







简介
DeepSeek-R1 是由杭州深度求索公司推出的高性能AI推理模型,于2025年1月20日正式发布。DeepSeek-R1,在强化学习之前整合了冷启动数据。DeepSeek-R1在数学、代码和推理任务方面的性能与OpenAI-o1相当。为了支持研究界,我们开源了DeepSeek-R1-Zero、DeepSeek-R1,以及基于Llama和Qwen从DeepSeek-R1中提取的六个密集模型。DeepSeek-R1-Distill-Qwen-32B在各种基准测试中表现优于OpenAI-o1-mini,为密集模型实现了最新的最先进结果。
核心特点
高性能推理能力
DeepSeek-R1 在数学推理、代码生成和自然语言推理等复杂任务中表现出色,性能与 OpenAI o1 正式版相当。其推理能力通过大规模强化学习(RL)技术实现,仅需极少量标注数据即可显著提升模型性能。
开源与开放协议
DeepSeek-R1 采用 MIT License 开源协议,用户可以自由使用、修改、分发和商业化该模型,包括模型权重和输出。这一举措打破了大型语言模型被少数公司垄断的局面,极大地推动了AI技术的普及和创新。
模型蒸馏支持
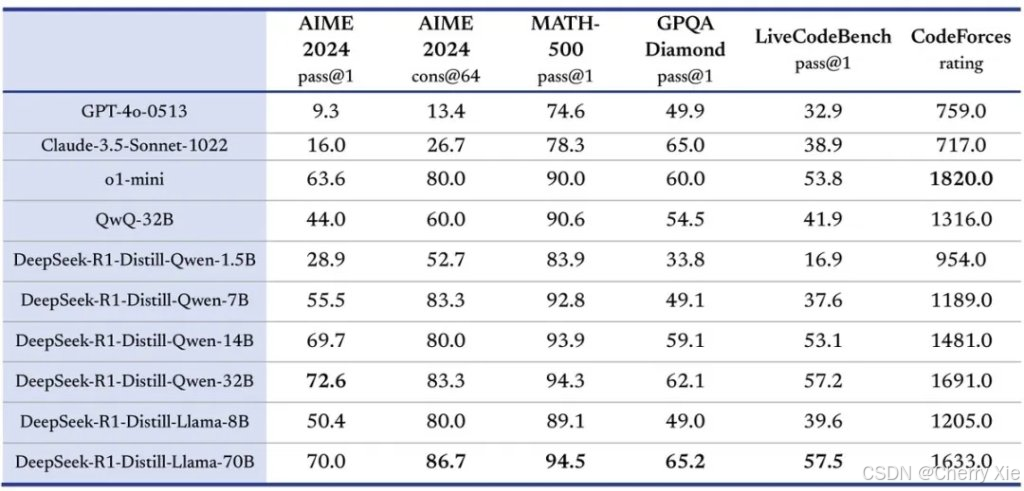
除了 DeepSeek-R1 本身,团队还开源了6个从 DeepSeek-R1 蒸馏而来的小型模型(如32B和70B模型),这些模型在多项基准测试中表现优异,甚至超越 OpenAI o1-mini。
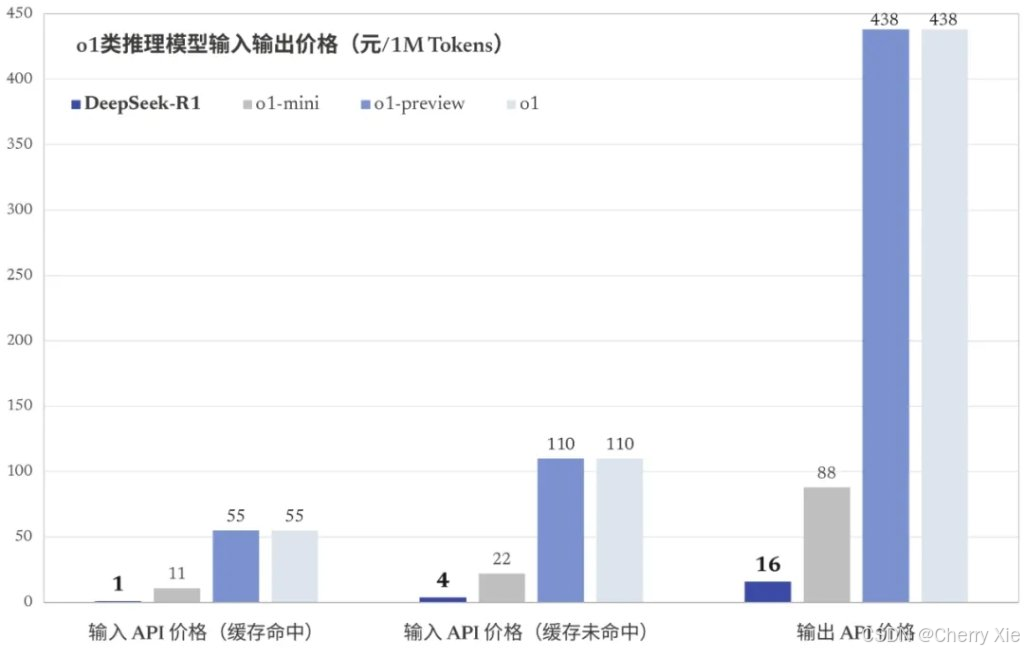
API服务与灵活计费
DeepSeek-R1 提供高效的API服务,支持按 token 计费,具体定价为:
-
输入数据:缓存命中每百万 tokens 1元,未命中为4元。
-
输出数据:每百万 tokens 16元。
这种按需计费模式适合企业和开发者根据实际需求灵活控制成本。

技术亮点
基础架构
DeepSeek-R1 是一个参数量为 660B 的大型语言模型,采用了混合专家(MoE,Mixture of Experts)架构。MoE 架构通过动态选择不同的专家网络来处理不同的输入,从而在保持模型规模的同时提升计算效率。
-
专家网络:DeepSeek-R1 的 MoE 架构包含 256 个路由专家和 1 个共享专家。每个输入 token 会激活 8 个专家,并确保每个 token 最多被发送到 4 个节点,以实现负载均衡。
-
冗余专家策略:为了进一步优化推理阶段的负载均衡,模型引入了冗余专家策略,即复制高负载专家并冗余部署。
强化学习后训练
DeepSeek-R1 在后训练阶段大规模使用强化学习技术,无需依赖监督微调(SFT)作为初步步骤。这种方法显著提升了模型的推理能力,尤其是在复杂任务中的表现。
长推理链优化
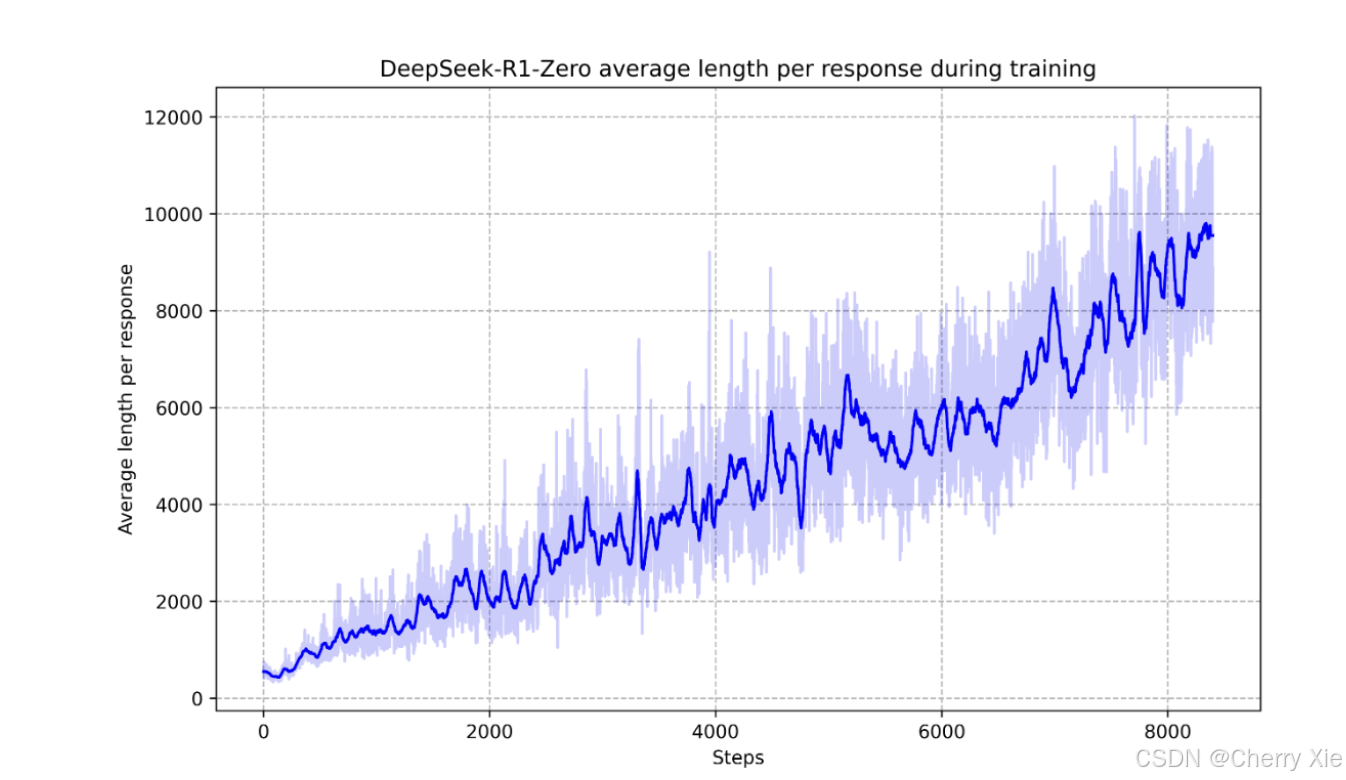
DeepSeek-R1 遵循“推理越长,表现越强”的 Scaling Laws。在 AIME 等测试基准中,随着推理长度的增加,模型得分稳步提升,展现出强大的自我反思和验证能力。
透明推理过程
与传统的“黑盒”模型不同,DeepSeek-R1 能够实时展示其思考过程,用户可以清晰地看到模型的推理步骤,这在代码生成和数学推理任务中尤为突出。
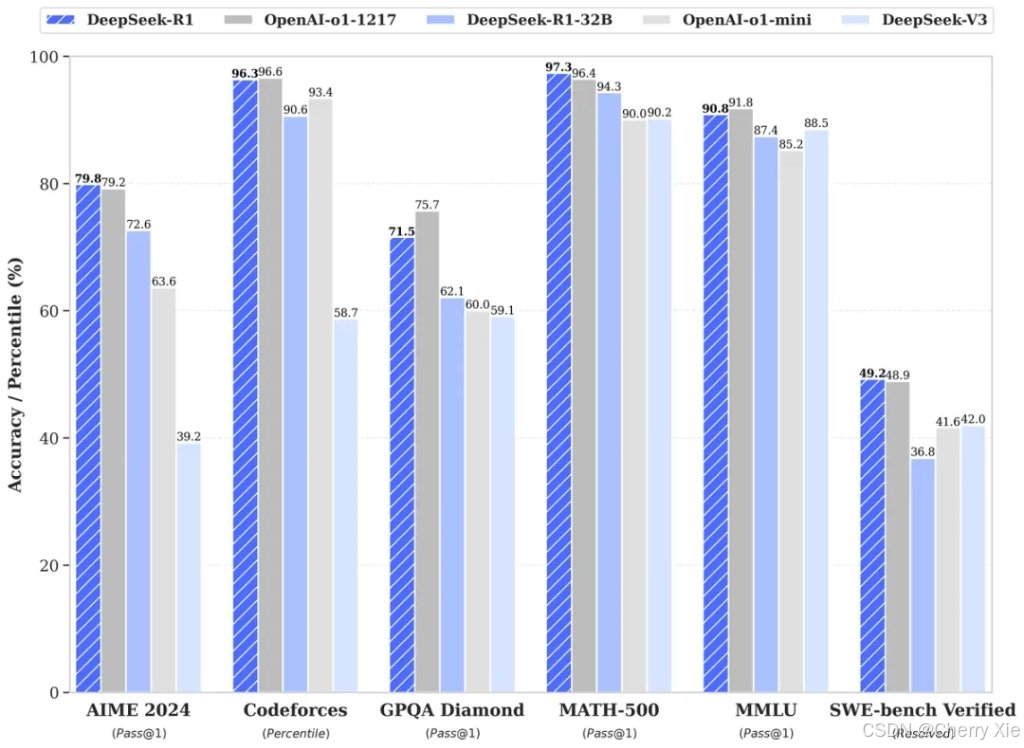
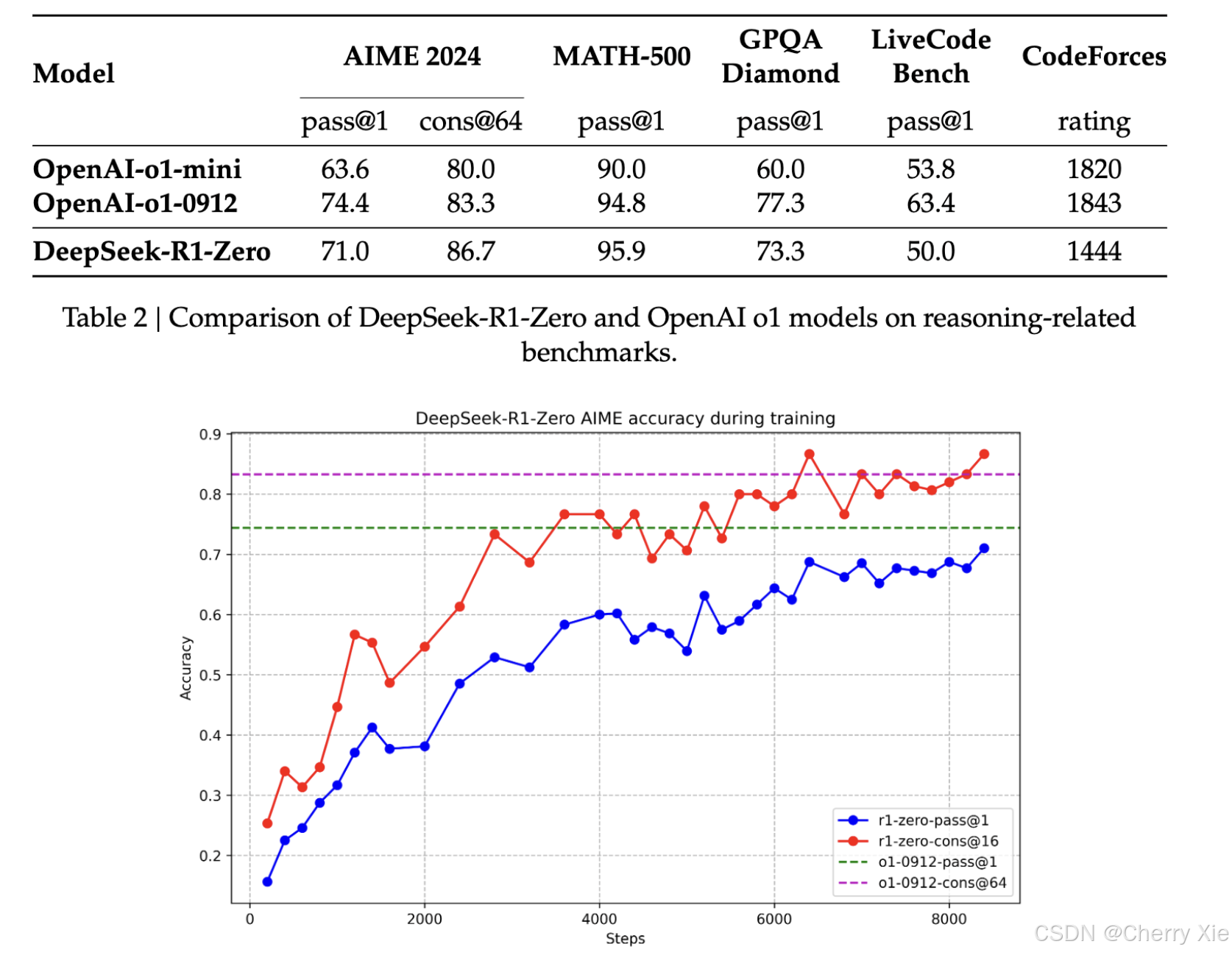
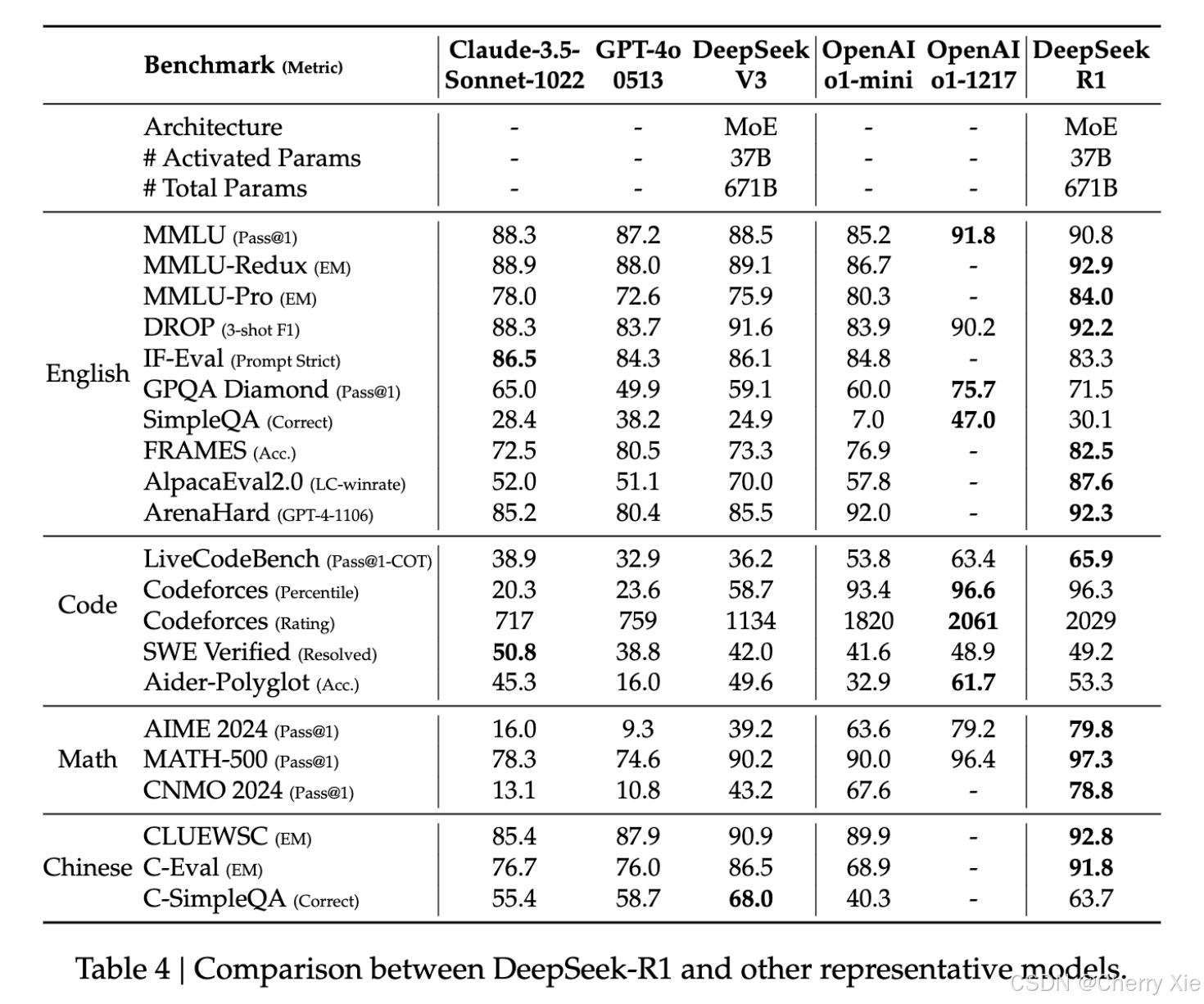
性能评估
DeepSeek-R1模型测评
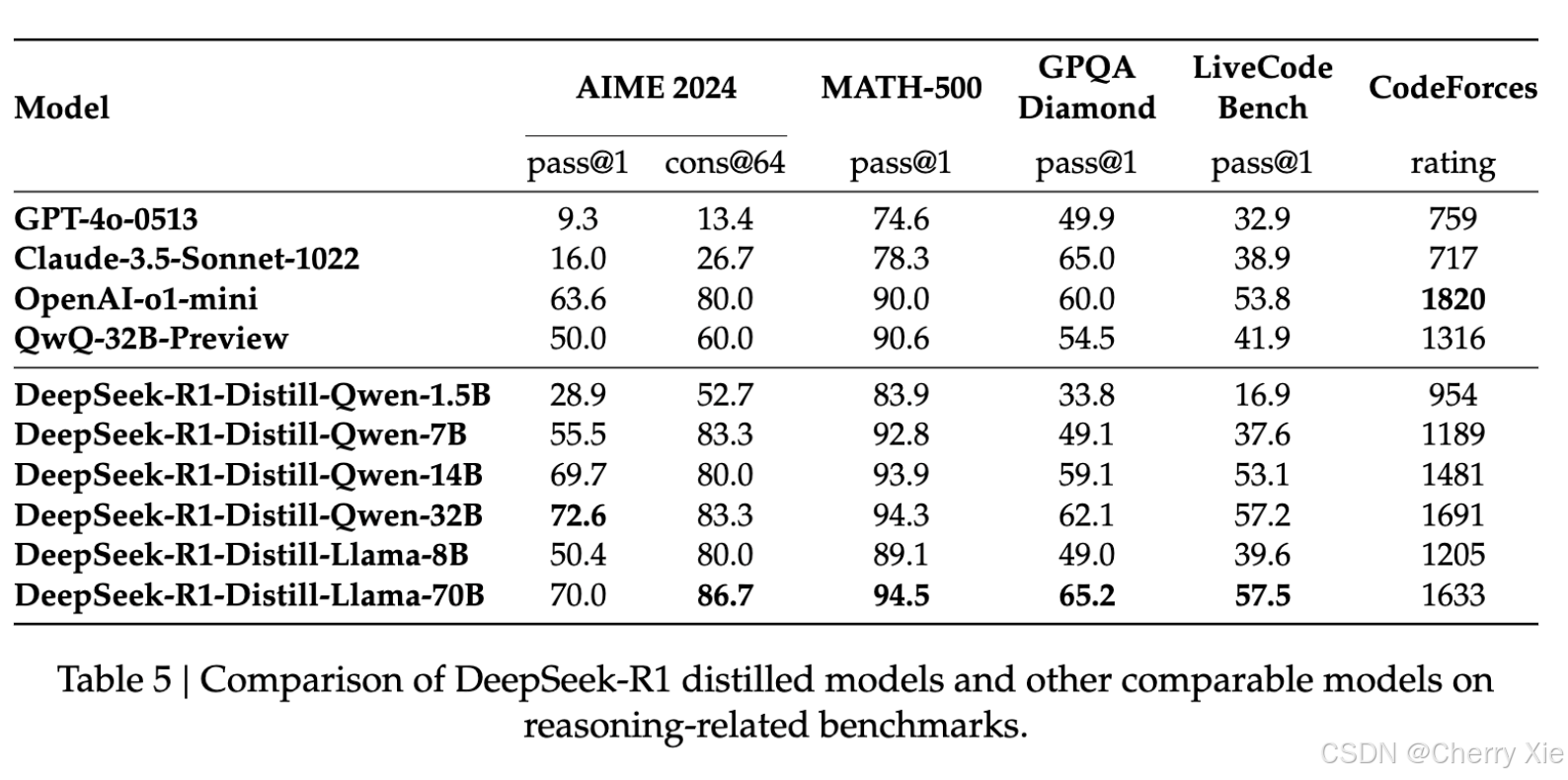
蒸馏模型评估




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











