







学习资料来源:小林coding
侵权删除
数据库学习笔记二:事务篇
目录
事务隔离级别是怎么实现的?
事务有哪些特性?
原子性(Atomicity)一致性(Consistency)隔离性(Isolation)持久性(Durability)
InnoDB 引擎通过什么技术来保证事务的这四个特性的呢?
- 持久性是通过 redo log (重做日志)来保证的;
- 原子性是通过 undo log(回滚日志) 来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
- 一致性则是通过持久性+原子性+隔离性来保证;
并行事务会引发什么问题?
脏读
事务A「读到」了事务B「修改过但未提交的数据(发生回滚)」。
不可重复读
在事务A多次读取事务B的同一个数据,出现前后两次数据不一样。
幻读(有范围的脏读)
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
事务的隔离级别有哪些?
- 脏读:读到其他事务未提交的数据;
- 不可重复读:前后读取的数据不一致;
- 幻读:前后读取的记录数量不一致。
这三个现象的严重性排序如下:

SQL 标准提出了四种隔离级别来规避这些现象,隔离级别越高,性能效率就越低,这四个隔离级别如下:
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 可串行化(serializable );会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:
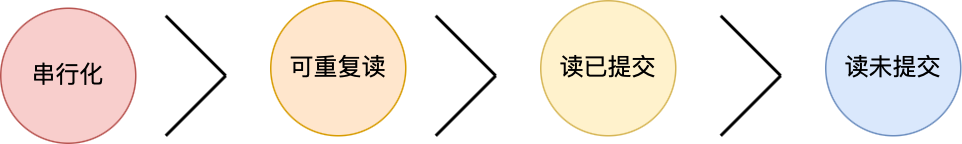
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
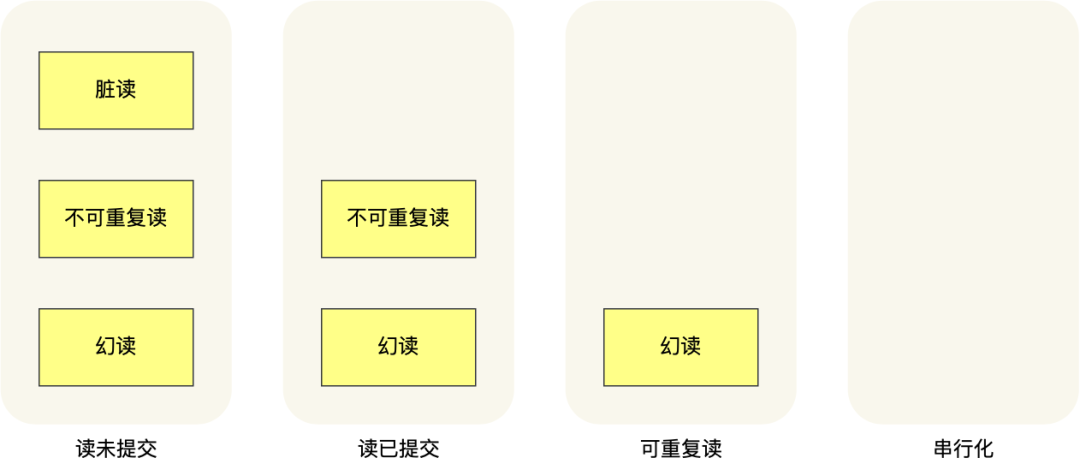
所以,要解决脏读现象,就要升级到「读提交」及以上的隔离级别;要解决不可重复读现象,就要升级到「可重复读」的隔离级别。
不过,要解决幻读现象不建议将隔离级别升级到「串行化」,因为这样会导致数据库在并发事务时性能很差。
InnoDB 引擎的默认隔离级别是「可重复读」,但是它通过next-key lock 锁(行锁和间隙锁的组合)来锁住记录之间的“间隙”和记录本身,防止其他事务在这个记录之间插入新的记录,这样就避免了幻读现象。
这四种隔离级别具体是如何实现的呢?
- 对于「读未提交」隔离级别的事务来说,因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好了;
- 对于「串行化」隔离级别的事务来说,通过加读写锁的方式来避免并行访问;
- 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照。「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View,而「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View。
注意,执行「开始事务」命令,并不意味着启动了事务。在 MySQL 有两种开启事务的命令,分别是:
- 第一种:begin/start transaction 命令;
- 第二种:start transaction with consistent snapshot 命令;
这两种开启事务的命令,事务的启动时机是不同的:
- 执行 begin/start transaction 命令后,并不代表事务启动了。只有在执行这个命令后,执行了增删查改操作的 SQL 语句,才是事务真正启动的时机;
- 执行 start transaction with consistent snapshot 命令,就会马上启动事务。
接下来详细说下,Read View 在 MVCC 里如何工作的?
Read View 在 MVCC 里如何工作的?
我们需要了解两个知识:
- Read View 中四个字段作用;
- 聚簇索引记录中两个跟事务有关的隐藏列;
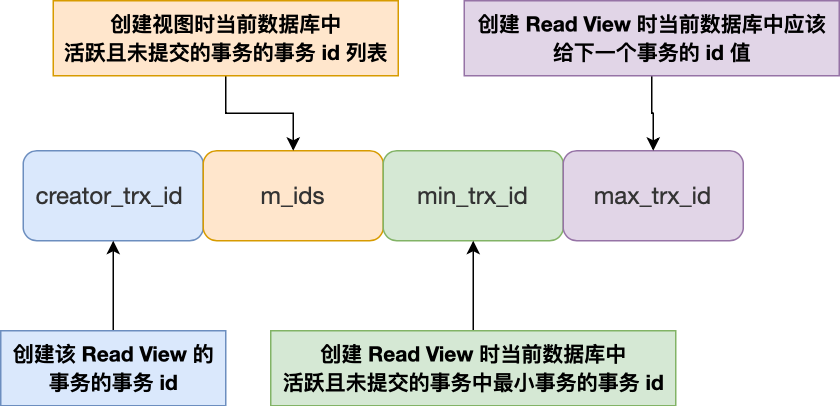
Read View 有四个重要的字段:
- m_ids :指的是在创建 Read View 时,当前数据库中 启动 但 未提交 的事务的 事务 id 列表,注意是一个列表。
- min_trx_id :m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
知道了 Read View 的字段,我们还需要了解聚簇索引记录中的两个隐藏列。
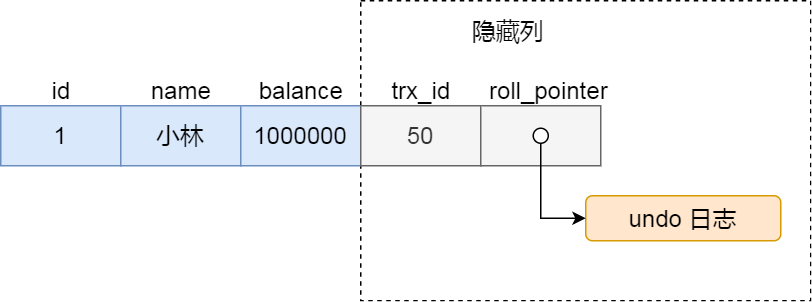
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:

一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 记录的 trx_id 值小于 Read View 中的
min_trx_id值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。 - 记录的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。 - 记录的 trx_id 值在 Read View 的
min_trx_id和max_trx_id之间,需要判断 trx_id 是否在 m_ids 列表中:- 如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。 - 如果记录的 trx_id 不在
m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 在
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
可重复读是如何工作的?
可重复读隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View。
读提交是如何工作的?
读提交隔离级别是在每次读取数据时,都会生成一个新的 Read View。
总结
事务是在 MySQL 引擎层实现的,我们常见的 InnoDB 引擎是支持事务的,事务的四大特性是原子性、一致性、隔离性、持久性,我们这次主要讲的是隔离性。
当多个事务并发执行的时候,会引发脏读、不可重复读、幻读这些问题,那为了避免这些问题,SQL 提出了四种隔离级别,分别是读未提交、读已提交、可重复读、串行化,从左往右隔离级别顺序递增,隔离级别越高,意味着性能越差,InnoDB 引擎的默认隔离级别是可重复读。
要解决脏读现象,就要将隔离级别升级到读已提交以上的隔离级别,要解决不可重复读现象,就要将隔离级别升级到可重复读以上的隔离级别。
而对于幻读现象,不建议将隔离级别升级为串行化,因为这会导致数据库并发时性能很差。InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它通过 next-key lock 锁(行锁+间隙锁的组合)来锁住记录之间的“间隙”和记录本身,防止其他事务在这个记录之间插入新的记录,这样就避免了幻读现象。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 **Read View **来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
在可重复读隔离级别中,普通的 select 语句就是基于 MVCC 实现的快照读,也就是不会加锁的。而 select .. for update 语句就不是快照读了,而是当前读了,也就是每次读都是拿到最新版本的数据,但是它会对读到的记录加上 next-key lock 锁。
幻读是怎么被解决的?
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是启动事务后,在执行第一个查询语句后,会创建一个视图,然后后续的查询语句都用这个视图,「快照读」读的就是这个视图的数据,视图你可以理解为版本数据,这样就使得每次查询的数据都是一样的。
MySQL 里除了普通查询是快照度,其他都是当前读,比如update、insert、delete,这些语句执行前都会查询最新版本的数据,然后再做进一步的操作。
这很好理解,假设你要 update 一个记录,另一个事务已经 delete 这条记录并且 提交事务了,这样不是会产生冲突吗,所以 update 的时候肯定要知道最新的数据。
另外,select ... for update 这种查询语句是当前读,每次执行的时候都是读取最新的数据。
因此,要讨论「可重复读」隔离级别的幻读现象,是要建立在「当前读」的情况下。
Innodb 引擎为了解决「可重复读」隔离级别使用「当前读」而造成的幻读问题,就引出了 next-key 锁,就是记录锁和间隙锁的组合。
- 记录锁,锁的是记录本身;
- 间隙锁,锁的就是两个值之间的空隙,以防止其他事务在这个空隙间插入新的数据,从而避免幻读现象。
需要注意的是,next-key lock 锁的是索引,而不是数据本身,所以如果 update 语句的 where 条件没有用到索引列,那么就会全表扫描,在一行行扫描的过程中,不仅给行加上了行锁,还给行两边的空隙也加上了间隙锁,相当于锁住整个表,然后直到事务结束才会释放锁。
所以在线上千万不要执行没有带索引的 update 语句,不然会造成业务停滞。















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









