







Flink是新的stream计算引擎,用java实现。既可以处理stream data也可以处理batch data,可以同时兼顾Spark以及Spark streaming的功能,与Spark不同的是,Flink本质上只有stream的概念,batch被认为是special stream。Flink在运行中主要有三个组件组成,JobClient,JobManager 和 TaskManager。主要工作原理如下图
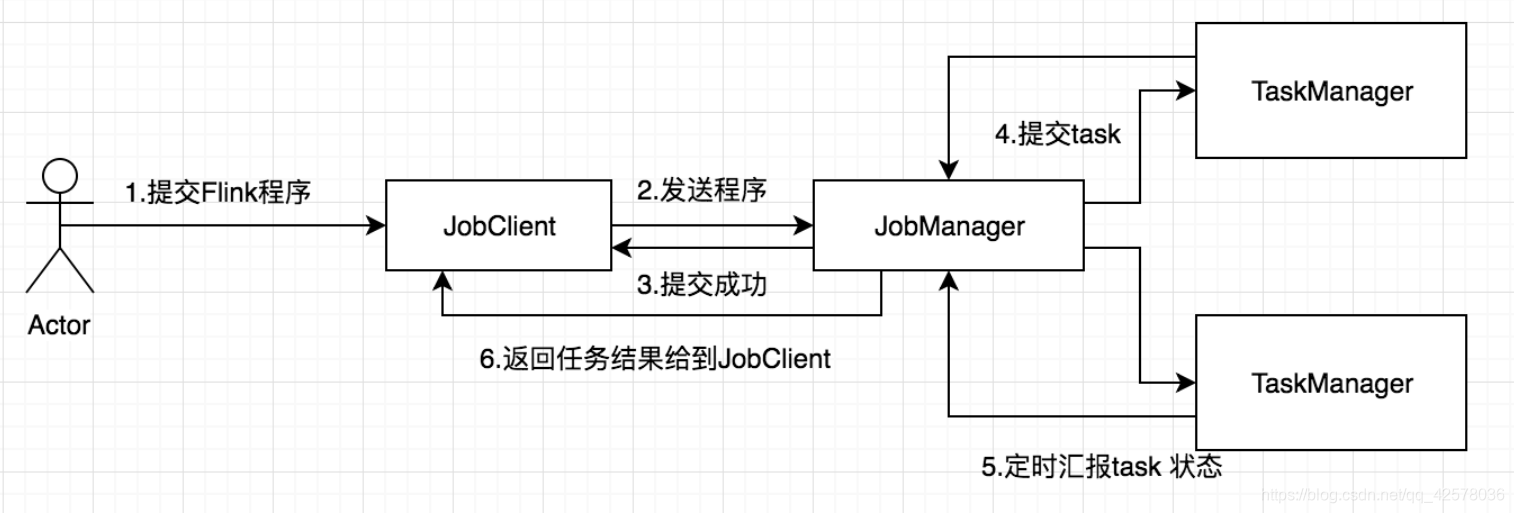
用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化提交到JobManager,最后由TaskManager运行task
JobClient
JobClient是Flink程序和JobManager交互的桥梁,主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。为了了解Flink的解析过程,需要简单介绍一下Flink的Operator,在Flink主要有三类Operator
- Source Operator:顾名思义这类操作一般是数据来源操作,比如文件、socket、kafka等,一般存在于程序的最开始
- Transformation Operator :这类操作主要负责数据转换,map,flatMap,reduce等算子都属于Transformation Operator,
- Sink Operator:意思是下沉操作,这类操作一般是数据落地,数据存储的过程,放在Job最后,比如数据落地到Hdfs、Mysql、Kafka等等
Flink会将程序中每一个算计解析成Operator,然后按照算子之间的关系,将operator组合起来,形成一个Operator组合成的Graph。如下面的代码解析之后形成的执行计划
DataStream<String> data = env.addSource(...);
data.map(x->new Tuple2(x,1)).keyBy(0).timeWindow(Time.seconds(60)).sum(1).addSink(...)

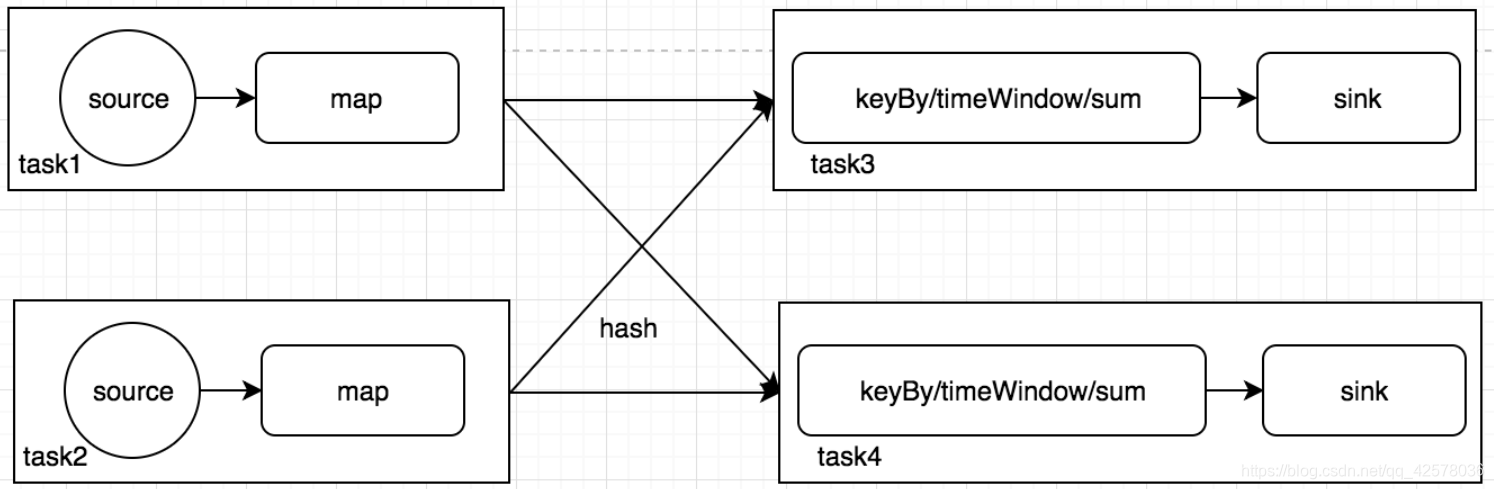
解析形成执行计划之后,JobClient的任务还没有完,还负责执行计划的优化,这里执行的主要优化是将相邻的Operator融合,形成OperatorChain,因为Flink是分布式运行的,程序中每一个算子,在实际执行中被分隔为多个SubTask,数据流在算子之间的流动,就对应到SubTask之间的数据传递,SubTask之间进行数据传递模式有两种一种是one-to-one的,数据不需要重新分布,也就是数据不需要经过IO,节点本地就能完成,比如上图中的source到map,一种是re-distributed,数据需要通过shuffle过程重新分区,需要经过IO,比如上图中的map到keyBy。显然re-distributed这种模式更加浪费时间,同时影响整个Job的性能。所以,Flink为了提高性能,将one-to-one关系的前后两类subtask,融合形成一个task。而TaskManager中一个task运行一个独立的线程中,同一个线程中的SubTask进行数据传递,不需要经过IO,不需要经过序列化,直接发送数据对象到下一个SubTask,性能得到提升,除此之外,subTask的融合可以减少task的数量,提高taskManager的资源利用率。图1.0中的执行计划,优化结果如下图,Flink的subTask融合规则可以参考官方文档。
- 值得注意的是,并不是每一个SubTask都可以被融合,对于不能融合的SubTask会独立形成一个Task运行在TaskManager中
- 改变operator的并行度,可能会导致不同的优化结果,同时这也是性能调优的一个重要方式,例如不显式设置operator的并行度的时候,默认所有算子的并行度是一样的,所以会有下图中的优化结果

我们来分析一下默认情况下可能发生的问题,假如设置作业的并行度为10,source明确为kafka,对应topic只有一个topic,因为source默认会根据topic的分区数,决定自己的分区数,那么10个source subtask只有一个会工作,而且任务比较重。这样会导致后面的map实际也是有一个subTask在工作,处理所有的数据,假如map中的任务比较重,那么会导致数据倾斜,性能低下。在source不能改造的情况下,我们显式减少source的并行度(为了节省资源,设置1),提高map的并行度(增加处理速度,设为20)。第一眼看上去,感觉性能提升了不少,但是在实际情况中却不一定这样。因为调整source和map的并发度, 失去了原有one-to-one数据传递的优势,导致subTask不能融合,数据需要reblance,产生大量的IO,所以修改并行度也不一定可以提升性能。修改并行度之后,执行计划的优化结果如下图。所以在实际优化的过程中,还是要注意结合数据分布和执行计划调优,理解Flink执行计划的生成过程很有必要
JobManager
JobManager是一个进程,主要负责申请资源,协调以及控制整个job的执行过程,具体包括,调度任务、处理checkpoint、容错等等,在接收到JobClient提交的执行计划之后,针对收到的执行计划,继续解析,因为JobClient只是形成一个operaor层面的执行计划,所以JobManager继续解析执行计划(根据算子的并发度,划分task),形成一个可以被实际调度的由task组成的拓扑图,如上图被解析之后形成下图的执行计划,最后向集群申请资源,一旦资源就绪,就调度task到TaskManager。
为了保证高可用,一般会有多个JobManager进程同时存在,它们之间也是采用主从模式,一个进程被选举为Leader,其他进程为follower。Job运行期间,只有Leader在工作,follower在闲置,一旦Leader挂掉,随即引发一次选举,产生新的Leader继续处理Job。JobManager除了调度任务,另外一个主要工作就是容错,主要依靠checkpoint进行容错,checkpoint其实是stream以及executor(TaskManager中的Slot)的快照,一般将checkpoint保存在可靠的存储中(比如hdfs),为了容错Flink会持续建立这类快照。当Flink作业重新启动的时候,会寻找最新可用的checkpoint来恢复执行状态,已达到数据不丢失,不重复,准确被处理一次的语义。一般情况下,都不会用到checkpoint,只有在数据需要积累或处理历史状态的时候,才需要设定checkpoint,比如updateStateByKey这个算子,默认会启用checkpoint,如果没有配置checkpoint目录的话,程序会抛异常。
TaskManager
TaskManager是一个进程,及一个JVM(Flink用java实现)。主要作用是接收并执行JobManager发送的task,并且与JobManager通信,反馈任务状态信息,比如任务分执行中,执行完等状态,上文提到的checkpoint的部分信息也是TaskManager反馈给JobManager的。如果说JobManager是master的话,那么TaskManager就是worker主要用来执行任务。在TaskManager内可以运行多个task。多个task运行在一个JVM内有几个好处,首先task可以通过多路复用的方式TCP连接,其次task可以共享节点之间的心跳信息,减少了网络传输。TaskManager并不是最细粒度的概念,每个TaskManager像一个容器一样,包含一个多或多个Slot
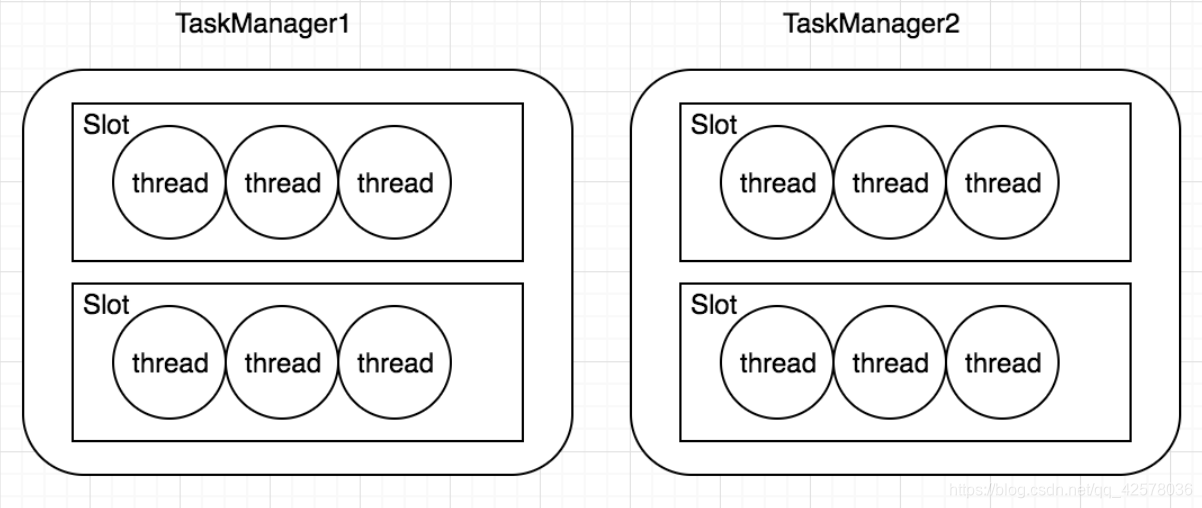
Slot
Slot是TaskManager资源粒度的划分,每个Slot都有自己独立的内存。所有Slot平均分配TaskManger的内存,比如TaskManager分配给Solt的内存为8G,两个Slot,每个Slot的内存为4G,四个Slot,每个Slot的内存为2G,值得注意的是,Slot仅划分内存,不涉及cpu的划分。同时Slot是Flink中的任务执行器(类似Storm中Executor),每个Slot可以运行多个task,而且一个task会以单独的线程来运行。Slot主要的好处有以下几点:
- 可以起到隔离内存的作用,防止多个不同job的task竞争内存。
- Slot的个数就代表了一个Flink程序的最高并行度,简化了性能调优的过程
- 允许多个Task共享Slot,提升了资源利用率,举一个实际的例子,kafka有3个partition,对应flink的source有3个task,而keyBy- 我们设置的并行度为20,这个时候如果Slot不能共享的话,需要占用23个Slot,如果允许共享的话,那么只需要20个Slot即可(Slot的默认共享规则计算为20个)
共享Slot,虽然在flink中允许task共享Slot提升资源利用率,但是如果一个Slot中容纳过多task反而会造成资源低下(比如极端情况下所有task都分布在一个Slot内),在Flink中task需要按照一定规则共享Slot。共享Slot的方式有两种,SlotShardingGroup和CoLocationGroup,CoLocationGroup这种方式目前还没有接触过,如果感兴趣可以查阅官方文档。下面主要介绍一下SlotShardingGroup的用法,这种共享的基本思路就是给operator分组,同一组的不同operator的task,可以共享一个Slot。默认所有的operator属于同一个组“default”,及所有operator的task可以共享一个Slot,可以给operator设置不同的group,防止不合理的共享。Flink在调度task分配Slot的时候有两个重要原则:
- 同一个job中,同一个group中不同operator的task可以共享一个Slot
- Flink是按照拓扑顺序从Source依次调度到Sink的














 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









