






在大数据时代,Hadoop作为分布式存储和计算的核心框架,受到了众多开发者的青睐。而伪分布模式则是在单台服务器上模拟分布式环境,非常适合开发和学习使用。本文将详细介绍如何搭建Hadoop伪分布模式,帮助大家快速上手。
一、环境安装
(一)安装 JDK
Hadoop 是基于 Java 开发的,因此在安装 Hadoop 之前,需要先安装 JDK。以下是安装 JDK 的详细步骤:
下载地址:https://www.oracle.com/cn/java/technologies/downloads/
1.创建安装包存放目录
mkdir -p /opt/modules # 用于存放安装包
mkdir -p /opt/installs # 用于存放解压后的软件
这样可以方便地管理和查找安装文件。
2.上传安装包至 Linux 系统
将下载好的 JDK 安装包(如 jdk-8u451-linux-x64.tar.gz)上传至 Linux 系统的 /opt/modules 目录下。可以使用工具如 WinSCP 等进行上传。
3.解压安装包
tar -zxvf /opt/modules/jdk-8u451-linux-x64.tar.gz -C /opt/installs/
将 JDK 解压到 /opt/installs 目录下
4.重命名
cd /opt/installs
mv jdk1.8.0_451 jdk
将解压后的文件夹重命名为 jdk,便于后续操作。
5.配置环境变量
输入以下命令编辑 /etc/profile 文件:
vi /etc/profile
在文件中追加以下内容:
export JAVA_HOME=/opt/installs/jdk
export PATH=$PATH:$JAVA_HOME/bin
6.刷新配置文件
source /etc/profile
使配置文件生效,确保环境变量设置成功。
(二)安装 Hadoop
接下来安装 Hadoop,以下是详细的安装步骤:
1.上传 Hadoop 安装包
下载地址:https://dlcdn.apache.org/hadoop/common/
将下载好的 Hadoop 安装包(如 hadoop-3.3.5.tar.gz)上传至 Linux 系统的 /opt/modules 目录下。
2.解压安装包
tar -zxvf /opt/modules/hadoop-3.3.5.tar.gz -C /opt/installs/
将 Hadoop 解压到 /opt/installs 目录下。
3.重命名
cd /opt/installs/
mv hadoop-3.3.5 hadoop
将解压后的文件夹重命名为 hadoop,便于后续操作。
4.配置环境变量
编辑 /etc/profile 文件:
vi /etc/profile
在文件中追加以下内容:
export HADOOP_HOME=/opt/installs/hadoop
#此语句在java安装的时候已有前面部分,追加即可
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.刷新配置文件
source /etc/profile
6.验证 Hadoop 是否安装成功
hadoop version
如果安装成功,将显示 Hadoop 的版本信息,如下图所示:

(三)关闭防火墙
为了确保 Hadoop 集群的正常通信,需要关闭防火墙。输入以下命令查看防火墙状态:
systemctl status firewalld
如果防火墙处于开启状态,可以使用以下命令关闭防火墙:
systemctl stop firewalld
(四)免密登录
在 Hadoop 集群中,为了方便节点之间的通信,需要设置免密登录。以下是设置免密登录的步骤:
生成密钥对
输入以下命令生成密钥对:
ssh-keygen -t rsa
按回车键接受默认设置,生成密钥对后,会在 ~/.ssh 目录下生成 id_rsa 和 id_rsa.pub 两个文件。
将公钥复制到本机
输入以下命令将公钥复制到本机:
ssh-copy-id 主机名
在提示输入密码时,输入当前用户的密码。主机名可以通过 hostname 命令查看。
测试免密登录
输入以下命令测试免密登录是否成功
ssh 主机名
如果成功,将直接登录到本机,无需输入密码。
(五)修改 Linux 安全机制
为了确保 Hadoop 集群的正常运行,需要修改 Linux 的安全机制。输入以下命令编辑 /etc/selinux/config 文件:
vi /etc/selinux/config
将文件中的 SELINUX=enforcing 修改为 SELINUX=disabled,然后保存并退出。
(六)设置 host 映射
为了方便节点之间的通信,需要设置 host 映射。输入以下命令编辑 /etc/hosts 文件:
vi /etc/hosts
在文件中添加以下内容:
本机ip地址 主机名
将 主机名 替换为实际的主机名
二、配置核心文件
(一)修改配置文件
Hadoop 的配置文件位于 /opt/installs/hadoop/etc/hadoop 目录下。以下是修改配置文件的详细步骤:
1.修改 core-site.xml
cd /opt/installs/hadoop/etc/hadoop
vi core-site.xml
修改内容如下:
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>
将 主机名 替换为实际的主机名。
2.修改 hdfs-site.xml
vi hdfs-site.xml
修改内容如下:
<configuration>
<property>
<!--备份数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>主机名:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>主机名:9870</value>
</property>
</configuration>
将 主机名 替换为实际的主机名。
3.修改 hadoop-env.sh
vi hadoop-env.sh
修改内容如下:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/opt/installs/jdk
确保 JAVA_HOME 的路径与之前安装的 JDK 路径一致。
4.修改 workers 文件
vi workers
修改内容为:
自己的主机名
例如:
hadoop01
(二)格式化 namenode
对整个集群进行 namenode 格式化,输入以下命令
hdfs namenode -format
格式化其实就是创建了一系列的文件夹,如 logs 和 tmp。如果需要再次格式化,需要先删除这两个文件夹,然后再进行格式化。
(三)启动集群
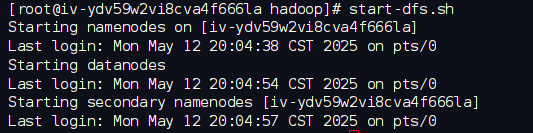
输入以下命令启动dfhs:
start-dfs.sh
如果启动成功,将显示如下图所示的信息:
(四)访问 HDFS 集群
过浏览器访问 HDFS 集群,输入以下网址:
http://192.168.233.128:9870/
将 192.168.233.128 替换为实际的 IP 地址。如果访问成功,将显示如下图所示的界面: 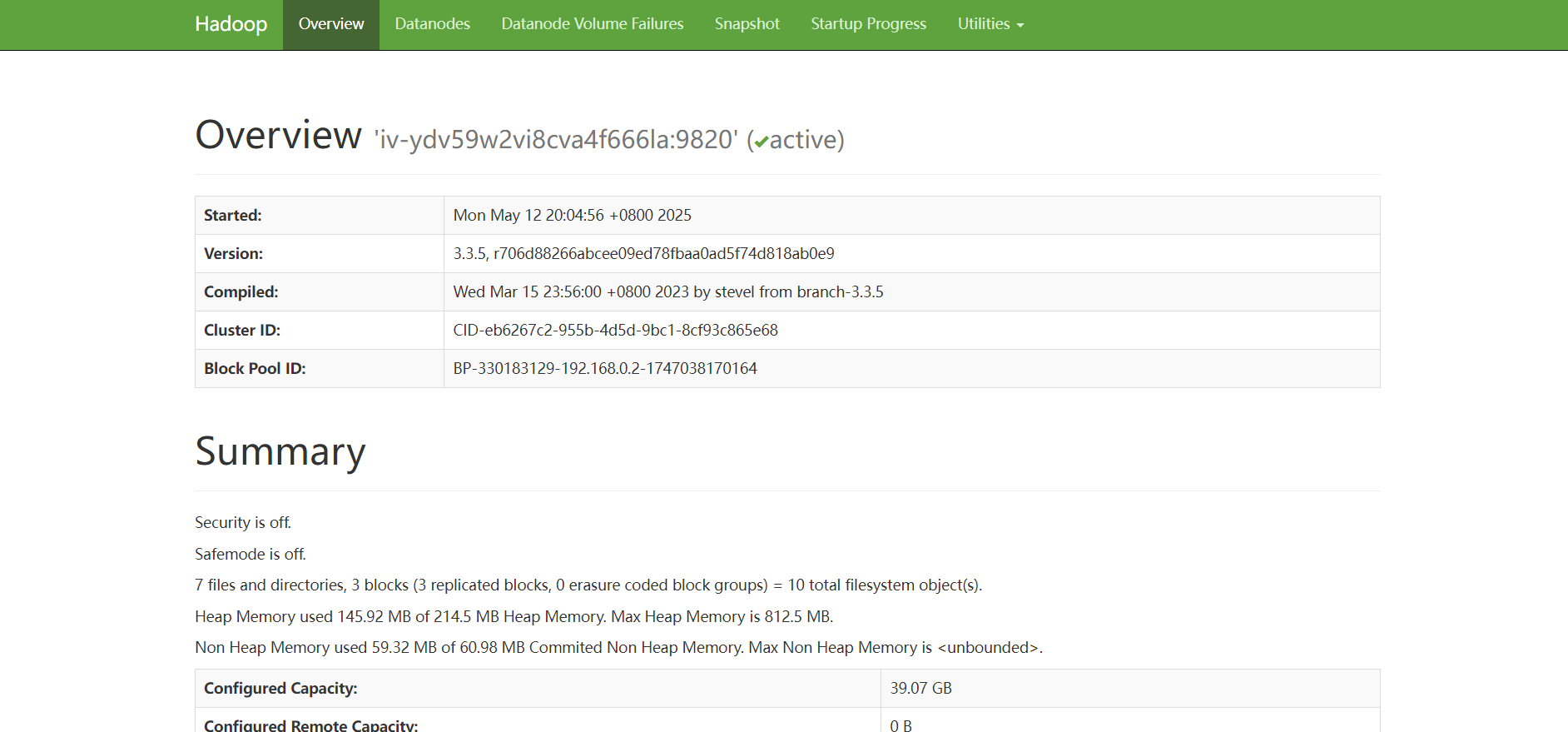
三、运行 WordCount 示例
为了验证 Hadoop 集群的运行情况,可以运行 WordCount 示例。以下是运行 WordCount 示例的详细步骤:
先创建一个word.txt
hello world spark flink
hello mostarc 2025 mostarc
hello suibian suibian hello
1.上传文件至 HDFS 文件系统
hdfs dfs -mkdir /home
hdfs dfs -put /home/word.txt /home
将本地文件 /home/wc.txt 上传至 HDFS 文件系统中的 /home 目录下。
2.运行 WordCount 示例
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /home/word.txt /home/output
使用 WordCount 程序对上传的文件进行统计。
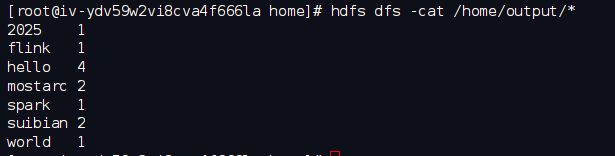
3.查看统计结果
hdfs dfs -cat /home/output/*
查看统计结果,如下图所示:
四、总结
通过以上步骤,我们成功搭建了 Hadoop 伪分布模式,并运行了 WordCount 示例。伪分布模式非常适合开发和学习使用,可以帮助我们更好地理解和掌握 Hadoop 的分布式存储和计算原理。在实际生产环境中,可以根据需要扩展为全分布模式,以满足大规模数据处理的需求。
如果你在搭建过程中遇到任何问题,欢迎在评论区留言,我会及时为你解答。希望这篇文章对你有所帮助,祝你在大数据学习的道路上越走越远!

















 4271
4271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









