







一,mysql安装卸载
安装卸载:mysql安装和卸载
二,SQLyog 下载 中文版 破解版 注册码
参考:SQLyog 下载 中文版 破解版 注册码
参考:SQLyog图形化l数据库的操作和学习
三,mysql语句及优化
1.mysql和oracle大致相同,下面回忆一些不同的地方
mysql基础语句参考oracle链接:Oracle使用总结
1.mysql使用limit分页,limit(x,y) 从第x行开始,截取y行,数据库默认从0开始。
oracle使用rownum
--mysql
select * from table limit 0, 10
--oracle
select * from (select * ,rownum as rn from table) where rn <= 10
2.多条件判断,case使用
--mysql
SELECT
CASE id
WHEN 1 THEN id
WHEN 3 THEN NAME
ELSE id
END
FROM task_work
--oracle 除了有case when还有简写方式的decode
-- 行列转换
SELECT ID,NAME,
SUM(DECODE(course,'语文',score,0)) 语文,
SUM(DECODE(course,'数学',score,0)) 数学,
SUM(DECODE(course,'英语',score,0)) 英语,
SUM(DECODE(course,'历史',score,0)) 历史,
SUM(DECODE(course,'化学',score,0)) 化学
FROM kecheng
GROUP BY ID ,NAME
2.函数使用
-- 格式化时间,字符串转时间
date_format(date,'%Y-%m-%d');
str_to_date(date,'%Y-%m-%d');
-- substr使用方法不同, oracle 从0 开始, mysql 从1
-- 空概念
oracle 的空和mysql的空不是同样的概念
oracle ''等同于null, mysql '' 不等同于null
4.主键自增
Mysql可以给表主键设置自增,添加数据时不需要设置id,数据库会自动设置id;
Oracle没有主键自增,如果需要设置自增,需要给表添加自增序列;
添加数据时,从序列中取下一个值作为id;
5.分组排序
MySql的group by与oracle有所不同,查询得字段可以不用写聚合函数,查询结果取得是每一组的第一行记录。group by默认按id升序,mysql5.7以及以后在子查询内部 使用order by 可能会被忽略。
2.mysql优化
1.mysql的架构 见图
2.mysql存储引擎
MyISAM:
不支持事务
表锁
不支持外键
支持表压缩
.frm:表结构
.MYD:数据
.MYI:索引
InnoDB:
事务
行级锁
.frm:表结构
.ibd:数据和索引
show engines:查看支持的引擎
show table status like 表名\G
- mysql支持的数据类型
Int(tinyint微整形(1字节),smallint(2),mediumint(3),int(4),bigint(8))
decimal
float,double
char varchar
text, blob
date,time,datetime timestamp
4.create table a like b;//以b建一张空表
锁:读锁、写锁
lock tables 表名(read | write)
unlock tables;
5、mysql中的日志文件
1、错误日志文件,默认文件hostname.err 可以自己定义
[mysqld_safe]
Log-error=/var/log/mysqld.log
2、通用日志文件 :将所有的查询语句都会记录下来
注意:这个文件一般都是关闭的,只是需要记录时候才打开。
3、慢查询日志文件
需要慢查询打开:什么才叫慢?实质上自己可以定义
比如我定义查询时间大于3秒的就慢查询
会将查询时间大于3秒这些查询语句提取出来写慢查询日志中
我就可以分析该语句有什么问题及优化点
Slow_query_log=on|off --是否开启慢查询日志
Slow_query_log_file=路径+文件名–指定慢查询日志保存的路径和文件名,如果不指定默认是在存放数据文件的目录下名称为hostname-slow.log的文件名
long_query_time=2–指定多少秒未返回结果的语句为慢查询
Long-queries-not-using-indexes–记录所有没有使用到索引的查询语句
Min_examined_row_limit=1000–记录那些查找了多余1000次而引发的慢查询
Log-slow-admin-statements–记录那些慢的optimize table,analyze table和alter table的语句
Log-slow-slave-statements–记录由slave所产生的慢查询
8、执行计划的查看
1、使用explain可以看执行计划
对执行计划的属性说明
select_type:查询的类型
simple:不含有子查询
primary:含子查询
subquery:非from子查询
derived:from型子查询
union
2、possible_key: 可能用到的索引
3、key : 最终用的索引.
4、key_len: 使用的索引的最大长度
5、type列: 是指查询的方式。
type=all(全表扫描)
type=index
type=range 使用索引做范围扫描
type=ref 直接就使用索引就可以了
type=const 按主键或者唯一键查询
6、rows :估计要扫描的记录数
7、extra = index:是指用到了索引覆盖,效率非常高
extra = using where:是指光靠索引定位不了,还得where判断一下
extra = using temporary:是指用上了临时表, group by 与 order by 不同列时,或group by ,order by 别的表的列.
extra = using filesort:文件排序(文件可能在磁盘,也可能在内存)
总结:工作中就是不断的看执行计划,效率不对,就各种的变化sql写法
四,MySql基础
1.MySql 数据类型
1.1字符串类型
参考:mysql的char,varchar,text类型的区别总结
参考:MySQL性能优化之char、varchar、text的区别
MySQL5.0以上的VARCHAR(n)可存储中文字符和英文字符数是一致的,都是n个字符
MySQL规定:单个字段长度不能超过 65535 bytes(所有字符串类型字段包括其字段名称占用空间都计算在内, text、blob等大字段类型除外)。
编码为utf-8时,VARCHAR,TEXT最大长度是21844
总结:
- 存储定长字符串,尽量用char,索引速度极快。
- 长度255以上字符串,只能用varchar和text。
- 能用varchar就不要用text。
- text和blob不能设置默认值。
参考:MySQL TEXT数据类型的最大长度
TEXT:只能存储字符数据;包括tinytext mediumtext longtext
BLOB:用于存储二进制数据,比如照片、声音和视频;包括tinyblob longblob mediumblob
tinyblob,tinytext,最大存储为 256 bytes
blob,text,最大存储约 64kb
mediumblob,mediumtext,最大存储约 16MB
longblob,longtext,最大存储约 4GB
1.2 数值类型
无符号unsigned表示设置的数据为0或正数;有符号可以是负数;
参考:MySQL 数据类型
TINYINT: 大小1byte,有符号范围(-128,127) ,无符号范围(0,255)
SMALLINT:大小2bytes,有符号范围(-32 768,32 767),无符号范围(0,65 535)
MEDIUMINT:大小3bytes,有符号范围(-8 388 608,8 388 607),无符号范围(0,16 777 215)
INT:大小4bytes,有符号范围(-2 147 483 648,2 147 483 647),无符号范围(0,4 294 967 295)
BIGINT:大小8bytes,有符号范围(-9,223,372,036,854,775,808,9 223 372 036 854 775 807)
FLOAT:单精度浮点数,大小4bytes,Float(10,2):整数部分为8位,小数部分为2位
DOUBLE: 双精度浮点数,大小8bytes
DECIMAL:定点型小数,适合财务和货币计算的128位数据类型
小数类型:浮点型和定点型,float和double都是浮点型,而decimal是定点型;
MySQL浮点型和定点型可以用类型名称后加(M,D)来表示,M表示该值的总共长度,D表示小数点后面的长度,M和D又称为精度和标度,如float(5,2)的 可显示为999.99,MySQL保存值时会进行四舍五入,如果插入999.009,则结果为999.01。
浮点型又称为精度类型:是一种有可能丢失精度的数据类型,数据有可能不那么准确(由其是在超出范围的时候)
Float单精度类型:只能保证大概7个左右的精度(如果数据在7位数以内,那么基本是准确的,但是如果超过7位数,那么就是不准确的)
Double又称之为双精度:系统用8个字节来存储数据,表示的范围更大,10^308次方,但是精度也只有15位左右。
参考:mysql中float、double、decimal的区别
参考:mysql列类型二——小数类型(float,double,decimal)
1.3日期和时间类型
DATE:大小3字节,范围:1000-01-01/9999-12-31,格式:YYYY-MM-DD
TIME:大小3字节,范围:’-838:59:59’/‘838:59:59’,格式:HH:MM:SS
YEAR:大小1字节,范围:1901/2155,格式:YYYY
DATETIME:大小8字节,范围:1000-01-01 00:00:00/9999-12-31 23:59:59,格式:YYYY-MM-DD HH:MM:SS
TIMESTAMP:大小4字节,范围 ‘1970-01-01 00:00:01.000000’ to '2038-01-19 03:14:07.999999’的时间戳,
TIMESTAMP类型有专有的自动更新特性,字段默认设置 current_timestamp,即可自动更新时间
2.MySQL 函数
2.1字符串函数
LENGTH(s) 获取字符串的长度
CHAR_LENGTH(s) 返回字符串 s 的字符数
CONCAT(s1,s2…sn) 字符串 s1,s2 等多个字符串合并为一个字符串
CONCAT_WS(x, s1,s2…sn) 同 CONCAT(s1,s2,…) 函数,每个字符串以x 作为分隔符
FORMAT(x,n) 函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入。
LOCATE(s1,s) 从字符串 s 中获取 s1 的开始位置
LEFT(s,n) 返回字符串 s 的前 n 个字符
RIGHT(s,n) 返回字符串 s 的后 n 个字符
SUBSTR起始下标:oracle 从0 开始,mysql 从1开始
SUBSTR(s, start, length) 从字符串 s 的 start 位置截取长度为 length 的子字符串
SUBSTRING(s, start, length) , SUBSTR() 等价于 SUBSTRING() 函数
UPPER(s) 将字符串转换为大写
TRIM(s) 去掉字符串 s 开始和结尾处的空格
substring_index,参考:mysql函数substring_index的用法
CONVERT(value, type);,参考:MySQL CAST与CONVERT 函数的用法
REPEAT(‘ab’,2),'ab’表示要复制的字符串,2表示复制的份数
2.2聚合函数
sum,avg,max,min,count,聚合函数不统计值为null的行,我们可以通过distinct过滤掉重复的记录,也可以通过group by 分组。
Count([Column Name])函数不统计带有 Null 字段的记录,除非使用星号,Count 将计算所有记录的总量,包括有 Null 的字段的记录。Count(*) 比 Count ([Column Name]) 快得多。不要将星号放在引号 (’ ') 中。
SUM(expression) 返回指定字段的总和
AVG(expression) 返回一个表达式的平均值,expression 是一个字段
MAX(expression) 返回字段 expression 中的最大值
MIN(expression) 返回字段 expression 中的最小值
COUNT(expression) 返回查询的记录总数,expression 参数是一个字段或者 * 号
2.3日期函数
NOW() 返回当前日期和时间 2018-09-19 20:57:43
CURRENT_DATE() 返回当前日期 2018-09-19
CURRENT_TIME 返回当前时间 9:59:02
CURRENT_TIMESTAMP() 返回当前时间戳
DATE_FORMAT(d,f) 按表达式 f 的要求显示日期 d
SELECT DATE_FORMAT(‘2011-11-11 11:11:11’, ‘%Y-%m-%d %r’)
-> 2011-11-11 11:11:11 AM
DAY(d) 返回日期值 d 的日期部分 天的号数
HOUR(t) 返回 t 中的小时值
MINUTE(t) 返回 t 中的分钟值
DAYOFWEEK(d) 日期 d 今天是星期几,1 星期日,2 星期一,以此类推
时间与字符串相互转换
date_format(now(), ‘%Y-%m-%d’); 格式化日期
str_to_date(‘2016-01-02’, ‘%Y-%m-%d %H’); 字符串转时间
MySQL日期格式化(format)取值范围。
%Y 四位数字表示的年份(2015,2016…)
%y 两位数字表示的年份(15,16…)
%m 两位数字表示月份(01,02, …,12)
%d 两位数字表示月中天数(01,02, …,31)
%H 24小时制,两位数形式小时(00,01, …,23)
%I、%i 两位数字形式的分( 00,01, …, 59)
%S、%s 两位数字形式的秒( 00,01, …, 59)
% 文字 直接输出文字内容
常用标准格式%Y-%m-%d %H:%i:%s
SELECT DATE_FORMAT(NOW(), ‘%Y-%m-%d %H:%i:%s’)
UNIX_TIMESTAMP(),返回自’1970-01-01 00:00:00’的到当前时间的秒数差
UNIX_TIMESTAMP(date),返回自’1970-01-01 00:00:00’与指定时间的秒数差
2.4高级函数
IF(expr,v1,v2) 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。
IFNULL(v1,v2) 如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。
ISNULL(expression) 判断表达式是否为 NULL
参考:MYSQL中 datediff、timestampdiff函数的使用
DATEDIFF(date1,date2),返回两个日期之间的天数
TIMESTAMPDIFF(interval,datetime1,datetime2),以interval为单位,计算日期datetime2-datetime1的差值
参考:Mysql to_days()用法
TO_DAYS(),返回从0000年(公元1年)至当前日期的总天数。
获取昨天的数据
SELECT * FROM hx_volunteer_service_sched_record WHERE TO_DAYS(NOW()) - TO_DAYS(createTime) <= 1
参考:mysql中的instr()函数的用法
INSTR(str,substr),返回 子字符串substr 在 字符串str 中首次出现的位置;instr()函数不区分大小写,位置是从1开始,如没找到则返回0
在没有索引的情况下,instr()函数与like运算符的速度是一样的;在具有前缀搜索的LIKE运算符下,使用like运算符速度会更快一些
GROUP_CONCAT(),参考:浅析MySQL中concat以及group_concat的使用
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
3.开发经验
3.1字段升序时,NULL排在最后
ORDER BY将字段降序时,字段为NULL的数据会排在最后面
ORDER BY将字段升序时,字段为NULL的数据会排在最前面,使用ORDER BY status IS NULL,status
SELECT * FROM organ_coip_situation ORDER BY status IS NULL,status
参考:mysql排序字段为空的排在最后面
3.2 SELECT DISTINCT 语句
SELECT DISTINCT d, f FROM test
DISTINCT必须放在开头,仅返回去重后列后的数据,如果要返回其他列用group by去重
单列去重:相同列的值只保留1个。
多列去重:只有所有指定的列信息都相同,才会被认为是重复的信息。
参考:去重是distinct还是group by?
参考:sql去重复操作详解SQL中distinct的用法
3.3 group by 对多个字段进行分组
参考:mysql group by 对多个字段进行分组
GROUP BY X意思是将所有具有相同X字段值的记录放到一个分组里。
GROUP BY X, Y意思是将所有具有相同X字段值和Y字段值的记录放到一个分组里。
然后对每个分组中的数据应用聚合函数
3.4mysql插入重复问题
主键是唯一的索引,当表中有多个主键时,称为复合主键,复合主键联合保证唯一索引”。
参考:数据库为何要有复合主键(多主键)
前提:表中必须要有Unique索引,即主键或唯一键。
INSERT IGNORE INTO 如果Unique索引的字段已存在,则忽略本次新增
ON DUPLICATE KEY UPDATE 如果Unique索引的字段已存在,则执行后面的UPDATE语句,原Unique索引的字段也可修改
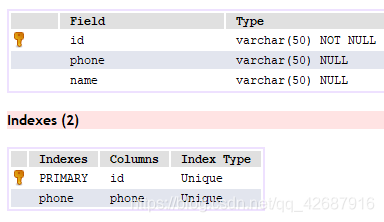
-- 如果Unique索引的字段已存在【id或phone】,则忽略本次新增
INSERT IGNORE INTO `test`(id, phone ,`name`)
VALUES('T001', '16608349001', '姓名');
-- 测试存在id
INSERT IGNORE INTO `test`(id, phone ,`name`)
VALUES('T001', '1111', '测试存在id');
-- 测试存在phone
INSERT IGNORE INTO `test`(id, phone ,`name`)
VALUES('1111', '16608349001', '测试存在phone');
-- 如果Unique索引的字段已存在【id或phone】,则执行后面的UPDATE语句,原Unique索引的字段也可修改
-- 测试存在id,此时会拿主键id作为唯一索引去UPDATE
INSERT INTO `test`(id, phone ,`name`)
VALUES('T001', '1111', '姓名')
ON DUPLICATE KEY UPDATE id='2222', phone='2222', `name`='测试存在id';
-- 测试存在phone,此时会拿唯一键phone作为唯一索引去UPDATE
INSERT INTO `test`(id, phone ,`name`)
VALUES('1111', '16608349001', '姓名')
ON DUPLICATE KEY UPDATE id='2222', phone='2222', `name`='测试存在phone';
3.5 关于 left join的优化
参考:mysql的left join和inner join的效率对比,以及如何优化
1、left join选择小表作为驱动表(这部分基本是大家的共识)
2、如果左表比较大,并且业务要求驱动表必须是左表,那么我们可以通过where条件语句,使得左表被过滤的小一些,主要原理和第一条类似
3、关联字段给索引,因为在mysql的嵌套循环算法中,是通过关联字段进行关联,并查询的,所以给关联字段索引很必要
4、如果sql里面有排序,请给排序字段加上索引,不然会造成排序使用全表扫描
参考:https://www.oschina.net/question/930697_2190172
5、如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句。
6、根据文档,MySQL能更高效地在声明具有相同类型和尺寸的列上使用索引。所以把表与表之间的关联字段给上encoding和collation(决定字符比较的规则)全部改成统一的类型
7、右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
3.6 in与not in,exists与not exists的区别以及性能分析
参考:SQL 子查询 EXISTS 和 NOT EXISTS
MySQL EXISTS 和 NOT EXISTS 子查询语法如下:
SELECT … FROM table WHERE EXISTS (subquery)
该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。
带有EXISTS 和 NOT EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或者逻辑假值“false”。
exists 和 in
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;外表大,用IN;内表大,用EXISTS。
not exists 和 not in
如果查询语句使用了not in,那么对内外表都进行全表扫描,没有用到索引;而not exists的子查询依然能用到表上的索引。所以无论哪个表大,用not exists都比not in 要快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









