






很多时候我们都需要用到模糊查询,但是在什么场景用什么查询方式才是最适合的呢?百分之八十的人都喜欢用LIKE,语法简单,正则表达式,等等优点。
下面通过几个简单的例子来对比一下,常用的模糊查询。
首先准备两张表
| CREATE TABLE TEST1 AS SELECT * FROM SYSOBJECTS; |
| CREATE TABLE TEST2 AS SELECT * FROM DBA_TABLES WHERE OWNER = 'USER1'; |
ROUND1:列对列全表扫描
LIKE
| SELECT * FROM TEST1 T1,TEST2 T2 WHERE T1.NAME LIKE '%'||T2.TABLE_NAME||'%' ; |
执行耗时:563毫秒 1875行
INSTR
| SELECT * FROM TEST1 T1,TEST2 T2 WHERE INSTR(T1.NAME,T2.TABLE_NAME)>0; |
执行耗时:338毫秒 1875行
REGEXP_LIKE
| SELECT * FROM TEST1 T1,TEST2 T2 WHERE REGEXP_LIKE(T1.NAME,T2.TABLE_NAME); |
执行耗时:10.740秒 1875行
小结:在进行列列比较时,虽然同是全表扫描,但是LIKE和INSTR均可以利用批量处理来进行对比,因此性能明显优于REGEXP_LIKE函数
ROUND2:列对值全表扫描
LIKE
| SELECT * FROM TEST1 T1 WHERE T1.NAME LIKE '%A%'; |
执行耗时:16毫秒 1944行
INSTR
| SELECT * FROM TEST1 T1 WHERE INSTR(T1.NAME,'A')>0 |
执行耗时:16
毫秒 1944行
REGEXP_LIKE
| SELECT * FROM TEST1 T1,TEST2 T2 WHERE REGEXP_LIKE(T1.NAME,'A'); |
执行耗时:21毫秒 1944行
小结:在进行列值比较时,LIKE、INSTR、REGEXP_LIKE均可以利用批量处理来进行数据对比,但是多次执行后REGEXP_LIKE函数的性能稍差。
ROUND3:功能对比
测试数据和索引
| INSERT INTO TEST1(NAME) VALUES ('113456'); INSERT INTO TEST1(NAME) VALUES ('123456'); INSERT INTO TEST1(NAME) VALUES ('133456'); INSERT INTO TEST1(NAME) VALUES ('143456'); INSERT INTO TEST1(NAME) VALUES ('1abc56'); COMMIT; |
| CREATE INDEX IND_TEST1_NAME ON TEST1(NAME); |
在前两轮的PK中,REGEXP_LIKE表现差强人意,但是REGEXP_LIKE函数强大的功能,让我们不得不选择它来进行模糊查询。
例1:查询出TEST1表中name列以1开头并以56结尾的数据。
REGEXP_LIKE
SELECT * FROM TEST1 T1 WHERE REGEXP_LIKE(T1.NAME,'1...56')
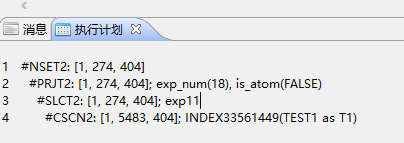
能查询但是无法利用索引
LIKE
SELECT * FROM TEST1 T1 WHERE T1.NAME LIKE '1___56'
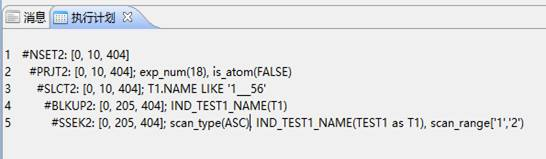
能查询并利用了索引,在大量数据情况下,利用索引的LIKE会占据很大的优势。
INSTR
无法满足条件
例2:如果需要查到全部都是数字的列
REGEXP_LIKE
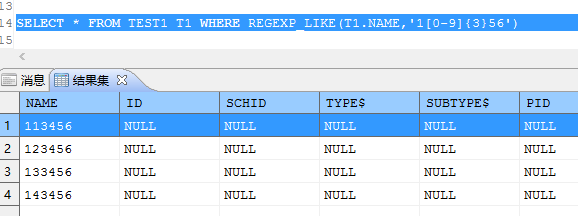
LIKE和INSTR却无能为力了。
不仅如此,使用REGEXP_LIKE还可以通过字符集、是否区分大小写、空格等一系列过滤条件来进行模糊查询。
综上所述:
在无法利用索引的情况下,使用INSTR是最佳的选择;
能利用索引的,只有LIKE;
如果条件很苛刻不好过滤判断,那么REGEXP_LIKE就派上用场了。


















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









