







在复习JUC之前,先搞明白什么情况下才能线程安全,也就是线程安全所具备的条件
- 原子性
- 有序性
- 可见性
那从上面这几个角度来考虑Synchronized和volatile的区别?
- Synchronized可以保证原子性,有序性,可见性
- volatile可以保证有序性和可见性,但是不能保证原子性
还有一种类是绝对安全的,它就是不可变类(immutable),它的不可变也就意味着不能进行写操作,那自然是安全的了。
先说说final,它可以修饰变量,变量的值为不可变,不过仅仅是于简单类型。如果是一个复杂类型的话,final就不能防止其内部的操作了,如下例子所示
@Slf4j
@NotThreadSafe
public class Immutable1 {
private final static Integer a = 1;
private final static String b = "2";
private final static Map<Integer, Integer> map = Maps.newHashMap();
static {
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
}
public static void main(String[] args) {
// a=2; 不可以赋值
// map = Maps.newHashMap(); 这个引用不能指向其他对象
map.put(1, 3);
log.info("{}", map.get(1));
}
结果如下

对于Integer是不能进行赋值操作的,可以看到final对于引用类型的变量是锁住了那个引用类型的地址。
那怎么可以实现对象的不可变呢?
对于集合来说可以调用Collections里面的不可变方法,如下代码
@Slf4j
@ThreadSafe
public class Immutable2 {
private final static Integer a = 1;
private final static String b = "2";
private static Map<Integer, Integer> map = null;
static {
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
//使用Collections.unmodifiableMap()生成不可变对象
map = Collections.unmodifiableMap(map);
}
public static void main(String[] args) {
//如果强制进行put就会报错
map.put(1, 3);
log.info("{}", map.get(1));
}
}
可以看到出现了异常,对于不可变对象也可以使用第三方的工具包等

也就是说volatile是一种辅助锁进行工作的一种机制!它并不能代替锁来保证多线程环境下的线程安全
下面是我从网上找到的一份JUC的图,下面就按照这个图来进行复习
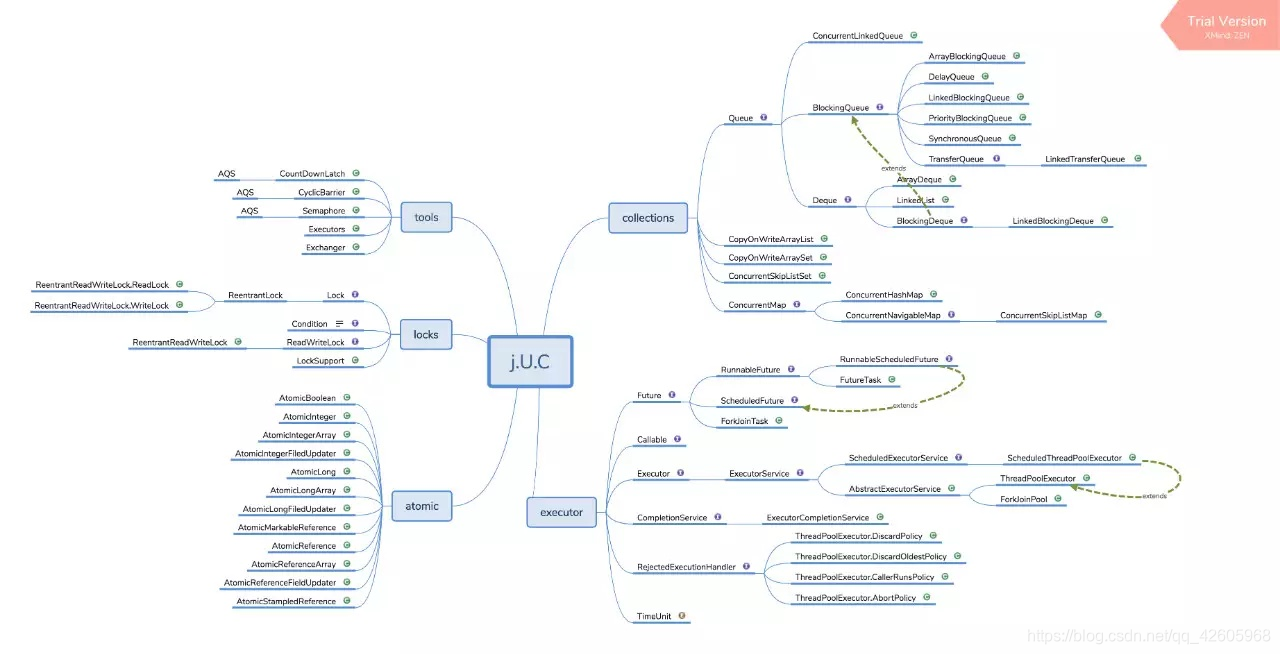
可以从图中看到JUC下主要分为五大部分
- collections
- atomic
- locks
- tools
- executor
但是实际上的JUC包不是这样的,这样只是为了模块分类
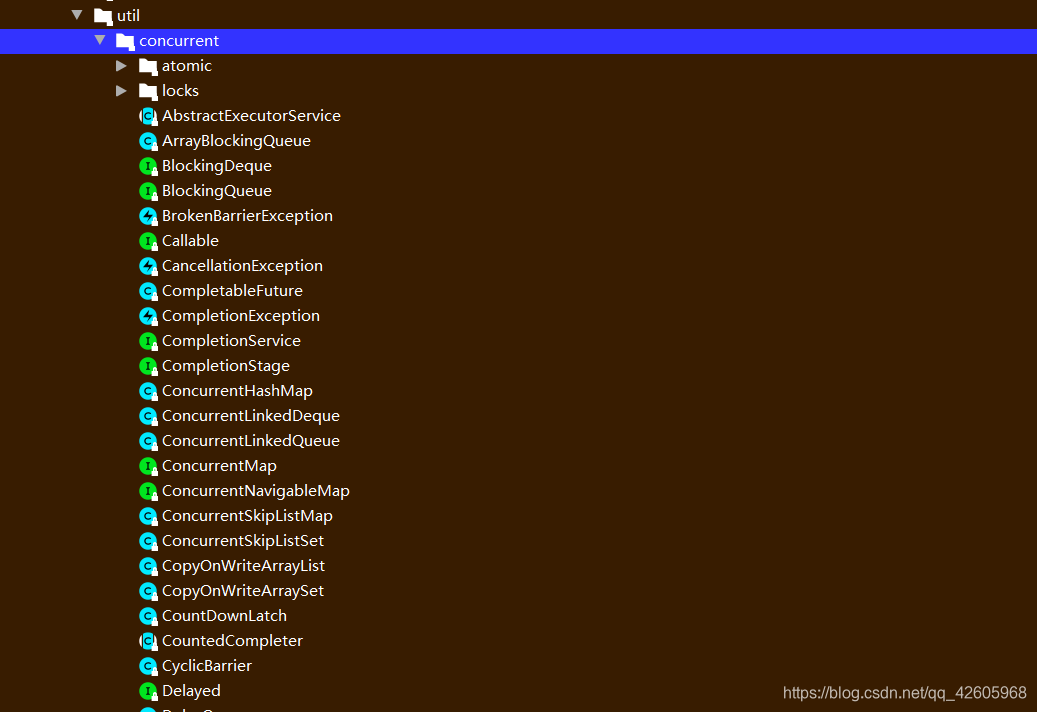
下面就按照逻辑模块来复习其中的重点
Collections
在Collections模块中,比较常见的的几个集合有
大体的分可以分为Concurrentxxx,Blockxxx,CopyOnWritexxx
- Concurrent开头的一般都是弱一致性的容器(fail-fast),比如统计size的准确度是有限的,没有像COW一样的修改开销
- Blocking中典型的就是阻塞队列,如ArrayBlockingQueue(有界),LinkedBlockingQueue(内部逻辑是根据有界来编写的),PriorityBlockingQueue
- CopyOnWrite:利用快照技术,写时复制
下面就挑里面典型的来说一说
CurrentHashMap的基本原理
在CurrentHashMap中采用的CAS+锁来保证的线程安全。它的默认容量和负载因子,树形化,剪枝基本都和HashMap相同。它与JDK7不同的是它不再采用分段锁,而是采用的bucket锁,缩小的锁的粒度,它把锁放在了头部,从而保证每个bucket的线程安全
下面以put为例
在了解put前需要了解几个变量
static final int MOVED = -1; // 标志证在扩容
static final int TREEBIN = -2; // 标志是树
private transient volatile int sizeCtl; // -1代表初始化,-N代表有N-1个线程正在扩容 正数/0表示没有被初始化
//put
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 1.合法性检测
if (key == null || value == null) throw new NullPointerException();
// 2.对key进行位干扰,目的是为了让hash更均匀
int hash = spread(key.hashCode());
int binCount = 0;
// 遍历哈希表 table就是Node数组,可以把数组的每个元素看为一个bucket
for (ConcurrentHashMap.Node<K,V>[] tab = table;;) {
ConcurrentHashMap.Node<K,V> f; int n, i, fh;
// 3.如果table未初始化,就进行初始化
if (tab == null || (n = tab.length) == 0)
// 初始化根据sizeCtl和循环CAS来进行的
tab = initTable();
// 4.如果该bucket为null就是要以CAS无锁方式进行put i = (n - 1) & hash是用来取模
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new ConcurrentHashMap.Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 5.如果正在扩容,就加快转移
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 锁住头
synchronized (f) {
// 6.如果是链表就遍历如果重复key就替换否则就尾插 并记录binCount
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (ConcurrentHashMap.Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
ConcurrentHashMap.Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new ConcurrentHashMap.Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 7.如果是树,就替换value或插入新的节点
else if (f instanceof ConcurrentHashMap.TreeBin) {
ConcurrentHashMap.Node<K,V> p;
binCount = 2;
if ((p = ((ConcurrentHashMap.TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 8.如果binCount到达率树形化的阈值就进行树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// 9.如果是替换操作就返回value
if (oldVal != null)
return oldVal;
break;
}
}
}
// 10.如果是添加Node,就给节点数+1,,并检查是否需要扩容,需要扩容就帮助扩容(增加线程)
addCount(1L, binCount);
return null;
}
initTable()方法
/**
* Initializes table, using the size recorded in sizeCtl.
*/
// 进行table初始化操作
private final ConcurrentHashMap.Node<K,V>[] initTable() {
ConcurrentHashMap.Node<K,V>[] tab; int sc;
// 1.循环进行初始化
while ((tab = table) == null || tab.length == 0) {
// 2.如果有线程去处理了就不管了,说明其他CAS已经成功,让出cpu
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 3.没有进行初始化就CAS操作,如果满足就进入
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 4. 根据默认容量进行初始化
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
ConcurrentHashMap.Node<K,V>[] nt = (ConcurrentHashMap.Node<K,V>[])new ConcurrentHashMap.Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
Blocking
阻塞队列一般可以用于生产者消费者模型中去,比如下面的例子
package com.wrial.main.example.collection;
/*
* @Author Wrial
* @Date Created in 12:06 2020/3/20
* @Description 使用阻塞队列实现生产者消费者模型
*/
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ConsumerAndProductorByBlockQueue {
private static ArrayBlockingQueue queue = new ArrayBlockingQueue(3);
public static void main(String[] args) {
Consumer consumer = new Consumer(queue);
Productor productor = new Productor(queue);
new Thread(consumer).start();
new Thread(productor).start();
}
static class Consumer implements Runnable {
private BlockingQueue queue;
Consumer(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 0; i < 10; i++) {
Thread.sleep(3000);
queue.put(i);
System.out.println("put->" + i);
}
//100标志结束
queue.put(100);
System.out.println("put结束标志" + 100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
static class Productor implements Runnable {
private BlockingQueue queue;
Productor(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
int i;
try {
while ((i = (int) queue.take()) != 100) {
System.out.println("take->" + i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}

CopyOnWrite
翻译过来就是就是写时复制, 在往集合中添加数据的时候,先拷贝存储的数组,然后添加元素到拷贝好的数组中,然后用现在的数组去替换成员变量的数组,由此可以看到它必然会很费时,在写的多的不建议使用它相关的。
锁相关
在开始正题之前,先了解一下Synchronized,AQS,Lock之间的关系
- Synchronized是JVM层面的锁,是程序员不可控的,它会有自己的锁膨胀机制
- AQS是一个同步器,比如在下面说的这些同步工具基本都是基于AQS的
- Lock是程序级别的锁的接口,提供tryLock,lock,unlock,newCondition等方法,可以和AQS实现ReentrantLock
说到JUC的锁必然是不能少了Lock接口,Lock接口规定了程序锁的规范
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
实现Lock接口的类也有很多ReentrantLock(可重入锁),ReadWriteLock(读写分离锁),StampedLock(可以看做是对读写锁的改进)等等
使用Lock自定义一个简单锁
package com.wrial.main.example.myLock;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* 定义一个自己的锁
*/
public class Mylock1 implements Lock {
private boolean isLock = false;
//为了处理多线程,加上Synchronized
@Override
public synchronized void lock() {
//不能用if,使用while自旋
while (isLock) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
isLock = true;
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
}
@Override
public synchronized void unlock() {
isLock = false;
notify();
}
@Override
public Condition newCondition() {
return null;
}
}
使用Lock接口实现一个可重入锁
package com.wrial.main.example.myLock;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/*
* 实现可重入锁,根据当前锁的状态,如果锁被占用,那就判断当前线程是不是占用锁的线程,否则就wait,释放锁的时候进行notify
*
* */
public class MyLock2 implements Lock {
private boolean isLock = false;
private Thread lockBy = null;
private int lockCount = 0;
@Override
public void lock() {
Thread currentThread = Thread.currentThread();
while (isLock && lockBy != currentThread) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
isLock = true;
lockBy = currentThread;
lockCount++;
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public boolean tryLock() {
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
}
//必须要加synchronized
@Override
public synchronized void unlock() {
if (lockBy == Thread.currentThread()) {
lockCount--;
if (lockCount == 0) {
notify();
isLock = false;
lockBy = null;
}
}
}
@Override
public Condition newCondition() {
return null;
}
}
AQS全称AbstractQueueSynchronizer同步发生器,是轻量级锁的基础,它用过内置的同步队列(FIFO)来完成共享资源的管理工作。
要想明白AQS,那就得先明白里面的内容,先看看它对节点的定义
static final class Node {
// 共享模型
static final Node SHARED = new Node();
// 独占模型
static final Node EXCLUSIVE = null;
// 代表取消的(中断或已完成),它不再会到队列中去,会被垃圾回收机制回收
static final int CANCELLED = 1;
// 表示该节点后续有阻塞的节点
static final int SIGNAL = -1;
// 条件下阻塞
static final int CONDITION = -2;
// 共享时头结点的状态
static final int PROPAGATE = -3;
简单的画了画图,表示了AQS里的队列维护过程,第一个是投,它不会存任何的进程信息,它主要是记录head和tail的指针,如果有新的Node进来就会插入到末尾,删除就是删除链表节点。这些Node是对线程信息的包装。当锁可用的时候它会唤醒里面的线程进行工作。AQS中还有一个十分重要的变量,那就是state,它的含义就是已获得锁的线程lock的次数
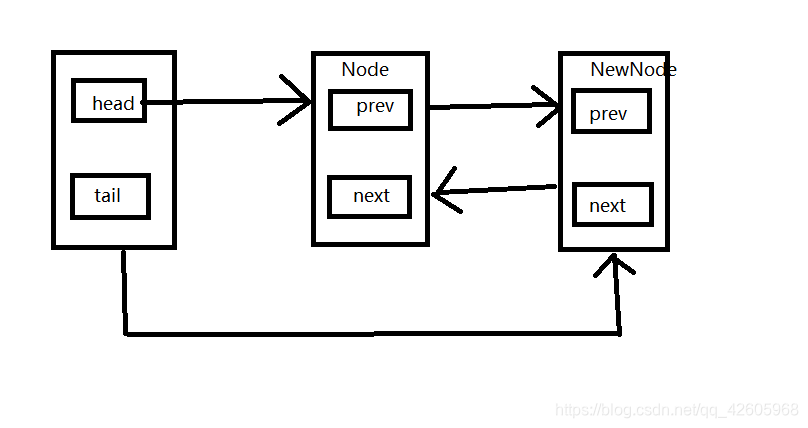
下面就是自己使用AQS和Lock实现自定义的可重入锁
package com.wrial.main.example.myLock;
/*
* 使用AQS来实现可重入锁
* */
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
public class MyLock4 implements Lock {
private class Helper extends AbstractQueuedSynchronizer {
//1.获取状态
//2.拿到状态,CAS判断(双重检测),并设置为独占锁
//3.判断是不是当前线程,要是当前线程的话就可重入
@Override
protected boolean tryAcquire(int arg) {
Thread t = Thread.currentThread();
int state = getState();
// 说明无锁,就CAS进行取,若成功就设置为独占锁
if (state == 0) {
if (compareAndSetState(0, arg)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
// 如果当前线程已经那到锁,那就state+1进行重入
}else if (t == getExclusiveOwnerThread()){
setState(state+1);
return true;
}
return false;
}
//1.先看是不是当前线程,如果不是就不能释放,抛出异常
//2.如果是的话,判断state,如果state-1(arg)=0,那就可以释放
@Override
protected boolean tryRelease(int arg) {
//锁的获取和释放需要一一对应,那么调用这个方法的线程,一定是当前线程
if(Thread.currentThread() != getExclusiveOwnerThread()){
throw new RuntimeException();
}
int state = getState() - arg;
setState(state);
// 如果state为0,说明独占锁被取消了
if(state == 0){
setExclusiveOwnerThread(null);
return true;
}
return false;
}
//ConditionObject不能在外部使用是AQS里的
Condition newCondition() {
return new ConditionObject();
}
}
Helper helper = new Helper();
@Override
public void lock() {
helper.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
helper.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return helper.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return helper.tryAcquireNanos(1, unit.toNanos(time));
}
@Override
public void unlock() {
helper.release(1);
}
@Override
public Condition newCondition() {
return helper.newCondition();
}
}
使用读写锁案例:
package com.wrial.main.example.myLock;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReentrantReadWriteLockExample {
private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Map<String, Data> map = new TreeMap();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
public Data getData(String key) {
readLock.lock();
try {
return map.get(key);
} finally {
readLock.unlock();
}
}
public Set<String> getKeySet() {
readLock.lock();
try {
return map.keySet();
} finally {
readLock.unlock();
}
}
public Data put(String key, Data value) {
writeLock.lock();
try {
return map.put(key, value);
} finally {
writeLock.unlock();
}
}
static class Data {
public int getValue() {
return 1;
}
}
public void testReadLock() {
Lock readLock = readWriteLock.readLock();
Data data = new Data();
new Thread(() -> {
System.out.println(Thread.currentThread() + "准备读" + data.getValue());
readLock.lock();
// 在此不释放锁
System.out.println(Thread.currentThread() + "正在读");
}).start();
new Thread(() -> {
System.out.println(Thread.currentThread() + "准备读" + data.getValue());
readLock.lock();
// 在此不释放锁
System.out.println(Thread.currentThread() + "正在读");
}).start();
}
public void testWriteLock() {
Lock writeLock = readWriteLock.writeLock();
Data data = new Data();
new Thread(() -> {
System.out.println(Thread.currentThread() + "准备写" + data.getValue());
writeLock.lock();
// 在此不释放锁
System.out.println(Thread.currentThread() + "正在写");
}).start();
new Thread(() -> {
System.out.println(Thread.currentThread() + "准备写" + data.getValue());
writeLock.lock();
// 在此不释放锁
System.out.println(Thread.currentThread() + "正在写");
}).start();
}
public static void main(String[] args) {
ReentrantReadWriteLockExample reentrantReadWriteLockExample = new ReentrantReadWriteLockExample();
reentrantReadWriteLockExample.testReadLock();
// reentrantReadWriteLockExample.testWriteLock();
}
}
读锁可以重复加,写锁只能独占,如下
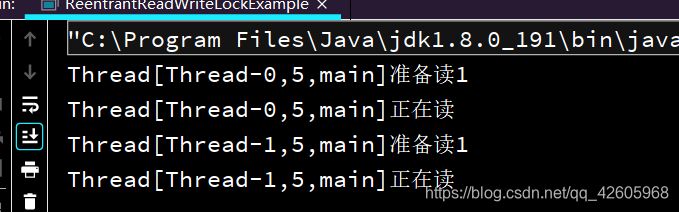

当然所的搭配还有读-写,写-读,经测试过读写锁是互斥的。
Atomic工具包
关于Atomic工具包使用方法都是相同的,它底层的原理还是利用的CAS进行数据更新,从而保证数据更新操作的原子性
这个程序是通过CountDownLatch控制打印次数五千的案例,此处并没有使用到Atomic进行add
@Slf4j
@NotThreadSafe
public class CountExample1 {
public static int clientTotal = 5000;
public static int threadTotal = 200;
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
//线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//信号量 控制最多可同时执行的个数(在此处的测试可以忽略它的存在)
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("cout:{}", count);
}
private static void add() {
count++;
}
}
可以看到结果如下,打印的结果不是5000
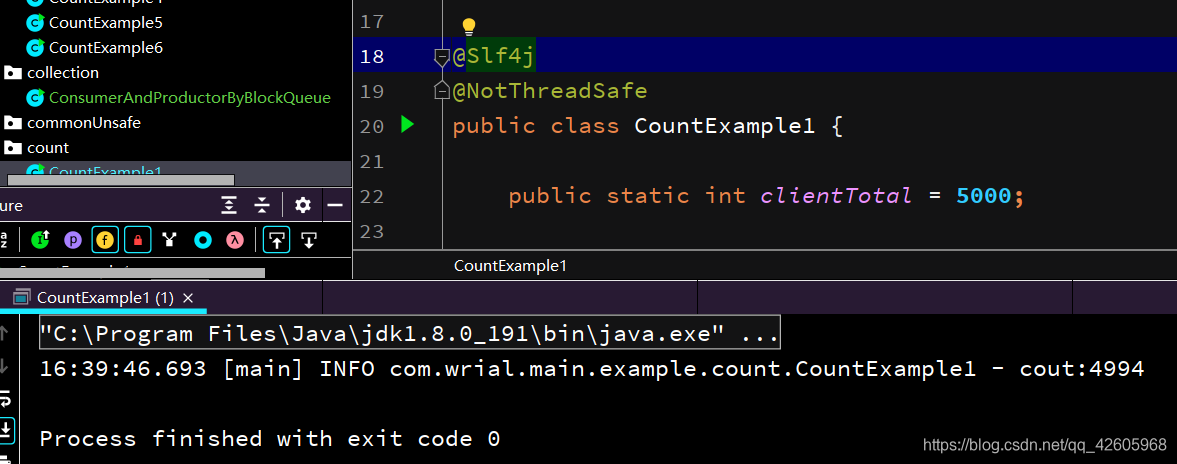
在下面程序使用AtomicInteger来进行自增
package com.wrial.main.example.count;
import com.wrial.main.annotations.NotThreadSafe;
import com.wrial.main.annotations.ThreadSafe;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 并发模拟测试
* 原子性Atomci包
* 可以和CountExample进行对比,这个是5000,而CountExample是一个变化的
* 仅仅将int换为AtomicInteger互斥访问后就不会出错了
*/
@Slf4j
@ThreadSafe
public class CountExample2 {
public static int clientTotal = 5000;
public static int threadTotal = 200;
// public static int count = 0;
public static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
//线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//信号量
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("cout:{}", count.get());
}
private static void add() {
// count++;
count.incrementAndGet();//先增加再get
// count.getAndIncrement();//先get后increment
}
}
打印结果一直是5000
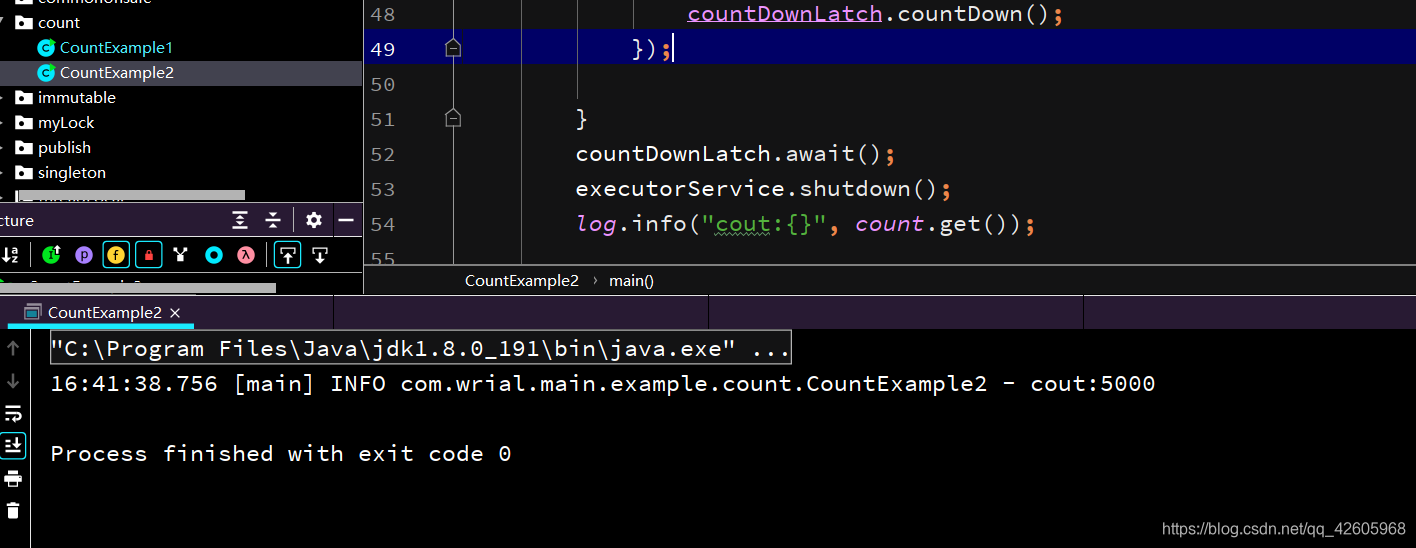
这就是Atomicxx的用法,它是利用CAS保证了原子性,也可以从此例子中进一步验证自增操作并不是具有原子性的
工具类
在JUC下的工具类有很多,比如
- CountDownLatch:正如其名,每执行一个任务就进行一次countdown。使用场景:划分任务由多个线程进行执行,例如采用多线程进行数据采集,可以通过它规定进行采集的次数等
- Semaphore:信号量,可用于控制同时资源访问,使用场景:连接池的可连接数等
- CyclicBarrier:内存屏障,它允许线程相互等待,等到达执行点之后再进行执行。它的意义和CountDownLatch很相似,但是又有不同。它的计数可以重置,而CountDownLatch不能重置。使用场景:可以用CountDownLatch的地方就可以用它,它比前者更强大,可以对阻塞数进行统计
- Exchanger:顾名思义,它就是用来交换数据的。使用场景:可以提供一个同步点,让两个线程可以交换数据,必须成对出现
CountdownLatch使用,完成200个任务就停止
@Slf4j
public class CountDownLatchExample {
private static final int count = 200;
public static void test(int threadNum) throws InterruptedException {
Thread.sleep(100);
log.info("{}", threadNum);
Thread.sleep(100);
}
public static void main(String[] args) throws InterruptedException {
ExecutorService exc = Executors.newCachedThreadPool();
CountDownLatch countDownLatch = new CountDownLatch(count);
for (int i = 1; i <= count; i++) {
final int num = i;
exc.execute(() -> {
try {
test(num);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//保证肯定会执行,在其他情况可以在某些条件下才会countdown
countDownLatch.countDown();
}
});
}
//可以保证前面的执行完,对count=0进行校验
countDownLatch.await();
log.info("finish");
exc.shutdown();
}
}
Semaphore信号量实现并发访问控制,案例如下
控制信号量值为10,执行任务需要一秒,可以在控制台中看到明显的停顿(而且是每隔10条任务),足以说明信号量的作用
package com.wrial.main.example.aqs;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
/*
* 信号量的使用
* */
@Slf4j
public class SemaphoreExample1 {
private static final int conutThrad = 30;
public static void test(int count) throws InterruptedException {
Thread.sleep(1000);
log.info("{}", count);
}
public static void main(String[] args) throws InterruptedException {
ExecutorService exc = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(10);//定义资源运行最大并发量为10
for (int i = 0; i < conutThrad; i++) {
final int count = i;
exc.execute(() -> {
try {
semaphore.acquire();//获得一个许可,也可以获取多个许可
test(count);
semaphore.release();//释放一个许可,也可以释放多个许可
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
exc.shutdown();
}
}
它的tryAcquire也可以对其设置超时时间等参数,如下例子
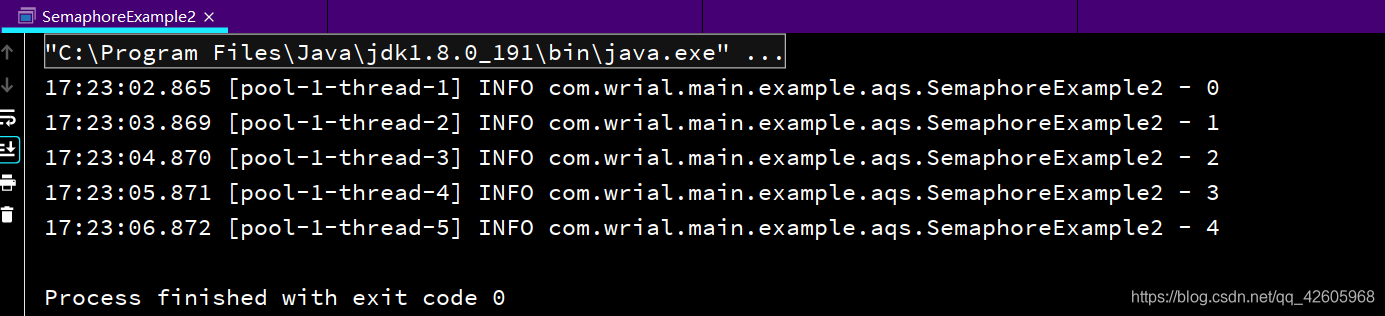
设置信号量大小为3,我们每次都获取三个,每执行一个任务需要1s,也就是说最多可以执行五个任务
package com.wrial.main.example.aqs;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
/*
* 信号量的使用
* */
@Slf4j
public class SemaphoreExample2{
private static final int conutThrad = 30;
public static void test(int count) throws InterruptedException {
Thread.sleep(1000);
log.info("{}", count);
}
public static void main(String[] args) throws InterruptedException {
ExecutorService exc = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(3);//定义资源运行最大并发量为3
for (int i = 0; i < conutThrad; i++) {
final int count = i;
exc.execute(() -> {
try {
//能获取到信号量的就可以使用,获取不到就舍弃
// if (semaphore.tryAcquire()) {
// test(count);
// semaphore.release();//释放一个许可,也可以释放多个许可
// }
//可以传入参数,设置信号量的超时时间,针对于多线程
// if (semaphore.tryAcquire(5, TimeUnit.SECONDS)) {
// test(count);
// semaphore.release();
// }
if (semaphore.tryAcquire(3,5, TimeUnit.SECONDS)) {
test(count);
semaphore.release(3);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
exc.shutdown();
}
}
演示结果如下:
CyclicBarrier的使用案例,每五个线程之间到达屏障点,先到的等待后面的然后全到了之后就继续执行
@Slf4j
public class CyclicBarrierExample1 {
// 规定为5,每五个线程comming,就等待一次再going
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
private static int threadCount = 20;
public static void runAndWait(int num) throws Exception {
Thread.sleep(100);
log.info("{} is comming", num);
cyclicBarrier.await();
log.info("{} is going", num);
}
public static void main(String[] args) throws Exception {
ExecutorService exe = Executors.newCachedThreadPool();
for (int i = 0; i < threadCount; i++) {
Thread.sleep(100);
final int num = i;
exe.execute(() -> {
try {
runAndWait(num);
} catch (Exception e) {
e.printStackTrace();
}
});
}
exe.shutdown();
}
}
部分结果如下图
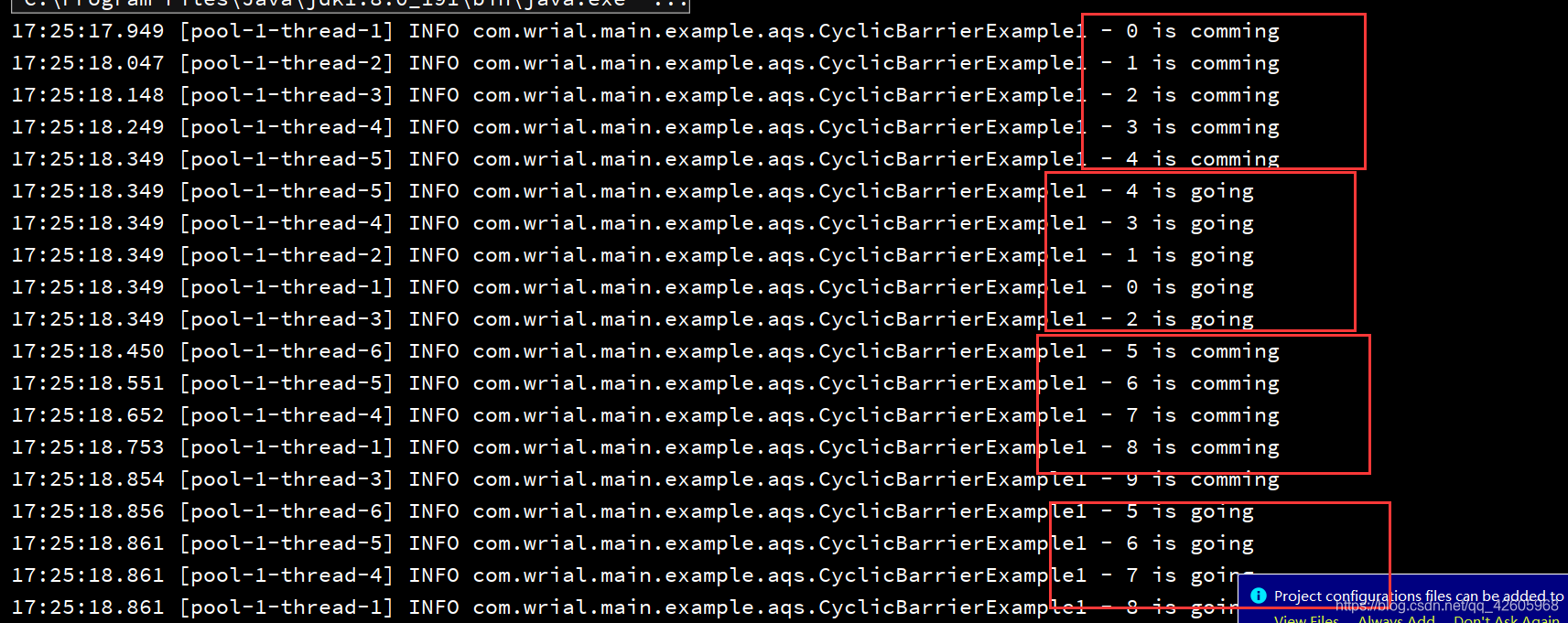
为了进一步验证,我将threadCount调整为18,发现后三个一直在等待,但是后面已经没有了
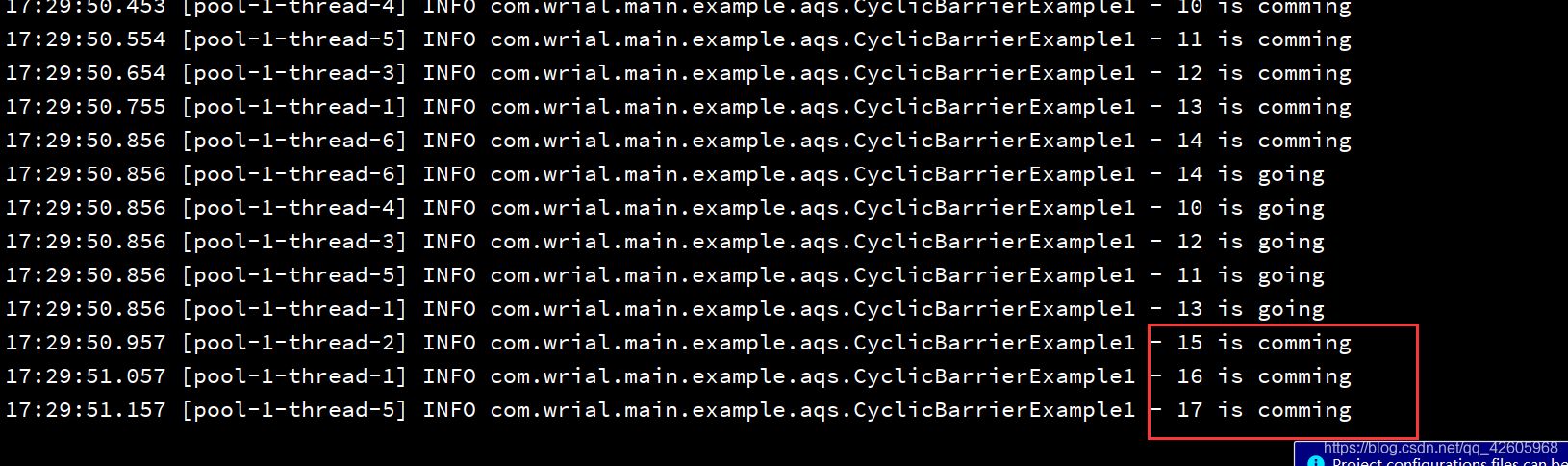
解决它的方法是什么了,可以给它设置超时时间,超时就不再等待
带有超时处理的CyclcBarrier
@Slf4j
public class CyclicBarrierExample2 {
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
private static int threadCount = 20;
public static void runAndWait(int num) throws Exception {
Thread.sleep(100);
log.info("{} is comming", num);
try {
cyclicBarrier.await(3, TimeUnit.SECONDS);
}catch (RuntimeException| BrokenBarrierException e){
log.warn("RuntimeException| BrokenBarrierException",e);
}
log.info("{} is going", num);
}
public static void main(String[] args) throws Exception {
ExecutorService exe = Executors.newCachedThreadPool();
for (int i = 0; i < threadCount; i++) {
Thread.sleep(1000);
final int num = i;
exe.execute(() -> {
try {
runAndWait(num);
} catch (Exception e) {
}
});
}
exe.shutdown();
}
}
可以看到它等不到就抛出异常,自己走了
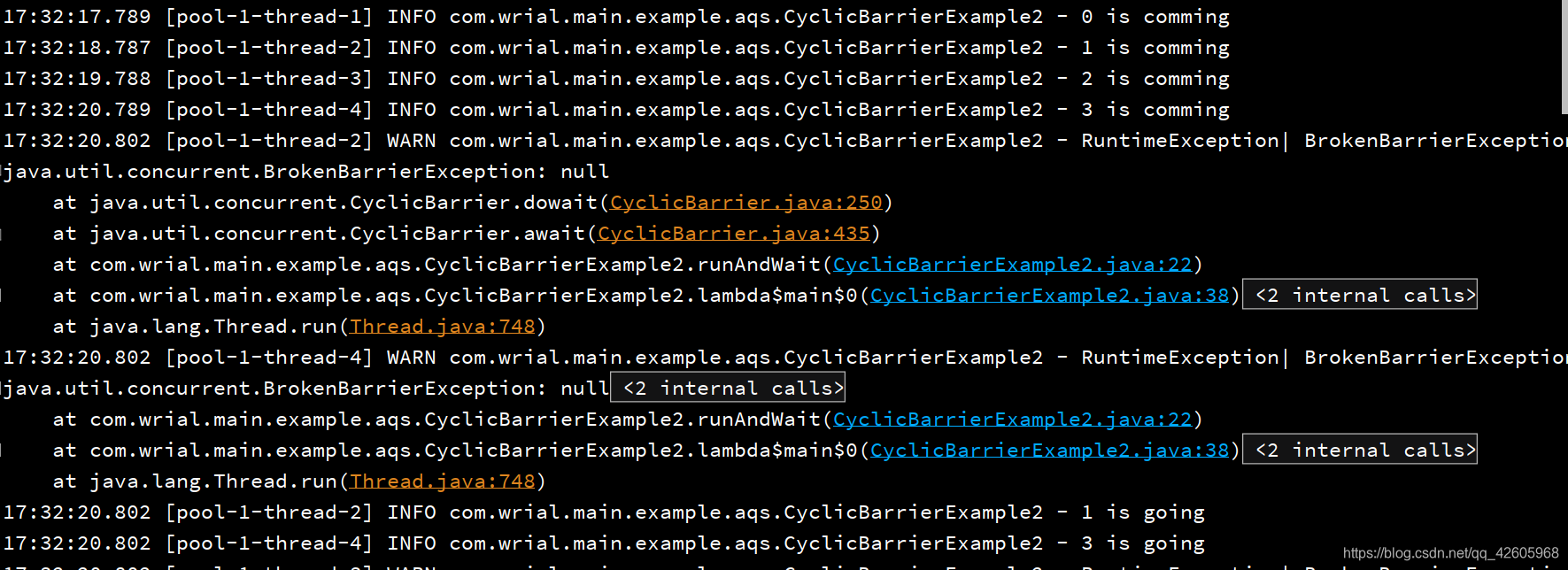
前面说到CyclcBarrier可以重置,可以传入一个Runnable接口作为重置标志,代码如下
package com.wrial.main.example.aqs;
/*
* 使用CyclicBarrier,并传入Runable
* */
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j
public class CyclicBarrierExample3 {
//传入的Runnable是在到达屏障后,第一个执行
private static CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
log.info("—————————————————————————————————— ");
});
private static int threadCount = 20;
public static void runAndWait(int num) throws Exception {
Thread.sleep(100);
log.info("{} is comming", num);
cyclicBarrier.await();
log.info("{} is going", num);
}
public static void main(String[] args) throws Exception {
ExecutorService exe = Executors.newCachedThreadPool();
for (int i = 0; i < threadCount; i++) {
Thread.sleep(1000);
final int num = i;
exe.execute(() -> {
try {
runAndWait(num);
} catch (Exception e) {
}
});
}
exe.shutdown();
}
}
演示效果:
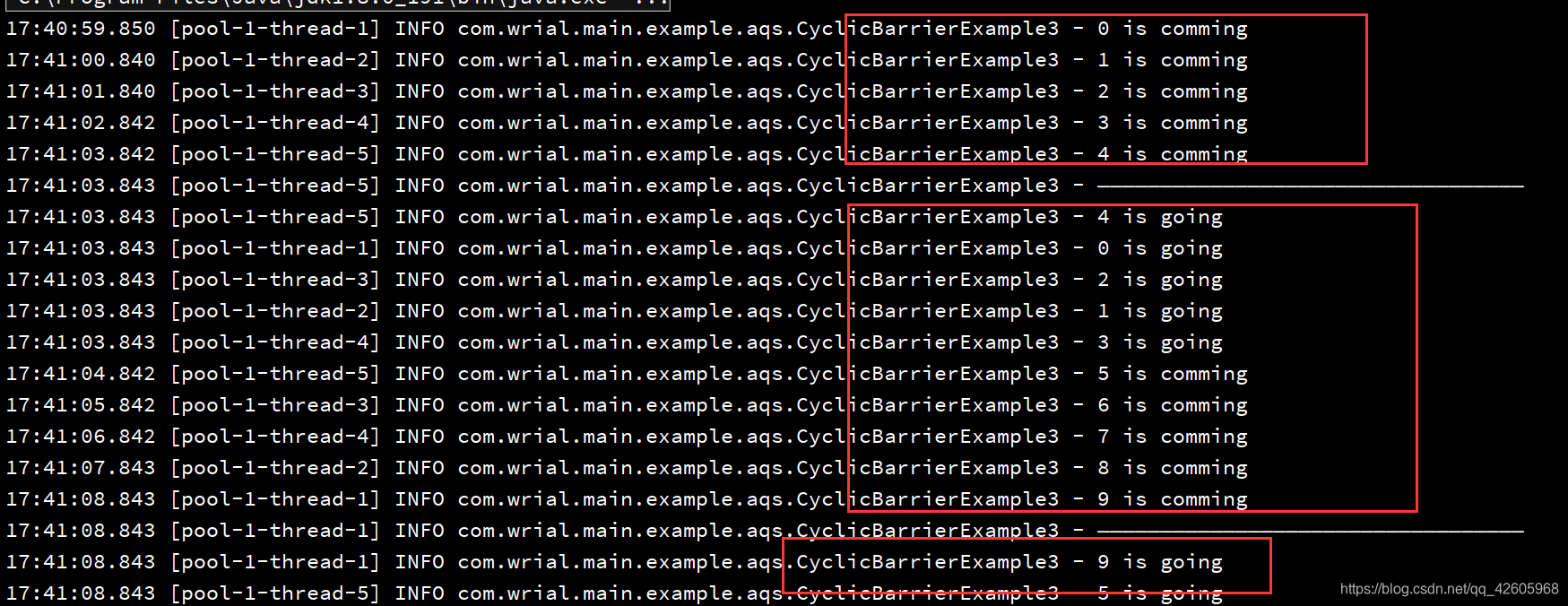
Exchanger使用案例
package com.wrial.main.example.aqs;
/*
* @Author Wrial
* @Date Created in 17:45 2020/3/20
* @Description Exchanger使用案例
*/
import java.io.IOException;
import java.util.concurrent.Exchanger;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ExchangerExample {
public void start() throws IOException {
int count = 5;
//new一个Exchanger
Exchanger<Integer> exchanger = new Exchanger<>();
ExecutorService executorService = Executors.newFixedThreadPool(count);
// 使用i作为休眠时间和各自的数据
for (int i = 0; i < count; i++) {
executorService.execute(new Worker(i, exchanger,i));
}
System.in.read();
}
class Worker extends Thread {
Integer value;
Integer sleepTime;
Exchanger<Integer> exchanger;
public Worker(Integer sleepTime, Exchanger<Integer> exchanger,Integer value) {
this.sleepTime = sleepTime;
this.exchanger = exchanger;
this.value = value;
}
@Override
public void run() throws IllegalArgumentException {
try {
System.out.println(Thread.currentThread().getName() + " 准备执行");
TimeUnit.SECONDS.sleep(sleepTime);
System.out.println(Thread.currentThread().getName() + " 等待交换");
Integer value = exchanger.exchange(this.value);
System.out.println(Thread.currentThread().getName() + " 交换得到数据为:" + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException, InterruptedException {
new ExchangerExample().start();
}
}
演示结果如下:
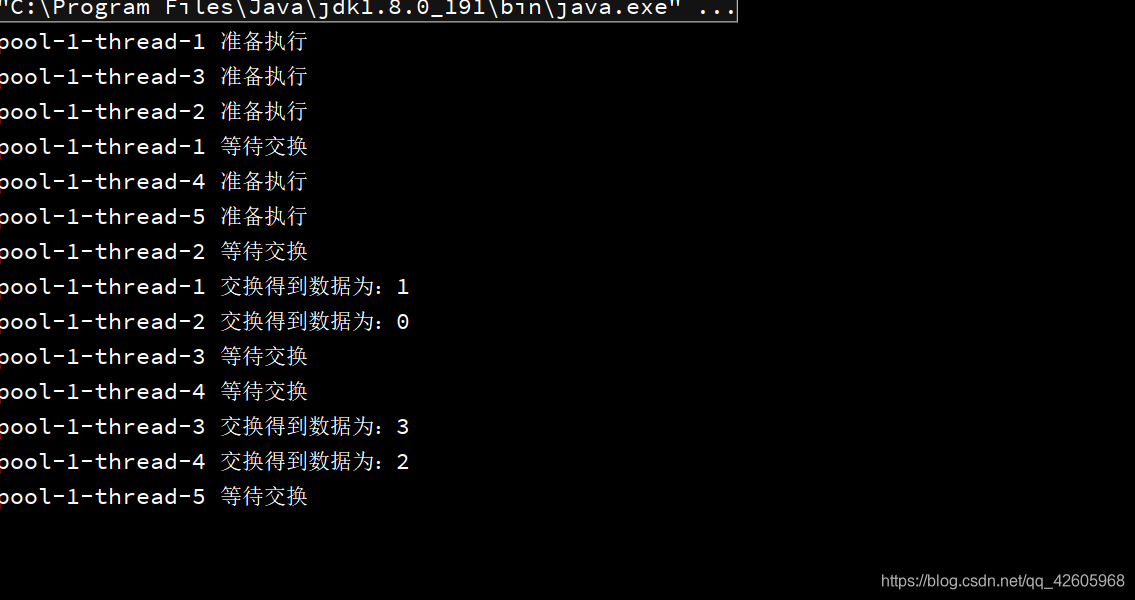
可以发现Exchanger不能孤立存在,thread-5一直在等线程和它交换,并且它进行交换的是相邻的两个线程的数据!
线程池
在前面也用到了线程池,下面就简单了解一下线程池的种类,和线程池的结构
为什么要有线程池?
原因很简单,就和数据库连接池一个道理,因为建立线程和销毁线程对资源消耗很大,因此可以采用线程池来进行线程复用,更为重要的一点是线程池提供了管理线程更简便的方法。
我们经常去使用Executors工具类去创建我们想要的线程池,如下图
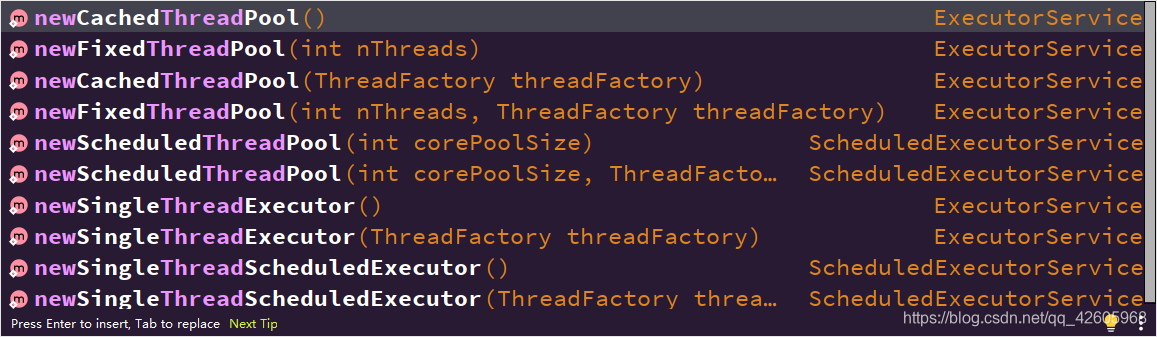
里面有固定大小的,也有可变大小的,也有可调度的,也有单线程的还有单线程可调度的线程池供我们去使用 ,结构是什么呢?怎么去工作的呢?下面就来聊一聊线程池
在说线程池之前先看看执行器,也就是Executor接口,在这个接口中只有一个方法,那就是execute方法,传入的是一个Runnable接口,代码如下
public interface Executor {
void execute(Runnable command);
}
可以从上面那幅图看到线程池从调度管理方面可以分为可调度的线程池和不可调度的线程池
- ExecutorService:不可调度的
- ScheduledExecutorService:可调度的
进入Executors源码可以看到创建线程池的方式大致分为三种
- ThreadPoolExecutor
- ForkJoinPool
- ScheduledThreadPoolExecutor
其中1和2创建出的是不可调度的,3创建出来的是可调度的
代码如下
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
下面着重于对最常用的ThreadPoolExecutor进行解释
下图为ThreadPoolExecutor的UML图,可以看到它的继承和实现关系
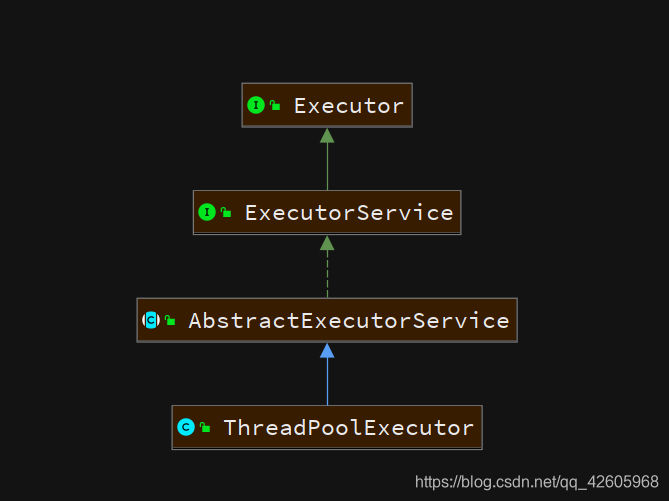
要通过ThreadPoolExecutor创建一个线程池,需要的七大核心参数,了解核心参数也是了解线程池的根本,如下图
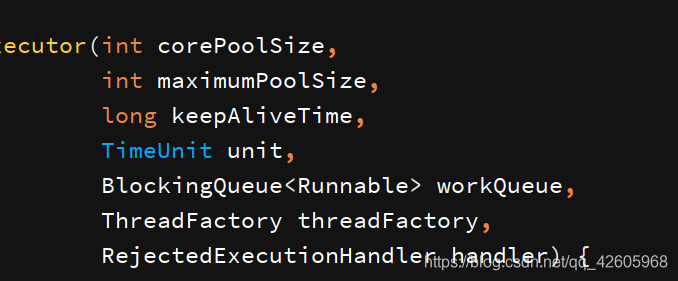
核心参数有
- 核心线程数量:分配核心工作线程的数量
- 最大线程池容量:线程池最大能维护的线程数量
- 保持存活时间:规定非核心线程的最大的空闲时间
- 时间单元:规定使用的时间的单位
- 工作队列(阻塞队列):用于排队的阻塞队列
- 线程工厂:用于生产线程
- 拒绝策略:线程池拒绝任务采取的策略
它也对拒绝策略做了规定,也就是RejectedExecutionHandler的所有子类,拒绝策略有如下四种

- ThreadPoolExecutor.AbortPolicy:是默认的拒绝策略,就拒绝执行是抛出异常
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程来完成任务(谁调用的就找谁)
- ThreadPoolExecutor.DiscardOldestPolicy:抛弃最老的任务(最先执行),然后重新提交被拒绝的线程
- ThreadPoolExecutor.DiscardPolicy:丢弃任务,只是默默的丢弃,也不会报异常
线程池的excute方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* 可以大致分为下面五个步骤:
* 1.判断当前执行任务的线程是否小于核心线程,如果小于核心线程就创建一个新的线程执行work
* 2.如果核心线程已满,那就判断workQueue满不满,等待队列不满的话就加入到等待队列被调度
* 3.如果workQueue满了,那就会去检查,当前执行任务线程数是否大于maxiumPoolSize
* 4.如果不大于maxiumPoolSize,那就创建一个新的线程加入到线程池
* 5.如果大于maxiumPoolSize那就是拒绝策略用到的地方了(根据自己的拒绝策略进行执行)
*
int c = ctl.get();
//1
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3 4
else if (!addWorker(command, false))
//5
reject(command);
}
因此结合其他代码不难分析出线程池的工作流程,下面是我画出的流程图
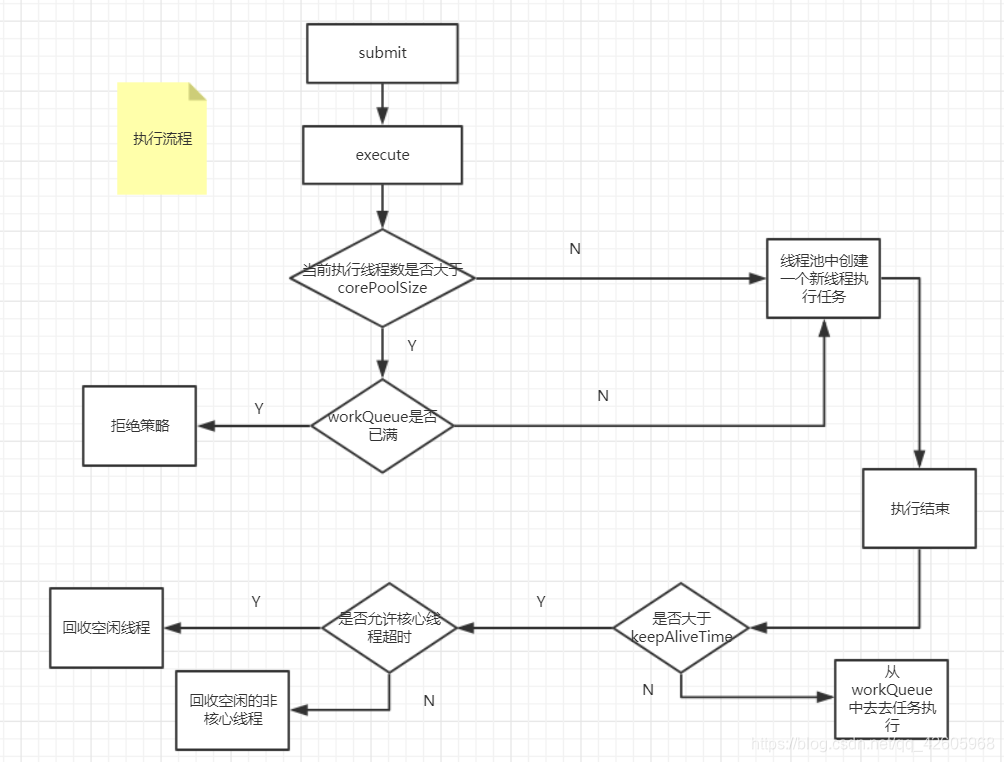
这就是ThreadPoolExecutor的工作流程
下面也稍微说一说其他的两种线程池
ForkJoinPool是根据并发里面的ForkJoin框架而来的,核心思想就是分治,先将任务拆分,然后执行,然后合并。一般在处理比较大的数据的时候效率比较高,但是CPU占有率也会急剧飙升。
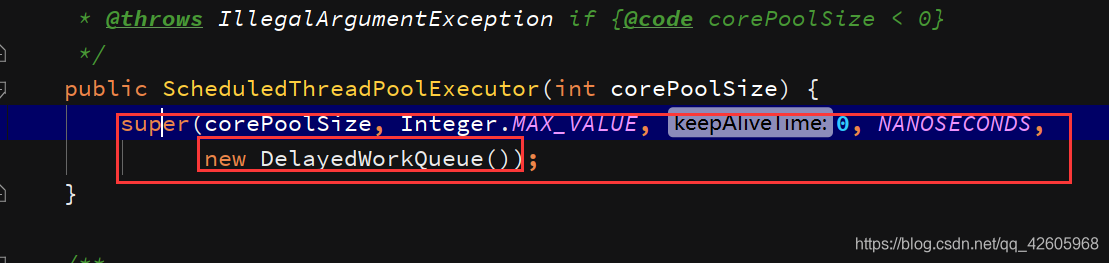
下面就说说带有调度的线程池,它其实是ThreadPoolExecutor的子类,它只是把阻塞队列换成了延时队列,从而实现调度,如下图
说完线程池就最后来说说Callable和Future
说之前呢,先将Callable和我们经常用的Runnable进行一个对比
Callable接口
public interface Callable<V> {
//如果不能完成就抛出一样,完成就返回V
V call() throws Exception;
}
Runnable接口
public interface Runnable {
public abstract void run();
}
经过对比可以发现Runnable接口是不能进行回调的,也可以这么说,Runnable是一个同步任务,Callable是一个异步任务
那说完Callable,那Future是干嘛的呢?通过下面的代码可以发现Future其实就是一个异步任务的管理,可以取消,判断是否完成,get等操作
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
因此就可以根据此进行异步任务的编写,代码如下
@Slf4j
public class FutureExample {
static class MyCallable implements Callable {
@Override
public String call() throws Exception {
log.info("Do Some Things in callable!");
Thread.sleep(4000);
return "Callable Things Done";
}
}
public static void main(String[] args) throws Exception {
ExecutorService exe = Executors.newCachedThreadPool();
Future future = exe.submit(new MyCallable());
log.info("do some thing in main");
//get方法如果获取不到就一直阻塞
String mes = (String) future.get();
log.info("{}", mes);
log.info("main done");
exe.shutdown();
}
}
结果如下,可以看到get执行完的时候和Thread.Sleep前,刚好差了4秒,可以看出get操作获取不到就是阻塞状态。

——————————————————————————————————————————
此文到此结束!














 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









