






java基础知识复习
java为什么被发明?
Green项目的确立,应用于像电视盒一样的消费类电子产品,语言本身本身中立。
java的三大版本?
javaSE的定位在于客户端,只要用于桌面应用软件的编程。
javaME的定位在于嵌入式系统开发,如手机以及pad的编程。
javaEE的定位在于服务端,java的企业版本,主要用于分布式网络程序的开发,如电子商务的网站等。
java的特点
java的跨平台。
java的运行机制是先编译后解释,所以可以跨平台,运行效率高
JVM:java的虚拟机,是保证java跨平台特性的核心。jvm可以在不同的系统中虚拟成为相同的环境,
并保证运行的结果一致。所以这是它跨平台的主要原因。
JRE:java的运行环境(解释器加JVM)
JDK:java的开发工具包,包含java的公共工具包,类库等(JRE+编译器)
java程序的运行逻辑如下
java文件->编译器->class文件->JRE解释->JVM运行解释后的代码。
如果我们有JDK那么就可以开发java程序,如果我们有JRE,就只能运行java程序。
Hello Word.java
package ceshi
public class HelloWord{
public static void main(String [] args){
System.out.Println("Hello Word");
}
}
如何编译我们的第一个Hello Word 程序呢?·
使用DOC窗口进行编译我们的第一个java程序
分析第一个Hello Word 程序
pageage:这是包名,在java程序中,一个包的名称必须是全小写的,并且必须出现在第一行。
public:这是一个修饰符,表示公开的意思(关于修饰符,这个我们后面会细说)
class:这是一个关键字,表示这个是一个类文件,类后面的就是这个类的名称。
(类名自定义,格式:首字母大写,拼接字母大写,其余字母小写)
public static void main(String [] arge){
}
这段表示java的主函数,每一个类中只能有一个这样的主函数。
其中方法参数中的args是启动java 程序是传入的启动参数变量(这个也会在后面演示)
认识注释
注释:不会参与编译
单行注释(只注释一行)://
多行注释:/**/ (由一个斜杠两个**加一个斜杠组成,两个星之间的是注释内容)
文档注释:/***/ 文档注释。(多行注释并生成帮助文档),使用方式:/** 注释内容*/
文档注释生成演示
帮助文档只会生成公开类的文档。
接下来我们讲述java的变量
变量
什么是变量?
变量的概念:计算机中的一块存储空间
内存:用于保存数据的一块存储区域
变量的数据分类
基本数据分类:整数,小数,字符,布尔类型
引用的数据分类:字符串,数组对象,自定义对象
变量声明的三种方式
先声明,再赋值(常用)
例如:int a;
a=1;
先声明并赋值(常用)
int a=1;
多个同类型变量的声明与赋值(不推荐使用,可读性差)
int a=1,b=2,c=4;
注意
java中的变量具有严格的数据类型区分(强类型),并且每个类型都有着各自的取值范围。
使用时不要超出相应的取值范围。
取值范围(可运算)
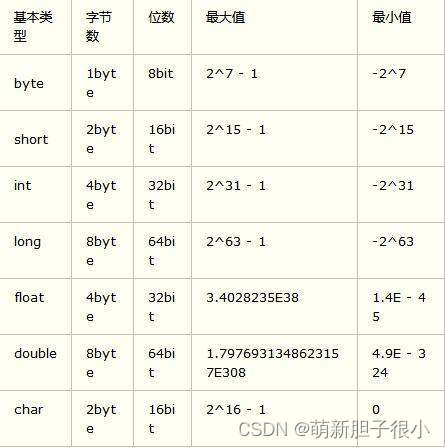
注意:整数类型默认为int,如果需要long类型赋值,则需要在值的后面加上L或者(小写L)进行标识。
浮点型数值采用科学计数法标识
以上是可以参与算数运算的基本类型,还有一种特殊类型,无法参与算数运算,那就是布尔类型。
布尔类型
boolean 1字节 只有true和false两种结果,可以直接赋值true或者false;
也可以赋值一个结果为true/false的表达式(后面会说)。
转移字符
java中存在一些特殊字符,需要进行转义才能使用
\n 换行符
\t 缩进(制表符)
\\ (转义‘\’)反斜杠
\' 单引号
\" 双引号
引用数据类型(字符串)
String,取值范围,任何的""之间的字符,
例如 String s="adasd";
String s=" 你好";空格也是字符。
类型转换
自动的类型转换
- 两种类型相互兼容并且目标类型大于原类型
//互为整数 (相互兼容)
byte b=10;
//int 的取值范围比byte大,这就是相互兼容
int i=b;
//小数之间的转换
float c=b;
//byte 所赋的值只能为整数,不能为小数
//打印c时,得到的结果为10.0
强制的类型转换
两种类型相互兼容并且目标类型小于原类型
//互为整数(相互兼容)
int i=10;
//byte的取值范围比int小,所以需要强制类型转换
byte c=(byte)i;
变换类型
强制类型转换规则,整数长度够,数据完整
例如:int i=100;byte b=(byte)i;结果b为100
整数长度不够,数据截断
例如 int b=10000; byte b=(byte)i;结果b为16(位运算符发生变化,结果无法准确预知)
小数强制转换整数,数据截断
例如 float f=10.8; int i=(int)f;结果 i=10;小数位被舍弃
字符整数互转,数据完整
例如 char c=65; int i=c;结果为 i=65;
表达式
使用运算符连接的变量或者字面值,并可以得到一个最终结果
例如:1+2=?;a=3 a-2=?;b*c=? c/b=? a>b=?
自动类型提升
进行算数运算时,两个操作数中有一个为double ,结果为double
如果两个操作数中没有double,有一个为float,结果提升为float。
如果两个操作数中没有float,有long,结果提升为long。
如果两个操作数中没有int,有short或者byte,结果仍然为int(默认)
double->float->long->int
特殊:任何类型与String相加(+)时,视为拼接字符,结果为String
运算符
算数运算符
两个操作数进行计算;
操作数 描述
+ 加,求和
- 减,求差
* 乘,求积
/ 除,求商
% 模,求余
一元运算符
操作符 递增
++ 变量值为1
操作符 递减
- - 变量值为1
例如 a++是先赋值后加1;++a是先加1再赋值 (加在前,先运算,加在后先赋值);
解析模 (%)
取余数(余数是指一个操作数除另一个操作数,如果除不尽,则多余的部分就是余数,如果除的尽则结果为0)
例如:10%3=1(这是相当于10除以3,是无法除尽的,那么为什么得到的结果是1,意味着10减去了3在10以下的最大倍数9,得到了1)
例如 123%10=3;就等于123-(10*12)=3 120是123以下最大的10的倍数。
逻辑运算符
等号右边赋值给等号左边(看描述可能更清楚一些)
操作符 描述
= 直接赋值
+= 求和后赋值
-= 求差后赋值
*= 求积后赋值
/= 求商后赋值
%= 求余后赋值
关系运算符
两个操作数进行比较
操作符 描述
> 大于
< 小于
>= 大于等于
<= 小于等于
== 等等于
!= 不等于
逻辑运算符
两个boolean类型的操作数或者表达式逻辑比较
操作符 描述
&& 与(并且)两个操作符同时为true时,才为true(常用)(阻断型)
& 与&&一致但是非阻断型
|| 或(或者)两个操作方,其中一个为true即为true(常用)(阻断型)
| 与||一致但是是非阻断型
! 取反 意为不是,true为false;false为true;
&与&&的区别:&&是阻断型
例如:if(a&&b)如果a是false,则不去判断B直接返回false;
若使用&时 if(a&&b) 如果a是false,仍然会去判断b是否为false;判断完毕后返回false;
|与||的区别:||是阻断型
例如:if(a||b)如果a是false,则不去判断B直接返回false;
若使用|时 if(a|b) 如果a是false,仍然会去判断b是否为false;判断完毕后返回false;
三元表达式
将判断后的结果赋值给变量
操作符 语义
?: 布尔表达式?结果1:结果2;
如果布尔表达式返回true,则去获取结果1,如果布尔表达式返回false,则去获取结果2;
选择结构与分支结构
基本的i选择结构
选择结构:根据已知条件进行逻辑判断,满足条件后执行
if(布尔表达式){
//代码块
}
后续代码
代码执行流程
对布尔类型进行判断
结果为true,则先执行代码块,再执行后续代码。
结果为false,则跳过代码块,直接执行后续代码。
if else 选择结构
语法
if(布尔表达式){
//代码块1
}else{
//代码块2
}
后续代码...
代码执行流程
对布尔表达式进行判断,结果为true则执行代码块1,再退出整个结构,执行后续代码。
结果为false,则先执行代码块2,再退出整个结构执行后续代码。
多重if选择结构
语法
if(布尔类型){
代码块1
}else if(布尔类型){
代码块2
}else if(布尔类型){
代码块3
}else{
代码块4
}
嵌套 if 选择结构
语法
if(外层表达式){
//代码块1
if(内层表达式){
//内层代码块1
}else{
//内层代码块2
}
}else{
//代码块2
}
执行流程
当外层条件满足条件时,再判断内层条件。
注意一个选择结构中,可以嵌套另一个选择结构,嵌套格式正确的情况下,支持任意组合。
分支结构
switch(变量表达式){
case 值1:
逻辑代码1;
case值2:
逻辑代码2;
case3:
逻辑代码3;
case 值n:
逻辑代码4
default:
未满足时的逻辑代码;
}
switch 可判断类型:
byte short int char String(String需要JDK1,7以上)
执行流程
如果变量中的值等于1,则执行逻辑代码1.
如果变量中的值等于2,则执行逻辑代码2
如果变量中的值等于n,则执行逻辑代码n
如果变量中的值没有匹配的case值时,则执行default中的逻辑代码。
注意所有的case的取值不可以相同
当匹配的case执行后,并不会自动退出整个机构,而是继续向下执行(称为穿透)
case '1'=='1'
System.out.Println("测试穿透");
break;
break关键字,可以在匹配的case执行后,直接跳出整个结构,不在执行剩下的case判断。
局部变量
概念:声明在函数内部的变量,必须先赋值再使用。
作用范围:定义行开始到所在的代码块结束。
注意:多个变量,在重合的作用范围内,不可以出现重名(命名冲突)
例如
public static void main(String[] args){
//声明在函数内部
//定义行,到该方法执行结束
int a=1;
//不可重名
//int a=2;(编译报错,无法编译)
}
//此时方法结束,变量从内存中被移除
循环结构
程序中的循环
概念:通过某个条件,重复的执行一段逻辑代码;
程序的开始←---循环操作
↓ ↑
循环条件-------> true
↓
false
↓
循环结束,执行后续代码
while循环
语法
while(布尔表达式){
//逻辑代码(循环操作)
}
执行流程
先对布尔表达式进行判断,结果为true,则执行逻辑代码。
本次执行完毕后,再次进行判断,结果仍然为true,则再次执行逻辑代码,
直到布尔表达式的结果为false时,才会退出循环结构,执行后续代码。
while 循环有四个部分组成
例:
//初始变量
int i=1;
//设置循环条件 i<=100
while (i<=100){
//循环操作
System.out.println("1000");
//迭代部分
i++;
}
初始部分:定义用于判断的变量
循环条件:决定师范继续循环的依据
循环操作:单次执行的逻辑代码或者任务
迭代部分:控制循环条件改变的增量,防止死循环。
while的特点
在首次不满足,则一次都不会执行。
首次既有入口条件先判断,再执行。
使用场景
适用于循环次数明确的情况
do while 循环
语法
do{
逻辑代码(循环操作)
}while(布尔表达式);
执行流程
先执行一次循环操作之后,再进行布尔判断,如果结果为true,则再次执行循环操作。
如果结果为true。则再次执行循环操作
如果结果为false,才会退出循环,执行后续代码。
特点
首次没有入口条件,先执行,再判断,至少执行一次。
使用场景
适用于循环次数不明确的情况。
for循环
语法
for (初始部分;循环条件;迭代部分){
//循环操作(逻辑代码)
}
执行流程
首次执行初始部分(仅一次)。
对循环条件(布尔表达式)进行判断,结果为true。则执行逻辑代码。
本次执行完毕后,执行迭代部分,再次判断,结果仍然为true,则再次执行逻辑代码。
直到布尔类型的结果为false时,才会退出循环结构,执行后续代码。
相同点
for循环与while循环相同,首次判断不满足,则一次都不会执行(执行次数0~n次)
特点
首次既有入口条件,先判断,再执行。适用于循环次数明确的情况;
关键字
break: 终止,跳出switch,循环结构(循环中遇到了break,则退出整个循环结构。不再执行循环)
continue: 结束本次循环,进入下一次循环(循环中遇到continue则跳过此次,进入下一循环)
嵌套循环
概念:在一个完整的循环结构中,嵌套留一个完整的循环结构
//i控制外层循环次数
for(int i=1;i<100;i++){
//c控制内层循环次数
for(int c=1;c<100;c++){
}
}
外部循环执行一次,内部循环会执行一遍
例如外部循环为5次,内部循环为10次,在外部循环开始时,外部每循环一次,则内部循环都会循环10次
函数
概念:实现特定功能的一段代码,可以反复使用
public void method(){
//逻辑代码
}
上面就是一个函数
形参与实参
形参与实参
形参案例
//String s就是形参
public void method(String s){
}
实参案例
method("SS");
注意
实参等价于局部变量的赋值。
一个函数的形参可以多个.
如何定义参数?
根据业务的需要来定义函数的参数,
但是注意一个函数的形式参数最多不要超过五个,否则这个方法的参数会非常混乱。
返回值和返回值类型
函数调用时一些情况下无需返回结果;另一些情况下必须有返回值结果
语法:
public 返回值类型 函数名称(形式参数列表){
//函数主体
return ;
}
返回值类型:规定返回的具体类型,void没有类型
调用语法:
变量=函数名称(实际参数)
变量类型与返回值一致。
return
return关键字,返回与返回值类型相同的实际变量,一个函数中只能有一个返回值,
函数内部存在分支结构时,若return存在不同的分支时。必须确保每一条都有正确的返回值。
函数的好处
减少代码的冗余
提高复用性
提高可读性
提高可维护性
方便分工合作
递归
什么是递归?
当一个函数在函数内部调用自己时就成为递归,递归应当有一个正确的出口条件,否则会产生无穷递归的情况。
什么情况下使用递归
当需要解决的问题可以产分成多个小问题,并且问题的解决方案一致时,可以使用递归,
注意
使用递归一定要设置有效的出口条件,避免无穷递归
递归和循环的区别?
for:从小到大的解决思路
递归:从大到小的解决思路
所有需要递归解决的问题,使用循环一定也可以解决,当解决复杂问题时,递归的实现和思路更加简单
数组
概念:一组连续的存储空间,存储多个相同数据类型的值
特点:数据相同,长度固定
数组的创建
//声明int的数组类型,变量名称定义为a
int[] a=new int[5];
//分配长度为5的连续空间
数组中的每个数据格被成为数组元素
对每个元素进行赋值或者取值的操作被成为'元素的访问'
访问元素时,需要使用'下标'(从0开始,依次加1,自动生成)
访问的语法:数组名[下标];
例如:a[0]=10;取a[0]下标比长度少1
数组的使用
public static void main(String[] args){
int[] arrayi=new int[5];
//赋值
arrayi[0]=1;
arrayi[1]=2;
arrayi[2]=3;
arrayi[3]=4;
arrayi[4]=5;
//取值使用
System.out.Println(arrayi[0]);
}
下标的使用及范围
语法:变量名[下标];获取固定位置的参数,不可以访问超出数组固定长度的参数。
数组的遍历
public static void main(String[] args){
int[] arrayi=new int[5];
//赋值
arrayi[0]=1;
arrayi[1]=2;
arrayi[2]=3;
arrayi[3]=4;
arrayi[4]=5;
//取值使用
System.out.Println(arrayi[0]);
for(int a=0;a<=arrayi.lenth;a++){
//遍历时使用变量a作为下边进行遍历取值
System.out.Println(arrayi[a]);
}
}
数组的创建语法
先声明再分配空间
数据类型[] 数组名;
数组名=new 数组类型[长度];
声明并分配空间
数据类型[] 数组名=new 数据类型[长度]
声明并赋值(繁)
数据类型[] 数组名=new 数组类型[]{value1,value2,value3
}
这种写法直接把value 直接赋值到下标上,自动赋予长度和下标,根据写入赋值的次数,分配的下标是多少
声明并赋值(简)
数据类型[] 数组名={}赋值1,赋值2,赋值3}
显示初始化:不可换行,显示赋值
数组的扩容
创建数组时,必须显示指定长度,并在创建之后不可更改长度
扩容的思路
创建大于原数组长度的新数组,并将原数组中的元素复制到新数组中去。
例如
内存:
old:[1][22][33][44][55]->旧数组
now:[1][22][33][44][55][][][]-新数组
栈和堆
栈:在基本类型中表示可存储变量名称所代表的值。
栈在引用类型中表示存储变量名称所代表的地址,它是一个转点,将变量引入堆所开辟的空间中。
堆:是数组开辟空间的地方,堆在开辟之后,会产生一个地址,这个地址会被栈保存
数组
变量(名称)->栈(存储堆产生的地址)->通过地址找到数组的实际空间->堆(开辟空间,产生地址)
地址的替换
数组作为引用类型之一,其变量中存储的是数组的地址。
完成元素复制后,需要将将新数组的地址,赋值给原变量进行替换
-地址a开辟的空间
内存 地址b
-地址b开辟的空间
通过a=b的方式,使a的地址将b的地址改变。
复制的方式
循环将原数组中的所有元素逐个赋值给新数组。
System.arrayCopy(原数组名,原数组的起始下标,新数组名,新数组的起始下标,复制的长度);
Java.util.Array.copyOf(原数组,新长度);返回带有原值的新数组。
可变长参数
概念:可接受多个同类型的实参,个数不限,使用方式与数组相同
语法:数据类型...形参(可变长参数,必须定义在形参列表的最后且只能有一个)
public static void method(String s,String... sarray){
//s是单个实参
//sarray是一个可变长参数。只能放在参数列表的最后。
}
数组的排序
冒泡排序:相邻的两个数值比较大小,互换位置
public class FastBubble{
public static void main(String[] args){
int[] a={99,77,11,22,33,44};
//创建一个for循环
for(int i=0;i<a.length-1;i++){
//创建第二个for循环
for(int c=0;c<a.length-1;c++){
//如果a[c]大于a[c+1],则
if(a[c+1]<a[c]){
//获取小的那个参数
int v=a[c+1];
//获取大的参数
int v1=a[c];
//将小的给当前参数
a[c]=v;
//将大的给后面
a[c+1]=v1;
}
}
}
}
}
选择排序
固定值与其他值依次比较大小,互换位置
public class ArrayBubble{
public static void main(String[] args){
int[] a={99,77,11,22,33,44};
//创建一个for循环
for(int i=0;i<a.length-1;i++){
//创建第二个for循环
for(int c=0;c<a.length-1;c++){
//判断固定值是否小于可变值
if(a[c]<a[i]){
//获取小的那个参数
int v=a[c];
//获取大的参数
int v1=a[i];
//将小的给当前参数
a[i]=v;
//将大的给后面
a[c]=v1;
}
}
}
}
}
JDK排序
java.util.Arrays.sort(数组名称);
自动升序,无法降序
二维数组
概念:一维数组中的一维数组;数组中的元素还是数组。
了解一下即可
面向对象
什么是对象?
面向对象思想:object Oriented Programming
一切客观存在的事物都是对象,万物全是对象。
特征:称为属性,一般是名词,表示一个对象有什么,比如鸟有翅膀(见明知意,就是一个对象的特征)
对象
行为:称为方法,一般是动词,表示对象能做什么,比如鸟能飞(见明知意,就是一个对象能做什么)
如何使用程序模拟现实世界,解决现实问题?
在程序中,需要将现实中所描述的事物,分析并建模出一个能够与之对应的一个对象。
然后在程序中代表这个现实对象进行操作,从而解决现实问题。
什么是类?
例如汽车,当我想买一个车的时候,我内心只是车,
而当我具体到想要什么型号的车时,那么我心中想要的那个车,就是对象
比如我想要一个七手的qq,那么这个qq就是车的对象。
又例如汽车设计图,规定了这样的外观,内部,发动机等具体信息。
这就是现实对象的模板。程序对模板也有相同的作用,称为类!
按照设计图做出的汽车,是真是存在的可用的实体,
所以汽车实体被称为现实中的对象,而通过程序中的模板创建出来的实体称之为对象。
模板就是类,根据模板创建出来的实体,是对象
类的抽取
在一组相同或者类似的对象中,抽取出来共性的行为和特征,保留所注意的核心点。
例如:狗是一个类,所有的品种的狗都可以称为狗
狗的特性有:品种,年龄,性别,发色
狗的行为有:吃,睡
一个类的创建
public class Dog{
//品种
String variety;
//年龄
int age;
//性别
String sex;
//颜色
String color;
/**
吃方法
*/
public void eat(){
}
/**
睡方法
*/
public void sleep(){
}
}
解析上面写的Dog
类声明的品种,年龄以及颜色就是所说的特征;
特征可以称之为属性,通过变量表达。
语法
修饰符 类型(基本类型+引用类型) 变量名称;
这样直接声明在类下的属性,我们称为成员变量。
在对象创建后叫做实例变量,因为声明的大部分都是在创建对象时才进行赋值。
行为:是通过函数的方式表达,比如吃睡。
位置:
行为:类的内部
属性:类的内部,方法的外部。
对象的创建
public static main(String[] args){
//对象的创建
Dog dog=new Dog();
//属性的赋值
dog.sex="公";
//年龄
dog.age=1;
//年龄
dog.color="黑色带点黑"
//方法调用
dog.eat();
}
new关键字
类型 变量=new 类型();
在使用new关键字时,java会根基new 关键字在堆中开辟空间。
类型();会返回开辟的堆空间的地址。从而实际的访问我创建的堆空间。
成员变量赋值变为实例变量
语法:通过new出的变量再.出具体的属性,进行赋值(如果不赋值,基本类型有默认值,引用类型是null)
例如:dog.sex="公";dog.age=1;
如果调用行为?
语法:通过new出的变量再.具体的方法,进行调用!
例如:dog.eat();
类与对象的关系?
(类)模板-new关键字-对象(实例)
类:定义了对象具有的特性和行为,类是对象的模板。
对象:根据模板通过new关键字创建出的实例。
类与对象在程序来说,类是现实问题的抽象模板,
我们一般不会对模板进行改动,除非现实场景发生变化。在程序运行中,除去一些特殊类,
类都会通过关键字创建出对象,如果一个类在非特定场景下,仍然不会通过关键字创建出对象的话,
那么这个类也是无用。
因为在开发中,我们往往是根据模板创建对象,并对创建出的实例,进行赋值并操作这个实例,从来不会操作模板。
因为模板是面向开发人员和场景的,而对象则是面向程序实际解决问题的。
建造模板的注意事项
每一个类,都应该是各司其职的,他的功能应该单一的,仅仅是在需要他的地方才会出现并解决问题。
例如:一个汽车,汽车中应该有很多属性,那么这个汽车中,他的各个部件各个参数,应该是相互分开的。
比如发动机,他应当是一个单独的类,这个单独的类去说明发动机内部的参数,
而车这个类,则去整合发动机类,而不是直接将发动机的各个信息也写到车这个类中。
这样会使得代码非常庞大,并且极难进行维护。
类的特点
可复用性:指的是类似的功能,不同的系统可以重复使用相同的代码。
可扩展性:是指在不修改原有系统的前提下,对现有功能进行扩展
弱耦合性:让对象与对象之间的联系尽可能的变弱。
可复用性:例如,我们在一个宠物医院的系统中,我们对狗进行了定义,
那么如果我们在动物管理系统中,就无法使用宠物医院中对狗的定义了吗?
显然不是,我们可以重复使用这个类。使用时,我们应当将这个类放到公共区域。
可扩展性:当我们将现实问题抽象成模板后,
我们所面临的问题,不再是模板是否变化,而是实际创建的对象是否变化,
我们可以根据各种系统以外的配置或者数据库参数,决定程序的走向,
这样我们既没有改变程序源代码,但是仍提供了功能。
弱耦合性:当汽车中直接写入了发动机的各种参数,那么这个发动机与这个汽车就强制绑定在一起了,
这就是强耦合,那如果我们把发动机和汽车通过不同的类进行了定义,
那么是否当发动机型号发生改变时,不会影响到汽车的运行呢?
显然是这样的。因为发动机和汽车的模板相互抽离,没有强制绑定在一起。
实例
定义:通过new 关键字创建出的对象,就是实例,每一次使用new 关键字,都会创建一个实例。
当然如果是创建完成后,地址的重新指定,那么就不会再创建一个实例,而是指向之前创建的实例的地址。
例如
public static void main(String[] args){
Dog dog=new Dog();
//开辟第二块空间保存dog1
Dog dog1=new Dog();
//没有开辟第二块空间保存dog3,而是将dog的对象地址赋值给了dog3
//相当于dog和dog3,其实是一个对象,不过是有两个名字而已。
Dog dog3=dog;
//这个地方,其实和我们之间所说的栈和堆所保存的内容有关
//栈只保存方法内部的局部声明(基本类型),但是引用对象的创建实际是存储在堆中的。
//那么栈 保存了 dog dog1 dog3 这三个变量,其实保存的不是实际数据
//而是堆所开辟出来的实际内存的地址值,那么当将dog的地址值赋值给dog3时,那么也就是意味着
//dog3所指向的地址与dog指向的地址是同一处地址。所以在程序上来说,他们是相同的对象
//只不过代码中的变量名称不一致
}
实例变量
无需先赋值后使用,基本类型系统会分配一个默认值,引用类型是null
基本类型默认值:
整数:0;
小数:0.0
字符:\u000(空格)
布尔:false;
引用类型:null;
成员变量与局部变量的区别
定义位置:成员变量在方法外,类中,局部变量在方法内。
默认值:成员变量有默认值,而局部方法没有
使用范围:成员变量,本类有效,而局部变量则是从定义行到方法结束。
命名冲突:方法内的局部变量命名不可冲突,但是成员变量与局部变量命名可以冲突,但是局部优先。
实例方法
方法的声明表示了对象能做什么。它本质上是一个函数,
但是在实例对象创建完成后,这个函数可以访问实例变量并操作实例变量,能够做更加复杂的功能。
方法的重载(Overload)
概念:有些情况下,相同的方法名称,会根据程序参数的不同,提高不同的实现功能。
例如:华硕电脑与联想电脑,他们都可以开机,但是它们都会对自己的硬件都有着特殊处理。
语法:
重载的方法名称必须一致;
方法的形参数列表不同;
与访问修饰符,返回值类型无关。
//无参
public void method(){
}
//形参列表不同
public void method(String s){}
//与返回值无关
public String method(int i){}
调用重载方法时,需要根据传入的实际参数找到与之匹配的方法。
注意:如果这是形参的名称不同,不会构成方法的重载,便是期间就会报错。
好处
屏蔽使用差异,灵活,方便
特性
向上就近匹配原则,如果实际参数,与形参不同就近选择类型
例如:实参为byte,形参为int和short,选择short();
(这个特性其实可以忽略)
构造方法
概念:类的特殊方法,主要用于创建对象
特点:名称与完全类名一直,没有返回值
调用时机
创建对象时,触发构造方法的调用,不可手动调用。
注意
如果没有在类中显示写构造方法,编译器会默认提供一个没有参数的构造方法。
//其实我们在写new Dog();就是调用的构造函数,java根据调用的构造函数,去堆中开辟空间。
public Dog(){
}
对象创建的过程
类名 自定义=new 类名();
new触发对象创建
1.内存中开辟对象空间
2.为各个属性附初始值
3.执行构造方法中的代码
4.[将对象的地址赋值给变量]
在存储对象的变量 自定义(引用)中保存对象的地址,通过变量中的地址访问对象的属性和方法。
构造方法也是可以重载的,遵循重载的规则
创建对象时,根据传入的参数,匹配对应的构造方法
在类中如果已经手动添加了构造方法,则无参构造方法则不在提供。
可以通过构造方法中的参数向成员变量赋值。
public Dog(int age,String color){
age=age;
this.color=color;
}
public static main(String[] args){
Dog dog=new Dog(1,"红色");
}
this关键字
概念:this.是获取地址并能得到这次对象的地址。
类是模板,可服务于此类的所有对象
this是类中的默认引用,代表当前实例
当类服务于某个对象时,this则指向这个对象
例如
当对象是dog时,this指向dog的age;
当对象是dog1时,this则指向dog1的age;
this是隐式存在的,可以把this理解为存在的对象地址,它既是实际地址。
但是它却会变化,因为当地址变化时,this表示不同对象。
this的使用方法
- 当形参名称与成员变量名称相同时,使用this来区分成员变量和局部变量
public void method(String name){
thsi.name=name;
}
- 在构造方法中调用其他构造方法
注意使用this调用构造函数时,必须放在首行。
public Dog(){
}
public Dog(int age){
this();
}
面向对象的三大特性
封装
什么是封装?
概念:尽可能隐藏对象内部的实现细节,控制对象的修改以及访问的权限。
访问修饰符
private:(可将属性修改为私有,仅本类可见)
封装的必要性
在类与类之间,联系应当划清界限。
使用封装之后,类内部的部分信息将对外部不可见,仅对内部类可见,这样的设计,可以让程序在运行中
不会出现不可预料的变数。
同时封装的出现也可以在参数进行设置时,提前出现错误,防止程序的正常使用。
例如:一个人的年龄,我们将属性私有之后,调用方必须使用getset方法取出和设置变量。
我们在set时,对传入参数进行了判断,那是不是就可以防止很多非法的数据进入类的内部。
属性的封装
当我们将成员变量设置为私有后,应当暴露出两个方法,分别是set设置变量以及get获取变量
例如
public class TestPrivate{
//变量设置为私有,并提供setget方法
private String name;
//通过set方法设置名称
public void setName(String name){
//判断如果是测试数据,则过滤并打印日志。
if(name.equals("测试")){
System.out.Printlin("测试专用无法生效!");
return ;
}else{
this.name=name;
}
}
//将实例变量返回。
public String getName(){
return this.name;
}
}
set/get是外界访问对象私有属性的唯一通道。
方法内部可以对数据进行检测和过滤。
set:使用方法参数实现赋值。
setXXX()
get:取值
getXXX()
使用方法返回值实现取值。
继承
生活中的继承是一种赠予,将一方所有用的东西给予另一方。
程序中的继承
程序中的继承,是类与类之间特征和行为的一种赠予和获得,两个类之间的继承关系,必须满是‘is a’关系
例如
dog is an Animal
父类的选择
现实生活中,很多类别之间都存在着继承关系,都满足is a的关系
狗是一种动物,一种生物,也可以是宠物
多个类别都可以是狗的父类,需要从中选择做适合的父类
当功能越精细,重合越多,越接近直接父类。
功能越粗略,重合点越少,越接近Object类(所有类的父类)
父类的抽取
实战:可根据程序需要使用的多个具体类,进行共性抽取,进而定义父类。
比如
动物,燕子是动物,狗是动物,猫也是动物,但是燕子是天生飞的,而狗和猫是地上跑的,
那么猫和狗则可以有一个父类,而燕子则需要单独一个鸟的父类。
而不管怎么的父类,他们都应该有年龄,品种,那么鸟的父类,和猫狗的父类都用是动物的子类。
父类
在一组相同类中或者相似的类中,抽取出来共性的特征和行为,定义在父类中实现复用。
继承的语法
语法:class 类名 extends 父类{ }
定义子类时,显示继承父类。
应用:产生继承关系之后,子类可以使用父类中的属性和方法,也可以定义子类独有的属性和方法。
好处:提高代码的复用性,提高对diamante的可扩展性。
特点
java为单继承,一个类只有一个直接的父类,但是可以多级继承,属性和方法逐级叠加。
public class Animal{
//年龄
int age;
//吃方法
public void eat(){
}
}
public class Dog extends Animal {
//子类独有的属性
String color;
//继承之后,不行写,就有吃方法。
}
不可继承
构造方法,类中的构造方法只负责创建本类对象,不可继承(指调用父类的构造方法)
private 属性修饰的属性和方法;
父子类不在同一个package中时,default修饰的属性和方法
访问修饰符
本类 同包 非同包子类 其他(不同包,不是子类)(冲上向下,从严到宽)
private √ × × ×
default √ √ × ×
protected √ √ √ ×
public √ √ √ √
子类对父类方法的覆盖(Override)
当父类提供的方法无法满足子类需求时,可在子类中定义和父类相同的方法进行覆盖(Override 重写)
方法覆盖原则
方法名称,参数列表,返回值必须与父类相同
访问修饰符可与父类相同或者比父类更宽松
方法覆盖的执行
子类覆盖父类方法后,调用时,优先执行子类覆盖后的方法。
super关键字
在子类中,可直接访问从父类继承到的属性和方法,
但如果父子类的属性存在重名(属性遮蔽,方法覆盖)时,需要加以区分,才可以访问。
如果在重写父类方法后,仍然调用父类的同名方法呢?
public class Animal{
//年龄
int age;
//吃方法
public void eat(){
}
}
public class Dog extends Animal {
//子类独有的属性
String name;
//重写吃方法
public void eat(){
int a=super.age;
this.name="测试指定this";
//通过supper关键字调用父类的方法
super.eat();
}
}
使用super关键字,可以访问有权限访问父类的方法和属性。
一般用于实现了重写或者因为属性名称一直导致的属性遮蔽,需要直接指定父类的方法和属性时。
父子类的同名属性,其实不存在覆盖关系,因为父类和子类不是一个地址。
两块空间同时存在(子类与父类属性同名时),
需要不同的前缀进行访问。
当前对象使用this前缀
父类参数使用super前缀
继承中的对象创建
在具有继承关系的对象创建中,构建子类对象会先构建父类对象。
由父类的共性内容,叠加子类的独有内容,组成完整的子类对象。
public class Test {
public static void main(String[] args){
new C();
}
}
class A{
}
class B extends A{
}
class C extends B{
}
构建过程
1.分配空间( A B C );
2.构建父类对象B->构建父类对象A-构建对象C;
3.初始化属性C->初始化属性B->初始化属性A;
4.执行构造方法C-执行构造方法B-执行构造方法A;
super调用父类无参构造
public class Test {
public static void main(String[] args){
new C();
}
}
class A{
public A(){
System.out.println("A")
}
}
class B extends A{
public B(){
super();
System.out.println("B")
}
}
class C extends B{
public C(){
super();
System.out.println("C")
}
}
执行结果
A B C
注意
super();表示调用父类的无参构造方法,如果没有显示书写,仍然会隐式存在与子类的构造方法中。
super调用父类的有参构造
public class Test {
public static void main(String[] args){
new C(1);
}
}
class A{
public A(int a){
System.out.println("A")
}
}
class B extends A{
public B(int a){
super(a);
System.out.println("B")
}
}
class C extends B{
public C(int a){
super(a);
System.out.println("C")
}
}
super();表示调用父类无参构造方法
super(实参):表示调用父类的有参构造方法。
this与super
public class Test {
public static void main(String[] args){
new C();
}
}
class A{
public A(){
System.out.println("A")
}
}
class B extends A{
public B(){
super();
System.out.println("B")
}
}
class C extends B{
public C(){
super();
System.out.println("C")
}
public C(int a){
this();
System.out.println("C1")
}
}
执行结果
A B C C1
this或super使用在构造方法中时,都要求在首行。
当子类构造中使用了this()或者this(实参),既不可再同时书写super或者super(实参),
会由this指向的构造方法完成super()的调用。
总结
super关键字的第一个用法
在子类的方法中使用super.的形式访问父类的属性和方法。
例如super.父类属性名称,super.父类方法();
super关键字的第二种用法:
在子类的构造方法的首行,使用super()或者super(实参),调用父类的构造方法。
注意
如果子类的构造方法中,没有显示定义super()或者super(实参),则默认提供super();
同一个子类构造方法中,super()和this()不可同时存在。
多态
引言:生活中,一个人,如果对与老师来说是学生,对于同学来说他就是同学,对于父母来说,他就是孩子。
生活中的多态是指:一个事物在不同情况下的不同形态。
程序中的多态
概念:父类引用指向子类对象,从而产生多种形态。
父类引用指向子类对象
只能调用父类中的方法和属性,不能调用子类独有。
例如
Animal animal=new Dog();
父类引用 -> 子类实现
二者具有直接或者间接的继承关系时,父类引用可指向子类对象,形成多态,
父类的引用仅可以调用父类所声明的属性和方法,不可调用子类独有的属性和方法。
多态中的方法覆盖
在方法覆盖中,依旧遵循覆盖原则,如果子类覆盖了父类的方法,则执行子类中覆盖的方法,否则执行父类方法。
若使用多态的语法
父类 变量名=new 子类();
若子类覆盖了父类的方法时,则优先执行覆盖后的方法
多态的应用
场景一:使用父类作为方法形参实现多态,使方法参数的类型更加宽泛。
例如
//方法
public void method(Animal a){
}
//调用
methdo(new Dog());
场景二:使用父类作为方法的返回值实现多态,使方法可以返回不同的子类对象。
例如
//方法
public Animal method(){
return new Dog();
}
向上转型
public class Test {
public static void main(String[] args){
Animal animal=new Dog();
}
}
父类引用中保存真实的子类对象。称之为向上转型(多态的核心概念)
注意
仅可以用父类中可访问的所有属性和方法
向下转型(拆箱)
public class Test {
public static void main(String[] args){
Animal animal=new Dog();
Dog dog=(Dog)animal;
}
}
将父类引用中的真实子类对象强制转换为子类本身,称之为向下转型。
注意
只有转换为子类的真是类型,才能调用子类独有的方法。
向下转型时,如果父类引用的子类对象和强转的目标类型不匹配
会爆出ClassCaseException类型选择异常。
instanceof 关键字
概念:判断引用的对象的真实类型
语法
引用对象 instanceof 类型 会返回一个布尔类型结果。
例如
//判断狗是否是猫类型。结果肯定是false;
if(dog instanceof Cat){
}
//判断狗是不是狗类型 结果肯定是true;
if(dog instanceof Dog){
}
场景
当判断对象的真实类型结果为true时,则再去进行强制类型转换,防止出现类型转换异常。
多态的作用
屏蔽子类间的差异,灵活,耦合度低。
重写(Override)与重载(Overload)
方法重写:在子类中出现与父类一模一样的方法声明的现象。
方法重载:同一个类中,出现的方法名相同,但是参数列表不同。
与修饰符返回值无关。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









