






一、GPU硬件架构:
GPU硬件架构中最核心的组件是图形处理核心(CUDA core),一个GPU通常包含数百到数千个CUDA core,并用以支持高度并行计算。每个CUDA core能够系列指令,实现高效并行计算。此外,GPU还包括纹理单元、光栅化器和存储控制器等功能模块。
GPU的图形(处理)流水线完成如下的工作:
- 顶点处理:这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。
- 光栅化计算:显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。
- 纹理帖图:顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射工作完成对多变形表面的帖图,
- 像素处理:这阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。
在GPU出现之前,CPU一直负责着计算机中主要的运算工作,包括多媒体的处理工作。CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。
但是如此设计的CPU在多媒体处理中的缺陷也显而易见:多媒体计算通常要求较高的运算密度、多并发线程和频繁地存储器访问,而由于X86平台中架构中暂存器数量有限,CPU并不适合处理这种类型的工作。
对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像,也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。
因此CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。
CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。而GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。
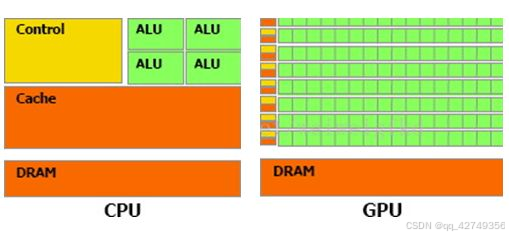
CPU、GPU架构简易示图
从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。
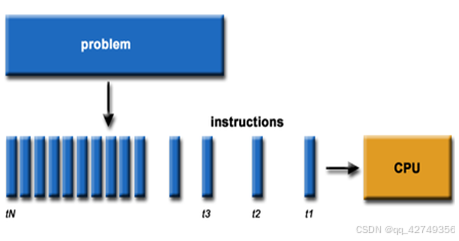
CPU串行运算示图
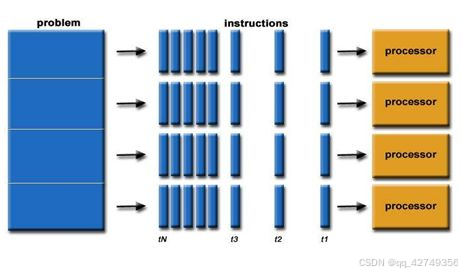
GPU并行运算示图
通过上图我们可以较为容易地理解串行运算和并行运算之间的区别。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。
而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。提高了算法的处理速度。
二、深度学习中GPU的应用
硬件选择与配置
消费级GPU
NVIDIA RTX系列、GTX系列:
消费级GPU,如NVIDIA的RTX和GTX系列,是个人研究者和小型团队在深度学习项目中常用的硬件选择。这些GPU具有较高的计算能力和较大的显存容量,同时价格相对专业级GPU更为亲民。
RTX 30系列:例如RTX 3060、RTX 3070、RTX 3080、RTX 3090。这些GPU基于Ampere架构,支持第三代Tensor Core,具有更高的性能和效率。
优点:
性价比高:相比专业级GPU,消费级GPU提供了较高的计算能力,价格更为合理。
可用性强:易于在市场上购买,安装和配置相对简单。
支持最新技术: RTX系列支持混合精度计算、实时光线追踪等新技术。
限制:
显存容量有限:相比专业级GPU,消费级GPU的显存容量较小(通常在6GB到24GB之间),可能无法处理超大规模的模型和批量大小。
散热和稳定性:在长时间高负载下,消费级GPU的散热和性能稳定性可能不如专业级GPU。
专业级GPU
NVIDIA Tesla、A100系列:
专业级GPU,如NVIDIA的Tesla和A100系列,是为数据中心和高性能计算设计的,适用于需要极高计算能力和可靠性的深度学习任务。
Tesla V100:基于Volta架构,配备640个Tensor Core,显存容量可达16GB或32GB,支持高带宽内存(HBM2)。
A100:基于Ampere架构,具有6912个CUDA核心和432个Tensor Core,显存容量为40GB或80GB HBM2e。
优势:
高计算性能:专业级GPU具有更高的计算能力和更多的核心,适合大规模深度学习训练。
大显存容量:更大的显存容量允许训练更大的模型和更大的批量大小。
可靠性和稳定性:专为持续高负载运行设计,具有更好的散热和硬件寿命。
企业级支持:提供ECC内存纠错、硬件隔离、虚拟化支持等企业级功能。
适用场景:
大型企业和研究机构:需要处理海量数据和超大规模模型。
数据中心和云计算:为客户提供高性能计算资源。
具体的深度学习中GPU配置、环境配置、运用实践不属于本文重点,在此略过
三、显卡的结构:
显卡主要包括:GPU(芯片),显存,供电,接口,散热模块。

显卡结构示图
以散热模块为例:
显卡大部分输入的电能都被转化成了热能,如今高端显卡动辄三四百瓦的功耗,如何高效处理这些热量成为了设计显卡的难题。
被动式散热:
以一款经典的图形加速卡NVIDIA Riva 128为例,早期显卡的低功耗,使其可以靠被动散热即可控制住温度。

Riva 128的被动散热
随后NVIDIA在98年发布的Riva TNT,性能与功耗同步提升,已经无法靠其被动散热保证安全温度,只能在芯片上放置一小块铝制散热片,芯片吧热量先传递给散热片,经过处理的散热片表面积远大于芯片封装,由散热片向空气传递热量自然散热效率更高。
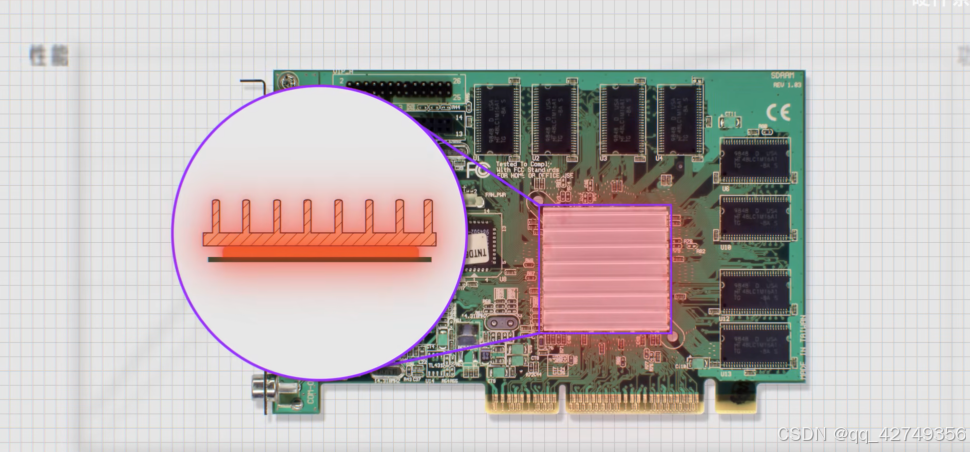
Riva TNT 加装铝片的被动散热
主动散热:
1999年,NVIDIA发布了一张划时代的显卡GeForce 256,第一次提出了GPU的概念,强大的性能带来了更大的功耗,于是,NVIDIA在这张显卡的散热片上加装了一个4cm小风扇用于加快空气对流。现在的很多低端显卡的散热仍采取这种方案,不过将散热片换成更大面积的挤铝散热片,风扇的规模也更大。

GeForce 256 主动式散热
而随着显卡性能的不断发展,更高的功耗要求更好的散热方案,随后便是如今中高端显卡上常见的热管散热方案以及更高端的水冷散热。

热管式散热
四、显卡的起源与发展:
图形化操作系统的普及让同时负责了图形运算的CPU逐渐不堪重负,而专门处理图形运算的图形加速卡(Graphics Card)的出现,将CPU解放出来,大大提升了操作系统的流畅性。

第一款2D图形加速卡 S3 86C911
接下来经过视频加速卡和3D加速卡(略)两个阶段,便来到了GPU的时代。

第一颗GPU、GeForce 256
显卡厂商双雄争霸:
1999年NVIDIA发布的GeForce256标志着GPU时代的开启,GeForce256凭借高强的性能席卷了市场,其他厂商纷纷败下阵来,不久,前3D加速卡时代的巨头3Dfx被NVIDIA收购,隐隐有一家独大之势。
但是英伟达未来二十年的对手ATI并未就此沉寂,随之便发布了Radeon系列的第一张显卡,Radeon DDR。

Radeon DDR
Radeon DDR搭载的R100芯片在性能上全面超越了GeForce256,可谓是扳回一城,让ATI得以喘息。但好景不长,NVIDIA随后便发布的性能接近的竟品GeForce2 GTS,阻拦了ATI登顶王座的脚步……

GeForce2 GTS
从此显卡市场NVIDIA和ATI双雄争霸的时代开始了。后面二十年两家各自经典型号显卡的各领风骚(略),如:Radeon 8500、GeForce4 MX440、Radeon 9700 Pro……
总体上NVIDIA保持对ATI压制,ATI时不时反超,期间2006年AMD将ATI收购,后来的NVIDIA和AMD的两家大战也不过是NVIDIA和ATI竞争的延续。
五、矿潮与矿卡
什么是矿潮:
由于虚拟货币价格的上涨,使得用于挖掘虚拟货币的硬件设备(如显卡)的需求增加,进而导致其价格飙升的现象。
什么是矿卡:
矿卡是“显卡”的一种,泛指用来“挖矿”的显卡,随着矿潮的衰退,大批量矿卡被抛售回流至市场,而这类显卡就被称为“矿卡”。

矿卡的工作环境
为什么用显卡挖矿,而不是CPU:
挖矿需要的算力,往往是通过哈希、解密等算法完成的。这类算法有一个特征,那就是复杂程度低,但强度极大,这正是GPU擅长的工作。
矿卡的价值:
可以较低的价格享受矿卡较高的性能算力。
矿卡的隐患:
矿卡在“挖矿”过程中长时间高负载运行,显卡部件因此老化、损坏,使用寿命减少,个人从市场买到矿卡后将承受矿卡突然损坏的风险。
六、显卡选购指南
你的显卡买来是干什么的
这是显卡购买的起点,也是你必须要考虑清楚的问题。因为不同的显卡,适合的场景使不一样的,它们的优势是不一样的。显卡和人一样,不是每个人都会游泳的,也不是每个会游泳的人,都能游得很快的,能够、适合、擅长是三个不同需求。你需要通过你的使用场景来确定显卡的最低标准,确保它能够完成任务。你要考虑你的预算来敲定你的选择范围内最好的选择。
怎么选显卡
可以通过预算和用途选,先定好GPU型号,后定品牌。通过预算初选,通过用途细选,显卡预算正常来说占整机预算一半左右,大体区间在30%-70%之间浮动。
生产力方面是指你干活的效率和电脑的性能正相关的领域,比如渲染、建模、深度学习。部分生产力和CPU密切一些,比如仿真,部分和显卡密切一些,比如深度学习。
生产力一般推荐选N卡,各种软件适配都很好,基本不会出错
炼丹、ai绘画,推荐选显存大的N卡,优先保证能够运行起来。视频剪辑的话,A卡、I卡、N卡都可以。达芬奇的话,推荐显存大的N卡。整体上说,涉及到生产力方面用途的,还是N卡会省心很多,A卡用来打游戏的话,性价比高。
确定好预算后,很容易能在网络上查找到此时在售新显卡,比如在视频平台上可以找到最新的新显卡购买推荐,在自己的预算区间内去选择几款适合的显卡再详细对比。如果接受二手显卡,可以现在网络论坛如图拉丁吧,显卡吧等查看价位内适合的显卡,确定好后可以在二手平台比如闲鱼进行选购,二手物品交易有风险,如果需要购买二手电子产品,请查阅相关注意事项和经验分享。
如果已经确定好几个备选显卡需要进行进一步对比,一是可以先查询显卡对应的架构,参数等信息,自己进行对比,对比方法会放在下文;二是可以去寻找网络博主关于这些显卡的性能测试,再结合对应价格,使用风险等因素综合考量。
一些显卡参数的对比方法
1、显卡芯片的架构。毋庸置疑,架构自然是越新越好。但是最新架构的显卡一定会比上一版本架构的显卡性能强吗?不一定,这里面有个等级。每个核心架构都有自己内部的等级,在没有革命性技术出现之前,最新架构的最低型号在性能上肯定不及之前架构的旗舰型号。当每个架构的全部版本型号都发布之后,新的架构优势就体现出来了,它的中端型号没准可以媲美上一版本架构的旗舰型号,可以变相的通过田忌赛马去理解。
2、核心代号。相同芯片架构的前提下,核心代号越高,性能越强劲。N卡一般的代号是G* 1**,其中,第一个*是指架构名称,费米的是F,开普勒是K,麦克斯韦是M,其实就是首字母。1**中,第一个*越高越厉害,第二个*越低越厉害。A卡比较容易,由高到低分别是Hawaii、New Zealand、Tahiti、Pitcairn、Cape Verde。
3、流处理器。流处理器越多,性能越强劲。不过要记住,不同核心架构的显卡不能比较流处理器个数,即使是同一个厂商。这又要说到每个核心架构的工作原理,在这里不多说,因为既专业又难懂。大家只要记住,只有相同核心架构的前提下才能根据流处理器的数量判断GPU的性能。
4、光栅单元和纹理单元。光栅单元和纹理单元越多,性能越强劲。理由同上。
5、GPU频率。GPU频率越高,性能越强劲。大家把GPU理解成CPU,理解成汽车的发动机,频率越高相当于转速越快。不过还是要注意,不同核心架构不要比较GPU频率。
6、显存带宽。显存带宽=显存位宽×显存频率/8。显存带宽可以看做是显存位宽和显存频率的综合指标,指的是单位时间内数据的吞吐量。有的人告诉你这个显存位宽有多高多高,但总带宽很低。打个比方,显存位宽就是一条马路的宽度,越宽表示可以并排行驶的车辆就越多;显存频率就是汽车速度,越高就表示车越快。那么带宽就是单位时间内这条街道所通过汽车的总数量。所以记住,看显卡不要只看位宽,一定要看带宽。
7、显存容量。有好多人认定只要显存大,显卡性能就强。其实这都是在DX9及之前时代留下的后遗症。当时的技术水平所能达到的性能高度确实能从显存上体现出来,但也不只是通过显存来决定性能。显存类似于电脑的内存,可以为暂时你储备和提供高质量的显示内容。打个比方,显存就是一个停车场,如果你的GPU性能不高,显存带宽不大,那么就不能为你提供更多的车进去,那么你修个大的停车场纯属浪费。当然,在其他参数差不多的情况下,还是显存越大越好。
8、显存颗粒。经历了各种厮杀和收购,目前闪存颗粒的最大的三家厂商是镁光、海力士和三星。GDDR5X目前只有镁光量产,其他两个厂商是GDDR5显存。至于之前的尔必达之类的,以后估计都少见了。在内存方面镁光颗粒是比较容易稳定超频的。
9、软件支持及优化。作为平民玩家,大家只要知道你的显卡支持DirectX***就可以了(***是版本号,从1到11,到11.1、11.2,再到最新的12)。相对于游戏优化方面,两家厂商都有自己独特的优化方式,N卡所谓的负优化,其实是新的驱动对新系列显卡的游戏性进行更好的优化,对老显卡没有改动。这样就导致了新显卡性能提升而旧显卡没有所产生的误解。A卡因为软件方面堪忧,刚出的驱动总是无法发挥新显卡的全部实力,所以每次的年度鸡血驱动只不过是将显卡硬件的全部功能发挥出来罢了。
10、SLI(N卡)和CF(A卡)。这些都是多卡互联技术。每个技术都是最多支持4个GPU互联。双芯显卡只能互联两个。这方面技术A卡可以将两个不同的卡互联,N卡只能同核心同型号互联。
11、显卡厂商。显卡厂商是将某一个显卡芯片包装成一个完整的显卡,包括PCB板、显存容量、供电系统、散热系统、显卡接口等等。现在显卡厂家有华硕、影驰、EVGA、七彩虹、技嘉、微星、蓝宝石、迪兰恒进、映泰、昂达等等。每个不同的厂商在对同一款芯片包装上有不同的风格,在显卡用料和售后服务上也有区别。
12、散热设计功耗(TDP)。这个肯定是越小越好,省电省硬件。新的架构和工艺在功耗上都会有所降低,不过高端显卡你就不要想低TDP了,目前的技术还没有发展到高性能低功耗的地步。
13、PCB板及供电系统。板材肯定是用料越多越好,保证高频率长时间使用以及供电的稳定性。供电相数越高肯定是越好,但是也要看一下电容电感等元件的可靠性。
14、散热。显卡散热风冷的有普通风扇和涡轮风扇,高端一点的就是水冷散热。水冷散热效果好,噪音低,但是价格贵,维护麻烦。风冷散热性能不及水冷,而且噪音较大,但是价格便宜,方便维护。另外普通风扇散热性能要高于涡轮散热,而且普通风扇往机箱内散热,涡轮风扇往机箱外散热,看个人喜好。还有就是热管数量、散热片、焊接技术等。另外很多高端显卡带有背板,一方面提高散热能力,另一方面也起到加固PCB板的作用。
在此贴一个“显卡天梯图”,可以对显卡的性能做参考。

显卡天梯图
七、二手电脑硬件需求人群及代表论坛
“垃圾佬”这个词就起源于图吧,全称为“图拉丁吧”。图吧是一个名为图拉丁的百度贴吧,里边的用户多为DIY爱好者。其名字起源于一款很早期的CPU核心名称(奔腾3代)——图拉丁。
图吧里边讨论的大都是二手配件,比如各种服务器CPU,服务器内存,拆机,洋垃圾硬件等,全新硬件配件在图吧关注率并不高。不少小白用户在图吧咨询配置的时候,得到的大都是一些老旧的二手配件组成的配置单,对于二手配件本身而言,性价比是其最大优势,图吧里一些有专业硬件知识的用户推荐的配置单的确还不错,不过一些奸商为了利润,会将这些二手配置当新的卖给小白,反正小白也不懂,能玩就是了。简单的说,把这些关注、推荐、购买二手洋垃圾配件的用户,都统称为垃圾佬,无所谓褒义还是贬义,只是代表了一部分用户对于DIY配件选购的立场。
图吧在同类别贴吧的排行榜上的排名仅次于显卡吧,是硬件区的第二大吧。图拉丁吧的简介是“图拉丁吧,技术天堂,DIY爱好者的聚集地”,一如简介所说,这是很多技术大佬的聚集地,大家在一起讨论硬件问题,同时帮助很多新人或者小白解决问题,像是帮助曾经的自己。
现在在这里你还能经常看到小白们的求助帖,比如电脑装好了点不亮、跳线怎么接,这配置合不合理,这预算能上xxxx吗之类的。还有大佬们的捡垃圾贴、装逼、闯电脑城贴、闯废品站贴(我们把它们统称为水贴)等。
大量二手电脑硬件,从近年较新的配件到七八年甚至十几年前的硬件现在还在二手市场广泛流通,需求人群就是以图吧“垃圾佬”为代表的爱折腾二手硬件的人群以及想要有一台电脑满足使用需求的学生党等人群。而图吧的存在意义就是提供一个平台供爱好者们讨论,同时让那些有需求但是预算较低的人能买到便宜但性能较好的二手配件。
 捡“垃圾”配件组装电脑主机
捡“垃圾”配件组装电脑主机
八、近期二手和全新显卡购买推荐
各大显卡厂商对Nvidia和AMD两家GPU的显卡产品系列和分级如下:
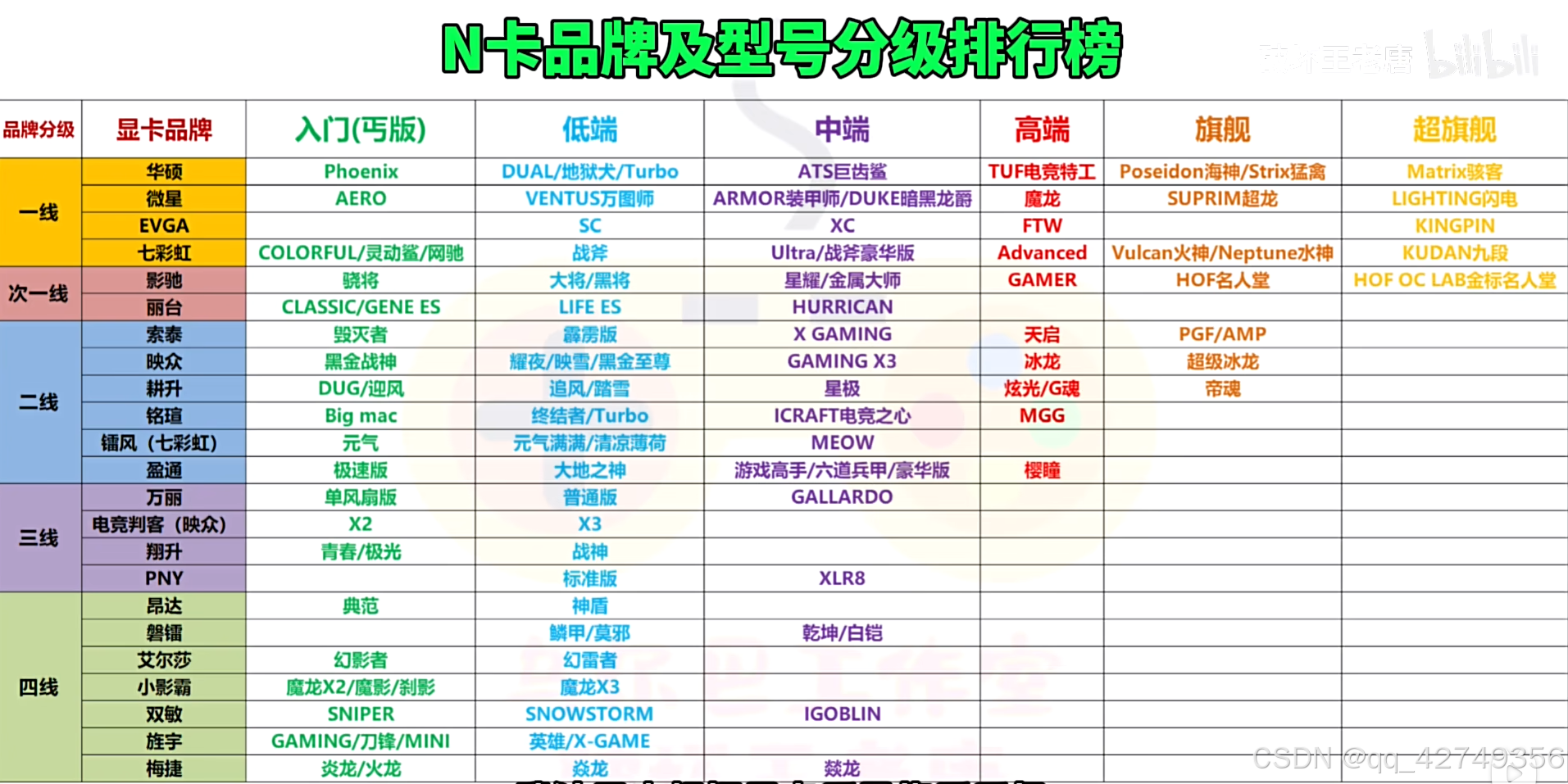
N卡各厂商显卡系列和分级
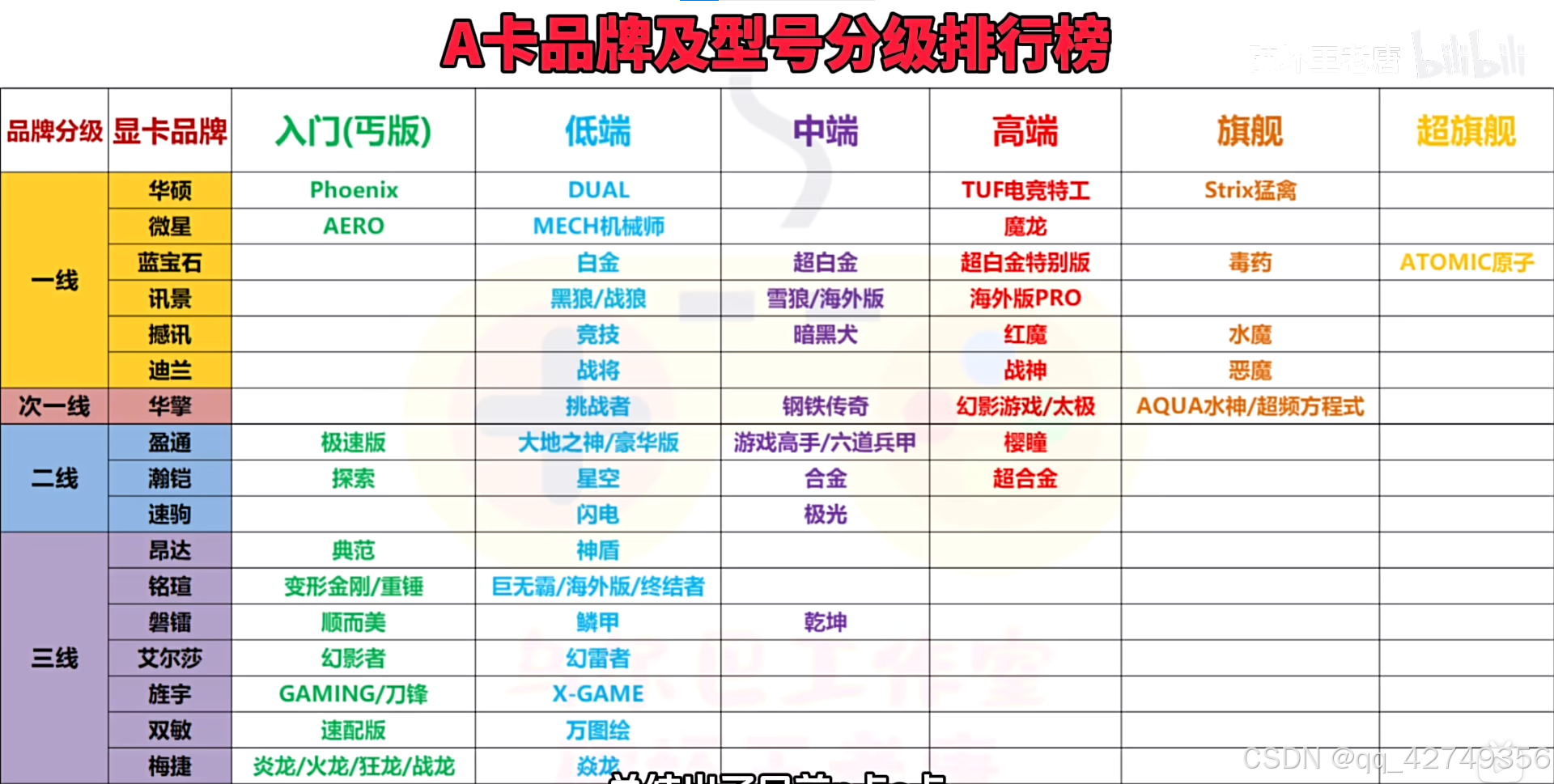
A卡各厂商显卡系列和分级
以下是近期全新及二手显卡的价格性能等信息的汇总,性能以RTX4090的性能为100%计算。
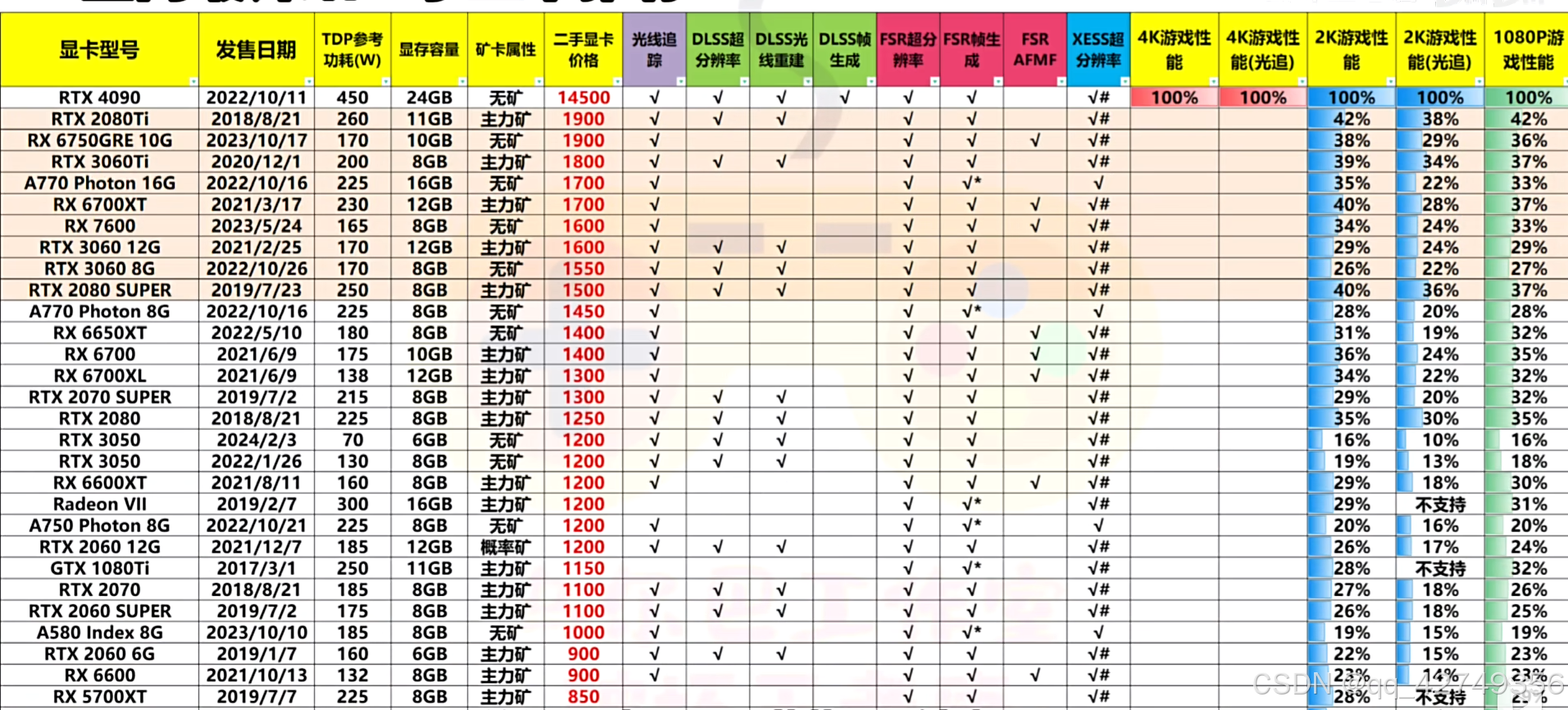
二手显卡汇总1
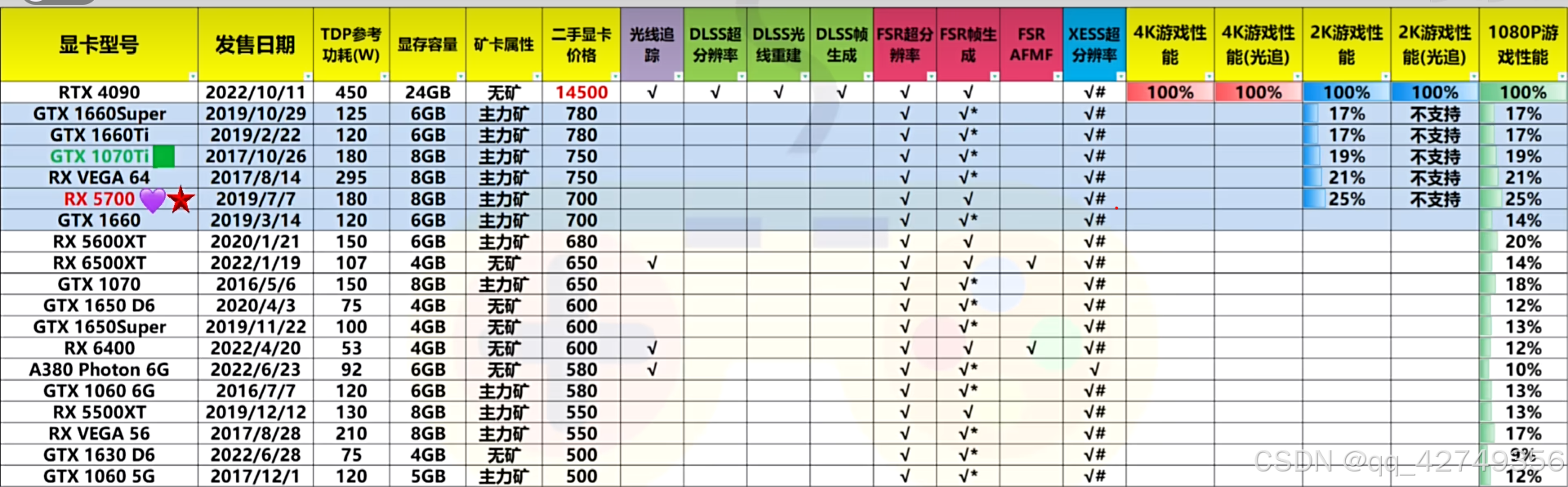
二手显卡汇总2
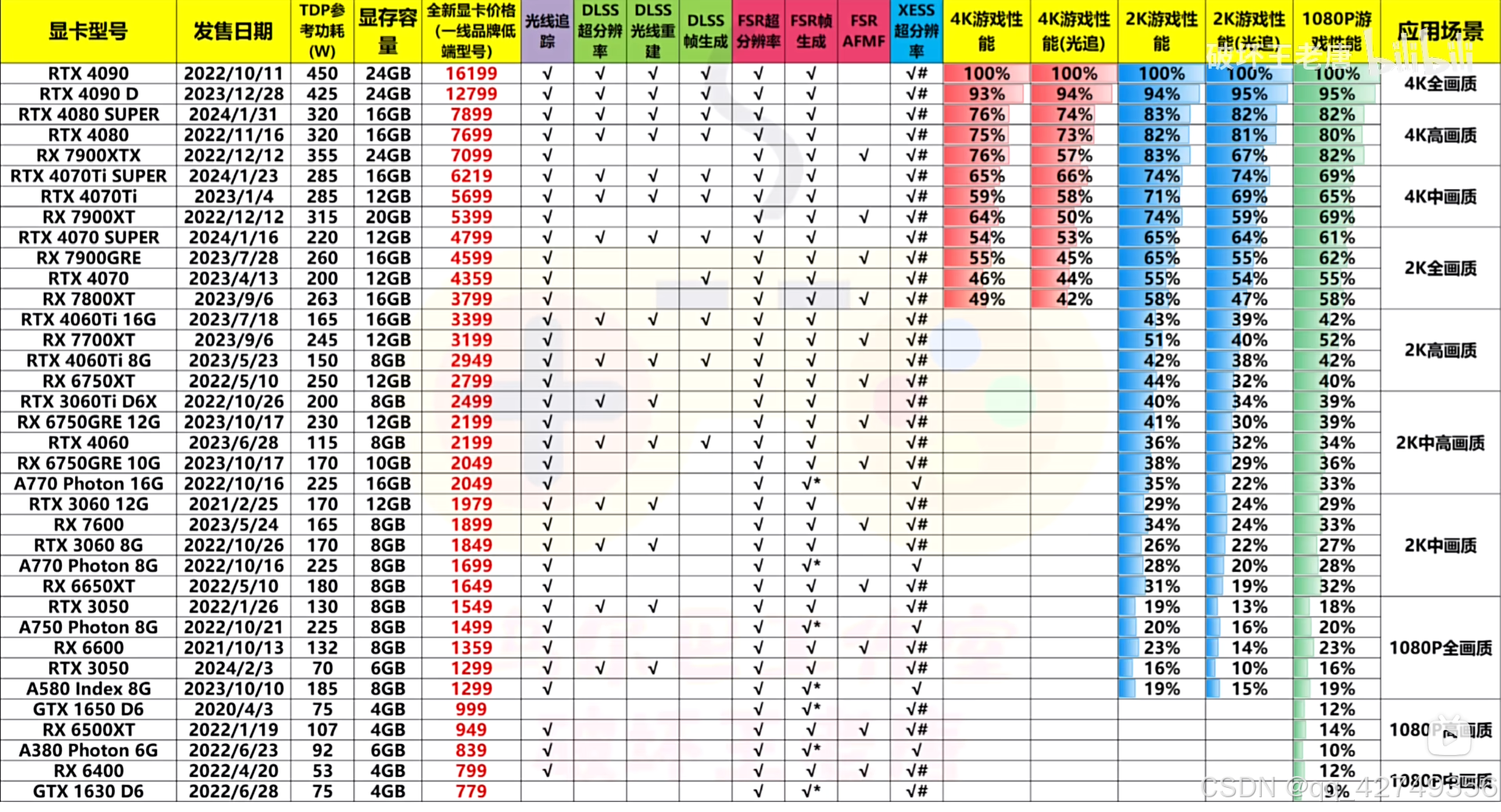
全新显卡汇总
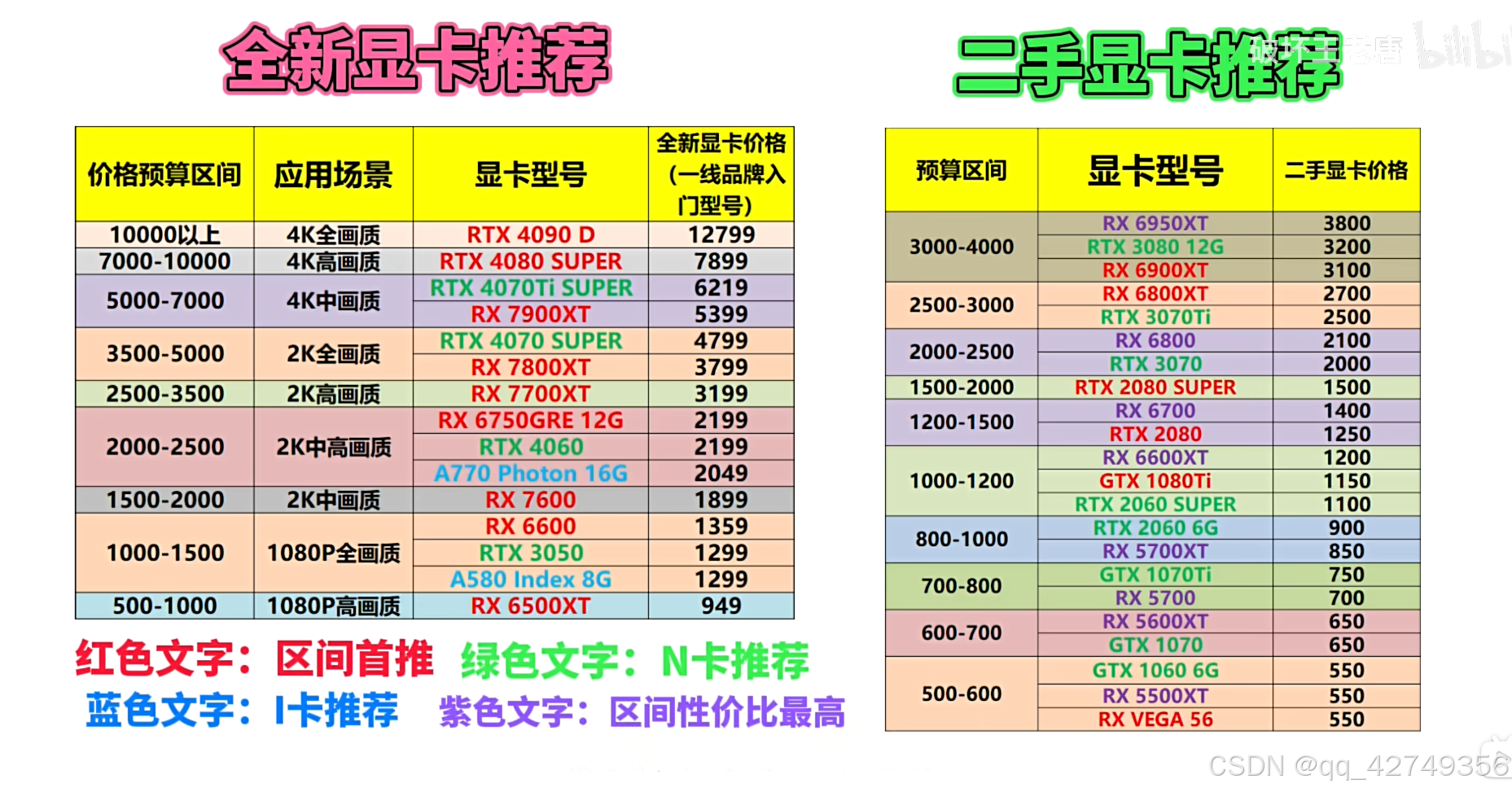
综合推荐
九、声明
本文章为学校作业,涉及内容皆从网络调研而来,本文章非盈利性质,如有侵权请联系我删除。
以下是参考内容来源:
深度学习中GPU的原理与应用方法_深度学习gpu-CSDN博客
【玩转GPU】全面解析GPU硬件技术:显卡、显存、算力和功耗管理的核心要点-腾讯云开发者社区-腾讯云
2024年全网最详细显卡推荐!2024年二手显卡推荐!英伟达/AMD/英特尔全系列全型号显卡性价比分析与推荐!2024年最新显卡推荐!电脑装机配置推荐_哔哩哔哩_bilibili


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









