







摘要
HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap的元素存取过程基本与HashMap基本类似,只是在细节实现上稍有不同。当然,这是由LinkedHashMap本身的特性所决定的,因为它额外维护了一个双向链表用于保持迭代顺序。此外,LinkedHashMap可以很好的支持LRU算法。
LinkedHashMap概述
HashMap是Java Collection Framework的重要成员,也是Map族中我们最为常用的一种。不过遗憾的是,HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类----LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别的,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap和保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
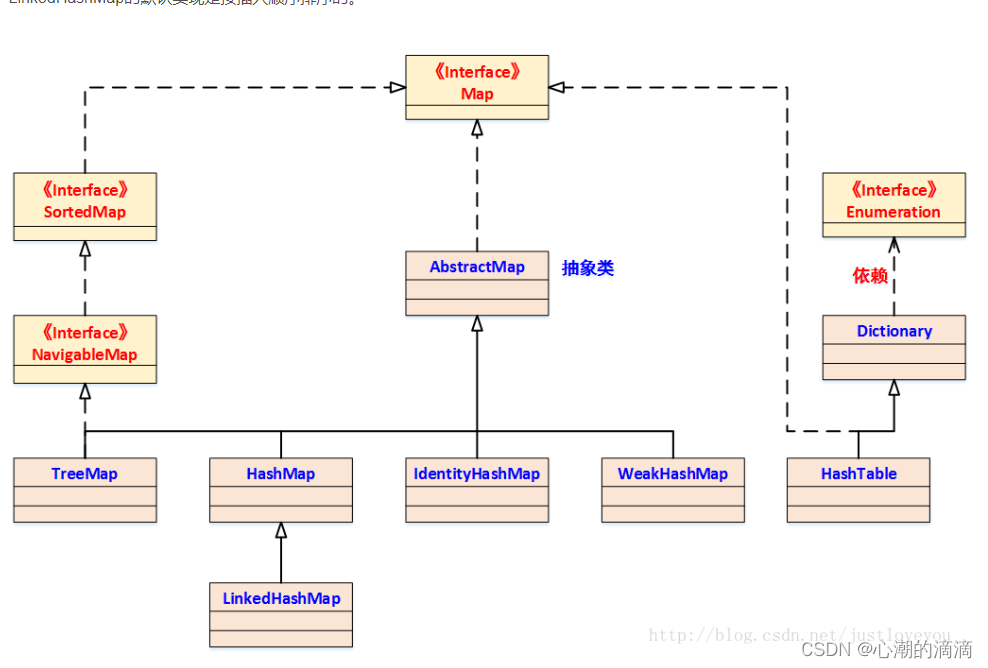
LinkedHashMap在JDK中的定义
1. 类结构定义
LinkedHashMap继承HashMap,其在JDK中的定义为:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
}
2. 成员变量定义
与HashMap相比,LinkedHashMap增加了两个属性用于保持迭代顺序,分别是双向链表头结点header和标志位accessOrder(值为true时),表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代
/**
* The head (eldest) of the doubly linked list.
* 双向链表的表头元素
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
* 双向链表的表尾元素
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* true表示按照访问顺序迭代,false时表示按照插入顺序
* @serial
*/
final boolean accessOrder;
LinkedHashMap的构造函数
LinkedHashMap一共提供了五个构造函数,它们都是在HashMap的构造函数的基础上实现的,分别如下
1. LinkedHashMap()
该构造函数意在构造一个具有默认初始容量(16)和默认负载因子(0.75)的空LinkedHashMap,是Java Collection Framework规范推荐提供的,其源码如下:
public LinkedHashMap() {
super();
accessOrder = false;
}
2. LinkedHashMap(int initialCapacity, float loadFactor)
该构造函数意在构造一个指定初始容量和指定负载因子的空LinkedHashMap,其源码如下
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
3. LinkedHashMap(int initialCapacity)
该构造函数意在构造一个指定初始容量和默认负载因子(0.75)的空LinkedHashMap,其源码如下:
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
4. LinkedHashMap(Map<? extends K, ? extends V> m)
该构造函数意在构造一个与指定Map具有相同映射的LinkedHashMap,其初始容量不小于16(具体依赖于指定Map的大小),负载因子是0.75,是Java Collection Framework规范推荐提供的
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(); // 调用HashMap对应的构造函数
accessOrder = false; // 迭代顺序的默认值
putMapEntries(m, false);
}
5. LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
该构造函数意在构造一个指定初始容量和指定负载因子的具有指定迭代顺序的LinkedHashMap,其源码如下:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap的快速存取
1. LinkedHashMap的扩容操作:resize()
在HashMap中,我们知道随着HashMap中元素的数量越来越多,发生碰撞的概率将越来越大,所产生的子链长度就会越来越长,这样势必会影响HashMap的存取速度。为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理,该临界点就是HashMap中元素的数量在数值上等于threshold(table数组长度*加载因子)。但是,不得不说,扩容是一个非常耗时的过程,因为它需要重新计算这些元素在新table数组中的位置并进行复制处理。所以,如果我们能够提前预知HashMap中元素的个数,那么在构造HashMap时预设元素的个数能够有效的提高HashMap的性能
同样的问题也存在与LinkedHashMap中,因为LinkedHashMap本来就是一个HashMap,只是它还将所有Entry节点链入到了一个双向链表中。LinkedHashMap完全继承了HashMap的resize()方法,只是对它所调用的transfer方法进行了重写
从上面代码中我们可以看出,Map扩容操作的核心在于重哈希。所谓重哈希是指重新计算原HashMap中的元素在新table数组中的位置并进行复制处理的过程。鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对重哈希过程(transfer方法)进行了重写
LinkedHashMap与LRU(Least recently used,最近最少使用)算法
到此为止,我们已经分析完了LinkedHashMap的存取实现,这与HashMap大体相同。LinkedHashMap区别于HashMap最大的一个不同点是,前者是有序的,后者是无序的。为此,LinkedHashMap增加了两个属性用于保证顺序,分别是双向链表头结点header和标志位accessOrder。我们知道,header是LinkedHashMap所维护的双向链表的头结点,而accessOrder用于决定具体的迭代顺序。实际上,accessOrder标志位的作用可不像我们描述的这样简单
使用LinkedHashMap实现LRU算法
public class LinkedHashMapDemo {
public static void main(String[] args) {
LRU<Character, Integer> lru = new LRU<>(16, 0.75f, true);
String s = "abcdefhijkl";
for (int i = 0, len = s.length(); i < len; i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为:" + lru.get('h'));
System.out.println("LRU的大小:" + lru.size());
System.out.println("LRU: " + lru);
}
}
// 使用LinkedHashMap实现一个符合LRU算法的数据结构,该结构最多可以缓存6个元素,但元素多余六个时,会自动删除最近最久没有被使用的元素
class LRU<K, V> extends LinkedHashMap<K, V> implements Map<K, V> {
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* 重写LinkedHashMap中的removeEldestEntry方法,当LRU中元素多余6个时,删除最不经常使用的元素
* @author Fang Ruichuan
* @date 2022/9/17 15:48
* @param eldest
* @return boolean
*/
@Override
protected boolean removeEldestEntry(Entry<K, V> eldest) {
if (size() > 6) {
return true;
}
return false;
}
}
运行结果:
LRU中key为h的Entry的值为:6
LRU的大小:6
LRU: {f=5, i=7, j=8, k=9, l=10, h=6}















 1392
1392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









