







一、块设备 RBD(RADOS Block Devices)
RBD(RADOS Block Devices)即为块存储的一种,RBD 通过 librbd 库与 OSD 进行交互,RBD 为 KVM 等虚拟化技术和云服务(如 OpenStack 和 CloudStack)提供高性能和无限可扩展性的存储后端,这些系统依赖于 libvirt 和 QEMU 实用程序与 RBD 进行集成,客户端基于 librbd 库 即可将 RADOS 存储集群用作块设备,不过,用于 rbd 的存储池需要事先启用 rbd 功能并进行初始化。
1.1 创建 RBD
利用命令创建一个名为 myrbd1 的存储池,并在启用 rbd 功能后对其进 行初始化
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create myrdb1 64 64 #创建存储池,指定 pg 和 pgp 的数量,pgp 用于在 pg 故障 时归档 pg 的数据,因此 pgp 通常等于 pg 的值
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool application enable myrdb1 rbd #对存储池启用 RBD 功能
[ceph@ceph-deploy ceph-cluster]$ rbd pool init -p myrdb1 #通过 RBD 命令对存储池初始化
1.2 生成 img (镜像)文件
rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image), 并把映像文件作为块设备使用,rbd 命令可用于创建、查看及删除块设备相在的映像(image), 以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作。
[ceph@ceph-deploy ceph-cluster]$ rbd create myimg1 --size 5G --pool myrdb1
[ceph@ceph-deploy ceph-cluster]$ rbd --image myimg1 --pool myrdb1 info
rbd image 'myimg1':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
id: 10d16b8b4567
block_name_prefix: rbd_data.10d16b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Mon Aug 9 06:02:01 2021
注意事项:
后续步骤由于 centos 内核较低无法挂载使用,因此只开启部分特性。
除了 layering 其他特性需要高版本内核支持。
[ceph@ceph-deploy ceph-cluster]$ rbd create myimg2 --size 1G --pool myrdb1 --image-format 2 --image-feature layering
[ceph@ceph-deploy ceph-cluster]$ rbd --image myimg2 --pool myrdb1 info
rbd image 'myimg2':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 10dd6b8b4567
block_name_prefix: rbd_data.10dd6b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Mon Aug 9 06:03:43 2021
1.3 客户端使用块存储
配置yum源
[root@centos7 ~]# yum install epel-release -y
[root@centos7 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
安装 ceph-common
[root@centos7 ~]# yum install ceph-common -y
从部署服务器同步认证文件
[ceph@ceph-deploy ceph-cluster]$ scp ceph.conf ceph.client.admin.keyring root@10.0.0.20:/etc/ceph/
客户端映射 img 文件
由于 myrdb1 有其他特性,centos 内核不兼容,所以采用 myrdb2 。
一般执行该命令不需要指定文件,他会从/etc/ceph/目录下读取配置文件,里面包含 ceph 的地址。
[root@centos7 ~]# rbd -p myrdb1 map myimg2
/dev/rbd0
# 查看已挂载的磁盘
[root@centos7 ~]# lsblk
[root@centos7 ~]# fdisk -l
格式化磁盘并挂载使用
[root@centos7 ~]# mkfs.xfs /dev/rbd0
[root@centos7 ~]# mkdir /data/lck/static/ -p
[root@centos7 ~]# mount /dev/rbd0 /data/lck/static/
[root@centos7 ~]# df -TH
/dev/rbd0 xfs 1.1G 34M 1.1G 4% /data/lck/static
下载一张图片,准备测试
[root@centos7 static]# ll
total 98236
-rw-r--r-- 1 root root 588041 Aug 2 14:41 1.jpg
-rw-r--r-- 1 root root 100000000 Aug 8 05:46 test-file
ceph 验证数据
[ceph@ceph-deploy ceph-cluster]$ ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
900 GiB 891 GiB 9.4 GiB 1.04
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
mypool 1 0 B 0 282 GiB 0
myrdb1 2 110 MiB 0.04 282 GiB 43
二、对象存储 RGW(radosgw)
RGW 提供的是 REST 接口,客户端通过 http 与其进行交互,完成数据的增删改查等管理操作。 radosgw 用在需要使用 RESTful API 接口访问 ceph 数据的场合,因此在使用 RBD 即块存储得场合或者使用 cephFS 的场合可以不用启用 radosgw 功能。
2.1 部署 radosgw 服务
ceph-mgr1 服务器部署为 RGW 主机。
一般建议 ceph-mgr1 和 ceph-mgr2 做高可用,在他们前面搭一个负载均衡器。
[root@ceph-mgr1 ~]# yum install ceph-radosgw
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy --overwrite-conf rgw create ceph-mgr1
2.2 验证 radosgw 服务
[root@ceph-mgr1 ~]# ps -aux | grep radosgw
ceph 3656 0.2 2.7 5055520 51016 ? Ssl 06:54 0:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-mgr1 --setuser ceph --setgroup ceph
root 4296 0.0 0.0 112808 968 pts/0 S+ 06:57 0:00 grep --color=auto radosgw
2.3 验证 ceph 状态
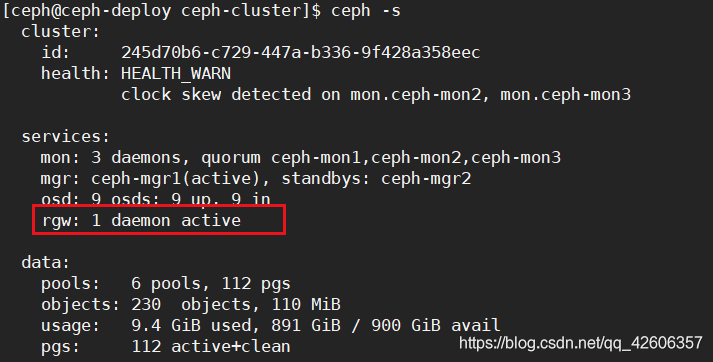
2.4 验证 radosgw 存储池
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool ls
mypool
myrdb1
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
三、文件存储 Ceph-FS
ceph FS 即 ceph filesystem,可以实现文件系统共享功能,客户端通过 ceph 协议挂载并使用 ceph 集群作为数据存储服务器。 Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds 进程管 理与 cephFS 上存储的文件相关的元数据,并协调对 ceph 存储集群的访问。
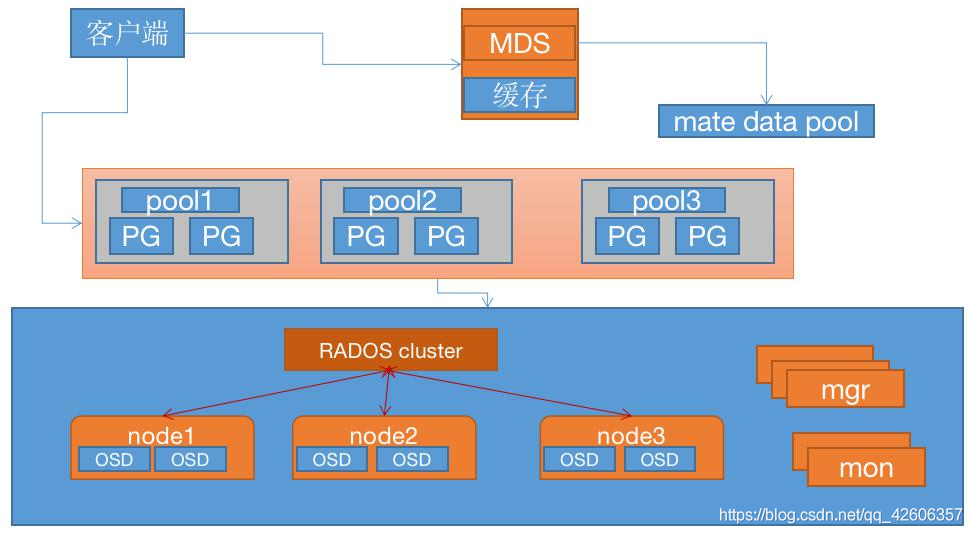
客户端先去MDS访问获取所要请求文件的元数据,然后再向Ceph存储节点请求文件。
3.1 部署 MDS 服务
[root@ceph-mgr1 ~]# yum install ceph-mds -y
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy mds create ceph-mgr1
 自动设置了开启自启动
自动设置了开启自启动
3.2 验证 MDS 服务
MDS 服务目前还无法正常使用,需要为 MDS 创建存储池用于保存 MDS 的数据。
[ceph@ceph-deploy ceph-cluster]$ ceph mds stat
, 1 up:standby #当前为备用状态,需要分配 pool 才可以使用。
3.3 创建 CephFS metadata 和 data 存储池
使用 CephFS 之前需要事先于集群中创建一个文件系统,并为其分别指定元数据和数据相关 的存储池
如下命令将创建名为 mycephfs 的文件系统,它使用 cephfs-metadata 作为元数据存储池;使用 cephfs-data 为数据存储池。
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs-metadata 32 32 #保存 metadata 的 pool
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs-data 64 64 #保存数据的 pool
查看当前 ceph 状态
[ceph@ceph-deploy ceph-cluster]$ ceph -s
cluster:
id: 245d70b6-c729-447a-b336-9f428a358eec
health: HEALTH_WARN
clock skew detected on mon.ceph-mon2, mon.ceph-mon3
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3
mgr: ceph-mgr1(active), standbys: ceph-mgr2
osd: 9 osds: 9 up, 9 in
rgw: 1 daemon active
data:
pools: 8 pools, 208 pgs
objects: 230 objects, 110 MiB
usage: 9.4 GiB used, 891 GiB / 900 GiB avail
pgs: 208 active+clean
[ceph@ceph-deploy ceph-cluster]$ ceph osd lspools
1 mypool
2 myrdb1
3 .rgw.root
4 default.rgw.control
5 default.rgw.meta
6 default.rgw.log
7 cephfs-metadata
8 cephfs-data
3.4 创建 cephFS 并验证
[ceph@ceph-deploy ceph-cluster]$ ceph fs new mycephfs cephfs-metadata cephfs-data
new fs with metadata pool 7 and data pool 8
[ceph@ceph-deploy ceph-cluster]$ ceph fs ls
name: mycephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
[ceph@ceph-deploy ceph-cluster]$ ceph fs status mycephfs #查看指定 cephFS 状态
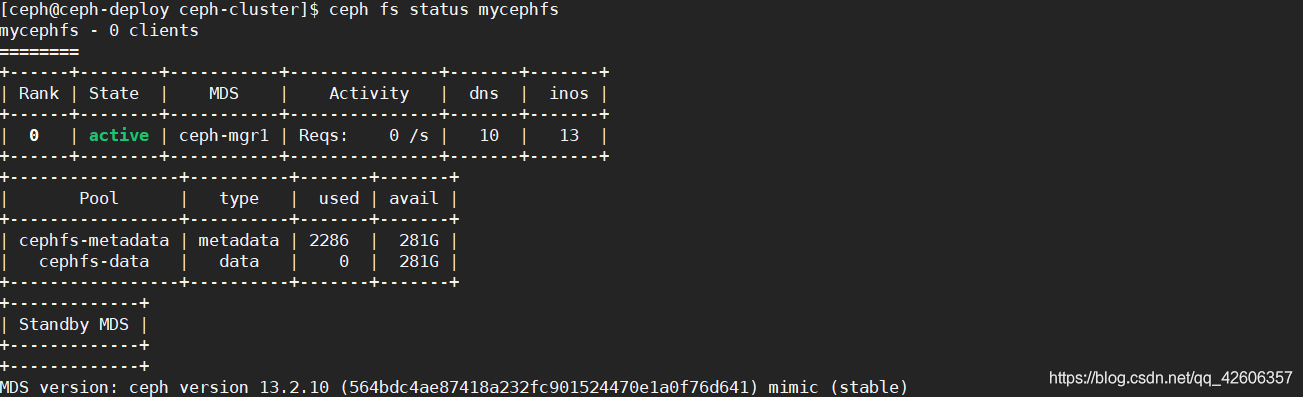
后期添加数据存储池 和 移除存储池
fs add_data_pool <fs_name> <pool>
fs rm_data_pool <fs_name> <pool>
3.5 验证 cepfFS 服务状态
[ceph@ceph-deploy ceph-cluster]$ ceph mds stat #是否转变为active状态
mycephfs-1/1/1 up {0=ceph-mgr1=up:active}
3.6 挂载 cephFS
获取 ceph-deploy 节点的 key
[ceph@ceph-deploy ceph-cluster]$ cat ceph.client.admin.keyring
[client.admin]
key = AQAq4Q9hSYOwDBAAldD+GE0L9KtrVJ2SOW07qQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
在 ceph FS 起来的时候,mon 所有节点都会把端口6789开启来,该端口供客户端挂载使用。
客户端挂在 mon 节点的 6789 端口
[root@ceph-client data]#mount -t ceph 10.0.0.14:6789:/ /mnt -o name=admin,secret=AQAq4Q9hSYOwDBAAldD+GE0L9KtrVJ2SOW07qQ==
[root@ceph-client ~]# cp /var/log/messages /mnt/ #验证数据
[root@ceph-client ~]# cp /var/log/messages /mnt/
[root@ceph-client ~]# ll /mnt/
total 1789
-rw------- 1 root root 1831397 Jun 1 17:15 messages
四、常用命令总结
ceph osd lspools #列出存储池
ceph pg stat #查看 pg 状态,如果是active+clean表示极佳状态
ceph osd pool stats myrdb1 #查看存储池 myrdb1 状态,osd坏掉会产生日志
ceph df #查看集群存储状态
ceph df detail #查看集群存储状态详情
ceph osd stat #查看 osd 状态
ceph osd dump #显示 OSD 的底层详细信息
ceph osd tree #显示 OSD 和节点的对应关系
ceph mon stat #查看 mon 节点状态
ceph mon dump #查看 mon 节点的 dump 信息
删除存储池,在ceph-deploy上执行
ceph tell mon.* injectargs --mon-allow-pool-delete=true #告诉所有mon节点,有存储池需要删除
ceph osd pool rm mypool mypool --yes-i-really-mean-it #移除名为mypool的存储池
ceph tell mon.* injectargs --mon-allow-pool-delete=false #告诉所有mon节点,存储池删除功能关闭

















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









