






前言:
今年在nlp领域,最靓的仔要数chat-gpt了,未来也可能颠覆搜索行业,甚至其他行业也会慢慢的被颠覆被取代,作为技术人员,为了保证饭碗,必须跟进相关技术的发展。目前梳理了一下chat-gpt技术的脉络,通过该脉络可以比较系统的了解chat-GPT背后的技术。论文的链接在最后的参考文献中,读者可以自行下载。
技术论文梳理

论文发展介绍
可以说nlp的发展,从2017年的transformer(Attentino is all you need)文章问世就已经进入了新的纪元。transformer使用了编码器和解码器,后来人在此论文上,分别对编码器和解码器展开研究,逐渐走上了两个不同的发展方向。典型的代表作分别为bert和gpt。
编码器的发展使用的完词填空的思路,也就是说一句话将中间的词覆盖住,使用前后两边的词去预测被覆盖的词,比如: 我的爱好是打篮球。覆盖【爱好】使用我的xx是打篮球,去预测【爱好】。而解码器是翻译模式,比如:我的爱好是打篮球,通过输入【我的爱好是】,预测【打篮球】,这种方式更符合人从左往后阅读的习惯,也更符合聊天的模式(先问问题,然后预测回答)。 在实际的应用中,编码器代表bert在很多的实际应用中都有很不错的效果(即便是在其之后发表的gpt2,效果也比bert差),因为其更专注于细分领域的问题,在细分领域使用对应的数据进行微调模型,得到较好的效果。而GPT从从左往后预测的方式,其难度比bert大很多,面对的的领域更加广阔,挑战性大的多,所以在前几年一直被以bert为代表的解码器研究方向所压制。但chat-gpt问世之后,人们发现了gpt模式蕴含着巨大的商业价值,甚至可以颠覆人们的工作、生活方式。可能在不久的将来,在方方面面都能看到gpt模式的身影。因此也就有必要梳理一下chat-GPT的原理,通过比较有代表的论文解读chat-GPT的细节。
1.transformer
chat-GPT大体的框架是GPT,是transformer中的decode部分改造的。论文标题:Attention Is All You Need
论文摘要:占主导地位的序列转导模型是基于复杂的递归或卷积神经网络,包括编码器和解码器。性能最好的模型还通过注意力机制将编码器和解码器连接起来。我们提出了一种新的简单网络架构Transformer,完全基于注意力机制,完全不需要重复和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,并且需要更少的训练时间。我们的模型在WMT2014英语到德语翻译任务中实现了28.4 BLEU,比现有的最佳结果提高了2个BLEU以上。在WMT2014英法翻译任务中,我们的模型在8个GPU上训练3.5天后,建立了一个新的单模型最先进的BLEU分数41.8,这只是文献中最佳模型训练成本的一小部分。我们通过将Transformer成功地应用于具有大量和有限训练数据的英语解析,表明它可以很好地推广到其他任务。
2. GPT1
GPT不是论文作者取名的,而是该论文追随者后来取名的:GPT1论文的标题为:Improving Language Understanding by Generative Pre-Training。论文追随者使用Generative Pre-Training(生成式预训练)作为该论文的简称。
论文摘要:自然语言理解包括一系列不同的任务,如文本隐含、问题回答、语义相似性评估和文档分类。尽管大量的未标记文本语料库非常丰富,但用于学习这些特定任务的标记数据却很少,这使得经过判别训练的模型很难充分执行。我们证明,通过在不同的未标记文本语料库上生成语言模型的预训练,然后对每个特定任务进行有区别的微调,可以在这些任务上实现巨大的收益。与以前的方法相比,我们在微调过程中使用了任务感知输入转换,以实现有效的传输,同时需要对模型架构进行最小的更改。我们在一系列自然语言理解基准上展示了我们的方法的有效性。我们的一般任务上模型优于使用专门为每个任务构建的体系结构的有区别训练的模型,在所研究的12个任务中,有9个任务显著提高了现有技术水平。例如,我们在常识推理(Stories Cloze Test)、问答(RACE)和文本暗示(MultiNLI)方面分别获得了8.9%、5.7%和1.5%的绝对改善。
3. GPT2
GPT2论文是在bert出来之后发表的,整体效果差于bert,但是这个论文的最大卖点为zero-shot,在不对具体任务进行微调的情况下,也能取得不错的效果。标题为:Language Models are Unsupervised Multitask Learners
论文摘要:自然语言处理任务,如问答、机器翻译、阅读理解和摘要,通常在特定任务的数据集上进行监督学习。我们证明,当在一个名为WebText的数百万网页的新数据集上进行训练时,语言模型在没有任何外部监督的情况下开始学习这些任务。当以文档加问题为条件时,语言模型生成的答案在CoQA数据集上达到55F1,在不使用127000+训练示例的情况下,匹配或超过了四分之三的基线系统的性能。语言模型的能力对于零样本任务转移的成功至关重要,增加它可以以对数方式跨任务提高性能。我们最大的模型GPT-2是一个1.5B参数的Transformer,它在8个测试语言建模数据集中有7个在零样本设置下获得了最先进的结果,但仍低于WebText。模型中的样本反映了这些改进,并包含连贯的文本段落。这些发现为构建语言处理系统提供了一条很有前途的道路,该系统可以从自然发生的演示中学习执行任务。
4. GPT3
GPT3论文将GPT1的12层增加到了96层,宽度也有增加,真正见证大力出奇迹,标题为:gpt3-Language Models are Few-Shot Learners
论文摘要:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准测试上取得了实质性的进展。虽然这种方法在架构上通常与任务无关,但它仍然需要数千或数万个实例的特定任务微调数据集。相比之下,人类通常只能通过几个例子或简单的指令来执行一项新的语言任务,而当前的NLP系统在很大程度上仍然很难做到这一点。在这里,我们表明,扩大语言模型的规模大大提高了任务不可知的、少镜头的性能,有时甚至与以前最先进的微调方法相比具有竞争力。具体来说,我们训练GPT-3,这是一个具有1750亿个参数的自回归语言模型,比以前的任何非稀疏语言模型都多10倍,并测试其在少数镜头设置中的性能。对于所有任务,GPT-3在没有任何梯度更新或微调的情况下应用,任务和少量镜头演示完全通过与模型的文本交互来指定。GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问答和完形填空任务,以及一些需要动态推理或领域自适应的任务,如解单词、在句子中使用新词或执行三位数算术。同时,我们还确定了GPT-3的少量镜头学习仍然困难的一些数据集,以及GPT-3面临与在大型网络语料库上训练相关的方法论问题的一些数据集中。最后,我们发现GPT-3可以生成新闻文章的样本,人类评估人员很难将其与人类撰写的文章区分开来。我们讨论了这一发现和GPT-3的更广泛的社会影响。
5. instruct GPT(2022)
chat-GPT没有给出论文,但是在描述中提到:

也就是说,chat-PGT是instruct GPT发展而来的,整体的框架的思路是一致的,所以通过这篇问题可以大致了解chat-GPT的大致情况,具体细节就要等论文了。instruct GPT在GPT3的基础上,增加了增强学习的训练方式。具体流程如下:
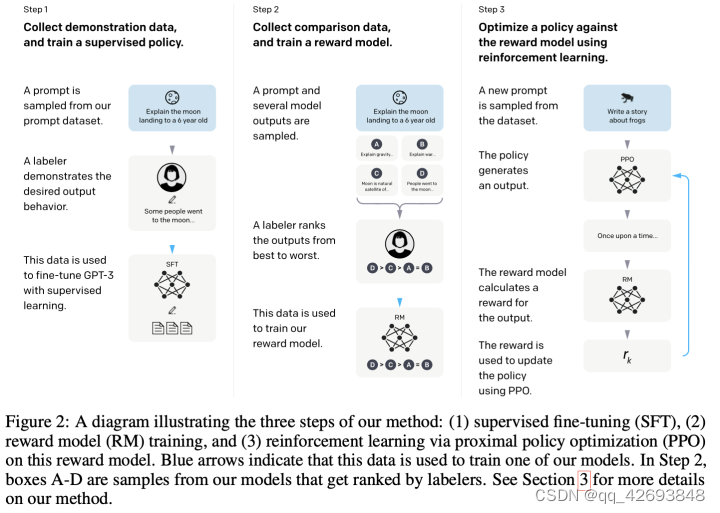
主要的亮点包括设计了奖励模型RM(reward model)和使用增强学习PPO更新GPT模型,使效果更上一层楼。标题为:Training language models to follow instructions with human feedback。
论文摘要:将语言模型做得更大并不能从本质上使它们更好地遵循用户的意图。例如,大型语言模型可以生成输出是不真实的、有毒的,或者根本对用户没有帮助。换句话说,这些模型与其用户不一致。在本文中,我们展示了一种方法,通过对人类反馈进行微调,使语言模型与用户在各种任务中的意图保持一致。从一组通过OpenAI API提交的贴标机书面提示和提示开始,我们收集了所需模型行为的贴标机演示数据集,我们使用该数据集使用监督学习对GPT-3进行微调。然后,我们收集了一个模型输出排名的数据集,我们使用该数据集使用来自人类反馈的强化学习来进一步微调这个监督模型。我们将生成的模型称为InstructGPT。在对我们的即时分布进行的人工评估中,1.3B参数InstructGPT模型的输出优先于175B GPT-3的输出,尽管参数减少了100倍。此外,InstructionGPT模型显示了真实性的提高和有毒输出生成的减少,同时在公共NLP数据集上具有最小的性能回归。尽管InstructGPT仍然会犯一些简单的错误,但我们的研究结果表明,利用人类反馈进行微调是使语言模型与人类意图相一致的一个很有前途的方向。
6. codex
codex是openai使用GPT自动生成代码上的研究,采用github上的代码训练模型,通过docstring生成代码的尝试,标题为:Evaluating Large Language Models Trained on Code
论文摘要:我们介绍了Codex,这是一种GPT语言模型,对GitHub的公开代码进行了微调,并研究了它的Python代码编写功能。Codex的一个独特的生产版本为GitHub Copilot提供了动力。在HumanEval上,我们发布了一个新的评估集,用于衡量从文档字符串合成程序的功能正确性,我们的模型解决了28.8%的问题,而GPT-3解决了0%,GPT-J解决了11.4%。此外,我们发现从模型中重复采样是一种非常有效的策略,可以为困难的提示提供有效的解决方案。使用这种方法,我们解决了70.2%的问题,每个问题有100个样本。对我们模型的仔细研究揭示了它的局限性,包括描述长操作链的文档字符串以及将操作绑定到变量的困难。最后,我们讨论了部署强大的代码生成技术的潜在更广泛影响,包括安全性、和生态经济学。
在上述的脑图中还列举了强化学习相关,解释模型为什么具有临场学习的能力( In-Context Learning),以及prompt等相关论文,感兴趣的读者可以一起阅读。
参考文献:
Attention Is All You Need
Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
Language Models are Few-Shot Learners
Training language models to follow instructions with human feedback
Evaluating Large Language Models Trained on Code
Augmenting Reinforcement Learning with Human Feedback
Interactively Shaping Agents via Human Reinforcement
Proximal Policy Optimization Algorithms
WHAT LEARNING ALGORITHM IS IN-CONTEXT LEARNING? INVESTIGATIONS WITH LINEAR MODELS
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
prompt-Pre-train, Prompt, and Predict- A Systematic Survey of Prompting Methods in Natural Language Processing















 8112
8112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









