






 SIGMOD'19论文介绍了FITing-Tree,这是一种针对OLTP负载优化的索引结构,旨在减少空间占用。与传统B+tree相比,FITing-Tree仅存储线性段的起点键值和斜率,通过数据分布属性实现更小的索引大小。文章提出了分割算法和成本模型,允许DBA调整误差参数以平衡查找性能和空间。在有序数据集上,FITing-Tree构建线性段,并在无序数据上使用KeyPages进行重新排序。查找过程包括B+tree定位和segment内的二分查找。
SIGMOD'19论文介绍了FITing-Tree,这是一种针对OLTP负载优化的索引结构,旨在减少空间占用。与传统B+tree相比,FITing-Tree仅存储线性段的起点键值和斜率,通过数据分布属性实现更小的索引大小。文章提出了分割算法和成本模型,允许DBA调整误差参数以平衡查找性能和空间。在有序数据集上,FITing-Tree构建线性段,并在无序数据上使用KeyPages进行重新排序。查找过程包括B+tree定位和segment内的二分查找。
【论文阅读】SIGMOD’19 FITing-Tree: A Data-aware Index Structure
介绍
传统的索引结构(比如B+tree),需要消耗大量的空间,在一些OLTP负载下,索引可以占据55%的空间。这种开销不仅限制了可用于存储新数据的空间量,而且还减少了在处理现有数据时有用临时空间。
尽管有一些压缩方案可以减小索引大小,但是索引依然随着存储键值的增加线性增长。
贡献
作者提出了FITing-Tree,利用有关底层数据分布的属性来减小索引的大小。
提出并分析了一种有效的分割算法,该算法结合了可调误差参数,允许DBA平衡索引的查找性能和空间占用。
提出一种成本模型,该模型帮助DBA在给定延迟或存储需求的情况下确定适当的错误阈值。
FITing-tree
与传统索引存储所有value不同,FITing-tree只存储1.每一个linear segment的开始键值;2.线性函数的斜率。通过这两个就可以计算出key的大致位置。
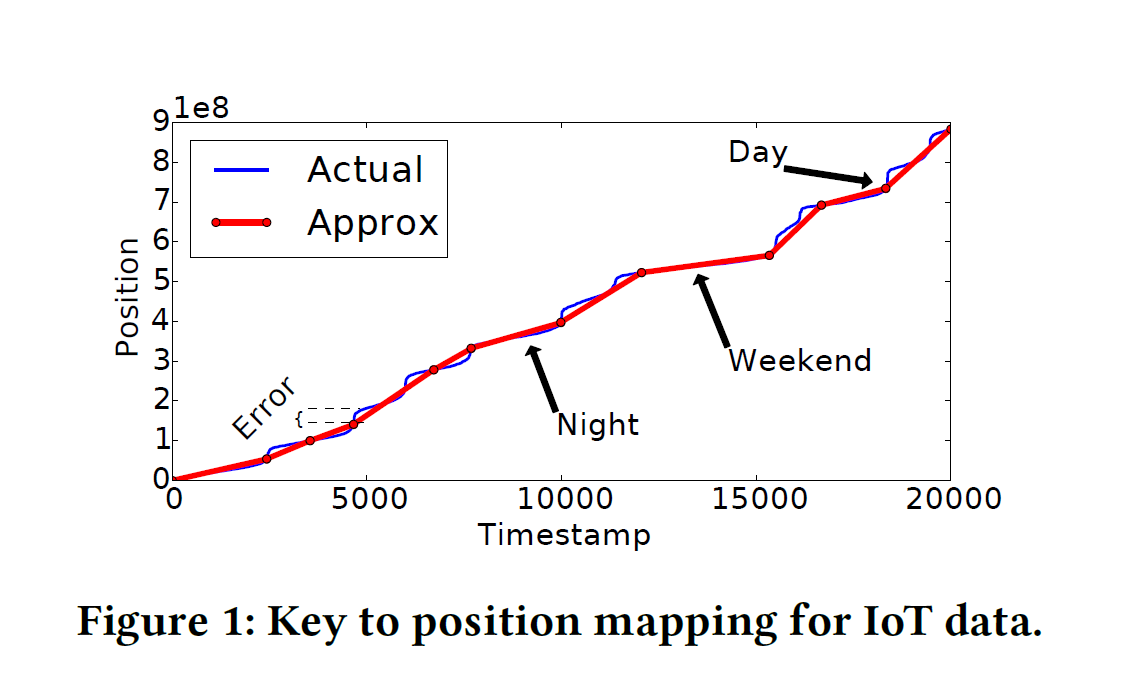
作者通过一个IOT数据集作为演示,IOT数据集的数据以事件发生的时间戳为键值已经排序好。我们可以通过构造函数去将timestamp信息映射到数据集中的存储位置。
设计
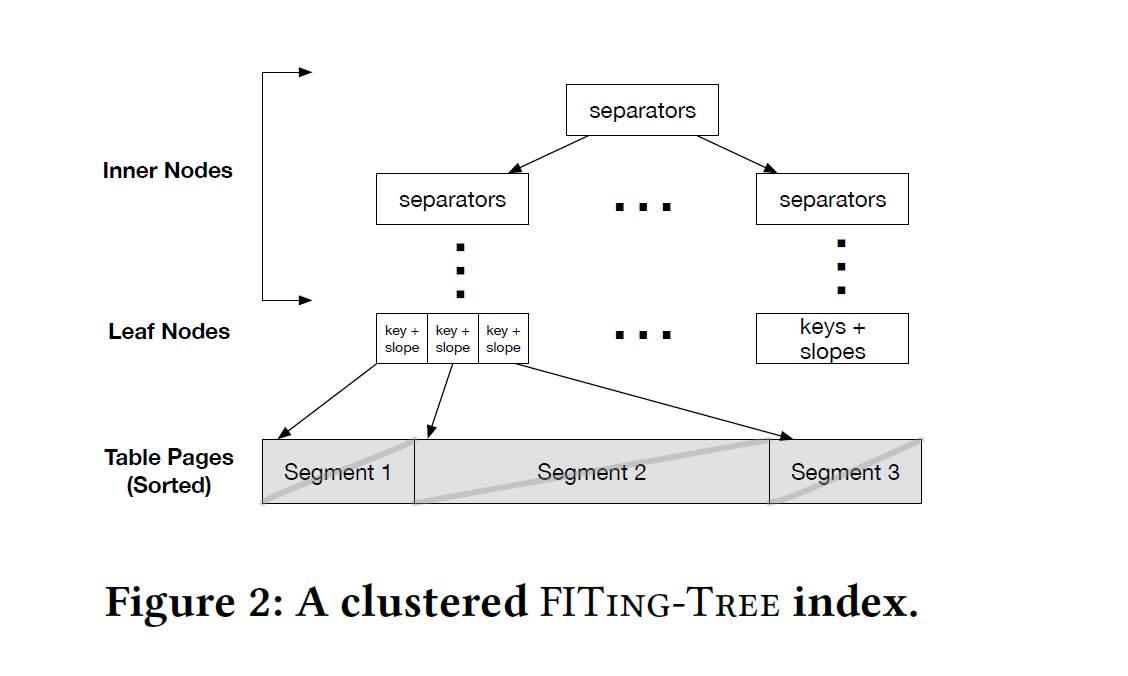
clustered FITing Tree
数据已经根据键值排序号(只有数据有序的情况下,才可以建模预测)
在传统的B+tree上,数据存储在固定大小的page中。
在FITing-tree中,数据根据给定的误差阈值被划分为不同大小的segment。每一个segment是一个数组(存储连续),不同的segment之间是独立的(不连续)。FITing-tree每个叶子节点存储的segment的斜率、最小键值、指向segment开始页面的指针。
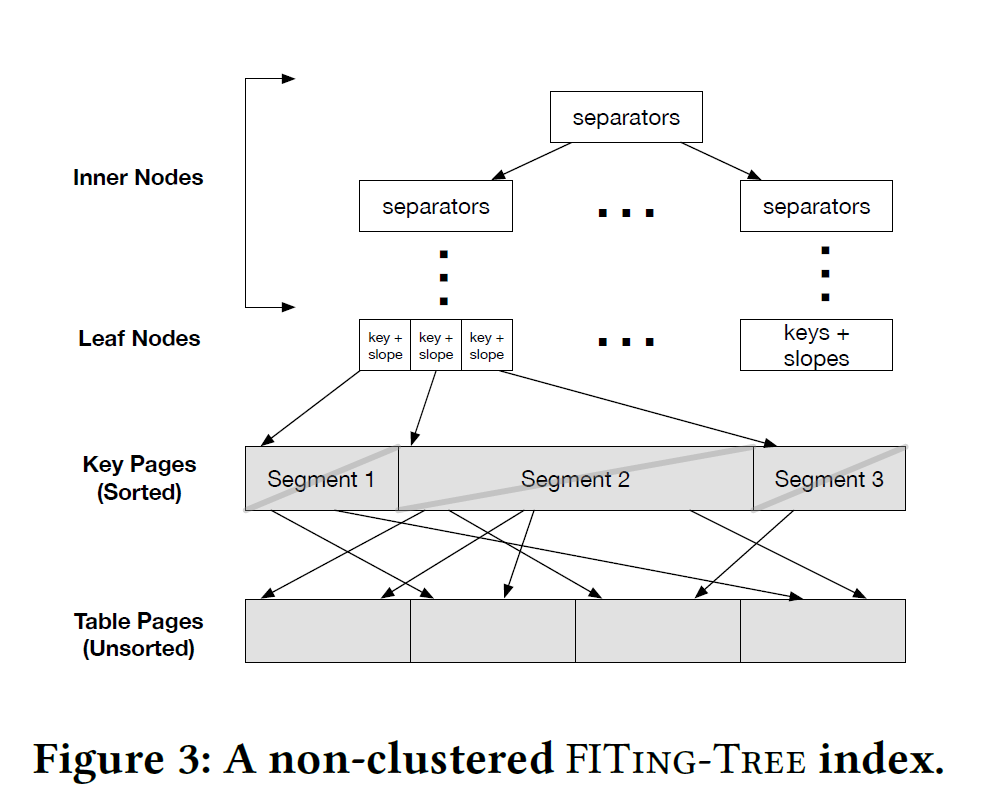
non-clustered FITing-Tree
对于没有排序好的数据,作者需要一个额外的中间层indirection layer又叫(Key Pages),将索引的键值进行重新排序然后在重新排序的数据上构造clustered FITing-Tree。
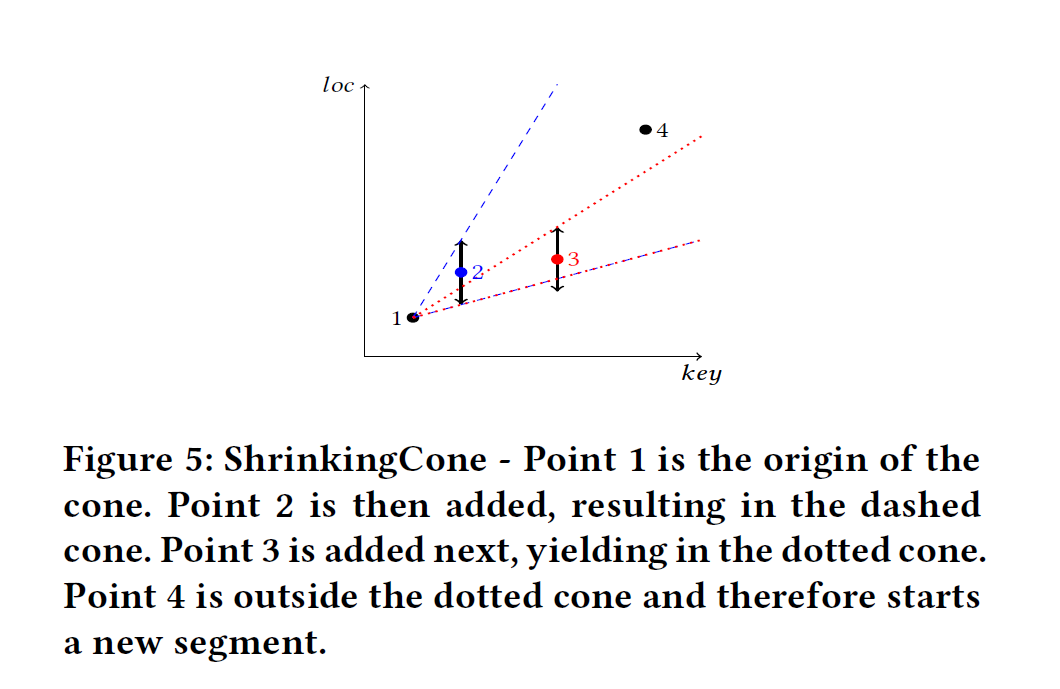
SEGMENTATION
构造segment:首先获取一个最小值key,当一个新key到的时候,根据error_bound,计算出满足误差的最小斜率和最大斜率,更新这个这两个斜率。如果新key不满足原先的最小、最大斜率,就重新建立一个新的segment。

查找
在Fiting-tree里的查找分为两个步骤。首先根据Btree定位到一个segment。然后再在segment里查找到目标的位置。
SerachTree:
找到一个最大的小于key的节点,如果没有到达叶子节点就继续往下递归查找,如果达到了叶子节点,找到leafnode里最大的小于key的节点然后返回。
SearchSegment:
我们通过返回的节点可以知道这个segment的斜率。 所以我们可以通过最小key和斜率计算出一个大概的position。由于我们的模型预测不太准确会有误差,但是在一个segment中不会位置超过过给定error的范围。所以我们需要在预测position + - error的这个范围二分查找到最终的值。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











