







概述
Mapreduce是一种分布式并行编程:借助一个集群通过多台机器同时并行处理大规模数据集。
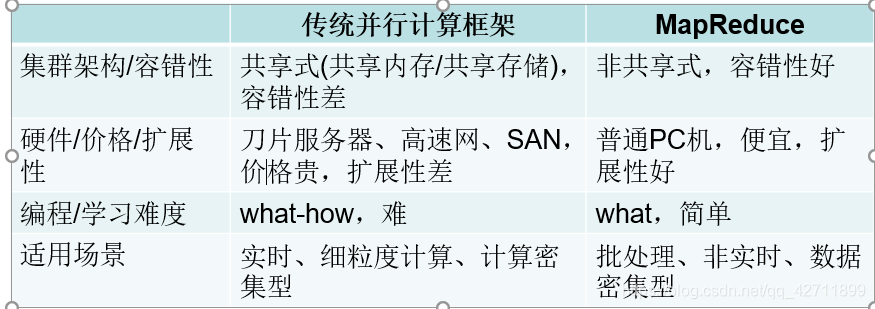
Mapreduc模型简介
Mapreduce采用分而治之的方法实现,把非常庞大的数据集,切分成非常多的独立的小片,然后单独的启动一个Map任务,最终通过多个map,并行的在多个机器上去处理
Mapreduce理念
计算向数据靠拢而不是数据向计算靠拢
要完成一次数据分析,选择一个计算节点把运行数据分析的程序放到计算节点上运行;然后把它所涉及的数据,全部从各个节点面上拉过来,传输到计算发生的地方。
Mapreduce采用了Master/slave架构:一个Master服务器个若干个slave服务器。Master上与新作业跟踪器jobTracker,slave服务器负责基本任务的组件TaskTracker.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









