







1.重复调用
- mysql
// 反例:表连接ids.size次
List<Project> projects = CollUtil.newArrayList();
for (Long id : ids) {
Project project = projectService.getById(id);
projects.add(project);
// 业务处理
}
// 正例:用in或者or批量查询,交互一次
List<Project> projects1 = projectService.listByIds(ids);
- redis
// keys
List<Object> totalPowerMeasIds = allInvCalcAttrMeasIdListMap.get("totalPMeasIds");
// 反例:单个key查询
List<Object> objectList = CollUtil.newArrayList();
totalPowerMeasIds.forEach(e->{
Object obj = redisTemplate.opsForHash().get(Constants.REAL_TIME_TABLE, e);
objectList.add(obj);
// 业务处理
});
// 正例:key集合批量查询
List<Object> totalPowerList = redisTemplate.opsForHash().multiGet(Constants.REAL_TIME_TABLE, totalPowerMeasIds);
- 死循环
- 递归
2.异步
有个用户请求接口中,需要做业务操作,发站内通知,和记录操作日志。为了实现起来比较方便,通常我们会将这些逻辑放在接口中同步执行,势必会对接口性能造成一定的影响。
- SpringBoot 注解 @Async;
- JDK1.8 中,Java 提供了 CompletableFuture 类,它是基于异步函数式编程。相对阻塞式等待返回结果,CompletableFuture 可以通过回调的方式来处理计算结果,实现了异步非阻塞,性能更优:
CompletableFuture 中常用api:
- 依赖关系
thenApply():把前面任务的执行结果,交给后面的Function thenCompose():用来连接两个有依赖关系的任务,结果由第二个任务返回
- and集合关系
thenCombine():合并任务,有返回值
thenAccepetBoth():两个任务执行完成后,将结果交给thenAccepetBoth处理,无返回值
runAfterBoth():两个任务都执行完成后,执行下一步操作(Runnable类型任务)
- 聚合关系
applyToEither():两个任务哪个执行的快,就使用哪一个结果,有返回值
acceptEither():两个任务哪个执行的快,就消费哪一个结果,无返回值
runAfterEither():任意一个任务执行完成,进行下一步操作(Runnable类型任务)
- 并行执行
allOf():当所有给定的 CompletableFuture 完成时,返回一个新的 CompletableFuture
anyOf():当任何一个给定的CompletablFuture完成时,返回一个新的CompletableFuture
- 结果处理
whenComplete:当任务完成时,将使用结果(或 null)和此阶段的异常(或 null如果没有)执行给定操作
exceptionally:返回一个新的CompletableFuture,当前面的CompletableFuture完成时,它也完成,当它异常完成时,给定函数的异常触发这个CompletableFuture的完成
- 获取结果(join&get)
join()和get()方法都是用来获取CompletableFuture异步之后的返回值。join()方法抛出的是uncheck异常(即未经检查的异常),不会强制开发者抛出。get()方法抛出的是经过检查的异常,ExecutionException,
InterruptedException 需要用户手动处理(抛出或者 try catch)
实例1:
public static void main(String[] args) {
System.out.println("小白进入餐厅");
System.out.println("小白点了 番茄炒蛋 + 一碗米饭");
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
System.out.println("厨师炒菜");
ThreadUtil.sleep(200);
return "番茄炒蛋";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
System.out.println("服务员蒸饭");
ThreadUtil.sleep(300);
return "米饭";
}), (dish, rice) -> {
System.out.println("服务员打饭");
ThreadUtil.sleep(100);
return String.format("%s + %s 好了", dish, rice);
});
System.out.println("小白在打王者");
System.out.println(String.format("%s ,小白开吃", cf1.join()));
}
实例2:
// 线程池
@Autowired
private ThreadPoolTaskExecutor taskExecutor;
// 对象VO
Load load = loadService.getByProjectId(projectId);
// 查询对象中属性
CompletableFuture<ElecLoad> cf1 = CompletableFuture.supplyAsync(() -> elecLoadService.getByLoadId(load.getId(), load.getCycle()), taskExecutor);
CompletableFuture<ColdLoad> cf2 = CompletableFuture.supplyAsync(() -> coldLoadService.getByLoadId(load.getId(), load.getCycle()), taskExecutor);
CompletableFuture<HeatLoad> cf3 = CompletableFuture.supplyAsync(() -> heatLoadService.getByLoadId(load.getId(), load.getCycle()), taskExecutor);
CompletableFuture<List<Select>> cf4 = CompletableFuture.supplyAsync(() -> industryService.select(Constants.ProjectIndustryType.LOAD_BASE), taskExecutor);
CompletableFuture<List<Select>> cf5 = CompletableFuture.supplyAsync(() -> industryService.select(Constants.ProjectIndustryType.LOAD_INDUSTRY), taskExecutor);
cf1.thenAccept(load::setElecLoad).join();
cf2.thenAccept(load::setColdLoad).join();
cf3.thenAccept(load::setHeatLoad).join();
cf4.thenAccept(load::setLoadBaseList).join();
cf5.thenAccept(load::setLoadIndustryTypeList).join();
注意: 实际开发中要用线程池去执行,线程池使用不合理会导致很多问题,文档后面会有线程池使用以及注意问题
- 京东零售的工具:asyncTool
3.事务
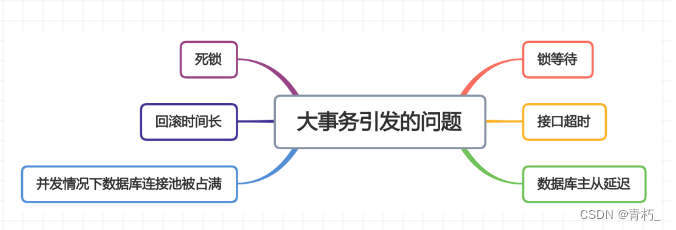
使用@Transactional注解这种声明式事务的方式提供事务功能,确实能少写很多代码,提升开发效率,也容易造成大事务(运行时间长的事务,由于事务一直不提交,就会导致数据库连接被占用,即并发场景下,数据库连接池被占满,影响到别的请求访问数据库),会导致整个业务方法都在同一个事务中,粒度太粗,不好控制事务范围;
1.复杂的业务逻辑或者执行时间长的业务不用声明式事务,采可以用编程式事务;
2.将查询(select)方法放到事务外,这里需要注意:@Transactional注解的声明式事务是通过spring aop起作用的,而spring aop需要生成代理对象,直接方法调 用使用的还是原始对象(新建service、自己获取代理对象)
3.可以根据业务情况,不使用事务
4.锁
在某些业务场景中,为了防止多个线程并发修改某个共享数据,造成数据异常。为了解决并发场景下,多个线程同时修改数据,造成数据不一致的情况。通常情况下,我们会加锁。JUC
-
锁的选取
Lock 类:手动释放;可重入锁,可以 判断锁,非公平(可以自己设置);适合锁大量的代码
synchronized 内置关键字;自动释放;无法判断获取锁的状态;可重入锁,不可以中断的,非公平;
分布式锁 :zk、redis -
锁粒度
如果锁加得不好,导致锁的粒度太粗,也会非常影响接口性能。
public synchronized void save(){
// 执行业务1需要加锁
System.out.println("执行业务1");
System.out.println("执行业务2");
System.out.println("执行业务3");
}
例子中只有【执行业务1】需要加锁,现在会导致整个方法加锁;需要改为代码块的方式
public void save(){
// 执行业务1需要加锁
synchronized(this) {
System.out.println("执行业务1");
}
System.out.println("执行业务2");
System.out.println("执行业务3");
}
5.缓存
Redis,读多写少且数据时效要求越低的场景,缓存用得好,可以承载更多的请求,提升查询效率,减少数据库的压力,比如一些平时变动很小或者说几乎不会变的商品信息,可以放到缓存,请求过来时,先查询缓存,如果没有再查数据库,并且把数据库的数据更新到缓存。需要考虑: 缓存和数据库一致性如何保证、集群(主备、哨兵)、缓存击穿、缓存雪崩、缓存穿透等问题。
6.远程调用
- 异常处理
比如,你调别人的接口,如果异常了,怎么处理,是重试还是当做失败还是告警处理。
- 接口超时
没法预估对方接口多久返回,一般设置个超时断开时间,以保护你的接口。如果http 调用不设置超时时间,最后响应方进程假死,请求一直占着线程不释放,拖垮线程池。
- 重试次数
你的接口调失败,需不需要重试?重试几次?根据业务情况。
- 幂等操作
网络抖动多次点击或者发请求,比如下单、付款等操作;文档详细说明
7 .辅助功能
- 开启慢查询日志
通常情况下,为了定位sql的性能瓶颈,我们需要开启mysql的慢查询日志。把超过指定时间的sql语句,单独记录下来,方面以后分析和定位问题。
开启慢查询日志需要重点关注三个参数:
- slow_query_log 慢查询开关
- slow_query_log_file 慢查询日志存放的路径
- long_query_time 超过多少秒才会记录日志
通过mysql的set命令可以设置:
set global slow_query_log='ON';
set global slow_query_log_file='/usr/local/mysql/data/slow.log';
set global long_query_time=2;
设置完之后,如果某条sql的执行时间超过了2秒,会被自动记录到slow.log文件中。
当然也可以直接修改配置文件my.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 2
可以用mq或者其他方式发送信息或者邮件的方式定时发送给开发人员,开发人员可以优化sql
2.druid的SQL监控
3.java性能分析
- jconsole
- jvisualvm
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











