









目录
Pandas 概览
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据
Pandas的官方文档地址:https://pandas.pydata.org/pandas-docs/stable/reference/index.html
- 注:Pandas适合处理结构化数据,即适合处理的维度在行、列级别而不是在某一个数据、单元格。当前数据分析中比较流行的工具中,Excel的处理类别在某一个数据、单元格级别的数据,其他例如SQL,Pandas,Tableau等均适合处理的维度在行、列级别的数据。所以这就是为什么在分析中有结构化和足够干净的数据是非常重要的一点。
入门Pandas
安装pandas
最常用的方法依旧是通过pip安装:
pip install Pandas
或者使用国内源安装:
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
其他安装方法在官网文档中有详细说明,这里不再赘述。https://www.pypandas.cn/docs/installation.html
用同样的方法安装numpy供后续使用
pip install numpy
导入 Pandas
通过下列语句我们导入pandas和numpy。
import numpy as np
import pandas as pd
Pandas数据结构
pandas有两种数据结构:
第一种是Series ,Series就是只有一个字段/维度/列的数据,它的行数可变,但是列数只有一列,只不过带有index(索引,或者称为标签)。
第二种是DataFrame,DataFrame就是我们最常见的二维表,有行有列,行数和列数都是可变的。
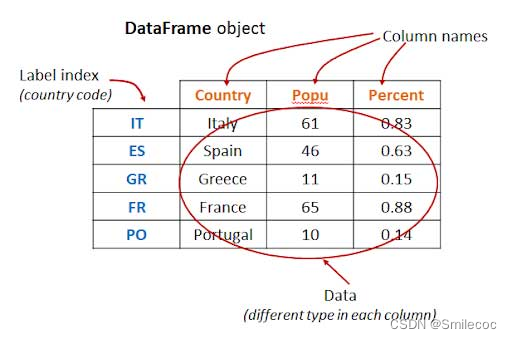
其中:
横向的称作行(row),我们所说的一条数据,就是指其中的一行
纵向的称作列(column),或者可以叫一个字段,是一条数据的某个值
第一行是表头,或者可叫字段名,列名
第一列是索引(index)
表头和索引在一些场景下也有称列索引和行索引的
Pandas Series
对象创建
首先创建一个Series结构的数据。创建Series结构的数据使用pandas.Series函数,语法如下:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=_NoDefault.no_default)
其中最重要的两个参数,一个是data,即输入到series的值,可以为数组,字典,列表等。这里要注意区分,python的基础类型有很多,比如list,tuple等。而Pandas只有两种数据结构,一维的Series和后面要说的二维的DataFrame。所以输入的数据类型可以多种多样,但是创建完后在pandas中都是Series和DataFrame对象
另一个是index,用来指定索引。如果不指定索引,则默认index是从0开始,步长为1的数字,如果指定index,则index必须与value个数相同。索引用来定位和选取数据
创建一个series方法如下:
# 由字典创建Series,字典的key就是index,values就是values
dic = {'a':1 ,'b':2 , 'c':3, '4':4, '5':5}
print(type(dic))
s = pd.Series(dic)
print(s)
#利用列表创建series
#使用list函数可以将字符串,元组等数据结构转化为列表的数据结构
s = pd.Series(list("abcdf"))
print(type(list("abcdf")))
print(s)
# 由标量创建Series
s = pd.Series(10, index = range(4))
print(s)
# 如果data是标量值,则必须提供索引。该值会重复,来匹配索引的长度
#仅传入value,会自动添加索引,从0开始,步长为1
s = pd.Series([1,2,3,4,5])
print(s)
#由数组创建(一维数组)Series
arr = np.random.randn(5) #用随机函数生成一些数字
print(type(arr))
s = pd.Series(arr)
print(arr)
print(s)
# 默认index是从0开始,步长为1的数字
在创建时指定series的索引和数值类型:
#修改索引
arr = np.random.randn(5) #用随机函数生成一些数字
s = pd.Series(arr, index = ['a','b','c','d','e'],dtype = np.object)
print(s)
# index参数:设置index,长度保持一致
# dtype参数:设置数值类型,可以看到与上一个pandas series相比输出的类型变成了object
#输入整数,指定series dtype是float类型,整数变为了带小数的数字
s = pd.Series([1,2,3,4,5],dtype=float)
print(s)
Series选取值
由于Series就只有一列,通过指定Series的索引或者行数我们可以定位Series中的元素。定位Series中的元素有如下几种方法:
1.切片索引[]
切片:通过[]选取行,即可定位,[]中可以传入位置下标,行数,标签等
# []切片
s = pd.Series(np.random.rand(5))
print(s)
print('---------------')
print(s[0],type(s[0]),s[0].dtype)
# 位置下标从0开始,[0]即选取series中第一行的数据。输出结果为numpy.float格式,
#通过float()函数转换为python float格式
print(float(s[0]),type(float(s[0])))
#从第一行到倒数第二行,原型是[n : m],前闭后开,索引从零开始,第一个索引指定可以取到,即n可以取到,后一个索引不可取到,即m不可取到
print(s[:-1])
#取第二行和第三行,即[n : m],前闭后开,索引从零开始,第一个索引指定可以取到,即n可以取到,后一个索引不可取到,即m不可取到
print(s[2:4])
print(s[::-1])#列表倒序取第一行到倒数第二行
print(s[:])#取列表中全部的数据
# 标签索引
s = pd.Series([1,2,3,4,5], index = ['a','b','c','d','e'])
print(s['a'],type(s['a']),s['a'].dtype)
# 方法类似下标索引,用[]表示,内写上index,注意index是字符串
sci = s[['a','b','e']]
print(sci,type(sci))
# 如果需要选择多个标签的值,用[[]]来表示(相当于[]中包含一个列表)
# 多标签索引结果是新的数组
2.布尔索引
根据逻辑判断选取数据,可以自由设定条件
#条件索引
s = pd.Series([1,2,3,4,5])
s[5] = None # 添加一个空值
print(s)
#将条件设置为值小于3,可以看到输出的是条件判断后的结果,True和False布尔类型
sr1 = s < 3
print(sr1)
#选出series中所有小于3的值
print(s[s < 3])
#选出series中所有非空的值
print(s[s.notnull()])
#还可以对index设置条件,例如index为数值型时,筛选出所有index小于3的值
print(s[s.index < 3])
3.iolc和loc索引
iloc可以传如对应的行数选取数据,loc可以传入index选取数据
s = pd.Series([1,2,3,4,5], index = ['a','b','c','d','e'])
#使用iloc来专门对隐式索引进行相关操作,跟s[[0,1]]一样,对行数进行选取
print(s.iloc[[0,2]])
#使用loc通过index标签选取数据
print(s.loc[['a','c']])
Pandas Series基本技巧
1.查看数据一般使用head()函数和tail()函数,分别默认查看前5条数据和后五条数据
s = pd.Series(np.random.rand(50))
print(s.head(10))
print(s.tail())
# .head()查看头部数据
# .tail()查看尾部数据
# 默认查看5条
2.重新索引,根据索引对数据重新排序
# 重新索引reindex
# .reindex将会根据索引重新排序,如果当前索引不存在,则引入缺失值
s = pd.Series(np.random.rand(3), index = ['a','b','c'])
print(s)
s1 = s.reindex(['c','b','a','d'])
print(s1)
# .reindex()中也是写列表
# 这里'd'索引不存在,所以值为NaN
s2 = s.reindex(['c','b','a','d'], fill_value = 0)
print(s2)
# fill_value参数:填充缺失值的值
3.Series相加,两个series相加会根据index自动对齐并相加,同时空值和任何值计算结果仍为空值
# Series相加
s1 = pd.Series(np.random.rand(3), index = ['Jack','Marry','Tom'])
s2 = pd.Series(np.random.rand(3), index = ['Wang','Jack','Marry'])
print(s1)
print(s2)
print(s1+s2)
# Series 和 ndarray 之间的主要区别是,Series 上的操作会根据标签自动对齐
# index顺序不会影响数值计算,以标签来计算
# 空值和任何值计算结果仍为空值
4.删除数据
# 删除:.drop
s = pd.Series(np.random.rand(5), index = list('ngjur'))
print(s)
#按照标签删除
s1 = s.drop('n')
s2 = s.drop(['g','j'])
print(s1)
print(s2)
5.添加数据
# 添加数据
s1 = pd.Series(np.random.rand(5))
s2 = pd.Series(np.random.rand(5), index = list('ngjur'))
print(s1)
print(s2)
s1[5] = 100
s2['a'] = 100
print(s1)
print(s2)
# 直接通过下标索引/标签index添加值
s3 = s1.append(s2)
print(s3)
# 通过.append方法,直接添加一个数组
6.修改Series数据
# 修改Series数据
s = pd.Series(np.random.rand(3), index = ['a','b','c'])
print(s)
s[0] = 100
s[['b','c']] = 200
print(s)
# 可通过上述选取数据的方法修改series里的数据
Pandas DataFrame
Pandas DataFrame是"二维数组" 结构的数据,也就是我们比较熟悉的表格型的数据,有多行多列数据,一般第一行为列名,其列的值类型可以是数值、字符串、布尔值等。
Dataframe 对象创建
创建Dataframe 的函数为pandas.Dataframe(),可以传入数组字典等数据类型
# Dataframe 创建方法一:由数组/list组成的字典
# 创建方法:pandas.Dataframe()
data1 = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
print(data1)
df1 = pd.DataFrame(data1)
print(df1)
data2 = {'one':np.random.rand(3),
'two':np.random.rand(3)}
print(data2)
df2 = pd.DataFrame(data2)
print(df2)
# 由数组/list组成的字典 创建Dataframe,columns为字典key,index为默认数字标签
# 字典的值的长度必须保持一致!
df1 = pd.DataFrame(data1, columns = ['b','c','a','d'])
print(df1)
df1 = pd.DataFrame(data1, columns = ['b','c'])
print(df1)
# columns参数:可以重新指定列的顺序,格式为list,如果现有数据中没有该列(比如'd'),则产生NaN值
# 如果columns重新指定时候,列的数量可以少于原数据
df2 = pd.DataFrame(data2, index = ['f1','f2','f3'])
print(df2)
# index参数:重新定义index,格式为list,长度必须保持一致
# Dataframe 创建方法二:由Series组成的字典
data1 = {'one':pd.Series(np.random.rand(2)),
'two':pd.Series(np.random.rand(2))} # 没有设置index的Series
print(data1)
df1 = pd.DataFrame(data1)
print(df1)
data2 = {'one':pd.Series(np.random.rand(2), index = ['a','b']),
'two':pd.Series(np.random.rand(3),index = ['a','b','c'])} # 设置了index的Series
print(data2)
df2 = pd.DataFrame(data2)
print(df2)
# 由Seris组成的字典 创建Dataframe,columns为字典key,index为Series的标签(如果Series没有指定标签,则是默认数字标签)
# Series可以长度不一样,生成的Dataframe会出现NaN值
# Dataframe 创建方法三:通过二维数组直接创建
ar = np.random.rand(9).reshape(3,3)
print(ar)
df1 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three']) # 可以尝试一下index或columns长度不等于已有数组的情况
print(df1)
# 通过二维数组直接创建Dataframe,得到一样形状的结果数据,如果不指定index和columns,两者均返回默认数字格式
# index和colunms指定长度与原数组保持一致
# Dataframe 创建方法四:由字典组成的列表
data = [{'one': 1, 'two': 2}, {'one': 5, 'two': 10, 'three': 20}]
print(data)
df1 = pd.DataFrame(data)
df2 = pd.DataFrame(data, index = ['a','b'], columns = ['one','two'])
print(df1)
print(df2)
# 由字典组成的列表创建Dataframe,columns为字典的key,index不做指定则为默认数组标签
# colunms和index参数分别重新指定相应列及行标签
# Dataframe 创建方法五:由字典组成的字典
data = {'Jack':{'math':90,'english':89,'art':78},
'Marry':{'math':82,'english':95,'art':92},
'Tom':{'math':78,'english':67}}
df1 = pd.DataFrame(data)
print(df1)
# 由字典组成的字典创建Dataframe,columns为字典的key,index为子字典的key
df2 = pd.DataFrame(data, columns = ['Jack','Tom','Bob'])
df3 = pd.DataFrame(data, index = ['a','b','c'])
print(df2)
print(df3)
# columns参数可以增加和减少现有列,如出现新的列,值为NaN
# index在这里和之前不同,并不能改变原有index,如果指向新的标签,值为NaN (非常重要!)
也可以通过读取文件,可以是json,csv,excel,SQL结果数据等等来创建一个Dataftame
#通过导入excel文件的方法来创建一个dataframe,这里要注意,如果用excel请先安装xlrd这个包
excel_pd=pd.read_excel("pandas_demo.xlsx")
#sql为SQL查询语句,db为对应的数据库地址,需要先安装pymssql这个包
df = pd.read_sql(sql,db)
Dataframe 选取值
Dataframe数据既有行索引又有列索引,所以相较于选取查看series数据可以选择行,列,也可以同时选取行和列
1.切片索引[]
在Dataframe中切片索引与在Series中用法基本一致,对行切片时一般使用数字索引,对列切片时一般使用列标题索引,并且一般只用于仅选取行或者仅选取列的情况
#选取数据
data = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df = pd.DataFrame(data)
print(df)
# 切片取数[]
data1 = df['a']
data2 = df[['a','c']]
print(data1,type(data1))
print(data2,type(data2))
# 按照列名选择列,只选择一列输出Series,选择多列输出Dataframe
data3 = df[:1]
data4 = df[1:3]
data5 = df[1::3]
print(data3,type(data3))
print(data4,type(data4))
print(data5,type(data5))
#原型是[n : m],前闭后开,索引从零开始,第一个索引指定可以取到,即n可以取到,后一个索引不可取到,即m不可取到,不支持df[1]这种类型的取数
2.loc和iloc索引
loc索引和iloc索引是比较常用的索引方法。 其中loc是根据DataFrame的行标签和列标签进行数据的筛选,也就是要输入所谓的行名和列名iloc是根据DataFrame的行序号和列序号进行筛选,需要输入数字。
loc和iloc函数的语法为df.loc[行索引表达,列索引表达]/df.iloc[行索引表达,列索引表达],只取行时可省略列索引参数
# loc和iloc索引,选取行
#loc是根据dataframe的具体标签选取列,而iloc是根据标签所在的位置,从0开始计数
data = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df = pd.DataFrame(data,index = ['one','two','three'])
print(df)
data1 = df.loc['one']
data2 = df.loc[['three','one']] #选取多行
data3 = df.loc['one':'three']#选取连续多行
print(data1,type(data1))#选取一行返回Series类型的数据,多行返回Dataframe类型的数据
print(data2,type(data2))
print(data3,type(data3))
#如果是数字索引,对应的索引为数字
data = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df = pd.DataFrame(data)
data1 = df.loc[1]
data2 = df.loc[[0,2,1]]
print(data1)
print(data2)
#iloc是根据标签所在的位置索引取数
data = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df = pd.DataFrame(data,index = ['one','two','three'])
print(df.iloc[0])
print(df.iloc[-1])
print(df.iloc[[0,2]])
print(df.iloc[0:2])
3.多重索引
利用上述方法对行和列同时进行索引
# 多重索引:比如同时索引行和列
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['one','two','three','four'],
columns = ['a','b','c','d'])
print(df)
print('------')
# 先选择列再选择行 —— 相当于对于一个数据,先筛选字段,再选择数据量
print(df['a'].loc[['one','three']]) # 选择a列的one,three行
print(df[['b','c','d']].iloc[::2]) # 选择b,c,d列的one,three行
print(df[df['a'] < 80].iloc[:2]) # 选择满足判断索引的前两行数据
# 选取第一,二行中a列小于80的行,可使用布尔索引对行和列同时进行条件筛选
print(df.loc[((df.index == 'one') |(df.index == 'two')) & (df['a'] < 80)])
Pandas Dataframe基本技巧
1.数据查看:与series相同使用head与tail函数
# 数据查看、转置
df = pd.DataFrame(np.random.rand(16).reshape(8,2)*100,
columns = ['a','b'])
print(df.head(2))
print(df.tail())
# .head()查看头部数据
# .tail()查看尾部数据
# 默认查看5条
print(df.T)
# .T 转置
2.Dataframe添加数据与修改数据
# 添加与修改
data = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df = pd.DataFrame(data,index = ['one','two','three'])
print(df)
df['e'] = 10
df.loc[4] = 20
print(df)
# 新增列/行并赋值
df['e'] = 20
df[['a','c']] = 100
print(df)
# 修改值
#将b列大于4的行在e列中显示为'数值较大'
df.loc[df['b'] > 4, 'e'] = '数值较大'
print(df)
3.删除行和列
# 删除 del / drop()
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df)
del df['a']
print(df)
print('-----')
# del语句 - 删除列
print(df.drop(0))
print(df.drop([1,2]))
print('-----')
# drop()删除行
print(df.drop(['d'], axis = 1))
# drop()删除列,需要加上axis = 1,inplace=False → 删除后生成新的数据,不改变原数据
4.排序:可以按照值(数字和文本均可)和索引排序
# 排序1 - 按值排序 .sort_values
# 同样适用于Series
data = {'a':[1,3,2],
'b':[3,4,5],
'c':['饼干','巧克力','果冻']}
df1 = pd.DataFrame(data)
print(df1)
print(df1.sort_values(['a'], ascending = True)) # 升序
print(df1.sort_values(['a'], ascending = False)) # 降序
print(df1.sort_values(['c'])) # 文本按照首字母排序
print('------')
# ascending参数:设置升序降序,默认升序
# 单列排序
df2 = pd.DataFrame({'a':[1,1,1,1,2,2,2,2],
'b':list(range(8)),
'c':list(range(8,0,-1))})
print(df2)
print(df2.sort_values(['a','c']))
# 多列排序,按列顺序排序
# 排序2 - 索引排序 .sort_index
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = [5,4,3,2],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['h','s','x','g'],
columns = ['a','b','c','d'])
print(df1)
print(df1.sort_index())
print(df2)
print(df2.sort_index())
# 按照index排序
# 默认 ascending=True, inplace=False














 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









