







一、java
(1)集合
1.List
lLinkedList
LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
LinkedList的数据结构是双向链表,可用作队列和栈。
LinkedList的add()方法是尾插法
//采用双向链表的尾插法
public boolean add(E e){
linkLast(e);
return true;
}
void linkLast(E e){
//创建临时借点l初始化为尾节点(那么其后继结点为null,前驱结点不为空)
final Node<E> l = last;
//初始化心机诶单 前驱结点为l 后继结点暂为null
final Node<E> newNode = new Node<>(l,e,null);
//由于是在链表尾部插入结点 那么新结点就作为尾节点
last = new Node;
/**
l节点作为newNode节点的前驱节点
如果l为空 那么newNode前驱节点为空
在双向链表中。前驱节点为空 那么该结点为头节点
*/
if(l == null)
first = newNode;
else
l.next = newNode;
size++;//在插入结点后 链表的长度加1
modCount++;
}
LinkedList使用尾插法,效率不会比头插法低吗?
不会,因为LinkedList代码中,已经保存了尾结点,所以插入时,不需要遍历查找尾结点,直接在尾结点后面插入就好了
如果get(index):如果index在前半段,则从头结点开始遍历;如果index在后半段,则从尾结点开始遍历。
ArrayList
ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
arrayList第一次扩容时,默认扩容大小为10
首次扩容不足时,扩容的公式是:oldCapacity + (oldCapacity>> 1),oldCapacity 表示数组现有大小
如果扩容后的值 < 我们的期望值,我们的期望值就等于本次扩容的大小
newCapacity = minCapacity;
数组最大值为Inteager的最大值2147483647
Vector
Vector 接口实现类 数组, 同步, 线程安全
默认构造的方式是0, 之后插入按照****1 2 4 8 16 二倍扩容。
对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了 ;
vector是以2****倍的方式扩容的
1.vector在push_back以成倍增长可以在均摊后达到O(1)的事件复杂度,相对于增长指定大小的O(n)时间复杂度更好。
2.为了防止申请内存的浪费,现在使用较多的有2倍与1.5倍的增长方式,而1.5倍的增长方式可以更好的实现对内存的重复利用,因为更好。
1、vector拥有一段连续的内存空间,如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2、list拥有一段不连续的内存空间,因此支持随机存取,如果需要大量的插入和删除,而不关心随即存取,则应使用list。
3、如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque
2.Set
HashSet
HashSet 使用哈希表存储元素,元素可以是null
HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,值不能重复,就如数据库中唯一约束
在HashSet中,基本的操作都是有HashMap底层实现的,因为HashSet底层是用HashMap存储数据的。当向HashSet中添加元素的时候,首先计算元素的hashcode值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置为空,就将元素添加进去;如果不为空,则用equals方法比较元素是否相等,相等就不添加,否则找一个空位添加
- 基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
- 当我们试图把某个类的对象当成 HashMap的 key,或试图将这个类的对象放入 HashSet 中保存时,重写该类的equals(Object obj)方法和 hashCode() 方法,而且这两个方法的返回值必须保持一致:当该类的两个的 hashCode() 返回值相同时,它们通过 equals() 方法比较也应该返回 true。通常来说,所有参与计算 hashCode() 返回值的关键属性,都应该用于作为 equals() 比较的标准。
- HashSet的其他操作都是基于HashMap的。
TreSet
-
TreeSet 底层实现为红黑树,元素排好序,元素不可以是null
-
TreeSet 是二叉树实现的,Treeset中的数据是自动排好序的,不允许放入null值
-
TreeSet的底层是TreeMap的keySet(),而TreeMap是基于红黑树实现的,红黑树是一种平衡二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。
3.map:HashMap、TreeMap和HashTable
线程安全
-
HshaMap线程不安全
-
TreeMap线程不安全
-
HashTable线程安全
空值
- HashMap一个null key,多个null value
- TreeMap不能null key,多个null value
- HashTable都不能有null
继承和接口
- HashMap继承AbstractMap,实现接口Map
- TreeMap继承AbstractMap,实现接口NavigableMap(SortMap的一种)
- HashTable继承Dictionary,实现接口Map
顺序
- HashMap中key是无序的
- TreeMap是有序的,TreeMap是基于元素的固有顺序 (由 Comparator 或者 Comparable 确定)。
- HashTable是无序的
构造函数
- HashMap有调优初始容量和负载因子
- TreeMap没有
- HashTable有
数据结构
- HashMap是链表+数组+红黑树
- TreeMap是红黑树
- HashTable是链表+数组
4.list、set和map的区别
- list:元素按进入先后有序保存,可重复
- set:不可重复,并做内部排序
- map:代表具有映射关系的集合,其所有的key是一个Set集合,即key无序且不能重复。
5.HashMap扩容机制
数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算(据说提升了5~8倍)。
数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造器传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能。
检查链表长度转换成红黑树之前,还会先检测当前数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
**链表树化的两个条件**(1:数组长度达到64, 2:该链表长度达到了8),该链表会转换为红黑树
6.HashMap中的循环链表是如何产生的(jdk1.7)
由于jdk1.7中采用头插法,在多线程中,存在两个线程同时对链表进行扩容的情况,执行transfer函数(链表数据转移)会导致链表数据倒置,当两个线程同时此操作,就导致链表死循环
7.B树和B+树的区别(mysql索引)
- B树是二叉排序树进化而来;B+树是分块查找进化而来
- B+树叶子节点包含所有数据,非叶节点仅起到索引作用;B树终端节点及以上都包含数据且不重复(叶节点只是一个概念,并不存在)
- B+树叶节点包含了全部关键字
- B+树支持顺序查找和多路查找,B树只支持多路查找
- B+树叶子结点数据都通过链表存储关联
- B+树更有利于对数据库的扫描 ,因为所有元素都在叶子节点上。
- B+树的查询效率更加稳定 ,所谓的稳定就是B树最后就是要找到叶子节点,就是不管你找谁都有从头走到尾,不会出现那个特别长,那个特别短。(这个可以在我推荐的这个工具演示一下寻找某个元素的过程)
- B+树没有像B树一样,把一些关键码每层都放一部分,之间存在互相之间的关系,指针。在考虑指针指向内容上,B树没有这些要存,反而数据量大的情况的,占的空间要比B树小。
8. HashMap为什么用红黑树而不是AVL树或者B+树
AVL树更加严格平衡,因此可以提供更快的査找效果。因此,对于查找密集型任务使用AVL树没毛病。 但是对于插入密集型任务,红黑树要好一些。通常,AVL树的旋转比红黑树的旋转更难实现和调试
B/B+树的节点可以存储多个数据,当数据量不够多时,数据都会”挤在“一个节点中,查询效率会退化为链表。
B和B+树主要用于数据存储在磁盘上的场景,比如数据库索引就是用B+树实现的。这两种数据结构的特点就是树比较矮胖,每个结点存放一个磁盘大小的数据,这样一次可以把一个磁盘的数据读入内存,减少磁盘转动的耗时,提高效率。而红黑树多用于内存中排序,也就是内部排序。
9.CopyOnWriteArrayList的原理
线程并发访问进行读操作时,没有加锁限制
写操作时,先将容器复制一份,再在新的副本上执行写操作,此时写操作是上锁的。结束之后再将原容器的引用指向新容器。注意,在上锁执行写操作的过程中,如果有需要读操作,会作用在原容器上。因此上锁的写操作不会影响到并发访问的读操作。
ConcurrentHashMap,在 JDK 1.7 中采用 分段锁(ReentrantLock + Segment + HashEntry)的方式,相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。;JDK 1.8 中直接采用了CAS(无锁算法)+ synchronized。
(2)多线程
1.Java中线程安全的基本数据结构
- string
- HashTable
- ConcurrentHashMap
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- Vector
- stringBuffer
2.创建线程有哪几种方式
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 线程池
3.Java多线程之间的通信方式
wait()、notify()、notifyAll()。采用synchronized来保证线程安全
await()、signal()、signalAll()。采用lock保证线程安全
BlockingQueue。当生产者线程试图向BlockingQueue中放入元素时,如果该队列已满,则该线程被阻塞;当消费者线程试图从 BlockingQueue中取出元素时,如果该队列已空,则该线程被阻塞
4.sleep()和wait()的区别
- sleep()是Thread类中的静态方法,而wait()是Object类中的成员方法;
- sleep()可以在任何地方使用,而wait()只能在同步方法或同步代码块中使用
- sleep()不会释放锁,而wait()会释放锁,并需要通过notify()/notifyAll()重新获取锁。
5.synchronized
Synchronized修饰非静态方法
Synchronized修饰非静态方法,实际上是对调用该方法的对象加锁,俗称“对象锁”。Java中每个对象都有一个锁,并且是唯一的。假设分配的一个对象空间,里面有多个方法,相当于空间里面有多个小房间,如果我们把所有的小房间都加锁,因为这个对象只有一把钥匙,因此同一时间只能有一个人打开一个小房间,然后用完了还回去,再由JVM去分配下一个获得钥匙的人。
情况1:同一个对象在两个线程中分别访问该对象的两个同步方法
结果:会产生互斥。
解释:因为锁针对的是对象,当对象调用一个synchronized方法时,其他同步方法需要等待其执行结束并释放锁后才能执行。
示例:
public class SynchronizedTest {
public synchronized void test1(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test1:"+thread.getId()+":"+i);
}
}
public synchronized void test2(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test2:"+thread.getId()+":"+i);
}
}
}
public static void main(String[] args) {
SynchronizedTest synchronizedTest = new SynchronizedTest();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest.test1();
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest.test2();
}
});
thread1.start();
thread2.start();
}
test1:11:0
test1:11:1
test1:11:2
test1:11:3
test1:11:4
test2:12:0
test2:12:1
test2:12:2
test2:12:3
test2:12:4
情况2:不同对象在两个线程中调用同一个同步方法
结果:不会产生互斥。
解释:因为是两个对象,锁针对的是对象,并不是方法,所以可以并发执行,不会互斥。形象的来说就是因为我们每个线程在调用方法的时候都是new 一个对象,那么就会出现两个空间,两把钥匙,
示例:
public class SynchronizedTest {
public synchronized void test1(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test1:"+thread.getId()+":"+i);
}
}
}
public static void main(String[] args) {
SynchronizedTest synchronizedTest1 = new SynchronizedTest();
SynchronizedTest synchronizedTest2 = new SynchronizedTest();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest1.test1();
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest2.test1();
}
});
thread1.start();
thread2.start();
}
test1:12:0
test1:11:1
test1:12:1
test1:12:2
test1:12:3
test1:11:2
test1:12:4
test1:11:3
test1:11:4
Synchronized修饰静态方法
Synchronized修饰静态方法,实际上是对该类对象加锁,俗称“类锁”。
情况1:用类直接在两个线程中调用两个不同的同步方法
结果:会产生互斥。
解释:因为对静态对象加锁实际上对类(.class)加锁,类对象只有一个,可以理解为任何时候都只有一个空间,里面有N个房间,一把锁,因此房间(同步方法)之间一定是互斥的。
注:上述情况和用单例模式声明一个对象来调用非静态方法的情况是一样的,因为永远就只有这一个对象。所以访问同步方法之间一定是互斥的。
public class SynchronizedTest {
static public synchronized void test1(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test1:"+thread.getId()+":"+i);
}
}
static public synchronized void test2(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test2:"+thread.getId()+":"+i);
}
}
}
public static void main(String[] args) {
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
SynchronizedTest.test1();
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
SynchronizedTest.test2();
}
});
thread1.start();
thread2.start();
}
test1:11:0
test1:11:1
test1:11:2
test1:11:3
test1:11:4
test2:12:0
test2:12:1
test2:12:2
test2:12:3
test2:12:4
情况2:一个对象在两个线程中分别调用一个静态同步方法和一个非静态同步方法
结果:不会产生互斥。
解释:因为虽然是一个对象调用,但是两个方法的锁类型不同,调用的静态方法实际上是类对象在调用,即这两个方法产生的并不是同一个对象锁,因此不会互斥,会并发执行。
public class SynchronizedTest {
static public synchronized void test1(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test1:"+thread.getId()+":"+i);
}
}
public synchronized void test2(){
Thread thread = Thread.currentThread();
for (int i = 0; i < 5; i++) {
System.out.println("test2:"+thread.getId()+":"+i);
}
}
}
public static void main(String[] args) {
SynchronizedTest synchronizedTest = new SynchronizedTest();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest.test1();
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronizedTest.test2();
}
});
thread1.start();
thread2.start();
}
synchronized与Lock的区别
synchronized是Java关键字,在JVM层面实现加锁和解锁;Lock是一个接口,在代码层面实现加锁和解锁
synchronized可以用在代码块上、方法上;Lock只能写在代码里。
synchronized在代码执行完或出现异常时自动释放锁;Lock不会自动释放锁,需要在finally中显示释放锁。
synchronized会导致线程拿不到锁一直等待;Lock可以设置获取锁失败的超时时间。
synchronized无法得知是否获取锁成功;Lock则可以通过tryLock得知加锁是否成功。
synchronized锁可重入、不可中断、非公平;Lock锁可重入、可中断、可公平/不公平,并可以细分读写锁以提高效率
6. ReentrantLock锁
内部构造
ReentrantLock 类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与 FairSync类继承自 Sync类,Sync类继承自 AbstractQueuedSynchronizer抽象类。下面逐个进行分析。
非公平锁
当线程争夺锁的过程中,会先进行一次CAS尝试获取锁,若失败,则进入acquire(1)函数,进行一次tryAcquire再次尝试获取锁,若再次失败,那么就通过addWaiter将当前线程封装成node结点加入到Sync队列,这时候该线程只能乖乖等前面的线程执行完再轮到自己了
公平锁
当线程在获取锁的时候,会先判断Sync队列中是否有在等待获取资源的线程。若没有,则尝试获取锁,若有,那么就那么就通过addWaiter将当前线程封装成node结点加入到Sync队列中
7.乐观锁和悲观锁的区别
悲观锁
顾名思义,就是比较悲观的锁,总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
反之,总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition****机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
乐观锁实现方式
1.版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。就是通过version版本号作为一个标识,标识这个字段所属的数据是否被改变。
2.CAS算法
即compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试
8.CAS
概述
概念
事例
CAS的全程是:Compare And Swap(比较并交换),CAS是实现并发计算时常用到的技术,Java并发包中的很多类都使用了CAS技术,如ConcurrentHashMap,AtomicInteger,ReentrantLock原子操作等
CAS操作涉及到3个操作符:当前内存中的值、预估值、即将修改的新增,当且仅当预估值等于内存中的值的时候,才将新的值保存到内存中,否则什么都不做
作用
CAS可以将比较和交换转换为原子操作,这个原子操作直接由CPU保证,CAS可以保证共享变量赋值时的原子操作
特点
CAS是一种非阻塞算法的实现,它能在不使用锁的情况下实现多线程安全,所以CAS也是一种无锁算法。
一个线程失败或挂起并不会导致其他线程也失败或挂起
优点
- 由于CAS是非阻塞的,可以避免优先级倒置和死锁等问题
- 性能好,使用无锁的方式,没有锁竞争带来的系统开销,也没有线程间频繁调度带来的开销
缺点
- 循环时间长开销大(自旋)如果CAS失败,会一直进行尝试,如果CAS长时间一直不成功,可能给CPU带来很大的开销
解决方法:
破坏调死循环,当超过一定时间或者一定次数时,return退出
-
只能保证一个共享变量的原子操作,当对一个共享变量操作时,可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性
解决方法:
用锁来保证原子性,把多个共享变量合成一个共享变量来操作封装成对象 ;Java1.5开始,JDK提供了AtomicReference类来保证引用对象之前的原子性,可以把多个变量放到一个对象里来进行CAS操作。
-
ABA问题
如果内存地址V初次读取的值是A,并且在准备赋值的时候检查到它的值仍然为A,那我们就能说明它的值没有被其他线程改变过吗?
如果在这段期间它的值曾经被改称了B,然后又改为A,那CAS就会误认为它从来没有被修改过,这就是ABA问题
解决方法:
-
Java并发包提供了一个带有标记的原子引用类AtomicStampedReference,它可以通过控制变量值的版本来保证CAS的正确性;即在变量前面添加版本号,每次变量更新的时候都把版本号+1,这样变化过程就变成A-B-A变成1A-2B-3A
-
增加时间戳
-
9.volatile
概念
volatile是Java中的关键字,用来修饰会被不同线程访问和修改的变量。JMM(Java内存模型)是围绕并发过程中如何处理可见性、原子性和有序性这3个特征建立起来的,而volatile可以保证其中的两个特性。
特性
- 可见性
- 可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉。通常,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有时甚至是根本不可能的事情。为了确保多个线程之间对内存写入操作的可见性,必须使用同步机制。
- 可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果。另一个线程马上就能看到。
- 在 Java 中 volatile、synchronized 和 final 都可以实现可见性。
- 原子性
- 原子性指的是某个线程正在执行某个操作时,中间不可以被加塞或分割,要么整体成功,要么整体失败。比如 a=0;(a非long和double类型) 这个操作是不可分割的,那么我们说这个操作是原子操作。再比如:a++; 这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。Java的 concurrent 包下提供了一些原子类,AtomicInteger、AtomicLong、AtomicReference等。
- 在 Java 中 synchronized 和在 lock、unlock 中操作保证原子性。
- 有序性
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含“禁止指令重排序”的语义,synchronized 是由“一个变量在同一个时刻只允许一条线程对其进行 lock 操作”这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行执行。
volatile是Java虚拟机提供的轻量级同步机制
- 保证可见性
- 不保证原子性
- 禁止指令重排(保证有序性)
原理
volatile 可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在 JVM 底层是基于内存屏障实现的。
-
当对非 volatile 变量进行读写的时候,每个线程先从内存拷贝变量到 CPU 缓存中。如果计算机有多个CPU,每个线程可能在不同的 CPU 上被处理,这意味着每个线程可以拷贝到不同的 CPU cache 中。
-
而声明变量是 volatile 的,JVM 保证了每次读变量都从内存中读,跳过 CPU cache 这一步,所以就不会有可见性问题。
-
对 volatile 变量进行写操作时,会在写操作后加一条 store 屏障指令,将工作内存中的共享变量刷新回主内存;
-
对 volatile 变量进行读操作时,会在写操作后加一条 load 屏障指令,从主内存中读取共享变量;
-
有 volatile 修饰的共享变量进行写操作时会对原值加零,其中相加指令addl前有 lock 修饰。通过查IA-32架构软件开发者手册可知,lock前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会引起在其他CPU里缓存了该内存地址的数据无效
正是 lock 实现了 volatile 的「防止指令重排」「内存可见」的特性
适用场景
- 对变量的写操作不依赖于当前值
- 该变量没有包含在具有其他变量的不变式中
其实就是在需要保证原子性的场景,不要使用 volatile。
性能
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
10.线程池类
线程池的几种状态
- RUNNING: 运行状态,能够接受新的任务且会处理阻塞队列中的任务。
- SHUTDOWN:关闭状态,不接受新任务,但是会处理阻塞队列中的任务,执行线程池的 shutDown对应的就是此状态。
- STOP:停止状态,不接受新的任务,也不会处理等待队列中的任务并且会中断正在执行的任务。调用线程池的 shutDownNow对应的是此状态
- TIDYING: 整理,即所有的任务都停止了,线程池中线程数量等于0,会调用 terminated如果你自己实现线程池的话。
- TERMINATED:结束状态,terminated方法执行完了。
线程池的运行流程

-
提交任务后会首先进行当前工作线程数与核心线程数的比较,如果当前工作线程数小于核心线程数,则直接调用 addWorker() 方法创建一个核心线程去执行任务;
-
如果工作线程数大于核心线程数,即线程池核心线程数已满,则新任务会被添加到阻塞队列中等待执行,当然,添加队列之前也会进行队列是否为空的判断;
-
如果线程池里面存活的线程数已经等于核心线程数了,且阻塞队列已经满了,再会去判断当前线程数是否已经达到最大线程数 maximumPoolSize,如果没有达到,则会调用 addWorker() 方法创建一个非核心线程去执行任务;
-
如果当前线程的数量已经达到了最大线程数时,当有新的任务提交过来时,会执行拒绝策略
总结来说就是优先核心线程、阻塞队列次之,最后非核心线程。
线程任务的获取
而线程获取任务的方式有两种,根据线程池容量区间,以及是否可以释放核心线程来使用take或者poll来获取任务,其中poll在一定时间内获取不到任务,则当前线程会被释放。
线程池里的核心线程为什么不死的原因
线程池里的线程从阻塞队列里拿任务,如果存在非核心线程,假设阻塞队列里没有任务,那么非核心线程也要在等到keepAliveTime时间后才会释放。如果当前仅有核心线程存在,如果允许释放核心线程的话,也就和非核线程的处理方式一样,反之,则通过take一直阻塞直到拿到任务,这也就是线程池里的核心线程为什么不死的原因。
从之前的代码一直看到这,并没有发现有明显的标志来标志核心线程与非核心线程,而是以线程数来表达线程身份。0 ~ corePoolSize 表示线程池里只有核心线程,corePoolSize ~ maximumPoolSize 表示线程池里核心线程满,存在非核心线程。
然后,根据区间状态做有差异的处理。可以大胆猜测,线程池实际并不区分核心线程与非核心线程,是根据当前的总体并发状态来决定怎样处理线程任务。corePoolSize是线程池希望达到并保持的并发状态,而corePoolSize ~ maximumPoolSize则是线程池允许的并发的超载状态,不希望长期保持。
线程池任务添加失败
在addWorker方法来有任务添加失败的策略,也就是RejectedExecutionHandler。ThreadPoolExecutor实现了四种策略来进行处理,简单了解即可:
- CallerRunsPolicy: 如果线程池没有SHUTODOWN的话,直接执行任务
- AbortPolicy: 抛出异常,说明当前情况的线程池不希望得到接收不了任务的状态
- DiscardOldestPolicy:丢弃阻塞队列最旧的任务
- DiscardPolicy:什么也不做
需要注意的是,默认情况下策略为AbortPolicy。
ExecutorService线程池
不同类型的线程池的实现
newCachedThreadPool()(可缓存线程池)
底层使用SynchronousQueue
-
缓存型池子,先查看池中有没有以前建立的线程,如果有,就reuse.如果没有,就建一个新的线程加入池中
-
缓存型池子通常用于执行一些生存期很短的异步型任务因此在一些面向连接的daemon型SERVER中用得不多。
-
能reuse的线程,必须是timeout IDLE内的池中线程,缺省timeout是60s,超过这个IDLE时长,线程实例将被终止及移出池。
-
适合异步任务多,但周期短的场景
注意:放入CachedThreadPool的线程不必担心其结束,超过TIMEOUT不活动,其会自动被终止。
newFixedThreadPool()
底层使用LinkedBlockingQueue
- newFixedThreadPool与cacheThreadPool差不多,也是能reuse就用,但不能随时建新的线程
- 其独特之处:任意时间点,最多只能有固定数目的活动线程存在,此时如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池子
- 和cacheThreadPool不同,FixedThreadPool没有IDLE机制(可能也有,但既然文档没提,肯定非常长,类似依赖上层的TCP或UDP IDLE机制之类的),所以FixedThreadPool多数针对一些很稳定很固定的正规并发线程,多用于服务器
- 从方法的源代码看,cache池和fixed 池调用的是同一个底层池,只不过参数不同:
- fixed池线程数固定,并且是0秒IDLE(无IDLE)
- 适合有一定异步任务,周期较长的场景,能达到有效的并发状态
cache池线程数支持0-Integer.MAX_VALUE(显然完全没考虑主机的资源承受能力),60秒IDLE
ScheduledThreadPool()
底层使用DelayedWorkQueue
- 调度型线程池
- 这个池子里的线程可以按schedule依次delay执行,或周期执行
- 适合周期性执行任务的场景
SingleThreadExecutor()(单线程化的线程池)
底层使用LinkedBlockingQueue
- 单例线程,任意时间池中只能有一个线程
- 用的是和cache池和fixed池相同的底层池,但线程数目是1-1,0秒IDLE(无IDLE)
- 适合任务串行的场景
invokeAll、invokeAny、submit、execute方法的区别
invokeAll触发执行任务列表,返回的结果顺序也与任务在任务列表中的顺序一致.所有线程执行完任务后才返回结果。如果设置了超时时间,未超时完成则正常返回结果,如果超时未完成则报异常。
invokeAny将第一个得到的结果作为返回值,然后立刻终止所有的线程。如果设置了超时时间,未超时完成则正常返回结果,如果超时未完成则报超时异常。
execute(Runnable x) 没有返回值。可以执行任务,但无法判断任务是否成功完成。——实现Runnable接口
submit(Runnable x) 返回一个future。可以用这个future来判断任务是否成功完成。——实现Callable接口
总结
- invokeAll和invokeAny会直接造成主线程阻塞(需要设置超时时间)。等待所有任务执行完成后返回结果,主线程继续执行。
- submit不会造成主线程阻塞,在后面执行get方法的时候阻塞。超时时间在get里面设置。
- execute会新开启线程直接执行任务,不会阻塞主线程。但无返回结果。
线程池的关闭
Shutdown
方法不会导致立即销毁ExecutorService。它将使ExecutorService停止接受新任务,并在所有正在运行的线程完成当前工作后关闭。
shutdownNow
方法试图立即摧毁ExecutorService,但是它并不能保证所有正在运行的线程将同时停止。此方法返回等待处理的任务列表。由开发人员决定如何处理这些任务。
配合awaitTermination使用
executorService.shutdown();
try{
if(!executorService.awaitTermination(800, TimeUnit.MILLISECONDS)){
executorService.shutdownNow();
}
}catch(InterruptedException e){
executorService.shutdownNow();
}
BlockingQueue
BlockingQueue,如果BlockQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作.
使用BlockingQueue的关键技术点如下:
-
BlockingQueue定义的常用方法如下:
- add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则招聘异常
- offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
- put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
- poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
- take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
-
BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
-
ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
-
LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
-
PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
-
SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
-
-
LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
如何判断线程池中的线程已经执行完毕
CountDownLatch
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程执行完后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有框架服务之后执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始化值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就相应得减1。当计数器到达0时,表示所有的线程都已完成任务,然后在闭锁上等待的线程就可以恢复执行任务。
isTerminated()
若关闭后所有任务都已完成,则返回true。注意除非首先调用shutdown或shutdownNow,否则isTerminated永不为true。返回:若关闭后所有任务都已完成,则返回true。
多线程按指定顺序执行
join方式
原理就是让main这个主线程等待子线程结束,然后主线程再执行接下来的其他线程任务
public static void main(String[] args) throws Exception{
thread1.start();
thread1.join();
thread2.start();
thread2.join();
thread3.start();
thread3.join();
thread4.start();
thread4.join();
thread5.start();
thread5.join();
}
ExecutorService方式
原理其实就是将线程用排队的方式扔进一个线程池里,让所有的任务以单线程的模式,按照FIFO先进先出、LIFO后进先出、优先级等特定顺序执行,但是这种方式也是存在缺点的,就是当一个线程被阻塞时,其它的线程都会受到影响被阻塞,不过依然都会按照自身调度来执行,只是会存在阻塞延迟。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class AppExecutorService {
static Thread thread1 = new Thread(() -> System.out.println("thread1"));
static Thread thread2 = new Thread(() -> System.out.println("thread2"));
static Thread thread3 = new Thread(() -> System.out.println("thread3"));
static ExecutorService executorService = Executors. newSingleThreadExecutor();
public static void main(String[] args) {
executorService.submit(thread1);
executorService.submit(thread2);
executorService.submit(thread3);
executorService.shutdown();
}
}
(3)其他
1.面向对象三大特性
继承
继承是从已有类得到继承信息创建新类的过程。提供继承信息的类被称为父类(超类、基类);得到继承信息的类被称为子类(派生类)。继承让变化中的软件系统有了一定的延续性,同时继承也是封装程序中可变因素的重要手段。
封装
通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口。面向对象的本质就是将现实世界描绘成一系列完全自治、封闭的对象。我们在类中编写的方法就是对实现细节的一种封装;我们编写一个类就是对数据和数据操作的封装。可以说,封装就是隐藏一切可隐藏的东西,只向外界提供最简单的编程接口。
多态性
多态性是指允许不同子类型的对象对同一消息作出不同的响应。简单的说就是用同样的对象引用调用同样的方法但是做了不同的事情。多态性分为编译时的多态性和运行时的多态性。如果将对象的方法视为对象向外界提供的服务,那么运行时的多态性可以解释为:当A系统访问B系统提供的服务时,B系统有多种提供服务的方式,但一切对A系统来说都是透明的。方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的时运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西,要实现多态需要做两件事:1.方法重写(子类继承父类并重写父类中已有的或抽象的方法);2.对象造型(用父类型引用子类型对象,这样同样的引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
抽象
抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
2.Object类的常用方法
- equals()
- hashCode()
- toString()
- getClass()
- wait()
- notify()
- notifyall()
- clone()
- finalize()
3.string、stringBuffer和stringBuilder
- string不可变、线程安全
- stringBuffer可变,效率低,线程安全
- stringBuilder可变、效率高,线程不安全
4.抽象类与接口的区别
- 抽象类属于继承,只能继承一个;接口可以实现多个
- 抽象类有构造方法;接口没有构造方法
- 抽象类的成员变量可以是变量也可以是常量;接口的成员变量只能是常量,默认修饰符public static final
- 抽象类的成员方法可以是抽象的也可以是具体实现的;接口在jdk1.7只能是抽象的成员方法,jdk1.8之后可以有具体实现且必须用 default修饰。并且接口也可以有静态方法,static修饰。
抽象类和接口的选择:如果关注的是一个事务的本质,就用抽象类;关注一个操作的时候就用接口。比如,关注一个人,男人或女人,这时候关注的是本质,就用抽象类。关注每种人吃东西,睡觉各种动作不同,就需要用接口,定义一个模板,分别去实现。
5.java的基本数据类型
byte:1字节(8位),数据范围是 -2^7 ~ 2^7-1。
short:2字节(16位),数据范围是 -2^15 ~ 2^15-1。
int:4字节(32位),数据范围是 -2^31 ~ 2^31-1。
long:8字节(64位),数据范围是 -2^63 ~ 2^63-1。
float:4字节(32位),数据范围大约是 -3.410^38 ~ 3.410^38。
double:8字节(64位),数据范围大约是 -1.810^308 ~ 1.810^308。
char:2字节(16位),数据范围是 \u0000 ~ \uffff。
boolean:Java规范没有明确的规定,不同的JVM有不同的实现机制
6.java代码块执行顺序
- 父类静态代码块
- 子类静态代码块
- 父类构造代码块
- 父类构造方法
- 子类构造代码块
- 子类构造方法
- 普通代码块
7.static关键字
修饰成员变量:该静态变量在内存中只有一个副本。只要静态变量所在的类被加载,这个静态变量就会被分配空间
修饰成员方法:调用该方法只需类名.方法名;静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的。在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都必须依赖具体的对象才能够被调用。
修饰代码块:在类初次被加载的时候,会按照static块的顺序来依次执行每个static块,并且只会执行一次。
修饰内部类:静态内部类不能直接访问外部类的非静态成员,但可以通过new 外部类().成员的方式访问;
8.重写和重载的区别
- 重写一般是子类重写父类方法(一对一),垂直关系;重载一般是一个类中多个方法重载(多个之间),水平关系
- 重写方法之间参数相同;重载方法之间参数不同
- 重写不可以修改返回值类型;重载可以修改返回值类型
9.java四个访问修饰符
- private:本类中
- default:本包中
- protected:不同包的子类
- public:所有
10.全局变量和局部变量的区别
成员变量:
- 成员变量是在类的范围里定义的变量;
- 成员变量有默认初始值;
- 未被static修饰的成员变量也叫实例变量,它存储于对象所在的堆内存中,生命周期与对象相同;
- 被static修饰的成员变量也叫类变量,它存储于方法区中,生命周期与当前类相同。
局部变量:
- 局部变量是在方法里定义的变量;
- 局部变量没有默认初始值;
- 局部变量存储于栈内存中,作用的范围结束,变量空间会自动的释放。
11.hashCode()和equals()的关系
- hashCode求的是对象的散列码(一般是对象的储存地址),equals是根据地址比较对象是否相同
- 如果两个对象相等,则它们必须有相同的哈希码
- 如果两个对象有相同的哈希码,则它们未必相等
12.为什么要重写hashCode()和equals()
Object类提供的equals()方法默认是用==来进行比较的,也就是说只有两个对象是同一个对象时,才能返回相等的结果。而实际的业务中,我们通常的需求是,若两个不同的对象它们的内容是相同的,就认为它们相等。
- 只需要一个类重写了equals,那么两个对象使用equals比较的时候比较的是属性值,但是不重写equals,比较的只是地址值。这时候hashcode值不相等。如果同时重写了hashcode和equals,那么两个对象的hashcode值是相等的,同时两个对象比较也是比较属性值。所以说,重写了hashcode,此类对象的hashcode值是相等的。重写了eqluas,进行比较的是属性值。如果单纯的比较值,重写equals即可。
- 我们在使用set集合和map的时候由于不重复原则(不重复一般指对象的属性不相等),必须重写hashcoe和equals,是因为根据hash算法,会先比较hashcode值是否相等或者获取存储位置,然后再比较使用equals比较;如果不重写hashcode,那么hashcode指是不相等的,就会直接存储,不会进行equals比较,有可能造成属性相等,存储重复的对象,违背不重复原则,所以必须重写hashcode和equals
13.反射
作用
反射机制是在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意个对象,都能够调用它的任意一个方法。在java中,只要给定类的名字,就可以通过反射机制来获得类的所有信息。这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
效率
通过new创建对象的效率比较高。通过反射时,先找查找类资源,使用类加载器创建,过程比较繁琐,所以效率较低。
创建对象的方式
new
Class.newInstance:
这是我们运用反射创建对象时最常用的方法。
Class类的newInstance使用的是类的public的无参构造方法。因此也就是说使用此方法创建对象的前提是必须有public的无参构造器才行
/ **
* [2] 使用class #ÁJnewInstanceFi1
*反射原理
*/
@Test
public void fun2() í
try{
Person01 person = Person01. class. newInstance() ;
person.setName("Rose");
person.setAge(18);
System.out. println("=-=> [2]class类的newInstance方法创建对象");
System.out.println("姓名: " + person.getName());
System.out.println("年龄: " + person.getAge());
}catch (InstantiationException | IllegalAccessException e) {
е.printStackTrace();
}
}
Constructor.newInstance
该方法和Class类的newInstance方法很像,但是比它强大很多。java.lang.relect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数(不再必须是无参)的和私有的构造函数(不再必须是public)
System.out.println("=======Constructor类的newInstance方法");
Constructor<PrintTest> constructor = PrintTest.calss.getConstrustor();
PrintTest printTest3 = (PrintTest) constructor.newInstance();
printTest3.seName("printTest3");
System.out.println(printTest3 + ",hashcode:" + printTest3.hashcode());
printTest3.hello();
Clone
无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。
要使用clone方法,我们必须先实现Cloneable接口并复写Object的clone方法(因为Object的这个方法是protected的,若不复写,外部也调用不了)。
序列化**(JDK序列化、反序列化特别特别耗内存)**
当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象。在反序列化时,JVM创建对象并不会调用任何构造函数。为了反序列化一个对象,我们需要让我们的Person01类实现Serializable接口。
@Test
public void fun5(){
String filePath = "F:\\Tests\\data.obj";
try{
//序列化过程
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(filePath));
objectOutputStream.writeObject(new Person01("序列化,后边要进行序列化了",123456));
objectOutputStream.close();
//反序列化过程
ObjectInputStream inputSteram = new ObjectInputStrea(new FileInputStream(filePath));
Person01 person = (Person) inputSteram.readObject();
inputSteram.close();
//console打印
System.out.println("=====>[5]使用反序列化创建对象");
System.out.println("姓名:"+person.getName());
System.out.println("年龄:"+person.getAge());
}catch(IOException | ClassNotFoundException e){
e.printStackTrace();
}
}
获取Class对象
- Class.forName(“类的路径”);
- 类名.class;
- 对象名.getClass();
- 基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象。
类属性
- Class:表示正在运行的Java应用程序中的类和接口,注意所有获取对象的信息都需要Class类来实现;
- Field:提供有关类和接口的属性信息,以及对它的动态访问权限;
- Constructor:提供关于类的单个构造方法的信息以及它的访问权限;
- Method:提供类或接口中某个方法的信息。
优点
- 能够运行时动态获取类的实例,提高灵活性;
- 与动态编译结合Class.forName(‘com.mysql.jdbc.Driver.class’);//加载MySQL的驱动类
缺点
使用反射性能较低,需要解析字节码,将内存中的对象进行解析。
14.IO
说明
IO是一种数据的流从源头流到目的地。比如文件拷贝,输入流和输出流都包括了。输入流从 文件中读取数据存储到进程(process)中,输出流从进程中读取数据然后写入到目标文件。
分类
- 字节流、字符流
(a)直接可以操作字节的称为字节流,如操作图像、视频等;
(b)直接可以操作字符的称为字符流,如文本文件;
(c)字节流不可以直接操作字符,字符流不可以直接操作字节,相互操作需要借助转换流。
- 节点流、处理流
(a)直接可以操作文件的为节点流;
(b)不可以直接处理文件,包裹字节流的称为处理流。
IO 里面的常见类,字节流、字符流、接口、实现类、方法阻塞?
输入流就是从外部文件输入到内存,输出流主要是从内存输出到文件。
IO 里面常见的类,第一印象就只知道 IO 流中有很多类,IO 流主要分为字符流和字节流。字节流有 抽 象 类 InputStream 和 OutputStream , 它 们 的 子 类 FileInputStream ,FileOutputStream,BufferedOutputStream 等。字符流 BufferedReader 和 Writer 等。都实现了 Closeable, Flushable, Appendable 这些接口。程序中的输入输出都是以流的形式保存的,流中保存的实际上全都是字节文件。 java 中的阻塞式方法是指在程序调用该方法时,必须等待输入数据可用或者检测到输入结束或者抛出异常,否则程序会一直停留在该语句上,不会执行下面的语句。比如 read()和readLine()方法。
字节流和字符流的区别?
字符流和字节流的使用非常相似,但是实际上字节流的操作不会经过缓冲区(内存)而是直接操作文本本身的,而字符流的操作会先经过缓冲区(内存)然后通过缓冲区再操作文件以字节为单位输入输出数据,字节流按照 8 位传输 以字符为单位输入输出数据,字符流按照 16 位传输
字节流读取的时候,读到一个字节就返回一个字节;字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,在 UTF-8 码表中是 3 个字节)时。先去查指定的编码表,将查到的字符返回。字节流可以处理所有类型数据,如:图片,MP3,AVI视频文件,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流。字节流主要是操作 byte 类型数据,以 byte 数组为准,主要操作类就是 OutputStream、InputStream字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字节数组。所以字符流是由 Java 虚拟机将字节转化为 2 个字节的 Unicode 字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点。在程序中一个字符等于两个字节,java 提供了 Reader、Writer 两个专门操作字符流的类。
IO分类
传统的BIO(同步阻塞的BIO)
就是说服务端一旦接受客户端的连接,就可以建立通信套接字在这个通信套接字上进行读写操作,
此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成,
不过可以通过多线程来支持多个客户端的连接,循环导致高cpu消耗。
服务器的实现模式是一个连接一个线程,这样的模式很明显的一个缺陷是:
由于客户端连接数与服务器线程数成正比关系,
可能造成不必要的线程开销,严重的还将导致服务器内存溢出。当然,
这种情况可以通过线程池机制改善,但并不能从本质上消除这个弊端。
问题:当出现高并发怎么办?
解决这个问题就有了下面的
NIO(同步非阻塞的NIO)。它支持面向缓冲的,基于通道的I/O操作方法
从JDK1.4以后开始,JDK引入的新的IO模型NIO
Channel(通道):通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
Buffer(缓冲区):Buffer是一个对象,它包含一些要写入或者要读出的数据
Selector(选择器):选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
就是说加了三个功能来解决bio中的单线程一对多的问题
而服务器的实现模式是多个请求一个线程,即请求会注册到多路复用器Selector上,
多路复用器轮询到连接有IO请求时才启动一个线程处理。
Java NIO: 单线程管理多个连接。
劣处:维护成本高,容易出现bug,项目大了之后消耗成本
AIO(异步非阻塞的AIO)
JDK1.7发布了NIO2.0也可以说是Nio的加强版,它是异步非阻塞的IO模型。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,
不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
这就是真正意义上的异步非阻塞,服务器的实现模式为多个有效请求一个线程,
客户端的IO请求都是由OS先完成再通知服务器应用去启动线程处理(回调)。
使用场景
并发连接数不多时采用BIO,因为它编程和调试都非常简单,但如果涉及到高并发的情况,应选择NIO或AIO,更好的建议是采用成熟的网络通信框架Netty。
总结
- BIO是一个连接一个线程。
- NIO是一个请求一个线程。
- AIO是一个有效请求一个线程。
IO与NIO区别
面向流和面向缓冲区
- Java IO 是面向流的而Java NIO是面向缓冲区的,就如同一个的重点在于过程,另一重点在于一个有一个阶段。
在Java IO中读取数据和写入数据是面向流(Stream)的,就如同河流一样。所有的数据不停地向前的流淌,我们只能触碰到当前的流水。
如果需要获取某个数据的前一项或后一项数据那就必须自己缓存数据(将水从河流中打出来),而不能直接从流中获取(因为面向流就意味着我们只有一个数据流的切面)
- Java NIO中数据的读写是面向缓冲区(Buffer)的,读取时可以将整块的数据读取到缓冲区中,在写入时则可以将整个缓冲区中的数据一起写入。
这就好像是在河流上建立水坝,面向流的数据读写只提供了一个数据流切面,而面向缓冲区的IO则使我们能够看到所有的水(数据的上下文),也就是说在缓冲区中获取某项数据的前一项数据或者是后一项数据十分方便。这种便利是有代价的,因为我们必须管理好缓冲区,这包括不能让新的数据覆盖了缓冲区中还没有被处理的有用数据;将缓冲区中的数据正确的分块,分清哪些被处理过哪些还没有等等。
阻塞和非阻塞
-
Java IO是阻塞的,如果在一次读写数据调用时数据还没有准备好,或者目前不可写,那么读写操作就会被阻塞直到数据准备好或目标可写为止。
-
Java NIO则是非阻塞的,每一次数据读写调用都会立即返回,并将目前可读(或可写)的内容写入缓冲区或者从缓冲区中输出,即使当前没有可用数据,调用仍然会立即返回并且不对缓冲区做任何操作。
举个例子:
IO和NIO去超市买东西,如果超市中没有需要的商品或者数量还不够, IO会一直等到超市中需要的商品数量足够了就将所有需要的商品带回来。Java NIO则不同,不论超市中有多少需要的商品,它都将有需要的商品,立即全部买下并返回,甚至是没有需要的商品也会立即返回。
IO 要求一次完成任务,NIO允许多次完成任务
读取形式
java中,IO属于流式IO,即 Stream/IO。它只能一个字节一个字节的处理数据。
而NIO是以Block的方式来读取数据的,以块的形式从磁盘上读取数据,所以它能提升IO的效率。
NIO 和传统的 IO 的区别
-
传统 IO 一般是一个线程等待连接,连接过来之后分配给 processor 线程,processor 线程与通道连接后如果通道没有数据过来就会阻塞(线程被动挂起)不能做别的事情。NIO 则不同,首先,在 selector 线程轮询的过程中就已经过滤掉了不感兴趣的事件,其次,在 processor处理感兴趣事件的 read 和 write 都是非阻塞操作即直接返回的,线程没有被挂起。
-
传统 io 的管道是单向的,nio 的管道是双向的。
-
两者都是同步的,也就是 java 程序亲力亲为的去读写数据,不管传统 io 还是 nio 都需要read 和 write 方法,这些都是 java 程序调用的而不是系统帮我们调用的,nio2.0 里这点得到了改观,即使用异步非阻塞 AsynchronousXXX 四个类来处理。
IO实现中用到的设计模式
装饰器模式
装饰器(Decorator)模式 可以在不改变原有对象的情况下拓展其功能。装饰器模式通过组合替代继承来扩展原始类的功能,在一些继承关系比较复杂的场景(IO 这一场景各种类的继承关系就比较复杂)更加实用。
对于字节流来说, FilterInputStream (对应输入流)和FilterOutputStream(对应输出流)是装饰器模式的核心,分别用于增强 InputStream 和OutputStream子类对象的功能。
我们常见的BufferedInputStream(字节缓冲输入流)、DataInputStream 等等都是FilterInputStream 的子类,BufferedOutputStream(字节缓冲输出流)、DataOutputStream等等都是FilterOutputStream的子类。
举个例子,我们可以通过 BufferedInputStream(字节缓冲输入流)来增强 FileInputStream 的功能。
适配器模式
适配器(Adapter Pattern)模式 主要用于接口互不兼容的类的协调工作,你可以将其联想到我们日常经常使用的电源适配器。
适配器模式中存在被适配的对象或者类称为 适配者**(Adaptee)** ,作用于适配者的对象或者类称为适配器****(Adapter) 。适配器分为对象适配器和类适配器。类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
IO 流中的字符流和字节流的接口不同,它们之间可以协调工作就是基于适配器模式来做的,更准确点来说是对象适配器。通过适配器,我们可以将字节流对象适配成一个字符流对象,这样我们可以直接通过字节流对象来读取或者写入字符数据。
InputStreamReader 和 OutputStreamWriter 就是两个适配器(Adapter), 同时,它们两个也是字节流和字符流之间的桥梁。InputStreamReader 使用 StreamDecoder (流解码器)对字节进行解码,实现字节流到字符流的转换, OutputStreamWriter 使用StreamEncoder(流编码器)对字符进行编码,实现字符流到字节流的转换。
InputStream 和 OutputStream 的子类是被适配者, InputStreamReader 和 OutputStreamWriter是适配器。
适配器模式和装饰器模式有什么区别呢?
装饰器模式 更侧重于动态地增强原始类的功能,装饰器类需要跟原始类继承相同的抽象类或者实现相同的接口。并且,装饰器模式支持对原始类嵌套使用多个装饰器。
适配器模式 更侧重于让接口不兼容而不能交互的类可以一起工作,当我们调用适配器对应的方法时,适配器内部会调用适配者类或者和适配类相关的类的方法,这个过程透明的。就比如说 StreamDecoder (流解码器)和StreamEncoder(流编码器)就是分别基于 InputStream 和 OutputStream 来获取 FileChannel对象并调用对应的 read 方法和 write 方法进行字节数据的读取和写入。
工厂模式
工厂模式用于创建对象,NIO 中大量用到了工厂模式,比如 Files 类的 newInputStream 方法用于创建 InputStream 对象(静态工厂)、 Paths 类的 get 方法创建 Path 对象(静态工厂)、ZipFileSystem 类(sun.nio包下的类,属于 java.nio 相关的一些内部实现)的 getPath 的方法创建 Path 对象(简单工厂)。
观察者模式
NIO 中的文件目录监听服务使用到了观察者模式。
NIO 中的文件目录监听服务基于 WatchService 接口和 Watchable 接口。WatchService 属于观察者,Watchable 属于被观察者。
Watchable 接口定义了一个用于将对象注册到 WatchService(监控服务) 并绑定监听事件的方法 register 。
什么是 Java 序列化,如何实现 Java 序列化?
序列化就是一种用来处理对象流的机制,将对象的内容进行流化。可以对流化后的对象进行读写操作,可以将流化后的对象传输于网络之间。序列化是为了解决在对象流读写操作时所引发的问题
序列化的实现:将需要被序列化的类实现 Serialize 接口,没有需要实现的方法,此接口只是为了标注对象可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,再使用 ObjectOutputStream 对象的 write(Object obj)方法就可以将参数 obj 的对象写出
Java 中有几种类型的流?
按照流的方向:输入流(inputStream)和输出流(outputStream)
按照实现功能分:节点流(可以从或向一个特定的地方(节点)读写数据。如 FileReader)和处理流(是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如 BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。)
什么是缓冲区?有什么作用?
缓冲区就是一段特殊的内存区域,很多情况下当程序需要频繁地操作一个资源(如文件或数据库)则性能会很低,所以为了提升性能就可以将一部分数据暂时读写到缓存区,以后直接从此区域中读写数据即可,这样就可以显著的提升性能。 对于 Java 字符流的操作都是在缓冲区操作的,所以如果我们想在字符流操作中主动将缓冲区刷新到文件则可以使用 flush() 方法操作。
15.哈希冲突
原因
哈希是通过对数据进行再压缩,提高效率的一种解决方法。但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致经过哈希函数处理后仍然有不同的数据对应相同的值。这时候就产生了哈希冲突。
影响因素
装填因子(装填因子=数据总数 / 哈希表长)、哈希函数、处理冲突的方法
解决方法
1.开放地址方法
(1)线性探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突。
(2)再平方探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
(3)伪随机探测
按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
2.链式地址法(HashMap的哈希冲突解决方法)
对于相同的值,使用链表进行连接。使用数组存储每一个链表。
优点:
(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
缺点:
指针占用较大空间时,会造成空间浪费,若空间用于增大散列表规模进而提高开放地址法的效率。
3.建立公共溢出区
建立公共溢出区存储所有哈希冲突的数据。
4.再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
16.throw和throws的区别
· throws跟在方法声明后,后面跟的是异常类名;throw在方法内,后面跟的是异常类实例
· throws后面可以跟多个异常类;throw只能抛出一个异常对象
· throws抛出异常,异常由调用者处理;throw由方法体内的语句来处理
17.设计模式
创建型(5):工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型(7):适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型(11):策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
设计模式的几个原则
· 单一职责原则
· 接口隔离原则
· 里氏替换原则
· 开闭原则
· 迪米特原则
· 依赖倒置原则
· 合成复用原则
单例实现
饿汉模式
public class Singleton {
/**
* 私有实例,静态变量会在类加载的时候初始化,是线程安全的
*/
private static final Singleton instance = new Singleton();
/**
* 私有构造方法
*/
private Singleton() {
}
/**
* 唯一公开获取实例的方法(静态工厂方法)
*
* @return
*/
public static Singleton getInstance() {
return instance;
}
}
懒汉式(线程不安全)
public class Singleton {
/**
* 私有实例
*/
private static Singleton instance;
/**
* 私有构造方法
*/
private Singleton() {
}
/**
* 唯一公开获取实例的方法(静态工厂方法),
*
* @return
*/
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
懒汉式(线程安全)
public class Singleton {
/**
* 私有实例
*/
private static Singleton instance;
/**
* 私有构造方法
*/
private Singleton() {
}
/**
* 唯一公开获取实例的方法(静态工厂方法),该方法使用synchronized加锁,来保证线程安全性
*
* @return
*/
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
双重检索模式(线程安全)
public class Singleton {
/**
* 私有实例 volatile
*/
private volatile static Singleton instance;
/**
* 私有构造方法
*/
private Singleton() {
}
/**
* 唯一公开获取实例的方法(静态工厂方法)
*
* @return
*/
public static Singleton getUniqueInstance() {
//第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作
if (instance == null) {
// 加锁
synchronized (Singleton.class) {
//第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 instance == null 时两个线程同时进行实例化操作。
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
18.spring中涉及的设计模式
· 工厂模式:BeanFactory和ApplicationContext来创建对象
· 单例模式:Bean默认为单例模式
· 代理模式:AOP动态代理
· 模板方法:jdbcTemplete,restTemplete(http请求工具)
· 适配器模式:mvc中的处理器适配
· 观察者模式:spring时间驱动行
(4)JDK1.8新特性
Lambda表达式
Lambda是一个匿名函数,我们可以将Lambda表达式理解为一段可以传递的代码(将代码像数据一样传递)。使用它可以写出简洁、灵活的代码。作为一种更紧凑的代码风格,使java语言表达能力得到提升。
Lambda表达式在java语言中引入了一种新的语法元素和操作。这种操作符号为“->”,Lambda操作符或箭头操作符,它将Lambda表达式分割为两部分。 左边:指Lambda表达式的所有参数 右边:指Lambda体,即表示Lambda表达式需要执行的功能。
Lambda表达式语法
1、语法格式一:无参数、无返回值,只需要一个Lambda体
public class Demo2{
private static Logger log = LoggerFactory.getLogger(Demo2.class);
public static void main(String[] arg){
Runnable t1 = ()-> log.info("lambda表达式:简洁、灵活");
}
}
2、语法格式二:lambda有一个参数、无返回值
public class Demo3{
private static Logger log = LoggerFactory.getLogger(Demo2.class);
public static void main(String[] arg){
Consumer<String> consumer = new Consumer<String>(){
@Override
public void accept(String s){
log.info(s);
}
};
consumer.accept("test");
Consumer<String> consumer1 = (s) -> log.info(s);
consumer1.accept("test");
}
}
3、语法格式三:Lambda只有一个参数时,可以省略()
public class Demo4{
private static Logger log = LoggerFactory.getLogger(Demo2.class);
public static void main(String[] arg){
Consumer<String> consumer1 = s -> log.info(s);
consumer1.accept("Lambda只有一个参数时,可以忽略()");
}
}
4、语法格式四:Lambda有两个参数时,并且有返回值
//没有使用lambda表达式
public static void CompareOldMethod(int num1,int num2){
Compartor<Integer> compartor = new Compartor<Integer>(){
@Override
public int compare(Integer o1,Integer o2){
log.info(o1);
log.info(o2);
return o1 < o2 ? o2 :o1;
}
};
log.info("oldFindMaxValue:{}",compartor.compare(num1,num2));
}
//使用lambda表达式
public static void findMaxValue(int num1,int num2){
Compartor<Integer> compartorMax = (o1,o2) ->{
log.info(o1);
log.info(o2);
return o1 < o2 ? o2 :o1;
}
log.info("oldFindMaxValue:{}",compartor.compare(num1,num2));
}
5、语法格式五:当Lambda体只有一条语句的时候,return和{}可以省略掉
//使用lambda表达式
public static void findMaxValue(int num1,int num2){
Compartor<Integer> compartorMax = (o1,o2) ->{
log.info(o1);
log.info(o2);
return o1 < o2 ? o2 :o1;
}
log.info("oldFindMaxValue:{}",compartor.compare(num1,num2));
}
public static void findMinValue(int num1,int num2){
Compartor<Integer> compartorMin = (o1,o2) -> (o1 < o2) ? o1 : o2;
log.info("findMinValue:{}",compartorMin.compare(num1,num2));
}
6、语法格式六:类型推断:数据类型可以省略,因为编译器可以推断得出,成为“类型推断”
public static void dateType(){
Consumer<String> consumer = (String s) -> log.info(s);
consumer.accept("Hello World !");
Consumer<String> consumer1 = (s) -> log.ifno(s);
consumer1.accept("Hello don't date type !");
}
函数式接口
什么是函数式接口?
只包含一个抽象方法的接口,称为函数式接口,并且可以使用lambda表达式来创建该接口的对象,可以在任意函数式接口上使用@FunctionalInterface注解,来检测它是否是符合函数式接口。同时javac也会包含一条声明,说明这个接口是否符合函数式接口。
Function(函数型接口)
有参数、有返回值
//1.普通方式
Function<String,String> function1 = new Function<String,String>(){
@Override
public String apply(String s){
return "hello, "+ s;
}
};
//2.lambda方式
Function<String,String> function1 = (str) -> {return "hello, "+ s};
//3.再简化
Function<String,String> function1 = str -> "hello, "+ s;
Predicate (判断型接口)
有参数,返回一个boolean值
//1.普通方式
Predicate<String> predicate1 = new Predicate<String>(){
@Override
public boolean test(String s){
return s.equals("小明");
}
};
//2.lambda方式
Predicate<String> predicate2 = (s) -> {return s.equals("小明")};
//3.再简化
Function<String,String> function1 = s -> s.equals("小明");
Consumer (消费型接口)
有参数,没有返回值
//1.普通方式
Consumer consumer1 = new PreConsumer(){
@Override
public void accept(Object name){
System.out.println((String)name+"正在消费");
}
};
//2.lambda方式
Consumer consumer2 = (name) -> {
System.out.println((String)name+"正在消费");
}
//3.再简化
Consumer consumer3 = name -> System.out.println((String)name+"正在消费");
//4.再简化 右侧相当于是将一个方法作为函数式接口的实现
Consumer consumer4 = System.out::println;
Supplier (供给者接口)
无参数,有返回值
//1.普通方式
Supplier supplier1 = new Supplier(){
@Override
public Object get(){
return new Hambuger("小明");
}
};
//2.lambda表达式方式
Supplie supplier2 = () -> {return new Hambuger("小红");};
//3.简化
Supplie supplier2 = () -> new Hambuger("小绿");
Stream流
1、什么是Stream?
StreamAPI它位于java.util.stream包中,StreamAPI帮助我们更好地对数据进行集合操作,它本质就是对数据的操作进行流水线式处理,也可以理解为一个更加高级的迭代器,主要作用是遍历其中每一个元素。简而言之,StreamAPI提供了一种高效且易于使用的处理数据方式。
2、Stream特点
1、Stream自己不会存储数据。
2、Stream不会改变源对象。相反,它们会返回一个持有结果的新Stream对象
3、Stream操作时延迟执行的。这就意味着它们等到有结果时候才会执行。
和list不同,Stream代表的是任意Java对象的序列,且stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。它可以“存储”有限个或无限个元素。
3、Stream操作步骤
创建 Stream
一个数据源(如: 集合、数组), 获取一个流。
中间操作
一个中间操作链,对数据源的数据进行处理。
终止操作**(终端操作)**
一个终止操作,执行中间操作链,并产生结果 。
4、创建Stream流的方式
第一种:通过集合
对于Collection接口(List 、Set、Queue等)直接调用Stream()方法可以获取Stream
第二种:通过数组
把数组变成Stream使用Arrays.stream()方法
第三种:Stream.of()静态方法直接手动生成一个Stream
Stream stream = Stream.of(“A”, “B”, “C”, “D”);
第四种:****通过Stream.iterate创建无限流
Stream.iterate(1,t->t+2).limit(10).forEach(System.out::println);
Stream.generate(Math::random).limit(10).forEach(System.out::println);
5、Map和FlatMap的区别
map
把数组流中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素个数相同的数组流。
flatMap
FlatMap()操作具有对该流的元素应用一对多变换的效果,然后将所得到的元素展平到新的流中。
flat是扁平的意思。它把数组流中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素相同的数组流。只不过,里面的元素也是一个子数组流。把这些子数组合并成一个数组以后,元素个数大概率会和原数组流的个数不同。
flapMap应用一般是先map 再flatMap, 先将每个元素做处理,然后将两个处理结果flat 平铺 合并,返回一个完整的数据。
示例
// 解释:一个房间有自己的房间号,里面有一堆人,每个人都有面子
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Room {
private int number;
private List<People> peopleList;
@Data
@NoArgsConstructor
@AllArgsConstructor
static class People {
private String name;
}
}
//map处理
public class demo {
public static void main(String[] args) {
final List<Room> roomList = initRoom();
List<List<Room.People>> collect = roomList.stream()
.map(Room::getPeopleList)
.collect(Collectors.toList());
// 1.先new ArrayList<>() 准备存储String字符串
List<String> peopleNameList = new ArrayList<>();
// 2. 这里就得套两层的foreach了
// 因为初始化是List<List<T>>对象
// 第一次foreach中peopleList 是List<Room.People>对象
collect.forEach(peopleList -> {
// 第二次foreach中people 是People对象
peopleList.forEach(people -> {
peopleNameList.add(people.getName());
});
});
}
}
//flatMap处理
public class demo {
public static void main(String[] args) {
final List<Room> roomList = initRoom();
List<String> peopleNameList = roomList.stream()
.map(Room::getPeopleList)
.flatMap(Collection::stream)
.map(Room.People::getName)
.collect(Collectors.toList());
}
}
二、JVM
1.JVM包含哪几部分
类加载器
根据给定的全限定名类名(如:java.lang.Object)来装载class文件到运行时数据区中的方法区
类加载器负责动态加载类,在运行时(而非编译时),当一个类初次被引用的时候,它将被加载、链接、初始化。
对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立在JVM中的唯一性,每一个类加载器,都有一个独立的类名称空间。类加载器就是根据指定全限定名称将class文件加载到JVM内存,然后再转化为class对象。
类加载子系统主要有三个具体的类加载器,包括启动类加载器(BootStrap ClassLoader), 扩展加载器(Extension ClassLoader),应用加载器(Application ClassLoader)
启动类加载器 (BootStrap ClassLoader) –是虚拟机自身的一部分,C++实现,负责从 bootstrap classpath 中加载类(J<JAVA_HOME>\jre\lib\目录中的,或者被 -Xbootclasspath 参数所指定的路径中并且被虚拟机识别的类库),有且只有一个 rt.jar 文件,该加载器具有最高优先级;
扩展加载器(Extension ClassLoader) – 它是Java实现的,独立于虚拟机,主要负责加载<JAVA_HOME>\jre\lib\ext\目录中或被java.ext.dirs系统变量所指定的路径的类库;
应用加载器(Application ClassLoader)– 它是Java实现的,独立于虚拟机,负责从用户定义的 classpath 中加载类,用户可以通过指定环境变量的方式定义该目录,如: java -classpath。一般情况下,如果没有自定义类加载器默认就是用这个加载器。
执行引擎
执行引擎也叫解释器,负责解释命令,交由操作系统执行;
本地接口
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序,Java诞生的时候是C/C++横行的时候,要想立足,必须有一个聪明的、睿智的调用C/C++程序,于是就在内存中专门开辟了一块区域处理标记为native的代码,它的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时
加载native libraies。目前该方法使用的是越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机,或者Java系统管理生产设备,在企业级应用中已经比较少见,因为现在的异构领域间的通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍
程序计数器(Program Counter Registers)
用于记录当前线程的正在执行的字节码指令位置。由于虚拟机的多线程是切换线程并分配cpu执行时间的方式实现的,不同线程的执行位置都需要记录下来,因此程序计数器是线程私有的。这个区域是唯一一个不会抛出任何异常的区域。
运行时数据区
JVM的内存,我们所有所写的程序都被加载到这里,之后才开始运行。
Java虚拟机在运行时会将其内存划分为不同的区域,这些区域都有特定的用途。但顾名思义,总的用途都是存储数据,只是存储的东西不同罢了.
简单的过程可以理解为:我们的源代码文件(.java文件)经过编译生成的字节码文件(.class文件),由class loader(类加载器)加载后交给执行引擎执行。在加载后和执行引擎执行的过程中产生的数据会存储在一块内存区域,这块内存区域就是运行时数据区。
虚拟机栈(Java Threads)
虚拟机栈是线程私有的。虚拟机栈是java方法执行的内存结构,虚拟机会在每个java方法执行时创建一个“栈桢”,用于存储局部变量表,操作数栈,动态链接,方法出口等信息。当方法执行完毕时,该栈桢会从虚拟机栈中出栈。其中局部变量表包含基本数据类型和对象引用;在java虚拟机规范中,对这个区域规定了两种异常状态:如果线程请求的栈的深度大于虚拟机允许的深度,将抛出StackOverFlowError异常(对于单个线程来说的栈溢出):
本地方法栈(Native Internal Threads)
本地方法栈是线程私有的。本地方法栈为虚拟机使用的Native方法(本地方法)提供服务,这个Native方法指得就是Java程序调用了非Java代码,算是一种引入其它语言程序的接口。和虚拟机栈类似,本地方法栈也会抛出StackOverFlowException和OutOfMemoryException异常。
方法区(Method Area)
方法区是线程共享的内存区域,用于存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译的代码等数据。通常被开发人员成为“永久代”。这个区域的内存回收的目标就是针对常量池的回收和对类型的卸载,也是较为难处理的部分。方法区溢出时会抛出OutOfMemoryException异常。
堆(Heap)
堆是java虚拟机中内存中最大的一块,被所有线程共享的一块内存区域,在虚拟机创建时创建。作用就是存放对象实例,所有的对象的实例都需要在这里分配内存。几乎所有的对象实例和对象数组都需要在堆上分配。是java虚拟机内存回收的管理的重要区域,因此也被称为**“GC”堆**,可以被分为新生代和老年代。新生代又由Eden空间、From Survivor空间、To Survivor空间组成。如果堆中没有内存完成实例分配,并且堆也无法扩展时,则抛出OutOfMemoryException异常
2.双亲委派机制
原理
当一个类加载器收到类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载类无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载。
使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将会变得一片混乱。
如何打破
1.自定义类加载,重写loadclass方法因为双亲委派的机制都是通过这个方法实现的,这个方法可以指定类通过什么类加载器来进行加载,所有如果改写他的加载规则,相当于打破双亲委派机制
2.使用线程上下文类
双亲委派模型的第二次“破坏”是由这个模型自身的缺陷所导致的,双亲委派很好的解决了各个类加载器的基础类统一问题,基础类之所以“基础”,是因为他们总被用户代码所调用,但是如果基础类又要重新调用用户代码,那咋办?
比如说JNDI是java的标准服务,它的代码是由启动类加载器进行加载的,但是jndi的作用就是进行资源的集中管理和查找,它需要调用由开发人员开发在classpath下的类代码,但是启动类加载器不会进行加载。
所以引入线程上下类加载器,通过java.lang.Thread类的setContextClassLoader()方法进行设置。如果创建线程是还未设置,它会从父线程继承一个,如果在应用程序全局范围内没有设置,那么这个线程上下类加载器就是应用程序类加载器。
那么这样JNDI服务使用这个线程上下类加载器去加载所需的spi代码,也就是父类加载器请求子类加载器去完成类加载的动作,这个实际是打通了双亲委派的逆向层次结构。
3.创建对象内存分析
public class Pet{
public String name; //使用public在main()方法中才能调用name的age属性
public int age;
//无参构造
public void shout(){
System.out.println("叫了一声");
}
}
public class Application{
public static void main(String[] args){
Pet dog = new Pet();
dog.name. "旺财";
dog.age = 3;
dog.shout();
Pet cat = new Pet();
}
}
创建实体类Pet并创建内部方法shout()
创建Application类main方法实例化Pet类并调用内部方法shout()
内存概念**:**
主要分为堆和栈,堆中又包含一个方法区
分析
- 首先在方法区加载Application类中的main()方法,执行main()方法(压入栈中)

- new Pet(dog),此时将Pet类加载到方法区

- 生成一个具体对象:dog,引用变量名存放在栈中,真正的对象存放在堆中,默认name = null,默认age = 0,方法shout()是调用的方法区Pet类中的shout()方法

- 此时在main()方法给dog中的name、age进行赋值

5. 此时进行new Pet(cat),操作与new Pet(dog)相同

4.JAVA对象实例化过程
对象实例化总述
当一个类被创建,并且这个类是首次被加载时(例如:A a=new A();),方法区会开辟出一块内存存放类的class文件并且将全部成员放入。之后会在堆中开辟一块内存,存储这个类并且将这个类的非静态的成员变量拷贝过来(静态成员不拷贝,所有实例共享),并持有对应的方法区的方法的句柄,这块内存有一个唯一内存地址,栈中的a对象指向的就是这个内存地址。
之后你为类的成员变量赋值时,堆中的变量的值会从默认值更改为设定值(方法区中变量无值)。
如果此时在实例化一个新的类(A a2=new A()😉,此时方法区中已经有一个A类的class,所以不会在创建一个A.class,但是此时会在堆中开辟一块新的空间并且将这个类的非静态成员拷贝并持有对应的方法区类的方法的句柄,这块内存空间标注一个新的内存地址。
此时,栈中a指向的是堆中第一个类的内存地址,a2指向的是堆中的第二个类的内存地址,而堆中这两块内存地址指向的是同一个方法区的class文件。所以栈中对象要么存的是一个内存地址(引用)要么就是一个具体的值,存放的是一个具体值的话他就是一个基本变量。
静态变量、静态代码块、普通变量、普通代码块、构造器的执行顺序如下图:

具有父类的子类的实例化顺序如下:

5.GC
1、什么是垃圾回收
垃圾回收(Garbage Collection),释放垃圾占用的空间,防止内存泄露,对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收。
2、Java8 后堆逻辑上的变化
- Jdk1.6及之前: 有永久代,常量池1.6在方法区
- Jdk1.7: 有永久代,但已经逐步“去永久代”,常量池1.7在堆
- Jdk1.8****及之后: 无永久代,常量池1.8在堆中。元空间**(对方法区的实现)**
- 永久代与元空间的最大区别之处:
- 永久代使用的是jvm的堆内存,但是java8以后的元空间并不在虚拟机中而是使用本机物理内存。因此,默认情况下,元空间的大小仅受本地内存限制。
3、新生区、养老区、永久代(元空间)
新生区 (新生代)
新new出的对象,会存入伊甸区,80%空间被占用后,产生轻gc:伊甸园区中销毁没有被其他对象引用的对象。将伊甸园中的剩余对象移动到幸存 From区。
GC垃圾回收过程:复制 -> 清空 -> 互换
1、幸存者从 eden、From 复制到 To区,年龄+1
2、清空 eden、From 区 (垃圾回收)
3、To 和 From 互换 (To区永远是空的,From区存储对象)
大对象特殊情况:幸存区存不下,直接进入养老区
养老区 (老年代)
经历多次GC仍然存在的对象(默认是15次),老年代的对象比较稳定,不会频繁的GC
若养老区也满了,那么这个时候将产生重GC(FullGC),进行养老区的内存清理。若养老区执行了Full GC之后发现依然无法进行对象的保存,就会产生OOM异常“OutOfMemoryError”。
如果出现 java.lang.OutOfMemoryError: Java heap space 异常,说明Java虚拟机的堆内存不够(堆空间出现的内存溢出)。
原因有二:
(1) Java虚拟机的堆内存设置不够,通过参数-Xms(初始)、-Xmx(最大) 来调整。
(2) 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集 (存在被引用)。
什么对象一定进入养老区:池对象 (连接池、线程池)
永久区 (永久代) (非堆)
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的 Class、Interface 的元数据,运行时所需要的环境。关闭 JVM 才会释放此区域所占用的内存。 实际而言,方法区(Method Area)和堆一样,是各个线程共享的内存区域,它用于存储虚拟机加载的:类信息+普通常量+静态常量+编译器编译后的代码等等,虽然JVM规范将方法区描述为堆的一个逻辑部分,但它却还有一个别名叫做 Non-Heap(非堆),目的就是要和堆分开(物理上)。 Jdk1.6及之前: 有永久代,常量池1.6在方法区 Jdk1.7: 有永久代,但已经逐步“去永久代”,常量池1.7在堆 Jdk1.8及之后: 无永久代,常量池1.8在堆中。元空间(对方法区的实现) 永久代与元空间的最大区别之处:永久代使用的是jvm的堆内存,但是java8以后的元空间是使用本机物理内存,并不在虚拟机中。因此,默认情况下,元空间的大小仅受本地内存限制。
4、垃圾标记法
引用计数算法**(Reference-Counting) (**不再使用)
通过在对象头部分配一个空间,来保存该对象被引用的次数。对象被其他对象引用,则它的计数加1,删除该对象的引用,计数减1,当该对象计数为0时,会被回收。
缺点:
- 引用和去引用伴随着加减算法,影响性能,
- 很难处理循环引用,相互引用的两个对象则无法释放。
可达性分析

GC Roots,指对象的起始节点,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的“路程”称为引用链,如果某个对象到GC Roots间没有任何引用链相连接,或者换句话说:对象到GC Roots不可达时,说明此对象是不可在被引用了。
GC Roots
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如当前正在运行的方法所使用到的参数、局部变量、临时变量等
- 类静态属性引用的对象,譬如Java类的引用类型静态变量
- 常量引用的对象,譬如字符串常量池(String Table)里的引用
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointException、OutOfMemoryError)等,还有系统类加载器
- 所有被同步锁(synchronized关键字)持有的对象
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等
二次标记
通过可达性算法,可以解决引用计数算法无法解决的循环依赖问题,只要不能被GC Root搜索到,就会被回收。 真正标记以为对象为可回收状态至少要标记两次。
第一次标记:不在 GC Roots 链中,标记为可回收对象。
第二次标记:判断当前对象是否实现了finalize() 方法,如果没有或虚拟机已调用过finalize()方法,则直接判定这个对象可以回收。如果这个对象被判定有必要执行finalize()方法,就会先放置到一个叫做F-Queue的队列中。并由虚拟机自动建立一个低优先级的Finalizer线程去执行它(这里的执行是指虚拟机会触发这个方法,但不会承诺会等待它运行结束)。随后就会对F-Queue队列进行第二次小规模标记,如果对象在finalize()中成功拯救了自己(重新与引用链的任何一个对象建立关联),那么会在第二次标记时将它移除出“即将回收”的集合,否则将在这次被标记的对象就会真正被回收了。
注:不建议使用finalize()方法。此方法是java刚诞生时为了使C/C++程序员更容易接受它所做的一个妥协。它的运行代价高昂,不确定性大,无法保证各个对象的调用顺序。
5、垃圾清理法
标记清除算法(Mark - Sweep)

首先标记(使用可达性分析算法标记)出所有需要回收的对象,然在标记完成后统一回收所有被标记的对象。
缺点
- 效率问题 (扫描两次),标记和清除两个过程的效率都不是很高。
- 空间问题,标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中的需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作,
使用地点
养老区 FullGC
复制算法

它将内存按容量平分成两块,每次使用其中的一块。当一块用完了,将其存活的对象复制到另一块上,再把这一块内存清理掉。保证了内存连续可用,不会产生内存碎片,逻辑清晰,运行高效。
优点
实现简单、效率高,不产生内存碎片
缺点
浪费一半内存空间,如果对象存活率高,复制这一工作浪费时间
使用地点
新生代 Minor GC
将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性的复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例为8:1.
内存分配担保
如果另外一块Survivor空间没有足够空间存放上一次新声代手机下来的存活对象,这些对象将直接通过分配担保机制进入老年代。
标记整理算法

复制收集算法在对象存活率较高时就要进行比较多的复制操作,效率将会变低。更关键的是如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代中一般不能直接使用这种算法。
标记整理算法(Mark - Compact)标记过程与
标记-清除算法一样,但后续不是直接回收对象,而是让存活的对象向一端移动,再清理端边界以外的内存。
优点
没有内存碎片,节省内存
缺点:
效率低
**使用地点
养老区 FullGC 老年代一般是由标记清除或者是标记清除与标记整理的混合实现
分代收集算法
分代收集算法(Generational Collection),融合上面 3 种思想。 根据对象存活周期的不同划分为几块,一般分为新生代和老年代,根据年代的特点采用适当的收集算法。
新生代:每次回收发现有大量对象死去,少量存活,则使用复制算法,付出少量存活对象复制的成本完成回收。
老年代:存活率高,没有额外空间分配,则使用标记——清除或标记——整理算法来回收。
6、gc算法实现
6.1 OopMap
GC Roots的节点主要在全局性的引用(例如常量或静态变量)与执行上下文(例如栈帧中的本地变量表)中,如果要逐个检查这里面的引用,那么必然会消耗很多时间。另外,可达性分析对执行时间的敏感还体现在GC停顿上,因为这项分析工作必须在一个能确保一致性的快照中进行——这里的
一致性的意思是指在整个分析期间整个执行系统看起来就像被冻结在某个时间节点上,不可以出现分析过程中对象引用关系还在不断变化的情况,该点不满足的话分析结果准确性就无法得到保证。 所以,当执行系统 停顿下来时,并不需要一个不漏的检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法直接得知哪些地方存放着对象引用。在HotSpot的实现中,是使用一组成为OopMap的数据结构来达到这个目的的。在类加载完成的时候,HotSpot就把对象内什么偏移量上是什么类型的数据计算出来,在JIT编译过程中,也会在**特定的位置(安全点)**记录下栈和寄存器中哪些位置是引用。这样GC在扫描时就不要去逐个检查引用就可以直接得知这些信息了。
总结oopMap的作用
- 可以避免全栈扫描,加快枚举根节点的速度
- 可以帮助HotSpot实现准确式GC
6.2 安全点
程序执行时并非在所有地方都能停下来开始GC,只有在达到安全点时才能暂停。
安全点的选定基本上是以程序“是否具有让程序长时间执行的特征”为标准进行选定的——因为每条指令执行的时间都非常短暂,程序不太可能因为指令流长度太长这个原因而过长时间运行。“长时间执行”的最明显特征就是指令序列复用,例如方法调用、循环跳转、异常跳转等。
如何在GC发生时让所有线程都“跑”到最近的安全点上再停顿下来?
抢先式中断
不需要线程的执行代码主动去配合,在GC发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它“跑“到安全点上。(现在大部分不再使用此方式)
主动式中断
当GC需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志,哥哥线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起。轮训标志的地方和安全点时重合的,另外再加上创建对象需要分配内存的地方。
6.3 安全区域
安全点机制保证了程序执行时,在不太长的时间内就会遇到可进入GC的安全点。但是程序“不执行”的时候,也就是程序没有分配CPU时间,典型的例子就是线程处于Slepp状态或者Blocked状态,这时候线程无法响应JVM的中断请求,“走”到安全的地方去挂起,JVM爷明显不太可能等待线程重新被分配CPU时间。对于这种问题,就引出了安全区域概念。
安全区域是指在一段代码片段中,引用关系不会发生变化。在这个区域中的恶人一地方开始GC都是安全的。在线程执行到安全区域中的代码时,首先表示自己已经进入了安全区域,当在这段时间里JVM发起GC时,就不用管标识自己为安全区域状态的线程了。在线程要离开安全区域时,他要检查系统是否已经完成了跟节点枚举(或者是整个GC过程),如果完成了,那线程就继续执行,否则该线程就必须等待知道收到可以安全离开安全区的信号为止。
7、垃圾收集器

7.1 Serial(连续)收集器
新生代收集器,使用复制算法。
单线程收集器,只会使用一个CPU或一个收集线程去完成垃圾收集工作,在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
优点
简单而高效(与其他收集器相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的线程收集效率。
缺点
只支持单核但线程执行。
7.2 ParNew(新品)收集器
新生代收集器,使用复制算法。
ParNew收集器就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集之外,其余都和ParNew完全一样。
ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器,并且是唯一能与CMS收集器配合工作。
7.3 Parallel Scavenge(并行清理)收集器
新生代收集器,使用复制算法。
Parallel Scavenge收集器是一个并行的多线程收集器,它的目标是达到一个可控制的吞吐量,与其他收集器追求的尽可能地缩短垃圾收集时用户线程的停顿时间不同。所谓的吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验,而高吞吐量则可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
-XX:MaxGCPauseMillis:控制最大垃圾收集停顿时间(大于0)。收集器将尽可能保证内存回收花费时间不超过该设定值。GC停顿时间缩短是以牺牲吞吐量和新生代空间来换取的。
-XX:GCTimeRatio:设置吞吐量大小(大于0且小于100)。垃圾收集时间占总时间的比率,相当于吞吐量的倒数。
-XX:+UseAdaptiveSizePolicy:开关参数,开启之后就不需要手工指定新生代的大小、Eden与Survivor区的比例、晋升老年代对象大小等细节参数了,虚拟机会根据当前系统等运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节成为GC自适应的调节策略。
7.4 Serial Old收集器
Serial Old是Serial收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”算法。这个收集器的主要意义也是在于给Client模式下的虚拟机使用。如果在Server模式下,那么它主要还有两大用途:一种用途是在JDK 1.5以及之前的版本中与Parallel Scavenge收集器搭配使用,另一种用途就是作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用。
7.5 Parallel Old收集器
Parallel Old是Parallel Scanvenge收集器的老年代版本,使用多线程和”标记-整理“算法。一般和Scanvenge收集器联合使用来追求吞吐量优先。
7.6 CMS收集器
老年代收集器,使用标记—清除算法
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的Java应用集中在互联网站或者B/S系统的服务端上,重视服务的响应速度,希望系统停顿时间最短。
运行过程
-
初始标记
标记GC Roots直接相关联的第一个对象,不用Tracing,速度很快 STW (jdk7默认单线程,jdk8默认多线程)
-
并发标记
与用户线程同时运行,根据所标记的GC Roots进行GC Roots Tracing(以GCRoots所引用的对象为起始点向下搜索)。
-
重新标记
修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录。会触发stop the world。
-
并发清除
与用户线程同时运行,清除不可达对象回收空间,同时有新垃圾产生,留着下次清理称为浮动垃圾。
缺点
-
对CPU非常敏感,在并发阶段虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量下降。CMS默认启动的回收线程数是(CPU数量+3)/4。当CPU数不足4个时,CMS对用户线程的影响就变的很大。
-
无法处理浮动垃圾(CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,之后留待下一次GC时再清理掉。这部分垃圾就称为**
浮动垃圾**)。 -
可能会出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMD收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。要是CMS运行期间预留的内存无法满足程序需要,就会出现一次“Currnet Mode Failure”失败,这时虚拟机将启动后备预案:临时启用Serial Old收集器来重新进行老年代的垃圾回收,这样停顿时间就很长了。
-
空间碎片过多,当大对象进行分配时会再次触发Full GC。CMS收集器是基于标记-清除算法实现的收集器,收集时会产生大量的空间碎片。为了解决这个问题,CMS收集器提供了两个配置参数:
-
-XX:+UseCMSCompactAtFullCollection:开关参数(默认开启),用于在CMD收集器顶不住要进行Full GC时开启内存碎片合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。
-
**-XX:CMSFullGCsBeforeCompation:**用于设置执行多少次不压缩的Full GC后,跟着来一次带压缩的(默认值为0,标识每次进入Full GC时都进行碎片整理)。
-
7.7 G1收集器
不再进行分代收集,整体使用标记-整理算法,两个Region之间采用复制算法。
G1收集器不像其他收集器一样收集的范围都是针对整个新生代或老年代,而是整个内存空间。在使用G1收集器时,他将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代与老年代的概念,但已经不是物理隔离的了,他们都是一部分Region的集合。
在进行垃圾收集时,G1跟踪各个Region里面的垃圾堆积的价值大小(回收所获得空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region,也就是不再有
Minor GC/Yong GC和Major GC/Full GC的概念,而是采用一种Mixed GC的方式,即混合回收的GC方式。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了G1收集器在有限的时间内可以获取尽可能高的收集效率。 Region中存在特殊的Humongous区域,用来存储大对象。G1认为只要大小超过了Region容量一半的对象即可判定为大对象,G1的大多数行为都把Humongous Region作为老年代的一部分来看待。
Region类型
G1将所有Region分为四种类型:Eden、Survivor、Old、Humongous。
默认新生代的Region内存占堆空间的5%,如果堆空间大小为4096MB,那么新生代占用200MB左右的内存,按照每个Region为2MB,对应就是100个Region。也可以通过参数**-XX:G1NewSizePercent**设置新生代初始占比。
在系统运行过程中,JVM会动态地给年轻代增加更多的Region,但新生代的占比最多不会超过60%,可以通过参数 -XX:G1MaxNewSizePercent设置。Region的区域类型是动态变化的,可能之前是年轻代,经过了垃圾回收之后就变成了老年代。
G1中的新生代依然与经典垃圾收集器中一样,分为Eden区和Survivor区,默认比例也是8:1:1。G1收集器对于对象从新生代转移到老年代与CMS等经典垃圾收集器是一样的,但对于大对象的处理有所不同。G1为大对象的内存分配专门设计了一个Humongous类型的Region,而不再是让对象直接进入老年代的Region。
在G1中,大对象的判断是超过一个Region大小的50%,按照每个Region大小为2MB来计算,只要对象超过了1MB,就会被放入到Humongous的Region中,如果一个对象太大,一个Region放不下,可能会存在跨多个Region来存放。
在进行Full GC的时候除了要收集新生代和老年代的Region外,还会将Humongous的Region一并进行回收。
记忆集(Remembered Set)
由于G1垃圾收集器将内存分成了不同的region,因此在垃圾标记和回收时,不可避免的会有跨Region引用的情况产生:一个region中存储的对象可能被其他任意region(这些region可能Old区或者Eden区)中的对象所引用。这样一来,在进行YGC的时候,在判断Eden区中的一个对象是否存活时,需要去扫描所有的region(包括Old区,Eden区等),导致了在回收年轻代的时候,还需要扫描老年代,同时扫描表示所有Eden区和Old区的region,相当于做了一个全堆扫描,这会大大降低YGC的效率。(在CMS等分代回收的垃圾回收器中,也存在跨代引用的问题,即如果老年代对象引用了新生代的对象,那么回收新生代时需要扫描从老年代到新生代的所有引用)
为了解决上述问题,通常采用记忆集(Remembered Set,RSet)来避免全堆扫描。记忆集在不同的垃圾收集器中的实现方式不同,G1采用卡表的形式来实现记忆集,具体方式如下:
- G1将Java堆划分为相等大小的一个个区域,这个小的区域大小是512 Byte,称为Card。并维护了一个字节数组Card Table,Card Table的数组下标映射着每一个Card,一个Card的内存中通常包含不止一个对象,只要Card内有一个(或更多)对象的字段存在着跨代指针,那就将对应卡表的数组元素的值标识为1,称为这个元素变脏(Dirty),没有则标识为0。
- 每个Region初始化时,会初始化一个remembered set
- RSet里面记录了引用——其他Region中指向本Region中所有对象的所有引用
- RSet其实是一个Hash Table,Key是其他的Region的起始地址,Value是一个集合,里面的元素是Card Table 数组中的index,既Card对应的Index,映射到对象的Card地址。
- 当进行垃圾收集时,在GC根节点的枚举范围加入Remembered Set;就可以保证不进行全局扫描,也不会有遗漏
运行过程
-
初始标记
标记一下GC Roots能直接关联到的对象,并修改TAMS(Next Top Mark Start)的值,让下一阶段用户线程并发运行时,能在正确可用的Region中创建对象。(需要Stop The World,但很短)
-
并发标记
从GC Root开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时很长,但可与用户线程并发执行。
-
最终标记
为了修正在并发标记期间因用户线程继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面。最终标记阶段需要把Remembered Set Logs的数据合并到记忆集(Remembered Set)中,这阶段需要停顿线程,但是可并发执行。
-
筛选回收
首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC 停顿时间来确制定回收计划。
这里是先把需要回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧的Region的全部空间。需要暂停用户线程,由多条收集器线程并行完成
配置参数
**-XX:G1HeapRegionSize:**设置每个Region的大小,取值范围:1MB~32MB,且应为2的N次幂。
**-XX:MaxGCPauseMillis:**用户期望Stop The World时间
**-XX:ConcGCThreads:**指定并发工作的GC线程数
6.jdk、jre和jvm
- jdk:java开发工具包。包括java运行环境(jre),java工具,java基础的类库
- jre:java运行环境。包括jvm标准实现及java核心类库
- jvm:java虚拟机,一种抽象化的计算机
三、mysql
数据库三大范式
- 第一范式:强调的是列的原子性,即列不能够再分成其他几列。
- 第二范式:在第一范式基础上,必须有一个主键其他字段必须完全依赖于主键,而不能只依赖于主键的一部分。
- 第三范式:在前两个范式基础上,非主键列必须直接依赖于主键,不能存在传递依赖。
防止sql注入
代码层防止sql注入攻击的最佳方案就是sql预编译(prepareedstatement类)
- 使用正则表达式过滤传入的参数 · 字符串过滤 · 前端调用函数检查是否包函非法字符
- 规定数据长度,能在一定程度上防止sql注入
- 严格限制数据库权限,能最大程度减少sql注入的危害
字段类型
1、整数类型
整数类型又称数值型数据,数值型数据类型主要用来存储整数数字。
MySQL 提供了多种数值型数据类型,不同的数据类型提供不同的取值范围,可以存储的值范围越大,所需的存储空间也会越大。
MySQL 主要提供的整数类型有 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,其属性字段可以添加 AUTO_INCREMENT 自增约束条件。下表中列出了 MySQL 中的数值类型:
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| TINYINT | 很小的整数 | 1个字节 |
| SMALLINT | 小的整数 | 2个宇节 |
| MEDIUMINT | 中等大小的整数 | 3个字节 |
| INT (INTEGHR) | 普通大小的整数 | 4个字节 |
| BIGINT | 大整数 | 8个字节 |
2、浮点数和定点数类型
- MySQL 中使用浮点数和定点数来表示小数。
- 浮点类型有两种,分别是单精度浮点数(FLOAT)和双精度浮点数(DOUBLE);定点类型只有一种,就是 DECIMAL。
- 浮点类型和定点类型都可以用(M, D)来表示,其中M称为精度,表示总共的位数;D称为标度,表示小数的位数。
- 浮点数类型的取值范围为 M(1~255)和 D(1~30,且不能大于 M-2),分别表示显示宽度和小数位数。M 和 D 在 FLOAT 和DOUBLE 中是可选的,FLOAT 和 DOUBLE 类型将被保存为硬件所支持的最大精度。DECIMAL 的默认 D 值为 0、M 值为 10。
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| FLOAT | 单精度浮点数 | 4 个字节 |
| DOUBLE | 双精度浮点数 | 8 个字节 |
| DECIMAL (M, D),DEC | 压缩的“严格”定点数 | M+2 个字节 |
3、日期/时间类型
MySQL 中有多处表示日期的数据类型:YEAR、TIME、DATE、DTAETIME、TIMESTAMP。当只记录年信息的时候,可以只使用 YEAR 类型。
每一个类型都有合法的取值范围,当指定确定不合法的值时,系统将“零”值插入数据库中。
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| YEAR | YYYY | 1901 ~ 2155 | 1 个字节 |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 个字节 |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC ~ 2040-01-19 03:14:07 UTC | 4 个字节 |
4、字符串类型
字符串类型用来存储字符串数据,还可以存储图片和声音的二进制数据。字符串可以区分或者不区分大小写的串比较,还可以进行正则表达式的匹配查找。
MySQL 中的字符串类型有 CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、ENUM、SET 等。
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串 | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
5、二进制类型
- MySQL 支持两类字符型数据:文本字符串和二进制字符串。
- 二进制字符串类型有时候也直接被称为“二进制类型”。
- MySQL 中的二进制字符串有 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| BIT(M) | 位字段类型 | 大约 (M+7)/8 字节 |
| BINARY(M) | 固定长度二进制字符串 | M 字节 |
| VARBINARY (M) | 可变长度二进制字符串 | M+1 字节 |
| TINYBLOB (M) | 非常小的BLOB | L+1 字节,在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字节,在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字节,在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字节,在此,L<2^32 |
索引
什么是索引
索引其实是一种数据结构,能够帮助我们快速的检索数据库中的数据。
优点
- 提高数据检索的效率,降低数据库IO成本。
- 通过索引对数据进行排序,降低数据的排序成本,降低CPU的消耗。
缺点
- 建立索引需要占用物理空间
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长
主键和唯一索引的区别
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
- 唯一性索引列允许空值,而主键列不允许为空值。
- 主键列在创建时,已经默认为空值 + 唯一索引了。
- 主键可以被其他表引用为外键,而唯一索引不能。
- 一个表最多只能创建一个主键,但可以创建多个唯一索引。
- 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
什么情况下需要建索引?
- 主键自动创建唯一索引
- 较频繁的作为查询条件的字段
- 查询中排序的字段,查询中统计或者分组的字段
什么情况下不建索引?
- 表记录太少的字段
- 经常增删改的字段
- 唯一性太差的字段,不适合单独创建索引。比如性别,民族,政治面貌
索引主要有哪几种分类?
普通索引
是最基本的索引,它没有任何限制
唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
组合索引
一个索引包含多个列,实际开发中推荐使用组合索引。
全文索引
全文搜索的索引。FULLTEXT 用于搜索很长一篇文章的时候,效果最好。只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。
主键索引和唯一索引的区别
- 主键必唯一,但是唯一索引不一定是主键;
- 一张表上只能有一个主键,但是可以有一个或多个唯一索引。
索引的数据结构有哪些?
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和Hash索引。InnoDB引擎的索引类型有B+树索引和Hash索引,默认的索引类型为B+树索引。
哈希索引
哈希索引是基于哈希表实现的,当我们要给某张表某列增加索引时,存储引擎会对这列进行哈希计算得到哈希码,将哈希码的值作为哈希表的key值,将指向数据行的指针作为哈希表的value值。这样查找一个数据的时间复杂度就是O(1),一般多用于精确查找。所以在= in <=>(安全等于的时候)塔的效率是非常,但我们开发一般会选择Btree,因为Hash会存在如下一些缺点。
- Hash索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。
- Hash 索引无法被用来避免数据的排序操作。
- Hash索引不能利用部分索引键查询。
- Hash索引在任何时候都不能避免表扫描。
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
B+树索引介绍
相对于cpu和内存操作,磁盘IO开销很大,非常容易成为系统的性能瓶颈。为什么索引能提升数据库查询效率呢?根本原因就在于索引减少了查询过程中的IO次数。
B+Tree相对于B-Tree有几点不同
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
为什么B+树比B树更适合实现数据库索引?
- B+ 树叶子结点之间用链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。
- B+ 树更相比 B 树减少了 I/O 读写的次数。由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
- B+树的查询效率更加稳定,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
索引失效场景有哪些?
- 组合索引未使用最左前缀,例如组合索引(age,name),where name='张三’不会使用索引;
- or会使索引失效。如果查询字段相同,也可以使用索引。例如where age=20 or age=30(索引生效),where age=20 or name=‘张三’(这里就算你age和name都单独建索引,还是一样失效);
- 如果列类型是字符串,不使用引号。例如where name=张三(索引失效),改成where name=‘张三’(索引有效);
- like未使用最左前缀,where A like ‘%China’; 在索引列上做任何操作计算、函数,会导致索引失效而转向全表扫描;
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引;
索引的设计原则
- 索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
- 尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,查询速度更快。
- 索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。 利用最左前缀原则。
ACID
特性
- 原子性:要么都发生,要么都不发生。
- 一致性:事务前后数据的完整性必须保持一致。
- 隔离性:一个事务不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
- 持久性:一个事务一旦被提交,数据不可再恢复
ACID各自的实现原理
原子性的实现依赖undolog回滚日志。每一条数据变更(insert/update/delete)操作都伴随一条undo log的生成,并且回滚日志必须先于数据持久化到磁盘上。所谓的回滚就是根据回滚日志做逆向操作,比如delete的逆向操作为insert,insert的逆向操作为delete,update的逆向为update等。
数据库的一致性依赖于其他三种特性:原子性,隔离性,持久性。所谓一致性,指的是数据处于一种有意义的状态,例如从帐户A转一笔钱到帐户B上,A账户上减少的钱数等于B账户上增加的钱数才是一种有意义的状态。
**隔离性**通过锁机制来实现。使用锁机制,保证每个事务能够看到的数据总是一致的,就好像其他事务不存在一样,多个事务并发执行后的状态和它们串行执行后的状态是等价的。原则上一般是两种类型的锁:乐观锁和悲观锁。
**持久性**通过redo log来保证。Mysql是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。但是如果事务提交前直接把数据写入磁盘太浪费IO资源,因此使用redo log来解决持久性和读写IO消耗严重之间的平衡问题,当做数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作。当事务提交的时候,会将redo log日志进行刷盘(redo log一部分在内存一部分在磁盘)。当数据库宕机重启会将redolog中的内容恢复到数据库再根据undo log和binlog内容决定回滚数据还是提交数据。
MySQL日志
undo log
在事务开始之前记录当前数据,主要用于事务失败时的回滚,以及MVCC中用于版本控制
redo log
WAL(write ahead log),事务开始之后就生成redo log,可以用于事务提交失败时,保证事务的持久性。事务提交失败,导致缓冲池中有脏页没有刷到磁盘,从而导致数据不一致,但是因为有了redo log,可以将数据恢复。由属性innodb_flush_log_at_trx_commit来控制。主要作用是保证mysql innodb引擎的缓冲池中的数据不丢失(mysql崩溃恢复),mysql优化点:将mysql缓冲池设置为可用内存的60%~80%,以提高mysq的性能。redo log在事务提交之后才写入磁盘,回滚不会写入。
Binlog
肯定也是事务开始后就生成binlog,事务commit的时候写到磁盘,由属性sync_binlog来控制,这个值建议设置为1,每次提交都fsync,将log刷到磁盘。怎样保证磁盘中的数据库数据不丢失(数据恢复,比如删库跑路)???首先要有数据备份,然后要有binlog(binlog中不要再执行删库的sql语句)。binlog在事务提交之后才写入磁盘,回滚不会写入。
是中继日志,在主从同步的时候使用到,它是一个中介临时的日志文件,用于存储从master节点同步过来的binlog日志内容。
事务并发产生的三种问题
脏读
一个事务读取到了另外一个事务没有提交的数据
幻读
同一事务中,用同样的操作读取两次,得到的记录数不相同(数据条数)
不可重复读
在同一事务中,两次读取同一数据,得到内容不同(数据内容)
mysql的事务隔离级别
Read Uncommitted(读未提交)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
这里查询不加锁,但是增删改加了行级共享锁,直到事物被提交或回滚才会解锁
Read Committed(读提交)
这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的 commit,所以同一 select 可能返回不同结果。
为了防止脏读,每次写入前,数据库都会记住旧值。 当前事务尚未提交时,其他事务的读取都会拿到旧值。当前事务提交后,其他事务才能读取到新值。
为了防止脏写,数据库一般用读锁。当事务想要修改特定的行时,必须先获得该行的锁。一次只有一个事务可持有任何给定行的锁。如果另一个事务要写入同一行,就必须等到第一个事务提交或回滚后。
Repeatable Read(可重复读)
这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。
事务读取时加行级共享锁,直到事务结束才会释放。
Serializable(可串行化)
通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
事务读取时加表级排它锁,直到事务结束时,才释放。这里因为有一个串行化的一种状态,未触发前只可以进行查询操作,一旦进行增删改串行化就会被触发,增删改查都会被事务阻塞!

MVCC
MVCC,Multi-Version Concurrency Control,即多版本并发控制,MVCC在MySQL的InnoDB中的实现主要是为了提高数据库并发性能,用来实现一致性的非锁定读,非锁定读是指不需要等待访问的行上X锁的释放,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
当前读
比如:“select * from table where … lock in share mode(共享锁)”、“ select * from table where … for update”、“update”、“insert”、“delete”(排他锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
快照读
比如:“select * from table where … ”,这种不加锁的select操作就是快照读,即不加锁的非阻塞读。快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读。
不同事务隔离级别的应用
- 对于innodb而言,在read committed 和 repeatable read两种隔离级别下使用MVCC,此时MVCC对于快照数据的定义不同:
- 在read committed 隔离级别下,对于快照数据总是读取被锁定行的最新一份快照数据;
- 在repeatable read 隔离级别下,对于快照数据总是读取事务开始时的行数据版本。
- 这里有一点要注意,之所以使用快照读能实现MVCC的非锁定读,即不需要加锁,是因为没有事务需要对历史的数据进行修改操作。
数据库锁
按粒度分:
表锁
表锁表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。表级锁定的主要是MyiSAM引擎
行锁
与表锁正相反,行锁最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力从而提高系统的整体性能。虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎
页锁
相对偏中性的页级锁,页锁是MySQL中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
全局锁
是对整个数据库实例加锁。使用场景一般在全库逻辑备份时
在给定的资源上,锁定的数据量越少,则系统的并发程度越高,如果系统花费大量的时间来管理锁,而不是存取数据,那么系统的性能可能会因此受到影响
按锁的级别(悲观锁与乐观锁)
悲观锁
- 共享(读)锁(S)
- 排他(写)锁(X)
就是比较悲观的锁,总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁,Java中synchronized是悲观锁思想的实现
乐观锁
- 意向共享锁
- 意向排他锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现,适用于多读的应用类型,这样可以提高吞吐量。
常用类型锁
共享锁(S锁)、排他锁(X锁)、意向共享锁(IS锁) 以及意向排他锁(IX锁),其中,意向共享锁和意向排他锁都是表级别的锁,共享锁和排他锁都是行级锁,innodb支持行锁,myisam不支持。
共享锁(行锁/读锁)
有事务对某数据加读锁,那么其他事务只可以读这条数据,不可修改
排他锁(行锁/写锁)
有事务对某数据加写锁,那么就只有该事务可以操作此数据,别的事务既不能读、也不能写
意向共享锁(表锁)
对一张表中某几行加的共享锁。
意向排他锁(表锁)
对一张表中某几行加的排他锁,目的是为了告诉其他事务,此时这条表被一个事务在访问;作用是可以排除表级别读写锁 (全面扫描加锁)。
Mysql事务的分类
扁平事务
是事务类型中最简单的一种,但在实际生产环境中,这可能是使用最为频繁的事务。 在扁平事务中,所有操作都处于同一层次,其由BEGIN WORK 开始,由COMMIT WORK 或ROLLBACK WORK 结束,其间的操作是原子的,要么都执行,要么都回滚。因此扁平事务是应用程序成为原子操作的基本组成模块。
注:扁平事务虽然简单,但在实际生产环境中使用最为频繁。正因为其简单,使用频繁,故每个数据库系统都实现了对扁平事务的支持。扁平事务的主要限制是不能提交或者回滚事务的某一部分,或分几个步骤提交。
带有保存点的扁平事务
除了支持扁平事务支持的操作外,允许在事务执行过程中回滚到同一事务中较早的一个状态。这是因为某些事务可能在执行过程中出现的错误并不会导致所有的操作都无效,放弃整个事务不合乎要求,开销也太大。保存点(Savepoint) 用来通知系统应该记住事务当前的状态,以便当之后发生错误时,事务能回到保存点当时的状态。
注意事项:
- 对于扁平的事务来说,其隐式地设置了一个保存点。然而在整个事务中,只有这一个保存点,因此,回滚只能回滚到事务开始时的状态。保存点用SAVE WORK 函数来建立,通知系统记录当前的处理状态。当出现问题时,保存点能用作内部的重启动点,根据应用逻辑,决定是回到最近一个保存点还是其他更早的保存点。
- 保存点在事务内部是递增的,这意味着 ROLLBACK 不影响保存点的计数,并且单调递增的编号能保持事务执行的整个历史过程,包括在执行过程中想法的改变。如果想要完全回滚事务,还需要再执行命令ROLLBACK WORK 。
链事务
在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式地传给下一个要开始的事务。注意,提交事务操作和开始下一个事务操作将合并为一个原子操作。这意味着下一个事务将看到上一个事务的结果,就好像在一个事务中进行的一样。
注意事项:
- 可视为保存点模式的一种变种。带有保存点的扁平事务,当发生系统崩溃时,所有的保存点都将消失,因为其保存点是易失的(volatile),而非持久的(persistent) 。这意味着当进行恢复时,事务需要从开始处重新执行,而不能从最近的一个保存点继续执行。
- 链事务与带有保存点的扁平事务不同的是,带有保存点的扁平事务能回滚到任意正确的保存点。而链事务中的回滚仅限于当前事务,即只能恢复到最近一个的保存点。对于锁的处理,两者也不相同。
- 链事务在执行COMMIT 后即释放了当前事务所待有的锁,而带有保存点的扁平事务不影响迄今为止所持有的锁。
嵌套事务
是一个层次结构框架。由一个顶层事务( topleveltransaction) 控制着各个层次的事务。顶层事务之下嵌套的事务被称为 子事务 (subtransaction), 其控制每一个局部的变换。
分布式事务
通常是一个在分布式环境下运行的扁平事务,因此需要根据数据所在位置访问网络中的不同节点(银行转账就是典型的分布式事务)。
注:对于InnoDB 存储引擎来说,其支持扁平事务、带有保存点的事务、链事务、分布式事务。对于嵌套事务,其并不原生支持,因此,对有并行事务需求的用户来说,MySQL 数据库或InnoDB 存储引擎就显得无能为力了。然而用户仍可以通过带有保存点的事务来模拟串行的嵌套事务。
MyISAM存储引擎和InnoDB存储引擎
MyISAM和InnoDB这两个存储引擎都使用B+树作为索引的结构,但是这两种存储引擎对索引的具体实现方式方面是不同的。下面来具体介绍一下这两种存储引擎的索引具体是如何实现的。
MyISAM存储引擎
- MyISAM引擎中,B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 **data域的值,然后以data****域的值为地址读取相应的数据记录。**所以MyISAM存储引擎中索引的实现特征是数据和索引分离,这被称为“非聚簇索引”。
- **非聚簇索引是一种索引结构和数据分开存放的索引,**该索引中索引的逻辑顺序与数据库表行中数据的物理顺序不同。
- 在MyISAM存储引擎中,只要索引值不重复的索引都被称为主索引。 所以MyISAM存储引擎中可以从在多个主索引。
- 在MyISAM存储引擎中,索引值重复的索引都被称为辅助索引(又称二级索引)
- 在MyISAM存储引擎中,无论是主索引还是辅索引,他们的叶子节点都保存的是数据的地址,因此多个索引之间可以保持同步的关系。
当我们在MyISAM存储引擎中创建一个表时,这个表会相应生成三个文件
- .frm文件,这是表定义文件。
- .myi文件,这个表存储了数据的索引。
- .md文件,这个表存储的是数据。
InnoDB存储引擎
InnoDB引擎中,其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶子节点data域保存了完整的数据记录(在Mysql中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据)。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,即数据表的主键列使用的就是主索引。
主键索引和辅助索引
数据表的主键列使用的索引就是主键索引。一张数据表有只能有一个主键,并且主键不能为 null,不能重复。许多情况下我们在建好表之后,并没有主动的建立索引,此时索引是系统帮助我们创建的。其创建的过程如下:
在我们创建好表之后,系统会查看表中有没有主键,如果我们设置了主键,那么系统就会根据这个主键来建立一个主键索引,接着将这个主键索引当为主索引(主索引不允许索引值重复,也不允许值为null)。
如果表中没有设置主键,那么系统就会查看表中有没有唯一索引的字段,如果有,那么系统就会将这个唯一索引的字段当为主索引(主索引不允许索引值重复)。
如果表中没有唯一索引的字段,此时系统就会在表中添加一个隐含字段,这个字段的大小为6字节。接着系统就会根据这个隐藏字段来建立索引,此时这个索引就变成了主索引了。所以****InnoDB **存储引擎中的主索引只有一个,**其余的索引都作为辅助索引。
在根据主索引搜索时,直接找到key所在的叶子节点即可取出数据;辅助索引是一种非聚集索引,其在叶子节点中存储的数据是索引列所在的表中对应的主键值。所以在根据辅助索引(二级索引)查找时,则需要先搜索辅助索引取出主键的值,然后依据取出的主键查询主索引,通过主键值找到数据,一共查询了两次。
聚簇索引
聚簇索引是一种索引结构和数据存放在一起的索引,**数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。**一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作。
覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, **而无需回表查询。**所以对于非聚簇索引来说,并不是必须要回表查询的,只要查询的字段正好是索引的字段,那么就可以直接返回查询的结果,无需再根据主键值到主键索引中再次查询了。
四、Http
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。在 OSI 七层模型中,HTTP协议位于最顶层的应用层中。通过浏览器访问网页就直接使用了 HTTP 协议。使用 HTTP 协议时,客户端首先与服务端的 80 端口建立一个 TCP 连接,然后在这个连接的基础上进行请求和应答,以及数据的交换。
HTTP 有两个常用版本,分别是 HTTP1.0和 HTTP1.1。主要区别在于 HTTP1.0 中每次请求和应答都会使用一个新的 TCP 连接,而从 HTTP1.1 开始,运行在一个 TCP 连接上发送多个命令和应答。因此大幅度减少了 TCP 连接的建立和断开,提高了效率。
特点
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
- 支持B/S及C/S模式。
请求消息Request
- 请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
- 请求头部,用来说明服务器要使用的附加信息,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
- 空行,请求头部后面的空行是必须的
- 请求数据也叫主体,可以添加任意的其他数据。
响应消息Response
- 状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
- 消息报头,用来说明客户端要使用的一些附加信息
- 空行,消息报头后面的空行是必须的
- 响应正文,服务器返回给客户端的文本信息。
状态码
- 200 OK //客户端请求成功
- 301 Moved Permanently //永久重定向,使用域名跳转
- 302 Found // 临时重定向,未登陆的用户访问用户中心重定向到登录页面
- 400 Bad Request //客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
- 403 Forbidden //服务器收到请求,但是拒绝提供服务
- 404 Not Found //请求资源不存在,eg:输入了错误的URL
- 500 Internal Server Error //服务器发生不可预期的错误
- 503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http的方法
- get:客户端向服务端发起请求,获得资源。请求获得URL处所在的资源。
- post:向服务端提交新的请求字段。请求URL的资源后添加新的数据。
- head:请求获取URL资源的响应报告,即获得URL资源的头部
- patch:请求局部修改URL所在资源的数据项
- put:请求修改URL所在资源的数据元素。
- delete:请求删除url资源的数据
https是如何保证数据传输的安全
https实际就是在TCP层与http层之间加入了SSL/TLS来为上层的安全保驾护航,主要用到对称加密、非对称加密、证书,等技术进行客户端与服务器的数据加密传输,最终达到保证整个通信的安全性。
SSL/TLS协议作用:
- 认证用户和服务器,确保数据发送到正确的客户机和服务器;
- 加密数据以防止数据中途被窃取;
- 维护数据的完整性,确保数据在传输过程中不被改变。
幂等
一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。例如,“getUsername()和setTrue()”函数就是一个幂等函数.
基于http协议的长连接
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request中增加”Connection: keep-alive“ header才能够支持,而HTTP1.1默认支持.
http1.0请求与服务端的交互过程
- 客户端发出带有包含一个header:”Connection: keep-alive“的请求
- 服务端接收到这个请求后,根据http1.0和”Connection: keep-alive“判断出这是一个长连接,就会在response的header中也增加”Connection: keep-alive“,同时不会关闭已建立的tcp连接.
- 客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.
Http协议实现的原理机制
客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。
发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
三次握手、四次挥手
三次握手
第一次握手
客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN。此时客户端处于 SYN_SEND 状态。
首部的同步位SYN=1,初始序号seq=x,SYN=1的报文段不能携带数据,但要消耗掉一个序号。
第二次握手
服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN。同时会把客户端的 ISN + 1 作为ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
在确认报文段中SYN=1,ACK=1,确认号ack=x+1,初始序号seq=y。
第三次握手
客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接。
确认报文段ACK=1,确认号ack=y+1,序号seq=x+1(初始为seq=x,第二个报文段所以要+1),ACK报文段可以携带数据,不携带数据则不消耗序号。
四次挥手
第一次挥手
客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态。
即发出连接释放报文段(FIN=1,序号seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN_WAIT1(终止等待1)状态,等待服务端的确认。
第二次挥手
服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。
即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号ack=u+1,序号seq=v),服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放。客户端收到服务端的确认后,进入FIN_WAIT2(终止等待2)状态,等待服务端发出的连接释放报文段。
第三次挥手
如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
即服务端没有要向客户端发出的数据,服务端发出连接释放报文段(FIN=1,ACK=1,序号seq=w,确认号ack=u+1),服务端进入LAST_ACK(最后确认)状态,等待客户端的确认。
第四次挥手
客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
即客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入TIME_WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL后,客户端才进入CLOSED状态。
收到一个FIN只意味着在这一方向上没有数据流动。客户端执行主动关闭并进入TIME_WAIT是正常的,服务端通常执行被动关闭,不会进入TIME_WAIT状态。
Http协议由什么组成?
请求行
方法字段 + URL + Http协议版本
通用信息头
Cache-Control头域:指定请求和响应遵循的缓存机制。
keep-alive 使其连接持续有效
请求头
- Referer: 先前网页的地址,当前请求网页紧随其后,即来路。
- User-Agent:经常用来做浏览器检测的userAgent。
- Cache-Control: 缓存策略,如max-age:100,详见官方文档。
- Connection: 连接选项,例如是否允许代理。
- Host: 指定请求的服务器的域名和端口号。
- Content-Encoding: 返回内容的编码,如gzip。
- Content-Language: 返回内容的语言。
- Content-Length: 返回内容的字节长度。
- Content-Type: 返回内容的媒体类型,如text/html。
- Date: 返回时间。
- Accept: 允许哪些媒体类型。
- Accept-Charset: 允许哪些字符集。
- Accept-Encoding: 允许哪些编码。
- Accept-Language: 允许哪些语言。
请求内容实体
- 状态行:包含HTTP版本,状态码,状态码原因短语
- 响应首部字段
- 响应内容实体
Http与Https的区别:
- HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头
- HTTP 是不安全的,而 HTTPS 是安全的
- HTTP 标准端口是80 ,而 HTTPS 的标准端口是443
- 在OSI 网络模型中,HTTP工作于应用层,而HTTPS 的安全传输机制工作在传输层
- HTTP 无法加密,而HTTPS 对传输的数据进行加密
- HTTP无需证书,而HTTPS 需要CA机构wosign的颁发的SSL证书
HTTPS工作原理
一、首先HTTP请求服务端生成证书,客户端对证书的有效期、合法性、域名是否与请求的域名一致、证书的公钥(RSA加密)等进行校验;
二、客户端如果校验通过后,就根据证书的公钥的有效, 生成随机数,随机数使用公钥进行加密(RSA加密);
三、消息体产生后,对它的摘要进行MD5(或者SHA1)算法加密,此时就得到了RSA签名;
四、发送给服务端,此时只有服务端(RSA私钥)能解密。
五、解密得到的随机数,再用AES加密,作为密钥(此时的密钥只有客户端和服务端知道)。
什么是Http协议无状态协议?怎么解决Http协议无状态协议?
无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息。也就是说,当客户端一次HTTP请求完成以后,客户端再发送一次HTTP请求,HTTP并不知道当前客户端是一个”老用户“。
可以使用Cookie来解决无状态的问题,Cookie就相当于一个通行证,第一次访问的时候给客户端发送一个Cookie,当客户端再次来的时候,拿着Cookie(通行证),那么服务器就知道这个是”老用户“。
Cookie是否会被覆盖,localStorage是否会被覆盖
Cookie是可以覆盖的,如果重复写入同名的Cookie,那么将会覆盖之前的Cookie
如果要删除某个Cookie,只需要新建一个同名的Cookie,并将maxAge设置为0,并添加到response中覆盖原来的Cookie。注意是0而不是负数。负数代表其他的意义。localStorage存储在一个对象中. 有键值对
什么是localStorage
在HTML5中,新加入了一个localStorage特性,这个特性主要是用来作为本地存储来使用的,解决了cookie存储空间不足的问题(cookie中每条cookie的存储空间为4k),localStorage中一般浏览器支持的是5M大小,这个在不同的浏览器中localStorage会有所不同。
localStorage的优势
1、localStorage拓展了cookie的4K限制
2、localStorage可以将第一次请求的数据直接存储到本地,这个相当于一个5M大小的针对于前端页面的数据库,相比于cookie可以节约带宽,但是这个却是只有在高版本的浏览器中才支持的
localStorage的局限
1、浏览器的大小不统一,并且在IE8以上的IE版本才支持localStorage这个属性
2、目前所有的浏览器中都会把localStorage的值类型限定为string类型,这个在对我们日常比较常见的JSON对象类型需要一些转换
3、localStorage在浏览器的隐私模式下面是不可读取的
4、localStorage本质上是对字符串的读取,如果存储内容多的话会消耗内存空间,会导致页面变卡
5、localStorage不能被爬虫抓取到
localStorage与sessionStorage的唯一一点区别就是localStorage属于永久性存储,而sessionStorage属于当会话结束的时候,sessionStorage中的键值对会被清空
cookie和session的区别
存储位置不同
cookie存放于客户端;session存放于服务端。
隐私策略不同
cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的;session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
生命周期不同
设置cookie的属性,达到cookie长期有效的效果;session只需关闭窗口该session就会失效,因此session不能长期有效。
存储上限不同
cookie有存储上限,4k左右;session没有
get和post请求的区别
- get请求一般是获取数据,post请求一般是提交数据
- get因为参数会放在url中,所以隐私性,安全性较差,请求的数据长度是有限制的,不同的浏览器和服务器不同,一般限制在 2~8K 之间,更加常见的是 1k 以内;post请求是没有的长度限制,请求数据是放在body中;
- get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求。
- get请求可以被缓存,post请求不会被缓存。
- get请求会被保存在浏览器历史记录当中,post不会。get请求可以被收藏为书签,因为参数就是url中,但post不能。它的参数不在url中。
五、Tomcat
Tomcat是什么?
Tomcat 服务器Apache软件基金会项目中的一个核心项目,是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选。默认端口8080
修改端口号方式
- 找到Tomcat目录下的conf文件夹
- 进入conf文件夹里面找到server.xml文件
- 打开server.xml文件
- 在server.xml文件里面找到下列信息
- 把Connector标签的8080端口改成你想要的端口
怎么在Linux部署项目
先使用eclipse或IDEA把项目打成.war包,然后上传到Linux服务器,然后把项目放在Tomcat的bin目录下的webapps,在重启Tomcat就行了。
Tomcat的目录结构
- /bin:存放用于启动和暂停Tomcat的脚本
- /conf:存放Tomcat的配置文件
- /lib:存放Tomcat服务器需要的各种jar包
- /logs:存放Tomcat的日志文件
- /temp:Tomcat运行时用于存放临时文件
- /webapps:web应用的发布目录
- /work:Tomcat把有jsp生成Servlet防御此目录下
类似Tomcat,发布jsp运行的web服务器还有那些:
- Resin
- Jetty
- WebLogic
- Jboss
tomcat 如何优化?
改Tomcat最大线程连接数 需要修改conf/server.xml文件,修改里面的配置文件: maxThreads=”150”//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可 创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般 可以在400-500。最大可以在800左右。
Tomcat内存优化,启动时告诉JVM我要多大内存 调优方式的话,修改: Windows 下的catalina.bat Linux 下的catalina.sh 修改方式如: JAVA_OPTS=’-Xms256m -Xmx512m’-Xms JVM初始化堆的大小-Xmx JVM堆的最大值 实际参数大
tomcat 有哪几种Connector 运行模式(优化)
BIO
同步并阻塞 一个线程处理一个请求。
缺点:并发量高时,线程数较多,浪费资源。Tomcat7或以下,在Linux系统中默认使用这种方式。 配制项:protocol=”HTTP/1.1”
NIO
同步非阻塞IO 利用Java的异步IO处理,可以通过少量的线程处理大量的请求,可以复用同一个线程处理多个connection(多路复用)。Tomcat8在Linux系统中默认使用这种方式。 Tomcat7必须修改Connector配置来启动。 配制项:protocol=”org.apache.coyote.http11.Http11NioProtocol” 备注:我们常用的Jetty,Mina,ZooKeeper等都是基于java nio实现.
APR
即Apache Portable Runtime,从操作系统层面解决io阻塞问题。 AIO方式,异步非阻塞IO(Java NIO2又叫AIO) 主要与NIO的区别主要是操作系统的底层区别.可以做个比喻:比作快递,NIO就是网购后要自己到官网查下快递是否已经到了(可能是多次),然后自己去取快递;AIO就是快递员送货上门了(不用关注快递进度)。
配制项:protocol=”org.apache.coyote.http11.Http11AprProtocol” 备注:需在本地服务器安装APR库。Tomcat7或Tomcat8在Win7或以上的系统中启动默认使用这种方式。Linux如果安装了apr和native,Tomcat直接启动就支持apr。
tomcat容器是如何创建servlet类实例?用到了什么原理?
当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对 xml文件进行解析,并读取servlet注册信息。然后,将每个应用中注册的servlet类都进行加载,并通过 反射的方式实例化。(有时候也是在第一次请求时实例化)
在servlet注册时加上1如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。
六、Spring
Spring的IoC理解:
什么是IOC:
IOC,Inversion of Control,控制反转,指将对象的控制权转移给Spring框架,由 Spring 来负责控制对象的生命周期(比如创建、销毁)和对象间的依赖关系。
最直观的表达就是,以前创建对象的时机和主动权都是由自己把控的,如果在一个对象中使用另外的对象,就必须主动通过new指令去创建依赖对象,使用完后还需要销毁(比如Connection等),对象始终会和其他接口或类耦合起来。而 IOC 则是由专门的容器来帮忙创建对象,将所有的类都在 Spring 容器中登记,当需要某个对象时,不再需要自己主动去 new 了,只需告诉 Spring 容器,然后 Spring 就会在系统运行到适当的时机,把你想要的对象主动给你。也就是说,对于某个具体的对象而言,以前是由自己控制它所引用对象的生命周期,而在IOC中,所有的对象都被 Spring 控制,控制对象生命周期的不再是引用它的对象,而是Spring容器,由 Spring 容器帮我们创建、查找及注入依赖对象,而引用对象只是被动的接受依赖对象,所以这叫控制反转。
什么是DI
IoC 的一个重点就是在程序运行时,动态的向某个对象提供它所需要的其他对象,这一点是通过DI(Dependency Injection,依赖注入)来实现的,即应用程序在运行时依赖 IoC 容器来动态注入对象所需要的外部依赖。而 Spring 的 DI 具体就是通过反射实现注入的,反射允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性
Spring的AOP理解
OOP面向对象,允许开发者定义纵向的关系,但并不适用于定义横向的关系,会导致大量代码的重复,而不利于各个模块的重用。
AOP,一般称为面向切面,作为面向对象的一种补充,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,提高系统的可维护性。可用于权限认证、日志、事务处理。
代理类型
- AspectJ是静态代理,也称为编译时增强,AOP框架会在编译阶段生成AOP代理类,并将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
- Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
动态代理方式
① JDK动态代理只提供接口的代理,不支持类的代理,要求被代理类实现接口。JDK动态代理的核心是InvocationHandler接口和Proxy类,在获取代理对象时,使用Proxy类来动态创建目标类的代理类(即最终真正的代理类,这个类继承自Proxy并实现了我们定义的接口),当代理对象调用真实对象的方法时, InvocationHandler 通过invoke()方法反射来调用目标类中的代码,动态地将横切逻辑和业务编织在一起;
② 如果被代理类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成指定类的一个子类对象,并覆盖其中特定方法并添加增强代码,从而实现AOP。CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
Spring bean的创建流程
1.读取Bean的定义信息
通过BeanDefinitionReader这个接口解析xml配置、配置类或其他的一些方式定义的类,得到BeanDefinition(Bean定义信息)
2.实例化Bean
通过BeanPostProcessor这个接口(增强器)可以对我们的BeanDefinition进行一些修改,然后BeanFactory通过反射实例化Bean对象,但是此时的Bean对象还没有进行初始化,没有填充属性等操作。
3.初始化Bean
- 自定义属性赋值是用 set 方法赋值(populateBean())
- 容器对象的属性赋值是用实现Aware接口的方式来赋值(invokeAwareMethods()),如BeanNameAware
- 调用BeanPostProcessor的前置处理方法
- 调用init初始化方法:init-method
- 调用BeanPostProcessor的后置处理方法(AOP在这里实现)
- 获得一个完整的对象,并将对象放入CurrentHashMap中(通过Context.getBean()可以获取到Bean对象并使用)
4.销毁Bean
Spring容器关闭时会调用DisposableBean的Destory()方法
如果你在这个Bean中配置了destory-method属性,会自动调用指定的销毁方法
Bean的生命周期
- 通过解析配置类、注解类或者以其他方式定义的类,得到BeanDefinition(Bean定义信息)
- BeanFactory通过获取到的BeanDefinition,利用反射创建Bean对象
- 通过populateBean()方法对Bean对象进行属性填充
- 通过invokeAwareMethods()方法对Bean对象进行赋值
- 调用BeanPostProcessor的初始化前置方法
- 调用init-method方法,进行初始化操作
- 调用BeanPostProcessor的初始化后置方法(AOP在此处进行)
- 将创建好的Bean对象放入map容器中
- 通过Context.getBean()方法获得Bean对象并使用
- spring容器关闭时会调用DisposableBean的destory()方法销毁Bean对象(如果配置了destory-method属性,spring会自动调用指定的销毁方法)
Spring中bean的作用域:
- singleton:默认作用域,单例bean,每个容器中只有一个bean的实例。
- prototype:为每一个bean请求创建一个实例。
- request:为每一个request请求创建一个实例,在请求完成以后,bean会失效并被垃圾回收器回收。
- session:与request范围类似,同一个session会话共享一个实例,不同会话使用不同的实例。
- global-session:全局作用域,所有会话共享一个实例。如果想要声明让所有会话共享的存储变量的话,那么这全局变量需要存储在global-session中。
InitializingBean、BeanPostProcessor、@PostConstruct
区别
1、BeanPostProcess先于InitializingBean执行
2、InitializingBean是在对象已经实例化之后,执行接口的afterPropertiesSet()方法;BeanPostProcess是在bean构建的过程中,此时对象已经执行了构造方法,随后执行before/after方法,postProcessBeforeInitialization,postProcessAfterInitialization
注意:每个bean在构建的过程中,Spring都会遍历所有的BeanPostProcessor的实现类,调用实现类中的方法,入参为构建好的bean
3、自己实现BeanPostProcess接口时,如果想生效,还需将实现类构建成SpringBean。即需要用@Component注解 等方法
执行顺序
- 先执行无参构造函数
- 执行BeanPostProcessor的postProcessBeforeInitalization方法
- 执行被@PostConstruct注解标注的方法
- 执行InitializingBean的afterPropertiesSet方法
- 执行BeanPostProcessor的postProcessAfterInitialization方法
七、SpringBoot
什么是SpringBoot
通过自动配置方式简化Spring应用的开发,弱化配置,遵循约定大于配置的原则,使开发者专注于业务开发而无需过多考虑配置相关操作,通过启动类的main方法一键启动应用。
优点
1、独立运行。
内嵌了servlet,tomat等,不需要打成war包部署到容器中,只需要将SpringBoot项目打成jar包就能独立运行。
2、简化配置
启动器自动依赖其他组件,简少了 maven 的配置。各种常用组件及配置已经默认配置完成,无需过多干预。
3、避免大量的Maven导入和各种版本冲突
4、应用监控
Spring Boot 提供一系列端点可以监控服务及应用。
SpringBoot和Spring、SpringMVC的区别
Spring
主要用来创建IOC容器,依赖注入,实现程序间的松耦合
SpringMVC
主要是用来做WEB开发,通过各种组件的协调配合,简化Web应用的开发
SpringBoot
SpringBoot更像是一个管家,当使用到对应功能时,只需要导入指定应用启动器,SpringBoot就能够在底层默认其配置,大大简化了开发所需的繁杂配置
核心注解
核心注解为:@SpringBootApplication
该注解主要由三个注解组成:
@SpringBootConfiguration():代表当前是一个配置类
@EnableAutoConfiguration(): 启动自动配置
@ComponentScan():指定扫描哪些Spring注解
自动装配流程
启动类的@SpringBootApplication注解由@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan三个注解组成,三个注解共同完成自动装配;
- @SpringBootConfiguration 注解标记启动类为配置类
- @ComponentScan 注解实现启动时扫描启动类所在的包以及子包下所有标记为bean的类由IOC容器注册为bean
- @EnableAutoConfiguration 注解通过@Import注解导入 ImportSelector 的子类 AutoConfigurationImportSelector 类,该类通过selectImports方法加载读取所有 spring-boot-autoconfigure 依赖下的 spring-autoconfigure-metadata.properties 配置文件和spring.factories 配置文件的内容,并根据 AutoConfigurationImportSelector 类下的 AutoConfigurationImportFilter过滤器的过滤规则和 spring-autoconfigure-metadata.properties 配置文件的内容过滤掉 spring.factories文件中需要被过滤掉的组件元素(当然这之前还有一步根据@EnableAutoConfiguration注解的 exclude 和 excludeName属性过滤 spring.factories 配置文件的内容,由于 @EnableAutoConfiguration注解的这两个属性默认为空,所以这步操作什么都没做),最终返回spring.factories文件中剩余组件的类全名数组,并由IOC容器注册为Bean
八、SpringCloud
SpringGateway
Spring Cloud GateWay如何实现限流?
-
Spring Cloud GateWay使用令牌桶算法实现限流(Nginx使用漏桶算法实现限流 )
-
Spring Cloud GateWay默认使用Redis 的RateLimter限流算法来实现,所以需要引入Redis依赖
-
使用的过程中,主要配置 令牌桶填充的速率,令牌桶容量,指定限流的key
-
限流的Key,可以根据用户 来做限流,IP 来做限流,接口限流等等。
微服务中网关的作用
统一入口:为全部微服务提供唯一入口点,网关起到外部和内部隔离,保障了后台服务的安全性
鉴权校验:识别每个请求的权限,拒绝不符合要求的请求
动态路由:动态的将请求路由到不同的后端集群中
减少客户端与服务端的耦合:服务可以独立发展,通过网关层来做映射
流量控制算法----漏桶算法和令牌桶算法
什么是漏桶算法?
漏桶算法思路很简单,请求先进入到漏桶里,漏桶以固定的速度出水,也就是处理请求,当水加的过快,则会直接溢出,也就是拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
long timeStamp = getNowTime();
int capacity = 10000;// 桶的容量
int rate = 1;//水漏出的速度
int water = 100;//当前水量
public static bool control() {
//先执行漏水,因为rate是固定的,所以可以认为“时间间隔*rate”即为漏出的水量
long now = getNowTime();
water = Math.max(0, water - (now - timeStamp) * rate);
timeStamp = now;
if (water < capacity) { // 水还未满,加水
water ++;
return true;
} else {
return false;//水满,拒绝加水
}
}
该算法很好的解决了时间边界处理不够平滑的问题,因为在每次请求进桶前都将执行“漏水”的操作,再无边界问题。
但是对于很多场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
该算法很好的解决了时间边界处理不够平滑的问题,因为在每次请求进桶前都将执行“漏水”的操作,再无边界问题。
但是对于很多场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
什么是令牌桶算法?
从某种意义上讲,令牌桶算法是对漏桶算法的一种改进,桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用的平均速率的同时还允许一定程度的突发调用。在令牌桶算法中,存在一个桶,用来存放固定数量的令牌。算法中存在一种机制,以一定的速率往桶中放令牌。每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌、或者直接拒绝。放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行,比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,这时服务还没完全启动好,等启动完成对外提供服务时,该限流器可以抵挡瞬时的100个请求。所以,只有桶中没有令牌时,请求才会进行等待,最后相当于以一定的速率执行。
实现思路:可以准备一个队列,用来保存令牌,另外通过一个线程池定期生成令牌放到队列中,每来一个请求,就从队列中获取一个令牌,并继续执行。
九、RabbitMQ
如何保证消息消费的顺序性
1、拆分多个 queue,每个 queue 一个 consumer。
2、一个 queue,但是对应一个 consumer,然后这个 consumer 内部用内存队列(其实就是List而已)做排队,然后分发给底层不同的thread来处理(此方案可以支持高并发)。
实际consumer的数量是受限的,不会仅仅因为消息消费太慢而去增加consumer实例的数量,所以通过方案2的方式,可以在不增加consumer实例数量的前提下,加快消息消费的速度。
如何保证消息不丢失?

1,生产者发送消息至MQ的数据丢失
解决方法:在生产者端开启comfirm 确认模式,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了
2,MQ收到消息,暂存内存中,还没消费,自己挂掉,数据会都丢失
解决方式:MQ设置为持久化。将内存数据持久化到磁盘中
3,消费者刚拿到消息,还没处理,挂掉了,MQ又以为消费者处理完
解决方式:用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须关闭 RabbitMQ 的自动 ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack 了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
如何保证消息不被重复消费
业务场景:假设你有个系统,消费一条消息就往数据库里插入一条数据,要是你一个消息重复两次,你不就插入了两条,这数据不就错了?但是你要是消费到第二次的时候,自己判断一下是否已经消费过了,若是就直接扔了,这样不就保留了一条数据,从而保证了数据的正确性。
解决方案:
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update 一下好吧。
比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类的东西,然后你这里消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
比如基于数据库的唯一键来保证重复数据不会重复插入多条。因为有唯一键约束了,重复数据插入只会报错,不会导致数据库中出现脏数据
消息怎么路由?
消息提供方->路由->一至多个队列消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。通过队列路由键,可以把队列绑定到交换器上。消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
常用的交换器主要分为一下三种:
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
direct:如果路由键完全匹配,消息就被投递到相应的队列
topic:可以使来自不同源头的消息能够到达同一个队列。 使用 topic 交换器时,可以使用通配符
mq 的缺点
(1)系统可用性降低
系统引入的外部依赖越多,越容易挂掉,本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一MQ 挂了咋整?MQ 挂了,整套系统崩溃了,你不就完了么。
(2)系统复杂性提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已
(3)一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。
十、Redis
Redis 的数据类型
1、string(字符串)是redis最常用的类型,可以包含任何数据,一个key对应一个value,在Rediss中是二进制安全的。
2、hash(哈希)是一个string 类型的field和value的映射表,适合被用于存储对象。
3、list(列表)是一个链表结构,按照插入顺序排序。
4、set(集合)是 string 类型的无序集合。
5、zset(有序集合)是string类型元素的集合,zset是插入有序的,即自动排序。
Redis 相比 Memcached 有哪些优势
存储方式不同
memcache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小;Redis 有部份存在硬盘上,这样能保证数据的持久性。
数据支持类型
memcache 对数据类型支持相对简单;Redis 有复杂的数据类型。
使用底层模型不同
它们之间底层实现方式,以及与客户端之间通信的应用协议不一样,Redis 自己构建了 vm 机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。 value 值大小不同:Redis 最大可以达到 1gb;memcache 只有 1mb。
如果key快要过期,但是业务逻辑还没执行完成
Redisson

watch dog 的自动延期机制
watch dog 机制启动,且代码中没有释放锁操作时,watch dog 会不断的给锁续期;
如果程序释放锁操作时因为异常没有被执行,那么锁无法被释放,所以释放锁操作一定要放到 finally {} 中;
要使 watchLog机制生效 。只要不传leaseTime即可
watchlog的延时时间 可以由 lockWatchdogTimeout指定默认延时时间,但是不要设置太小。如100
watchdog 会每 lockWatchdogTimeout/3时间,去延时。
watchdog 通过 类似netty的 Future功能来实现异步延时
watchdog 最终还是通过 lua脚本来进行延时
Redis实现队列
List 类型实现
List 类型实现的方式最为简单和直接,它主要是通过 lpush、rpop 存入和读取实现消息队列的,如下图所示:

lpush 可以把最新的消息存储到消息队列(List 集合)的首部,而 rpop 可以读取消息队列的尾部,这样就实现了先进先出,如下图所示:

优点:使用 List 实现消息队列的优点是消息可以被持久化,List 可以借助 Redis 本身的持久化功能,AOF 或者是 RDB 或混合持久化的方式,用于把数据保存至磁盘,这样当 Redis 重启之后,消息不会丢失。
缺点:但使用 List 同样存在一定的问题,比如消息不支持重复消费、没有按照主题订阅的功能、不支持消费消息确认等。
ZSet 实现消息队列
ZSet 实现消息队列:它是利用 zadd 和 zrangebyscore 来实现存入和读取消息的。
**优点:**同样具备持久化的功能
**缺点:**List 存在的问题它也同样存在,不但如此,使用 ZSet 还不能存储相同元素的值。因为它是有序集合,有序集合的存储元素值是不能重复的,但分值可以重复,也就是说当消息值重复时,只能存储一条信息在 ZSet 中。
Redis发布/订阅(PUB/SUB)实现消息队列
PUBLISH,向信道发送消息
SUBSCRIBE,用于订阅信道
UNSUBSCRIBE,取消订阅
生产者和消费者通过相同的一个信道(Channel)进行交互。信道其实也就是队列。通常会有多个消费者。多个消费者订阅同一个信道,当生产者向信道发布消息时,该信道会立即将消息逐一发布给每个消费者。可见,该信道对于消费者是发散的信道,每个消费者都可以得到相同的消息。典型的对多的关系。
优点是:
典型的广播模式,一个消息可以发布到多个消费者
多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息
消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点是:
消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
不能保证每个消费者接收的时间是一致的
若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时
可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
实现:
Jedis提供了JedisPubSub抽象类,我们只要继承该类,实现其中的onMessage,onSubscribe,onUnsubscribe等方法即可。
基于SortedSet有序集合的实现
有序集合的方案是在自己确定消息顺ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。通常可以使用时间戳+序号的方案。确保了消息ID的单调递增,利用SortedSet的依据Score排序的特征,就可以制作一个有序的消息队列了。
和上面的方案相比,优点就是可以自定义消息ID,在消息ID有意义时,比较重要。缺点也明显,不允许重复消息(以为是集合),同时消息ID确定有错误会导致消息的顺序出错。
Redis缓存穿透、击穿、雪崩
1. 缓存雪崩
指在系统运行过程中,缓存服务宕机或大量的key值同时过期,导致所有请求都直接访问数据库导致数据库压力增大。
解决办法
这里分三个时间段进行进行分析
事前
如果缓存雪崩造成的原因是因为缓存服务宕机造成的,可以将redis采用集群部署,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。若缓存雪崩是因为大量缓存因为失效时间而造成的,我们在批量往redis存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效,或者设置热点数据永远不过期,有更新操作就更新缓存就可以了。
事中
如果我们之前没有考虑缓存雪崩的问题,那么在实际使用中真的发生缓存雪崩了,我们该怎么办呢?这时我们就要考虑使用其他方法避免出现这种情况了。我们可以使用ehcache 本地缓存 + Hystrix 限流&降级 ,避免 MySQL 被打死的情况发生。
这里使用echache本地缓存的目的就是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix 进行 限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000 个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑,然后去调用我们自己开发的降级组件(降级)。比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
事后
如果缓存服务宕机了,这里我们可以开启**「Redis」** 持久化 「RDB」+「AOF」,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
2. 缓存穿透
在正常的情况下,用户查询数据都是存在的,但是在异常情况下,缓存与数据都没有数据,但是用户不断发起请求,这样每次请求都会打到数据库上面去,这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
解决办法
添加参数校验
我刚入职的时候,我的老大就跟我说过,作为一名后端开发工程师,不要相信前端传来的东西,所以数据一定要在后端进行校验。我们可以在接口层添加校验,不合法的直接返回即可,没必要做后续的操作。
缓存空值
上面我们也介绍了,之所以会发生穿透,就是因为缓存中没有存储这些空数据的key。从而导致每次查询都到数据库去了。
那么我们就可以为这些key 设置的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null ,就不用在到 数据库中去走一圈了。但是别忘了设置过期时间。
布隆过滤器
redis的一个高级用法就是使用布隆过滤器(Bloom Filter),BloomFilter 类似于一个hase set 用来判断某个元素(key)是否存在于某个集合中。这个也能很好的防止缓存穿透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
3. 缓存击穿
我们在平常高并发的系统中,大量的请求同时查询一个key时,假设此时,这个key正好失效了,就会导致大量的请求都打到数据库上面去,这种现象我们称为击穿。
这么看缓存击穿和缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是**「缓存击穿」**是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
缓存击穿带来的问题就是会造成某一时刻数据库请求量过大,压力剧增。
解决办法
不过期
我们简单粗暴点,直接让热点数据永远不过期,定时任务定期去刷新数据就可以了。不过这样设置需要区分场景,比如某宝首页可以这么做。
互斥锁
为了避免出现缓存击穿的情况,我们可以在第一个请求去查询数据库的时候对他加一个互斥锁,其余的查询请求都会被阻塞住,直到锁被释放,后面的线程进来发现已经有缓存了,就直接走缓存,从而保护数据库。但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
十一、socket
WebSocket
一、WebSocket原理及运行机制与HTTP关系
WebSocket是HTML5下一种新的协议。它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的。它与HTTP一样通过已建立的TCP连接来传输数据,但是它和HTTP最大不同是:
WebSocket是一种双向通信协议。在建立连接后,WebSocket服务器端和客户端都能主动向对方发送或接收数据,就像Socket一样;
WebSocket需要像TCP一样,先建立连接,连接成功后才能相互通信。
相比HTTP长连接,WebSocket有以下特点:
是真正的全双工方式,建立连接后客户端与服务器端是完全平等的,可以互相主动请求。而HTTP长连接基于HTTP,是传统的客户端对服务器发起请求的模式。
HTTP长连接中,每次数据交换除了真正的数据部分外,服务器和客户端还要大量交换HTTP header,信息交换效率很低。Websocket协议通过第一个request建立了TCP连接之后,之后交换的数据都不需要发送 HTTP header就能交换数据,这显然和原有的HTTP协议有区别所以它需要对服务器和客户端都进行升级才能实现(主流浏览器都已支持HTML5)。此外还有 multiplexing、不同的URL可以复用同一个WebSocket连接等功能。这些都是HTTP长连接不能做到的。
WebSocket优势: 浏览器和服务器只需要要做一个握手的动作,在建立连接之后,双方可以在任意时刻,相互推送信息。同时,服务器与客户端之间交换的头信息很小。
二、WebSocket 相比普通的 TCP 长连接有什么优势?
首先需要指出WebSocket 本身就是 TCP 长连接应用的一种,那么WebSocket 和普通的 Socket 优势区别在哪?最大的区别就是普通的 Socket 就是基础的 Socket,没有规定传输协议,只是提供了最基本的数据传输功能,而 WebSocket 既是一种技术,更是一个 Socket 的应用层协议,它规定了两端之间数据传输的编码和解码方案,有了这个现有的方案,开发者只需要根据其设计出对应的实现,而不再需要自己去搞一套另外的协议。至于浏览器那个 WebSocket 对象,就是一个 WebSocket 协议的实现,使用者只需要调用它的 API 就可以使用 WebSocket 协议进行通讯。WebSocket 不止可以在浏览器上使用,在服务器或者其他类型的客户端也同样可以使用,只要有实现的软件包即可。
WebSocket 是应用层协议,tcp 是传输层协议。
websocket 本身是基于 tcp 实现的。
tcp 本身无所谓长短连接,理想状态下只要不 close,tcp 连接就一直存在(注意是理想)。
所谓的长连接本身是一条虚拟链路。
十二、Mqtt
消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与 HTTP 一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。
(1)MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的"轻量级"通讯协议,该协议构建于TCP/IP协议上,由IBM在1999年发布。MQTT最大优点在于,可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务。作为一种低开销、低带宽占用的即时通讯协议,使其在物联网、小型设备、移动应用等方面有较广泛的应用。
(2)MQTT是一个基于客户端-服务器的消息发布/订阅传输协议。MQTT协议是轻量、简单、开放和易于实现的,这些特点使它适用范围非常广泛。在很多情况下,包括受限的环境中,如:机器与机器(M2M)通信和物联网(IoT)。其在,通过卫星链路通信传感器、偶尔拨号的医疗设备、智能家居、及一些小型化设备中已广泛使用。

关键词
订阅 Subscription
订阅包含一个主体过滤器(Topic Filter)和一个最大的服务质量(Qos)等级。订阅和单个会话(Session)关联。会话可以包含多于一个的订阅。会话的每个订阅都有一个不同的主题过滤器。
主题名 Topic Name
附加在应用消息上的一个标签,服务端已知且与订阅匹配。服务端发送应用消息的一个副本给每一个匹配的客户端订阅。
主题过滤器 Topic Filter
订阅中包含的一个表达式,用于表示相关的一个或多个主题。主题过滤器可以使用通配符。
会话 Session
客户端和服务端之间的状态交互。一些会话持续时长与网络连接一样,另一些可以在客户端和服务端的多个连续网络连接间扩展。
控制报文 MQTT Control Packet
通过网络连接发送的信息数据包。类似于ICMP,MQTT规范定义了十四种不同类型的控制报文,其中一个(PUBLISH报文)用于传输应用消息。
服务器 Broker
在消息订阅模型中充当服务器的角色, 类似于送信的邮差。
Qos 消息服务质量机制
通过使用Qos机制,来保证通信的质量,也就是发送connect报文的次数时间,有以下几种情况:
QoS0: “至多1次”
消息发布完全依赖底层TCP/IP网络。会发生消息丢失或重复。1次发送失败后,不再重新发送。
这一级别可用于如下情况,环境传感器数据,丢失一次读记录无所谓,因为不久后还会有第二次发送。这一种方式主要普通APP的推送,倘若你的智能设备在消息推送时未联网,推送过去没收到,再次联网也就收不到了。
QoS1:“至少1次”
确保信息到达,发送1次对方没有确认接收后,会重新发送,但是可能会出现多次接收的情况。
QoS2:“至多一次”
确保信息到达1次且仅到达1次。在一些要求比较严格的计费系统中,可以使用此级别。在计费系统中,消息重复或丢失会导致不正确的结果。这种最高质量的消息发布服务还可以用于即时通讯类的APP的推送,确保用户收到且只会收到1次。
MQTT协议中的通信过程
建立连接
在建立连接时,首先客户端往服务器发送CONNECT连接建立报文。
规定在网络连接建立后,客户端发送给服务端的第一个报文必须是CONNECT报文。
在一个网络连接上,客户端只能发送一次CONNECT报文。服务端必须将客户端发送的第二个CONNECT报文当作协议违规处理并断开客户端的连接。在这个报文中包含了遗嘱信息、keep alive等标志位。
在服务器接收到CONNECT报文后,服务端发送CONNACK报文响应从客户端收到的CONNECT报文。服务端发送给客户端的第一个报文必须是CONNACK。
如果客户端在合理的时间内没有收到服务端的CONNACK报文,客户端应该关闭网络连接。合理的时间取决于应用的类型和通信基础设施。
在CONNACK报文中,主要包含连接确认标志和返回码,但是不包含有效载荷。

发送信息流程
在发送信息的流程中主要有几种报文:
PUBLISH – 发布消息:
PUBLISH控制报文是指从客户端向服务端或者服务端向客户端传输一个应用消息。在信息中主要的标志位是DUP(重发标志位)、QoS(服务质量标识)、Topic Nmae(主题名)等。
有了PUBLISH报文后,就可以发送QoS为0的报文:
对于QoS为0的情况,发起方在发送PUBLIC 报文后便由Broker发送给接收方,中间不再做任何处理。
对于QoS为1的报文,还需要另外1个报文类型参与:
PUBACK –发布确认:
PUBACK报文是对QoS 1等级的PUBLISH报文的响应。
有了PUBACK报文后,就可以完成QoS为1 的报文发送。
对于QoS为1的情况,发起方在发送PUBLIC 报文后便由Broker发送给接收方,接收方收到后,会回复PUBACK报文,具体流程如图:
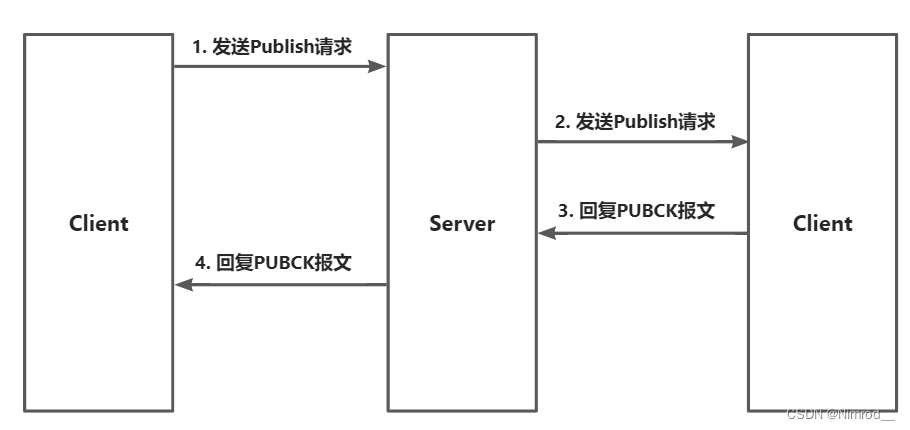
要实现QoS为2的信息发布,还需要另外3个报文:
PUBREC – 发布收到(QoS 2,第一步)
PUBREC报文是对QoS等级2的PUBLISH报文的响应。它是QoS 2等级协议交换的第二个报文。
PUBREL – 发布释放(QoS 2,第二步)
PUBREL报文是对PUBREC报文的响应。它是QoS 2等级协议交换的第三个报文。
PUBCOMP – 发布完成(QoS 2,第三步)
PUBCOMP报文是对PUBREL报文的响应。它是QoS 2等级协议交换的第四个也是最后一个报文。
对于QoS为2的信息发布,需要:
- 发送方发送PUBLIC报文
- 接收方接收到PUBLIC后回复PUBREC报文
- 发送方接收到PUBREC报文回复PUBREL报文
- 接收方接收到PUBREL后回复PUBCOMP报文
结束。
对于QoS为2的流程,明显多了几个步骤,因此对于该类型的信息发布有较多的流量消耗。
具体流程见图:
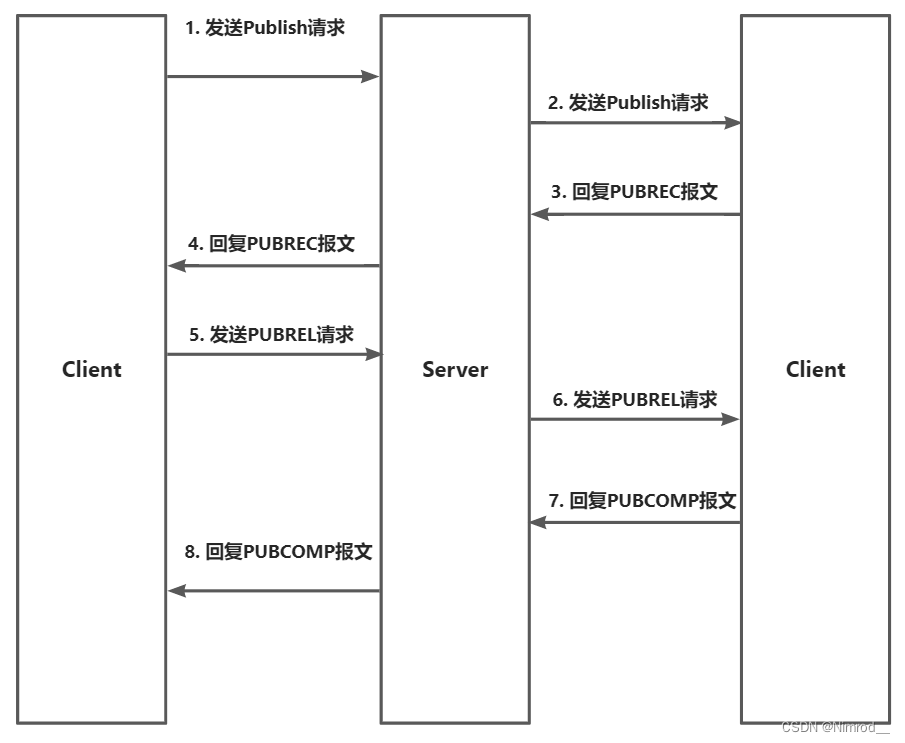
消息订阅流程
订阅相关报文:
SUBSCRIBE - 订阅主题
客户端向服务端发送SUBSCRIBE报文用于创建一个或多个订阅。
每个订阅注册客户端关心的一个或多个主题。 SUBSCRIBE报文也(为每个订阅)指定了最大的QoS等级,服务端根据QoS等级发送应用消息给客户端。
其主题相关数据放在了有效载荷上,并且还包含一个主题过滤器列表。
SUBACK – 订阅确认
在接收到SUBCRIBE报文后,服务端发送SUBACK报文给客户端,用于确认它已收到并且正在处理SUBSCRIBE报文。
SUBACK报文包含一个返回码清单,允许的返回码值:
0x00 - 最大QoS 0
0x01 - 成功 – 最大QoS 1
0x02 - 成功 – 最大 QoS 2
0x80 - Failure 失败
它们指定了SUBSCRIBE请求的每个订阅被授予的最大QoS等级。
订阅完成后客户端需要传输对应的信息时,会在信息上添加上主题,添加后通过PUBLIC 发送到服务端,服务端再根据主题与订阅情况发送给对应的客户端。
基于以上两个报文,订阅的流程如下:
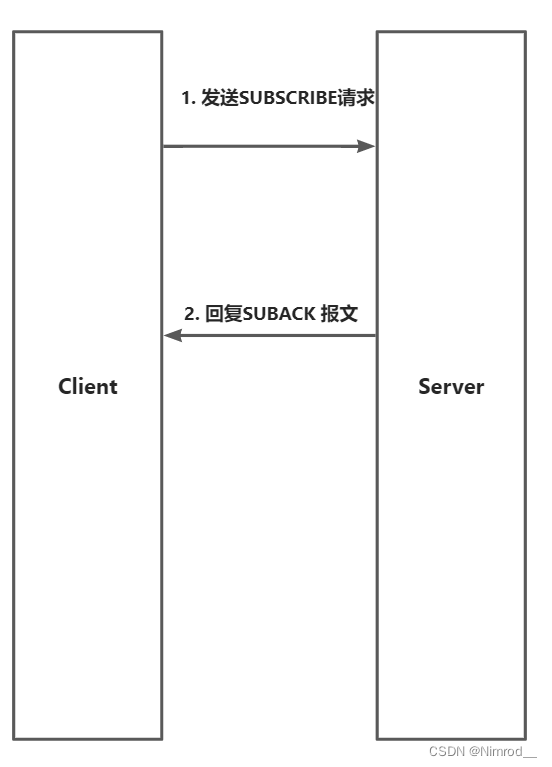
同样的,有了订阅流程便还有取消订阅流程,相关的有两个报文:
UNSUBSCRIBE –取消订阅
客户端发送UNSUBSCRIBE报文给服务端,用于取消订阅主题。
关于想要取消的订阅主题列表在有效载荷中,且规定取消订阅主题必须至少包含1个取消订阅主题。
UNSUBACK – 取消订阅确认
服务端收到UNSUBSCRIBE报文后,发送UNSUBACK报文给客户端用于确认收到UNSUBSCRIBE报文。
对于取消订阅确认报文,没有有效载荷。
流程跟订阅类似:

Too many publishes in progress异常
在使用paho的包批量发送mqtt消息(QOS为0)时,跑了一定的时间后就会报错Too many publishes in progress (32202)。
所使用包
<!-- https://mvnrepository.com/artifact/org.eclipse.paho/org.eclipse.paho.client.mqttv3 -->
<dependency>
<groupId>org.eclipse.paho</groupId>
<artifactId>org.eclipse.paho.client.mqttv3</artifactId>
<version>1.2.0</version>
</dependency>
报错地方
if (message instanceof MqttPublish) {
synchronized (queueLock) {
if (actualInFlight >= this.maxInflight) {
//@TRACE 613= sending {0} msgs at max inflight window
log.fine(CLASS_NAME, methodName, "613", new Object[]{new Integer(actualInFlight)});
throw new MqttException(MqttException.REASON_CODE_MAX_INFLIGHT);
}
......
当检查到actualInFlight大于maxInflight时,会报Too many publishes in progress (32202)
尝试将maxInflight值设大,但依旧会报错。
观察源码的发布流程
当调用MqttClient的publish方法时,并没有真正的发布消息,而是检查是否可以发布消息(actualInFlight小于maxInflight),如果可以则将消息放进pendingMessages。
if (message instanceof MqttPublish) {
synchronized (queueLock) {
if (actualInFlight >= this.maxInflight) {
throw new MqttException(MqttException.REASON_CODE_MAX_INFLIGHT);
}
MqttMessage innerMessage = ((MqttPublish) message).getMessage();
······
tokenStore.saveToken(token, message);
pendingMessages.addElement(message);
queueLock.notifyAll();
······
实际上是谁在处理pendingMessages队列里的消息呢
跟踪MqttClient的connect方法,实际会启动一个ConnectBG
ConnectBG conbg = new ConnectBG(this, token, connect, executorService);
conbg.start();
ConnectBG conbg = new ConnectBG(this, token, connect, executorService);
conbg.start();
观察ConnectBG的run方法
sender = new CommsSender(clientComms, clientState, tokenStore, networkModule.getOutputStream());
sender.start("MQTT Snd: "+getClient().getClientId(), executorService);
sender = new CommsSender(clientComms, clientState, tokenStore, networkModule.getOutputStream());
sender.start("MQTT Snd: "+getClient().getClientId(), executorService);
发现会启用一个单独的线程去消费pendingMessages里的消息,发送到MQTT服务器
public void run() {
public void run() {
.....
message = clientState.get();
if (message != null) {
.....
MqttToken token = tokenStore.getToken(message);
if (token != null) {
synchronized (token) {
out.write(message);
try {
out.flush();
} catch (IOException ex) {
if (!(message instanceof MqttDisconnect)) {
throw ex;
}
}
clientState.notifySent(message);
}
}
.....
}
- clientState.get()中会从pendingMessages中取一个消息,并使actualInFlight+1
- 在发送完消息后,clientState.notifySent(message)会判断如果QOS为0,则actualInFlight-1,不需要等待服务器回复。
以并发发送QOS为0的消息场景来说,在Sender线程中,会先从队列里取消息,actualInFlight+1,发送,然后actualInFlight-1,并且Sender线程是单线程的,理论上actualInFlight应该永远为0,不可能会超过maxInflight的
开启日志调试
实际上paho的源码里是有很多日志输出,于是想打开日志看看问题出在哪里
日志配置方法:https://blog.csdn.net/lblblblblzdx/article/details/81136922
- 在日志中搜索actualInFlight
发现actualInFlight会经历多次+1,才会经历一次-1 - 观察actualInFlight+1和下一次actualInFlight+1之间经历了什么
当sender从pendingMessages取出消息后,actualInFlight+1,message不为空,打印key=0和message
紧接着,sender又从pendingMessages取出消息后,actualInFlight+1
初步判断,sender获取消息后因为某些原因报错了或者某些判断条件没有执行下去,导致没有了后面应有的日志。 - 观察actualInFlight+1和下一次actualInFlight-1之间经历了什么
当sender从pendingMessages取出消息后,actualInFlight+1,message不为空,打印key=0和message
中间夹杂着许多次MqttClient的publish方法调用,然后是send,然后是saveToken
紧接着sender使actualInFlight-1,然后是removeToken - 从日志或者代码都可以知道QOS=0时key都为0,而tokens是存在一个map里,并发发送QOS=0的消息时,多次saveToken其实都只成功往tokens里放进一个值,但只要sender发送一次消息,就会removeToken,导致发送第二条QOS为0的消息时,获取不到token,直接放弃发送。
saveToken方法
protected void saveToken(MqttToken token, String key) {
final String methodName = "saveToken";
synchronized(tokens) {
//@TRACE 307=key={0} token={1}
log.fine(CLASS_NAME,methodName,"307",new Object[]{key,token.toString()});
token.internalTok.setKey(key);
this.tokens.put(key, token);
}
}
Sender的发送逻辑
MqttToken token = tokenStore.getToken(message);
// Whilequiescing the tokenstore can be cleared so need
// to check for null for the case where clear occurs
// while trying to send a message.
if (token != null) {
synchronized (token) {
out.write(message);
try {
out.flush();
} catch (IOException ex) {
// The flush has been seen to fail on disconnect of a SSL socket
// as disconnect is in progress this should not be treated as an error
if (!(message instanceof MqttDisconnect)) {
throw ex;
}
}
clientState.notifySent(message);
}
}
结论
从以上过程中可得出结论,并发发送QOS=0的消息时,多次将消息加到pendingMessages队列并saveToken后,假若此时Sender线程获取到CPU资源,从pendingMessages队列获取消息并removeToken后,就会导致pendingMessages队列里其余消息获取不到token,导致发送失败,最终导致actualInFlight越来越大,程序报错Too many publishes in progress (32202)
解决方案
使用QOS=1















 3448
3448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









