







1.背景
1.1 起因
在某个业务需求中,出现了需要给出拼音以供客户端进行模糊搜索的场景,恰巧没有现成可用的汉字转拼音库,那么我们不得不寄希望于go语言生态中的汉字词句转拼音开源库了
1.2 诉求分析
语言:当然是Golang
场景要求:
- 可以将一段中文字词句转换为汉语拼音;如”汉语拼音“转换为”hanyupinyin“
- 可以正确区分一些词语的多音字发音,如”重庆“可以正确转换为”chongqing“而不是”zhongqing“
- 不能引入动态外部资源(即运行时请求外部接口、编译时下载外部资源文件)
2.寻找开源库
诉求相对明了的情况下,我们就可以对GitHub上已有的go语言库进行一轮筛选了,这里提供了靠前的几个库(感谢kimi和deepseek帮我总结)
- go-pinyin GitHub star数最高,但是仅支持逐字转拼音
go-pinyin 是一个非常流行的 Go 语言拼音转换库,能够将汉字转换为拼音,并且支持多音字的处理。
- 特性:
- 支持汉字到拼音的转换。
- 支持多音字处理,但需要手动指定正确的拼音
- 提供丰富的 API,支持声调符号、数字表示等多种格式
- 灵活配置:支持多种拼音风格,包括带声调、不带声调、声调用数字表示等
- 持续维护:项目活跃,作者定期更新并修复问题,保证了项目的稳定性和兼容性
- 缺点:
- 转换方式为逐字转换,不支持语句转换支持,无法对专有名词进行整体多音字转换
- gpy 基于go-pinyin实现,支持分词
- 特性:
- 基于go-pinyin实现,具备go-pinyin的上述特性
- 分词 & 多音字处理:通过分词支持汉字词句转换,可正确处理多音字词和专有名词,能够较好地处理词语中的多音字,例如“重庆”会正确转换为“chongqing”:
- 无外部依赖:所有数据都嵌入在库中,无需引入动态外部资源
- 可拓展性:分词词库、拼音词典均支持用户自定义添加
缺点: - 项目活跃度相对较低,更新频率不如其他两个库,可能在某些特殊场景下缺乏支持。
- pinyin-golang CC-CEDICT 词典实现
特性:- 词典准确性:基于 CC-CEDICT 词典,能够更准确地处理多音字
- 无需外部资源:拼音数据库嵌入到二进制文件中,无需额外依赖,简化了部署过程
- 性能优化:采用静态编译方式,启动速度快,处理大量数据时表现出优秀的性能
- 简单易用:API 设计清晰,只需几行代码即可实现汉字到拼音的转换
- 缺点:
- 词库可能不够全面,对于一些生僻字的处理可能存在不足
- 边缘情况存在问题:https://github.com/Lofanmi/pinyin-golang/issues/2
那么根据我们的诉求,似乎只有gpy 可以满足,不妨来一起看看他的表现和实现吧。
3 gpy库分析
在这里我们将对gpy库进行功能验证、项目设计分析、安全性分析,以便更好地了解其实现原理和性能表现
正式开始前,我们不妨在脑中对汉字词句转拼音的流程形成一个大概的印象:汉字词句 -> 分词 -> 拼音转换 -> 拼音输出为指定格式的拼音字符串
3.1 功能验证 & 实操
根据gpy的readme,如果我们想要使用词句转拼音,应该使用 github.com/go-ego/gpy/phrase这个package的功能
不过readme的介绍还是显得稍微有些粗糙,我在这里补充一下最简单的用法:
package main
import (
"fmt"
"github.com/go-ego/gpy/phrase"
"github.com/go-ego/gse"
)
var test = `西雅图都会区; 长夜漫漫, winter is coming!`
func main() {
// load default gse dict
_ = phrase.LoadGseDictEmbed("zh")
// convert a Chinese string paragraph to pinyin
fmt.Println("gpy phrase:", phrase.Paragraph(test))
// if you want to customize the pinyin of a word, you can use the following code
//phrase.DictAdd["都会区"] = "dū huì qū"
phrase.AddDict("都会区", "dū huì qū")
// convert a Chinese string paragraph to pinyin with user's dict
fmt.Println("gpy phrase:", phrase.Paragraph(test))
}
输出为:
gpy phrase: xi ya tu dou hui qu; chang ye man man, winter is coming!
gpy phrase: xi ya tu du hui qu; chang ye man man, winter is coming!
phrase.LoadGseDictEmbed("zh")用于加载内置的分词词典,也可以用其他方法加载自定义的分词词典,不过这里先不展开phrase.AddDict用于添加用户自定义的拼音词典phrase.Paragraph用于转换中文字词句为拼音
可以看到,“都”字在默认情况下会被转换为“dū”字,而我们通过phrase.AddDict添加了一个自定义的拼音词典,所以“都”字被转换为了“dū”
那么从结果上看,gpy库的确能够满足我们的需求,不过我们还需要对其进行更深入的分析,以便更好地了解其实现原理和性能表现
3.2 预期
在开始实现分析前,我们也不妨先考虑一下,转拼音的需求和实现方式大致会是怎么样的呢?
- 需求:将汉字词句转换为拼音,并且需要支持多音字处理、可以输出不同风格的拼音(如不带声调或者声调用数字表示)
- 实现方式:语句分词 -> 拼音转换 -> 拼音输出为指定格式的拼音字符串
- 分词:将汉字词句分割为一个个词语(非本库重点,可以使用即可)
- 添加分词词库:支持用户自定义添加分词词库
- 拼音转换:将词语转换为拼音
- 用户自定义拼音词典:支持用户自定义添加拼音词典,用于应对专有名词等情况
- 拼音输出:将拼音输出为指定风格的拼音字符串
- 支持多种拼音风格:包括带声调、不带声调、声调用数字表示等
那么带着这些思路,来看看gpy库的项目结构和实现方式
3.3 项目分析
gpy库的主要项目流程和代码结构如下:
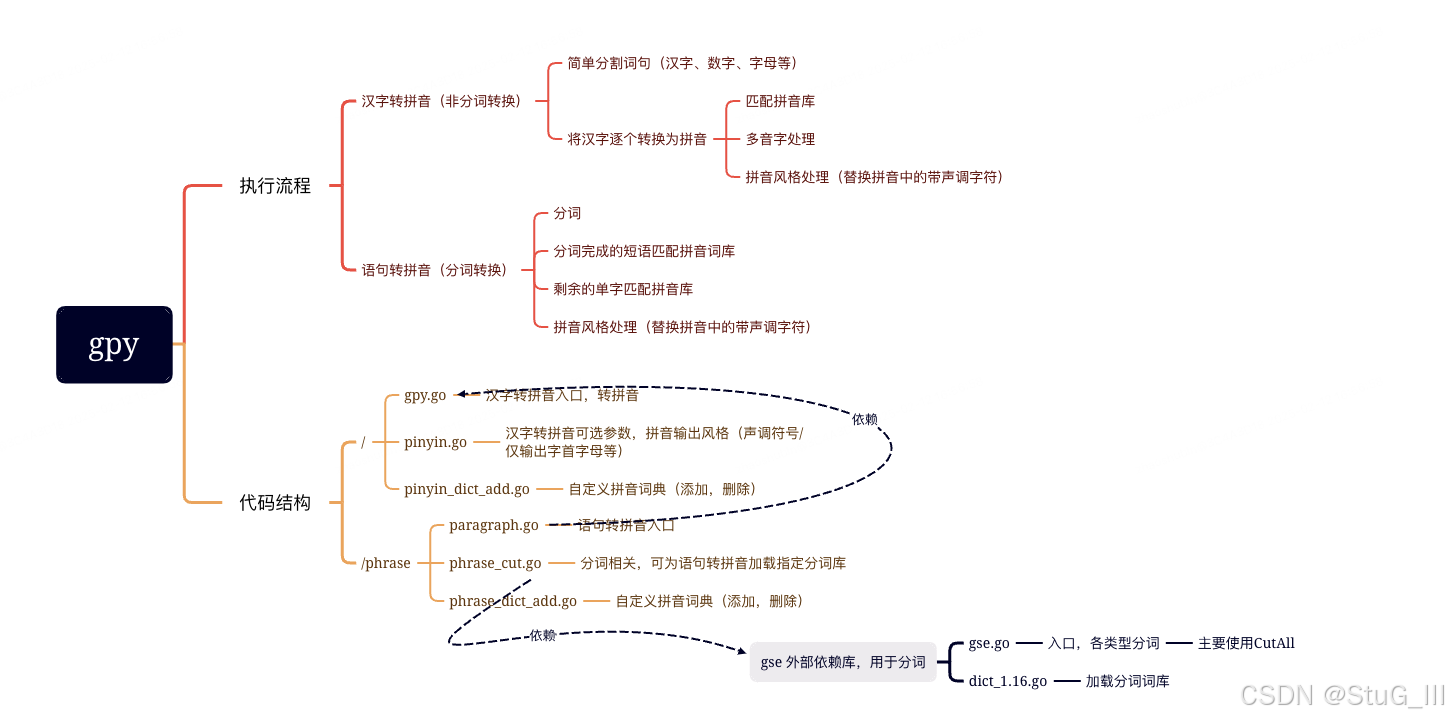
3.3.1 pharse package
图上说得七七八八,那么我们把关注点放到phrase这个package上,看看有没有需要注意的地方
- 注意,如果没有加载任何词库,那么最终输出的结果会和没有分词一样,所以在使用前一定要确保词库已经加载!!!
入口函数
Paragraph的作用是将一个中文段落转换为拼音,其函数签名如下:
func Paragraph(p string, segs ...gse.Segmenter) (s string)
不难看出,segs是一个可变参数,用于传入分词器,如果不传入分词器,则使用默认的分词器;那么我们接下来就需要看看分词器是怎么初始化的了
默认
对于分词词库的初始化,有一些包装好的函数,下面这个函数是用于加载内置词库的:
package phrase
// LoadGseDictEmbed load the embed dictionary
func LoadGseDictEmbed(dict ...string) error {
loaded = true
return seg.LoadDictEmbed(dict...)
}
提供一个例子:
func phraseExampleWithEmbedDict() {
// load default gse dict
_ = phrase.LoadGseDictEmbed("zh")
// convert a Chinese string paragraph to pinyin
fmt.Println("gpy phrase:", phrase.Paragraph(test))
// if you want to customize the pinyin of a word, you can use the following code
//phrase.DictAdd["都会区"] = "dū huì qū"
phrase.AddDict("都会区", "dū huì qū")
// convert a Chinese string paragraph to pinyin with user's dict
fmt.Println("gpy phrase:", phrase.Paragraph(test))
}
自定义分词器
如果我们想要使用自定义的分词器,那么可以使用下面的方法,先创建自定义的分词器,再到Paragraph函数中传入即可:
我们先准备好一个分词词库dict.txt
都会区 100 n
然后我们可以这样使用:
// if you want to customize the segmentation dict, you can use the following code
func phraseExampleWithFileDict1() {
fmt.Println("gpy phrase 1:", phrase.Paragraph(test))
// load gse dict from file
seg, _ := gse.New("zh, dict.txt")
// if you want to customize the pinyin of a word, you can use the following code
//phrase.DictAdd["都会区"] = "dū huì qū"
phrase.AddDict("都会区", "dū huì qū")
fmt.Println("gpy phrase 2:", phrase.Paragraph(test, seg))
}
自定义拼音词典
如果我们想要使用自定义的拼音词典,那么可以使用下面的方法,添加到自定义的拼音词典即可:
phrase.AddDict("都会区", "dū huì qū")
3.3.2 gpy package
gpy是项目的根目录,也是单个汉字转拼音的入口
入口函数
我们关注的pharse对gpy的使用主要集中在gpy.HanPinyin和gpy.ToFixed和这两个函数上,其中gpy.HanPinyin是将一个汉字词句转换为拼音,gpy.ToFixed是将一个拼音转换为指定格式的拼音字符串
// HanPinyin 汉字转拼音,支持多音字模式.
HanPinyin(s string, arg ...Args) [][]string
// ToFixed fixed pinyin style
ToFixed(p string, a Args) string
拼音风格
提供了Args结构体,用于传入拼音风格等参数,具体的参数如下:
// Args 配置信息
type Args struct {
Style int // 拼音风格(默认: Normal)
Heteronym bool // 是否启用多音字模式(默认:禁用)
Separator string // Slug 中使用的分隔符(默认:-)
// 处理没有拼音的字符(默认忽略没有拼音的字符)
// 函数返回的 slice 的长度为0 则表示忽略这个字符
Fallback func(r rune, a Args) []string
}
简单例子
package gpy_test
import (
"fmt"
"github.com/go-ego/gpy"
)
var hans = "中国话"
func ExamplePinyin_normal() {
a := gpy.NewArgs()
a.Style = gpy.Normal
fmt.Println("Normal:", gpy.Pinyin(hans, a))
// Output: Normal: [[zhong] [guo] [hua]]
}
func ExamplePinyin_tone() {
a := gpy.NewArgs()
a.Style = gpy.Tone
fmt.Println("Tone:", gpy.Pinyin(hans, a))
// Output: Tone: [[zhōng] [guó] [huà]]
}
安全性分析
如果需要将这个库引入到线上项目,那么我们还需要对其进行安全性分析,以保证其不包含恶意文件、代码等问题
- 后门风险
- 代码审查:作为 GitHub 上的开源项目,代码是公开的,我们可以随时检查代码是否存在恶意行为,目前我们也没有发现存在任何http/rpc请求。
- 依赖管理:该项目依赖于其他Go包(gse),尚未在gse包中发现风险。
- 外部文件风险
外部文件加载:代码中提到可以通过添加自定义词典(如 dict.txt)。如果用户加载了不受信任的外部文件,可能会引入安全风险(如恶意词典文件)
- 如果需要保持高安全性,可以考虑仅使用硬编码的方式添加词典
- 在使用外部文件时,确保文件来源可靠,避免加载不受信任的文件 - 代码执行风险
- 代码执行:该项目主要功能是汉字转拼音,没有涉及直接的代码执行或 shell 命令调用,因此代码执行风险较低。
就结论上而言,gpy库的安全性较高,可以放心引入到线上项目中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









