对于边 <x, y>,当且仅当x是其所在链中最后一个结点、y是其所在链中第一个结点时,算法会合并包含x的链和包含y的链。如果二个条件中有一个不为真,则算法会保持包含x的链与包含y的链原样不动。
如果算法合并包含x的链和包含y的链,则它必须为新的链分配一个适当的优先级。它将新的优先级设定为x和y所在链优先级的最低值。如果x和y是退化链,仍然是初始的高优先级,则算法会将新链的优先级设置为算法到目前为止已经考虑过的合并操作的数目,记作P。该值会将这个链放置在基于更高频度的边构建而成的链之后,基于较低频度的边构建而成的链之前。
该算法在处理完每条边之后停止。它会产生一组链,描述了CFG中的热路径。每个结点都刚好属于一条链。与链之间的边相比,链内部的各条边执行得更为频繁。每条链的优先级数值编码了各条链的一种相对布局次序,能够使实际执行的正向分支(forward branch,分支的目标地址比源地址高称为正向分支。在某些体系结构中,正向分支比反向分支的破坏性小)数目逼近最大值。
下图是4.2.1中的CFG的处理过程。

4.2.3 进行代码布局
计算出热路径后,就进行代码布局。编译器必须将所有基本程序块按一个固定的线性次序放置。下图8-17给出了一个算法,可以根据链集合来计算出一个线性布局。其中包含了两个简单的启发规则:
- 一个链内部的各个基本程序块按顺序放置,使链中的边能够通过落空分支实现;
- 在多个链之间,根据链的优先级选择。

该算法用对(c,p)表示一个链,其中c是链的名字,p是其优先级。取出第一条热路径放入WorkList,把路径中的基本块顺序放置。同时与该路径中基本块相关的路径也加入WorkList。按照优先级从小到大的顺序取出另一条热路径放置代码,直至 WorkList 为空。于是例子中放置的结果为 (B0,B1,B3,B5,B2,B4)
五、过程间优化
将一个程序划分为多个过程,对于编译器生成高效代码的能力具有正反两方面的影响。从正面来看,它限制了编译器在任一时刻需要考虑的代码数量。这使得编译时数据结构保待在比较小的尺寸上,同时通过对问题规模的约束又限制了各种编译时算法的代价。
从负面来看,限制了编译器理解调用过程内部行为的能力。比如fee调用fie时将变量x作为传引用参数传递,在调用之后使用x,编译器必须证明fie或其调用的任何过程都不会直接或间接地改变对应于x的形参。另一个则是引入了调用者调用前返回后的代码、被调用者起始收尾代码的开销。
过程调用对于编译时知识和运行时操作的这些影响,会引入过程内优化无法解决的低效性。为减少独立过程引入的低效性,编译器可以使用过程间分析和优化技术,同时对多个过程进行分析和变换。
5.1 内联替换
从之前文章中的过程调用可知,编译器为实现过程调用而必须生成的代码涉及很多操作。生成的代码必须分配一个活动记录,对每个实参求值,保存调用者的状态,创建被调用者的环境,将控制从调用者转移到被调用者(以及与之对应的反向转移),以及(如有必要)从被调用者把返回值传递给调用者。在某种意义上,这些运行时活动是使用编程语言的一部分固有开销,它们维护了编程语言本身的抽象,但严格说来对于结果的计算并不是必需的。优化编译器试图减少此类开销的代价。
有时候,编译器可以通过将被调用者过程体的副本替换到调用位置上(并根据具体调用位置进行适当的调整)来提高最终代码的效率。这种变换称为内联替换(inlinesubstitution),它不仅使编译器能够避免大部分过程链接代码,还可以根据调用者的上下文对被调用者过程体的新副本进行调整。
内联替换可以分为两个过程:一是对代码结构的实际变换,二是决策对哪些调用位置进行内联。
变换过程
为进行内联替换,编译器需要用被调用者过程体重写一个调用位置,同时需要适当修改过程体副本以模拟参数绑定的效果。最后再对正确内联的代码进行优化,消除掉一部分操作。
变换相对简单,但仍有一些注意的点。一些源语言结构可能导致内联的代码控制流很复杂,比如多个过早的返回语句,或者 Fortran 的交替返回(alternate return)特性,都会使控制流图变得复杂。
除此之外,也要注意内联后局部变量变多的问题。考虑内联过程的一个简单实现,在被调用点处为过程的局部变量创建对应的局部变量。这时如果内联多个过程,或者在几个调用位置内联同一个过程,会有局部变量太多的问题。这不是一个正确性问题,但会影响其他的优化过程。其实这里我们只要能够做到重用局部变量就可以了。
决策过程
决策过程比较复杂且对性能有直接影响。内联过程不一定都会提高性能,比如会增加代码长度和命名空间规模,这会导致原来调用位置对寄存器的需求增加。因此有多个方面来考虑是否需要内联替换:
- 体系结构特点。比如说是否有更大的寄存器集合,这会增加过程调用的代价(保存和恢复寄存器的操作变多),会让内联更有吸引力。
- 被调用者规模。如果被调用者代码长度小于过程链接代码(调用前代码序列、返回后代码序列、起始代码序列和收尾代码序列),内联后的代码长度和实际执行的操作数都会减少。
- 调用者规模。编译器可能会限制过程的总长度,来避免编译时间增加和降低优化性能。
- 调用次数。对频繁执行的调用进行内联替换(如果有必要)会有更大的收益。
- 常数值实参。调用位置的实参如果已知是常数,那么内联能带来常数折叠的优化空间。
- 参数数量。参数越多,过程调用代价越大,因为编译器会生成代码对每个实参求值并将其存储。
- 被调用的位置数。如果过程只在一个地方被调用,那么内联不会带来代码长度的增加。注意编译器应该在内联后更新这些位置数据,以发现由于内联的进行而减少到只剩一个调用位置的那些过程
- 被调用者是否调用其他过程。跟踪过程中调用的数目,可以发现调用图中的叶过程,即不包含调用的过程。通常叶过程是良好的内联候选者。
- 调用点是否在循环内。循环内的过程执行会比较频繁,也难以把整个循环当作基本块进行优化。
- 占执行时间的比例。根据剖析数据计算每个过程占执行时间的比例,可以防止编译器内联那些对性能影响不大的例程。
一般编译器会采用启发式决策来决定是否内联替换,如下图所示:

5.2 过程置放
过程置放思想很简单,当过程 p 调用 q,我们希望 p 和 q 占用相邻的内存位置,才能更好地利用指令Cache的局部性。同样,这个算法也类似于上面见过的全局代码置放,由分析和变换两个阶段组成。
过程置放类似于上面介绍过的全局代码置放,由两个阶段组成:分析和变换。分析阶段统计出每条调用边的频度。变换阶段按照频度从高到低的顺序依次取出边 (x, y),把过程 y 的代码放置 x 之后,合并 x 和 y 为一个节点。合并可能需要修改与 x 和 y 相关的其他边的指向及边的频度。当每条调用边都处理完,调用图就已经被合并为一个节点,所有过程的置放顺序也就确定了。
下图8-21给出了一个用于过程置放分析阶段的贪婪算法。算法在第一步建立调用图,为各条边分配与估算的执行频度相对应的权重,然后将两个结点之间的所有边合并为一条边。作为初始化工作的最后一部分,算法为调用图的边建立一个优先队列,按边的权重排序。
算法的后半部分以迭代方式建立过程置放的一种次序。该算法将调用图中的每个结点关联到过程的一个有序表。这些列表规定了各个有名字过程之间的一种线性序。在该算法停止时,这些列表规定了各个过程上的一个全序,可利用该全序在可执行代码中放置各个过程。
算法使用调用图中各条边的权重来引导这一处理过程。它重复地从优先队列中选择权重最高的边,假定为(x,y),并合并边的源(source)x和目标(sink)y。接下来,算法必须更新调用图以反映这种变化。
- 算法对每条边(y,z)调用ReSource,将(y,z)替换为(x,z)并更新优先队列。如果边(x,z)已经存在,则Resource将合并二者。
- 算法对每条边(z,y)调用ReTarget,将(z,y)替换为(z,x)并更新优先队列。如果边(z,x)已经存在,则ReTarget将合并二者。
为使过程y放置到x之后,算法将list(y)追加到list(x)。最后,算法从调用图中删除y和与之相连的边。

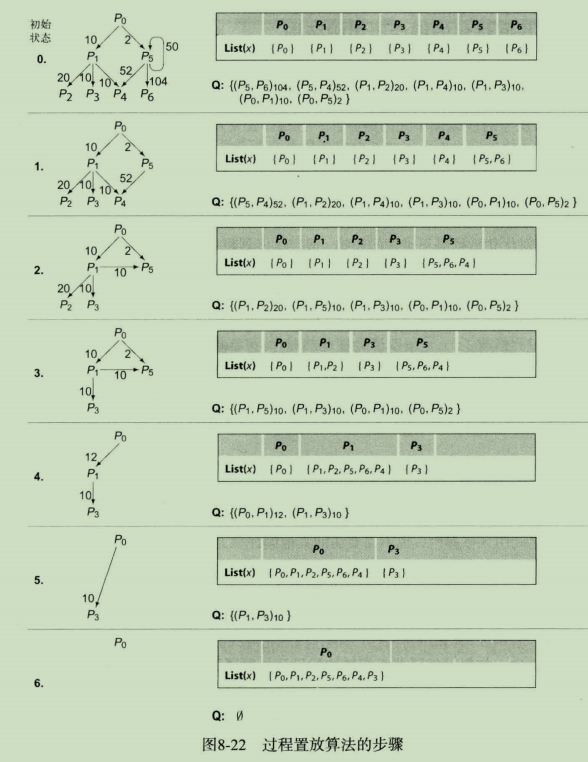
从下图8-22中的例子了解过程置放算法的工作方式。
画面0给出了该算法在迭代归约即将开始时的状态。P5有一个自环,即源和目标相同,这种边是无法影响置放算法的。每个结点对应的列表都是平凡的,只包含其自身的名字。优先队列使图中每条边(自环除外)根据执行频度排序。
画面1给出了该算法在while循环完成第一次迭代之后的状态。算法将P6坍缩(collapse)到P5,并更新对应于凡的列表和优先队列。
在画面2中,算法已经将P4坍缩到P5。它将边(P1,P4)的目标重定向到P5,并改变了优先队列中对应边的名字。此外,它从图中删除了P4,并更新了对应于P5的列表。
画面4给出了算法合并边的场景。此时,算法将P5坍缩到P1,并将边(P0,P5)的目标重定向到P1。因为(P0,P1)已经存在,算法只是合并了新旧两条边的权重,并相应地更新优先队列:删除(P0,P5),并改变(P0,P1)的权重。
在各次迭代结束后,调用图已经坍缩到一个结点P0。虽然这个例子构建的布局从入口结点开始,但这是由各条边的权重所致,而非算法设计如此。
















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











