







MySQL逻辑分层

sql解析顺序
书写顺序
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
mysql解析器执行的顺序
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
索引
问题:为什么千万条数据下加了索引依然很快?
答:mysql底层存索引的数据结构
-
二叉树 如果索引是顺序的,二叉树就退化成了一个链表

-
红黑树 红黑树存在高度问题,如果高度是20,要查的索引在叶子节点,需要查20次

-
Hash 对索引的key进行hash计算,算出存储位置,很多时候性能比B+树好,有hash冲突,不支持范围查询

-
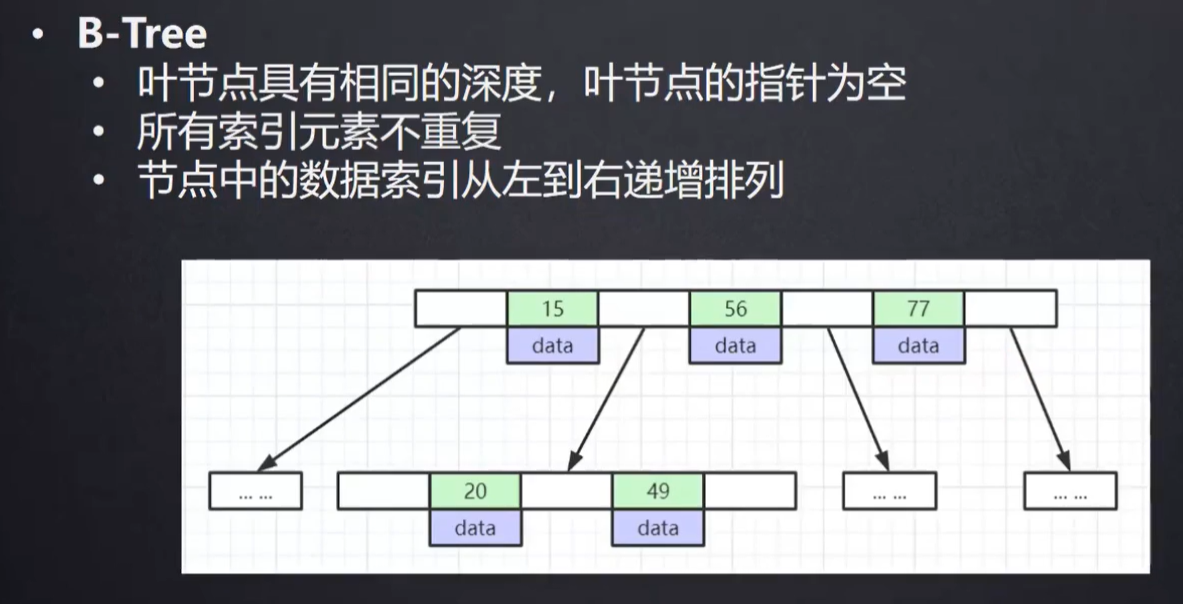
B树 B树的一个节点可以存放多个索引节点(数据+地址),索引数据是从左到右顺序递增
叶子节点上和非叶子节点上的索引节点大概1KB的大小,索引每个节点能存16个索引节点
假设这个B树有3层,能存放161616=4096,大概四千个索引节点,而且查找只需要3次
-
B+树 B+树的索引数据都放在叶子节点上,非叶子节点只存放索引(冗余),不放数据
假如给一个节点分配16KB的数据,非叶子节点上的一个索引节点(数据8B+地址6B)大约14B的大小,所以一个非叶子节点总共能存1170个索引节点
叶子节点上的索引节点大概1KB的大小,所以一个叶子节点能放16个索引节点
假设这个B+树有3层,能存放1170117016=21902400,大概两千万个索引节点,而且查找只需要3次

B+树相比B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
存储引擎:
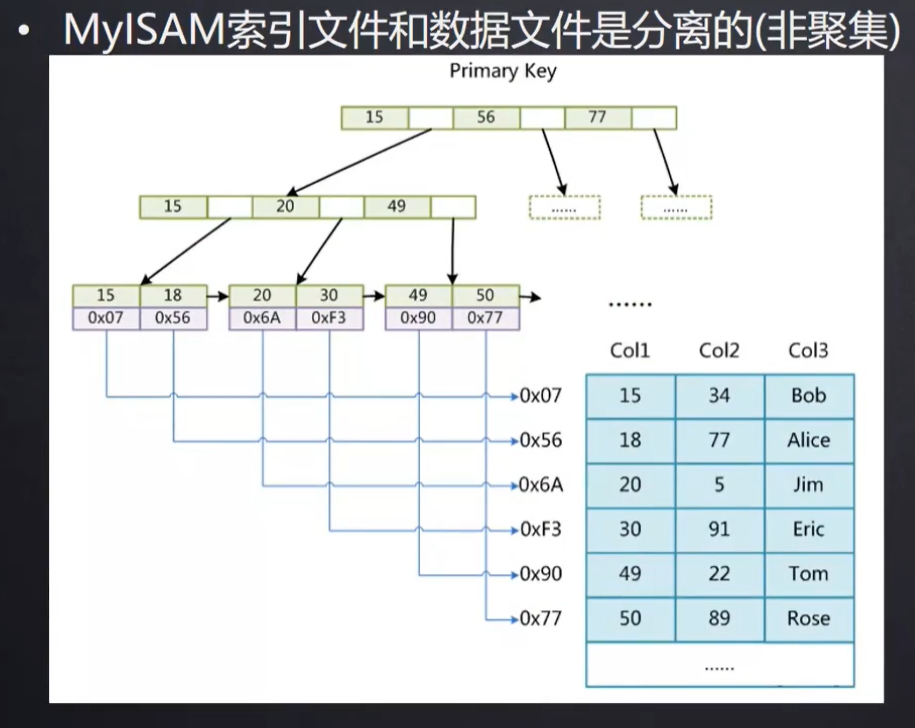
MyISAM:非聚集索引 索引和数据分开
每个MyISAM在磁盘上存储成三个文件
(1)frm文件:存储表的结构
(2)MYD文件:存放具体数据
(3)MYI文件:存储索引 索引放的是索引所在行的磁盘文件地址
InnoDB:聚集索引(聚簇索引) 索引和数据存在一起
每个InnoDB:在磁盘上存储成两个文件
(1)frm文件:存储表的结构
(2)ibd文件:存放索引所在行的其他列的数据

InnoDB的主键索引是聚集索引, 二级索引(非主键索引)的叶子节点放的是主键元素,然后去主键索引中拿到完整数据,也存在回表
为什么建议InnoDB必须建主键,并且推荐使用整型自增主键?
必须建主键?
mysql资源宝贵,自己能做的,不要麻烦数据库,影响性能
InnoDB底层必须要有个主键索引使用B+树维护数据,如果不建索引,mysql底层会在表中开始找
从最左边的列开始找,如果发现这一列的所有数据都不同,就会用这一列维护表的数据
如果一列都找不到,mysql会加一个隐藏列,用这个隐藏列维护表的数据
为什么使用整型?
查找索引时要进行比大小,整型比大小快
为什么要自增?
B+树的叶子节点要维护一个从左到右递增的顺序,
自增的话,一直会向后加,树节点进行分裂的概率很小
不是自增的话,有可能加到中间,数节点放满了就会进行分裂,而分裂非常耗费性能
优化
看执行计划,看是否合理的走了索引,然后看Extra,最好达到Using index,然后是type,最好达到ref
单表优化:
1.最佳左前缀,保证索引的定义和使用的顺序一致性
2.索引逐步优化
3.范围查询放在最后,防止索引失效
多表优化:
1.索引加在哪个表?
小表驱动大表,小表写在连接条件的左边,【对于左连接,给左表加索引,右连接,给右表加索引】
2.索引建立在经常查询的字段上
常用优化方法:
1.不要使用sleect *
2.exist和in
- 如果主查询的数据集大,用in(外表大而内表小的情况)
- 如果子查询的数据集大,用exist(外表小而内表大的情况)
3.order by
Using filesort有两种算法:单路排序、双路排序(根据IO次数)
- MySQL4.1前,默认双路排序:扫描两次磁盘 1)从磁盘读取排序字段,对排序字段进行排序(在buffer中进行的排序) 2)扫描其他字段
- MySQL4.1后,默认单路排序:只读取一次(全部字段),在buffer中进行排序,有隐患,不一定是真的单次,如果数据量特别大,无法将所有数据一次性读完,因此,会进行“分片读取、多次读取”
单路排序使用时,根据数据量,可以调大buffer的大小:set max_length_for_sort_data = 1024 单位byte - 如果max_length_for_sort_data太小,则mysql会自动从单路->双路
1.选择单路、双路。调整buffer的大小
2.避免select *
3.复合索引不要跨列使用,避免Using filesort
4.保证排序字段的一致性(都升序或降序)
避免索引失效:
1.尽量使用索引覆盖
2.复合索引不要跨列或无序使用(最佳左前缀),尽量使用全索引匹配
3.不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效
4.范围查询放在最后,否则范围查询后面的索引失效
5.复合索引不能使用不等于(!= <>)或 is null(is not null),否则自身以及右侧索引全部失效
6.like尽量以“常量”开头,不要以’%'开头,否则索引失效
7.字符串不加单引号(类型转换),索引失效
8.尽量不适用or,否则索引失效,用in代替
9.尽量避免子查询,而用join
SQL排查
慢查询日志:MySQL提供一种日志记录,用于记录MySQL中响应时间超阀值的SQL语句(long_query_time 默认10s)
相关参数:
-
slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭。
-
log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
-
slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
-
long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志。
-
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
-
log_output:日志存储方式。log_output=‘FILE’表示将日志存入文件,默认值是’FILE’。log_output='TABLE’表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output=‘FILE,TABLE’。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
日志分析工具mysqldumpslow
在实际生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow
查看mysqldumpslow的帮助信息:
1 [root@localhost~]# mysqldumpslow --help
2 Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
3
4 Parse and summarize the MySQL slow query log. Options are
5
6 --verbose verbose
7 --debug debug
8 --help write this text to standard output
9
10 -v verbose
11 -d debug
12 -s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
13 al: average lock time
14 ar: average rows sent
15 at: average query time
16 c: count
17 l: lock time
18 r: rows sent
19 t: query time
20 -r reverse the sort order (largest last instead of first)
21 -t NUM just show the top n queries
22 -a do not abstract all numbers to N and strings to 'S'
23 -n NUM abstract numbers with at least n digits within names
24 -g PATTERN grep: only consider stmts that include this string
25 -h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
26 default is '*', i.e. match all
27 -i NAME name of server instance (if using mysql.server startup script)
28 -l don't subtract lock time from total time
例子:
-s, 是表示按照何种方式排序
c: 访问计数
l: 锁定时间
r: 返回记录
t: 查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如:
得到返回记录集最多的10个SQL。
mysqldumpslow -s r -t 10 /database/mysql/mysql06_slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /database/mysql/mysql06_slow.log
得到按照时间排序的前10条里面含有左连接的查询语句。
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/mysql06_slow.log
另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现刷屏的情况。
mysqldumpslow -s r -t 20 /mysqldata/mysql/mysql06-slow.log | more















 6530
6530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









