








一.数据类型
1.数字类型
(1)在Python中浮点类型只有单精度float
a=10/2
#5.0,除法运算,如果两个运算数都是整数,结果将为浮点数。
a=10//2
# //运算符执行整除,它会返回商的整数部分。(2)复数类型(其实就是数学中开平方的那个东西)
complex1 = 22 + 12j
print('complex1 =', complex1) #complex1 = (22+12j)
print('复数 complex1 中的实部为:', complex1.real) #复数 complex1 中的实部为: 22.0
print('复数 complex1 中的虚部为:', complex1.imag) #复数 complex1 中的虚部为: 12.0
complex_demo1 = complex(22) # 将数字 22 转换为复数
print('complex_demo1 =', complex_demo1) #complex_demo2 = (22+0j)
complex_demo2 = complex('33-22j') #将字符串转换为复数,字符串在+或-的周围(前后)必须不能有空格。
print('complex_demo2 =', complex_demo2) #complex_demo2 = (33-22j)
(3)进制转换
#int()函数可以将一个带有数字的字符串转换为整型。比如:
age = int('18');
#int()函数可以将其他进制的数转换为十进制数。例如,将二进制数1101转换为十进制数:
num = int('1101',2);
print(num)#输出:13
#其中,第二个参数2表示要将字符串'1101'视为二进制数进行转换。同样地,将十六进制数0x1A转换为十进制数:
num = int('1A',16);
print(num)#输出:26
#其中,第二个参数16表示要将字符串'1A'视为十六进制数进行转换。
print(bin(num));
#bin()函数用来将数字(不论是八进制,十进制,十六进制)转换为二进制数。
print(oct(num));
#oct()函数用来将数字(不论是二进制,十进制,十六进制)转换为八进制数。
print(hex(num));
#hex()函数用来将数字(不论是二进制,八进制,十进制)转换为十六进制数。2.判断是什么类型的数据
type(a1)
print('complex1 的类型为:', type(complex1))类型转换
c1 = 'a'
c2 = 'b'
if ord(c1) < ord(c2):
print(c1, '小于', c2)
else:
print(c1, '大于等于', c2)
#ord函数是一个内置函数,用于返回指定字符的Unicode码点(整数表示)。严密意思上说,它是与chr函数完全相反计算的函数。平时运用中,也可以将unichr函数认为是ord函数的相反函数。
c3=chr(ord(c1))
print(c3)
#chr函数是Python内置的函数之一,用于将Unicode码转换为对应的字符。它接受一个整数参数,并返回一个字符串。chr函数的用法如下:chr(i),其中,i是一个介于0-1,114,111的整数(即Unicode码的范围)。
#除此之外还有str函数、float函数、int函数3.string类型
python中单引号和双引号没有区别,都表示字符串
下面是常用函数的表
| 函数 | 描述 |
|---|---|
| title() | 返回将原字符串中单词首字母大写的新字符串 |
| istitle | 判断字符串中的单词首字母是否大写 |
| capitalize() | 返回将整个字符串的首字母大写的新字符串 |
| lower()、upper() | 返回字符串的小写、大写后的新字符串 |
| swapcase() | 返回字符串的大小写互换后的新字符串 |
| islower()、isupper() | 判断字符串是否全部为小写、大写 |
| strip()、lstrip()、rstrip() | 删除字符串首尾、左部或右部的空白,空白包括空格、制表符、换行符等 |
| ljust()、rjust()、center() | 打印指定数目的字符,若字符串本身长度不足,则在其左部、右部或者两端用指定的字符补齐 |
| startswith()、endswith() | 判断原字符串是否以指定的字符串开始或结束 |
| isnumeric()、isdigit()、isdecimal() | 判断字符串是否为数字、整数、十进制数字 |
| find()、rfind() | 在字符串中查找指定字符串第一次出现的位置,方向分别为从左和从右 |
| split() | 按照指定的字符将字符串分割成词,并返回列表 |
| splitlines() | 按照换行符将文本分割成行 |
| count() | 统计指定字符串在整个字符串中出现的次数 |
| format() | 用指定的参数格式化原字符串中的占位符 |
string常用函数了解一下,具体用到可以百度。下面是具体的用法,format的用法在后面的输入输出中有介绍。
a = 'Hello','LXX' #这里的a是一个元组,后面会讲到
b = 'Hello''LX'
c,d= 'Hello','LXX'
print(a)#('Hello', 'LXX')
print(b)#HelloLXX
print(c,d)#Hello LXX
print(c+d)#输出结合:HelloLXX
#字符串切片,从字符串中提取子串,可指定两个索引:第一个字符的索引;要提取的最后一个字符的索引加 1
print(a[0:-1]) #('Hello',)
print(b[0:-2]) #Hello
print(b[0:-3]) #Hell
print(c[0:])#Hello
# 省略字符串的终止索引,Python 会假设你要提取到字符串末尾。
print('a' in b) #False,判断b中是否包含字符'a'
print(c*2,d*2)#各输出两次,HelloHello LXXLXX
print('Hello,\nLXX')#带有回车
print(r'Hello,\nLXX')#加了r后转义字符失效
print(b[0],b[-1]) #负数索引是从右向左,-i表示倒数第i个,H X
#Python字串符是不可以被改变的,如果向一个指定索引赋值,将会错误
print(ord('1')) #返回对应字符的ASCll数值,或者Unicode值
num=1
snum=str(num) #str函数是将数值类型转换成string类型
print(type(snum))#<class 'str'>
str ='aa'
z=str.join('123')#join函数表示将()中的元素之间用.前面的str连接起来,形成一个新的字符串
print(z) #1aa2aa3
x='1+2+3'
x=x.split('+')
print(x)#['1', '2', '3']
y = '/'.join(x) #split方法的逆方法,用来在队列中添加元素,必须是字符串
print(y) #1/2/3
str1 = "xxioddmnjkppuy"
print(str1.find('dd',1,12)) #返回字符串所在位置的最左段索引,1和12表示始末位置
#判断是否只包含数字,-1,1.1在这个函数中都为False,只有正整数可以
str1.isdigit()
#isnumeric()比isdigit()多识别一个汉字数字
#修改字符串的方法
#1.切片后赋值相加
#2.转换成列表修改好后,再转换回去
s='abcdef'
s1=list(s)#将原字符串转换为列表
s1[4]='E'
s1[5]='F'
s=''.join(s1) #join函数只能字符串或者字符串列表起作用,如果列表中包含非字符串类型的元素,需要先将其转换为字符串,例如使用str()函数。
print(s)#abcdEF
#用空串将列表中的所有字符重新连接为字符串,新字符串
#3.使用字符串的replace函数
s='abcdef'
s=s.replace('a','A')
s=s.replace('bcd','123')
print(s)#A123ef
a='asdd'
a.ljust(10,"$")#前一个字符代表填充后字符串的总长度
print(a.ljust(10,"$"))#asdd$$$$$$
#用0填充,类似 "a.zfill(9,"0")
print(a.zfill(9))#00000asdd
#在左右两边都假设空格
print(a.center(50)) # asdd
#去重左右两边的空格
print(a.strip())#asdd
#去重左右两边的字符
print(a.strip("sdd"))#a
a.splitlines()#识别空行进行分割
a.split("\n")#同上分割空行4.列表:List类型
在Python中,复合数据类型分别有三种:Tuple(元组)、Set(集合)与List(列表)
Python中没有数组的数据结构,但列表很像数组
下面是List的常用函数(还有max、min、list.index函数,在代码最后面有补充)
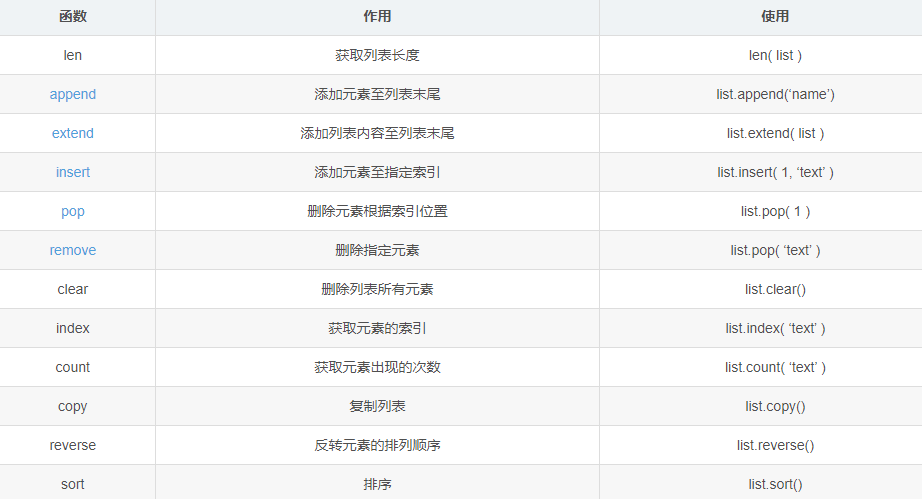
下面 是List的用法
s1 ='asas'
#将字符串或者元组转换为列表
name=list(s1)
#分片赋值,可以使用与原序列不等长的序列将分片替换
name[1:]=list(s1)
print(name)#['a', 'a', 's', 'a', 's']
#创建两个列表
a = ['a','b','c',3]
b = [4,'love','l','l',',','never']
print(a,b)#['a', 'b', 'c', 3] [4, 'love', 'to', 'l', ',', 'never']
c=a+b#c赋值后不受a、b的影响
print(c)#['a', 'b', 'c', 3, 4, 'love', 'l', 'l', ',', 'never']
print(b[1:5:2]) #['love', 'l']
#参数1是起始的索引,默认为0;参数2是结尾的索引,默认是列表最后一位;参数3是步长,默认是1,当步长是负值时返回原序列的倒序,如[::-1]返回原序列倒序。
print(b[1:6:2])#['love', 'l', 'never']
print(b[1::2])#['love', 'l', 'never']
print(b[1:5],b[2])#['love', 'l', 'l', ','] l
#添加元素:在列表末尾添加新数值
a.append(347)
#插入元素:把元素插入到指定位置
a.insert(2,2)
print(a)#['a', 'b', 2, 'c', 3, 347]
#2个参数相等,则是从参数1中插入数据,参数不等,则是覆盖
a[2:2]=['w22','e22']
print(a)#['a', 'b', 'w22', 'e22', 2, 'c', 3, 347]
#元素替换,直接赋值给对应的索引位置
a[0:3]='A','B','C'
print(a) #['A', 'B', 'C', 'e22', 2, 'c', 3, 347]
#插入一个空序列,a[1]到a[2-1]都是空的
a[1:2]=[]
print(a) #['A', 'C', 'e22', 2, 'c', 3, 347]
#给a[2]一个空数列,移除a列表中指定索引数据
a[2]=[]
print(a)#['A', 'C', [], 2, 'c', 3, 347]
#len()函数用于统计列表数据个数,
print('a列表数据个数:',len(a)) #a列表数据个数: 7
#清空列表
a.clear()
#扩展列表,追加多个值,与append的区别,如果append用列表追加,则列表会作为一个元素添加
a.extend(b)
# a.extend((4,5,6)) # 列表末尾添加元祖
# 1.append() 添加的是元素「引用」,而 extend() 添加的是元素的「值」
# 2.append() 可以添加「任意类型」元素,而 extend() 只能添加「序列」
#pop,移除,默认最后一个元素。可以加序号index指定移除
a.pop()
a.pop(0)
#x= list1.pop(0),x是返回的被删除的值
print(a)#['love', 'l', 'l', ',']
#返回某个值在该列表出现的次数
print(a.count('l'))
#找出第一个匹配该值的索引index,没有找到会报错
print(a.index('l'))
#找到指定元素删除只删除第一个出现的元素,,没有找到会报错
a.remove('l')
#remove可以删除【对象类型】元素,包括列表类型和数组类型
print(a)#['love', 'l', ',']
#删除元素
del a[1:2]#如果是del a[1:1] 则一个也删不掉
print(a)#['love', ',']
#反向列表中元素
a.reverse()
print(a)#[',', 'love']
cat = ['fat', 'black', 'loud'] #多重赋值
c1, c2, c3 = cat #ci分别对应cat中的第i个
print(c1)
#生成一个嵌入式列表
e1=[a,cat]
#append函数添加的是地址,当被添加的列表发生变化时,添加后的列表也会同步变化
e2=a.append(cat)
print(e1)#[['love', 'never', ['fat', 'black', 'loud']], ['fat', 'black', 'loud']]
cat.append('a')
print(e1)#[['love', 'never', ['fat', 'black', 'loud']], ['fat', 'black', 'loud', 'a']]
#=是直接赋值,2个列表是等价的,修改其中任何一个列表都会影响到另一个列表。
e3=e1
#采用切片就没事儿,返回包含原列表所有元素的新列表,新的列表占用新的内存地址。切片是取操作,不改变原值
eee = e1[ : ]
e3.append('0')
eee.append('1')
print(e3,eee)#e3和e1的内容一样,eee和e1的内容不一样
#浅拷贝,只拷贝第一层, 浅拷贝后e1的变动可能影响e4的值(第二层改变)
e4=e1.copy()
import copy as cp
#深拷贝,拷贝所有内容,深拷贝后e1的任何变动不会影响e5
e5=cp.deepcopy(e1)
e1[2]='1'
e1[0][0]=10
#e1的第一层改变,e4不变,e1的第二层改变,e4改变
print(e4)#[[10, 'love', ['fat', 'black', 'loud', 'a']], ['fat', 'black', 'loud', 'a'], '0']
print(e5)#[['never', 'love', ['fat', 'black', 'loud', 'a']], ['fat', 'black', 'loud', 'a'], '0']
# insert同样存在 「列表同步」问题,改为 「深拷贝」即可
a = [1,2,3]
# 添加列表a,换成深拷贝就不会出问题cp.deepcopy(a)
e2=e1[:]
e1.insert(2, a)
e2.insert(2,cp.deepcopy(a))
a.append(4) # 列表a发生变化
print(e1)#列表e1同步发生变化
print(e2)#列表e2不变
#sort排序只能对纯数字或者纯字符串的列表排序,整型和浮点型可以相互转换就可以排序,当元素之间的类型不能够互相转换时,例如整数和字符串就会报错
#sort排序,2个参数,key,reverse
# key参数指的是为列表的元素一一标记权值,并按照元素所对应的权值来排序元素。key=函数名,该函数的返回值作为元素的权值大小。
# reverse 默认升序,=True是降序
a = [(4, 2), (3, 2), (4, 4), (2, 4)]
a.sort(key=len,reverse=True) #根据字符串长度排序
a.sort(key=lambda i:i[1]) #利用lambda表达式,对于元素全是字符串的列表,按照元素的第2个「字符」排序。
def cmp(a, b): # 自定义比较函数
if(a[0]==b[0]):
return b[1]-a[1]
return a[0]-b[0]
#当结果为小于时,返回一个负数;当结果为相等时,返回0;当结果为大于时,返回一个正数。根据返回数的正负,确定2者之间的顺序
A = [(4, 4), (4, 3), (2, 4), (4, 5), (3, 3)]
import functools
A.sort(key=functools.cmp_to_key(cmp)) #Python3的functools包提供了cmp_to_key函数,可以将用户自定义的cmp函数转化为可以被可选参数key接收的对象。
#A.sort(key=functools.cmp_to_key(lambda x,y: x[0]-y[0]))
print(A)#[(2, 4), (3, 3), (4, 5), (4, 4), (4, 3)]
a = [0 for x in range(0, 10)] #v想定义10长度的a,初始值全为0
print(a)#[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
a=[[0 for x in range(4)] for y in range(4)]#这里定义了4*4初始为0的二维数组。
print(a)#[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
list = [10, 5, 20, 8, 15]
#常用的遍历list的方法
# 方法1
for i in list:
print("序号:%s 值:%s"%(list.index(i)+1,i))
#方法2
for i in range(len(list)):
print("序号:%s 值:%s"%(i+1,list[i]))
list = [10, 5, 20, 8, 15]
max_value = max(list)
min_value = min(list)
max_index = list.index(max_value)
print("最大值:", max_value)
print("最大值位置:", max_index)
print("最小值:", max_value)
print(max(a),min(a)) #返回列表元素最大值never,返回列表元素最小值love列表list的推导式,这位大哥写的很好:Python——列表(list)推导式_python列表推导式-CSDN博客
5.元组:Tuple类型
元组的语法与列表差不多,不同之处就是元组使用小括号(),且括号中元素不能被改变,创建元组可以不需要括号;而列表是使用中括号[]。
元组是包含0个或多个元素的不可变序列类型。元组生成后是固定的,其中任意元素都不能被替换或者删除。
元组与列表的区别在于元组中的元素不能被修改。
tup1 = (123,'xyz','zara','abc')
list1 = list(tup1) #元组转化为list
print(list1)
list1.append(999)
tup1 = tuple(list1)#list转化为元组
print(tup1)
tup1 = ('physics','chemistry',1997,2000) #元组中包含不同类型的数据
tup2 = "a","b","c","d" #声明元组的括号可以省略
tup3 = (50,) #元组只有一个元素时,逗号不可省略
tup4 = ((1,2,3),(4,5),(6,7),9)
print(1997 in tup1)
c = tup1+tup2 #相互结合
print(c)
print(tup1[1]) #使用索引访问元组中元素
print(tup1.count(2000))
print(tup1.index(2000))#检索元组中元素的位置,检索不存在报异常6.集合:Set
Set集合数据类型是一种无序不重复元素的序列。在Python中,我们可以使用大括号{}或内置函数Set()来创建一个集合(创建一个空集合必须用Set()函数,不可用{},因为{}实质是创建一个空的字典
a = {'a','bb','c','d','a'}#创建集合a
print(a) #{'bb', 'c', 'd', 'a'}
#因为集合是无序不重复元素序列,所以不会输出多出的a,但是每次输出结果中的顺序不同
b = set('sdgsdggfdgdasrfdsf')#运用Set()函数创建集合b
print(b) #{'s', 'a', 'f', 'd', 'g', 'r'}
print('a' in a) #True,判断元素是否在集合内
# Set也支持数学运算符运算,不同运算符使用范围也不同
a = set('sdfygsyfysdgfsdtfsyhf')
b = set('hgdhsdfsghdvhgsfs')
print(a - b) #减号(-)的作用就是输出a集合中b集合内没有的元素,{'t', 'y'}
print(a | b) #竖线符号(|)主要输出集合a或b中包含的元素,{'d', 't', 'h', 'v', 'g', 's', 'y', 'f'}
print(a & b) #逻辑符号(&)就是要输出集合a和b中共同包含的元素,{'d', 'h', 'g', 's', 'f'}
print(a ^ b) #乘方(^)主要输出不同时包含于a和b的元素,{'v', 't', 'y'}
a=set('abc')
a.add('qx') #add是添加或覆盖整个字符串
a.update('zx') #update是添加或覆盖散的字符
print(a) #{'z', 'qx', 'b', 'a', 'c', 'x'}
a.remove('a') #删除某些元素可以使用关键字remove,discard
a.discard('b')
print(a) #{'z', 'qx', 'c', 'x'}
a.pop() #使用pop会随机删除某些元素
print(a) #{'qx', 'c', 'x'}
a.clear() #清空=a=set()
print(a) #输出结果:set()
list1=list(a) #转换成list
print(list1)
set1=set(list1) #转换成set
print(set1)7.字典:dictionary
创建一个空字典需要用大括号{},在字典中每一个值对用冒号,且每个值需要逗号(,)分隔。
#要输出的值字典内没有,那么输出将会显示异常。
a = {'a':'HTML/J',1:'347','c':'hjg'}#创建一个字典
a['c']='Perl' #修改字典中的数据
print(a['a'],a['c']) #HTML/J Perl
# 清除字典数据也很简单,与集合一样,使用clear()函数,然而删除的话就需要用到del语句
print(a) #输出整个字典:{'a': 'HTML/J', 1: '347', 'c': 'Perl'}
a.clear() #清除字典所有数据
print(a) #{}
del a #删除字典,删除后print(a)会异常
a = {'a':'HTML/J',1:'347','c':'hjg'}#创建一个字典
l1=list(a.keys()) #把key和value转换成列表输出
l2=list(a.values())
print(l1) #['a', 1, 'c']
print(l2) #['HTML/J', '347', 'hjg']
print(list(a.items())) #[('a', 'HTML/J'), (1, '347'), ('c', 'hjg')]
#把键值对转换成列表输出二.基本语法
1.输入输出
# 单个输入
# a1 = input() #无参数 默认返回字符串
# a2 = input("提示性输入语句:")
# ia= int(input()) #根据给定的类型输入,返回值类型int,输入别的类型会报错
# fa= float(input()) #根据给定的类型输入,返回值类型float
# ea = eval(input()) #eval()函数用来执行一个字符串表达式,并返回表达式的值。也可以用于返回数据本身的类型
# print(a1,a2,ia,fa,ea)
#多个输入
# a,b,c= input().split(" ") # 输入字符串(默认返回类型)a 和 b 以(空格)分隔
# print(a,b,c)
# a,b,c = eval(input()) #输入三个值(任何类型)中间由逗号分隔,int(input())不行会报错
# print(a,b,c)
# a, b, c = map(eval, input().split(" ")) #输入三个值(任何类型)中间(空格)分隔
# print(a,b,c)
# a, b, c = map(int, input().split(" ")) #输入三个值(int)中间(空格)分隔
# print(a,b,c)
#一行输入
# lst = list(map(int, input().split(" "))) # 输入一行值(int)由(空格)分隔 存入列表,最后一个数后面多一个空格都不行
# print(lst)
format()格式化输出,把传统的%替换为{}来实现格式化输出。
格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 % 。format 函数可以接受不限个参数,位置可以不按顺序。
#输出
lst=[1,2,3]
for i in lst:
print(i, end=" ")
#在print中,默认的输出方式:换行进行输出,添加了end=’ ’后,结果会在一行中输出。
#end参数用于指定打印结束后的字符,即在打印完所有值后,输出的最后一个字符。默认值为换行符 \n
#sep参数用来设定print中的参数在输出时用什么来连接,默认使用空格来分隔
#用于指定分隔符,即在打印多个值时,它们之间的分隔符。默认值为一个空格。
print("hello", "world")
print("hello", "world", sep=" ") # 这里把输出使用空格进行连接
# 1.
print("{}is {}".format('jgdabc','蒋光道'))#默认格式化输出,{}里面不带参数
# 通过索引的方式去匹配参数,可以调换填入数据的前后顺序
print("{1} is {0} is {1}".format("jgdabc",'蒋光道'))
#{}的个数大于后面format中的个数 或者 需要调换顺序时, 需要指定参数
# 通过参数名来匹配参数
print("{a} {b} {c}".format(a="hello",b="world",c="everyone"))
# jgdabcis 蒋光道
# 蒋光道 is jgdabc is 蒋光道
# hello world everyone
# 可以通过索引,参数名来混搭进行匹配
s = "My name is {}, i am {age} year old, She name is {}".format('Liming', 'Lily', age=10)
print(s) # My name is Liming, i am 10 year old, She name is Lily
# 需要注意的是,命名参数必须写道最后,否则会报错!索引和默认格式化不可以混合使用
# 2.
s="好好学习"
print("{:<10s} is {:>10s}".format("hello","world"))# 字符串中加s和不加s是一样的
print("{:25}".format(s))#输出25个字符的宽度,默认左对齐
print("{:>25}".format(s))#输出25个字符的宽度,右对齐
print("{:^25}".format(s))#输出25个字符的宽度,居中对齐
print("{:*^25}".format(s))#输出25个字符的宽度,居中对齐,用*填充,也可以用别的填充,如果数字小于字符串的长度,则不进行填充操作。
print("{:^25.3}".format(s))#.3表示限制字符串的长度为3位
print("{:2}World".format('Hello'))#不足的时候,会用空格补充,多了就会自动后移
# hello is world
# 好好学习
# 好好学习
# 好好学习
# **********好好学习***********
# 好好学
# HelloWorld
a=1234.12345678
print("{:.6}".format(a))#.6表示限制数字的长度为6位
print("{:+^25,}".format(a))#后面加了个逗号,给数字加千位符,是数字金额中每隔3位加一个逗号
print("{0} is {0:15}".format(a)) # {}的数量和format中的数量不一致时需要指定,否则会报错
print("{:f} and {:10.3f}".format(a,a))
#f表示小数点保存后6位 .2f表示小数点保存后2位,10表示输出10个字符的宽度(包括小数点),左对齐
# 1234.12
# +++++1,234.12345678++++++
# 1234.12345678 is 1234.12345678
# 1234.123457 and 1234.123
# 3.
# 通过对象的属性
class Names():
name1='Kevin'
name2='Tom'
print( 'hello {names.name1} i am {names.name2}'.format(names=Names))
# hello Kevin i am Tom
# 支持对参数部分引用.可以通过索引对参数的部分进行取值.
s = "The word is {s}, {s[0]} isinitials".format(s='world')
print(s)# The word is world, w is initials
# 在format格式化时,可使用* 或者 ** 进行对list、tuple拆分。
foods = ['fish', 'beef', 'fruit']
s = 'i like eat {} and {} and {}'.format(*foods)
print(s)# i like eat fish and beef and fruit
s = 'i like eat {2} and {0} and {1}'.format(*foods)
my_list = ['脚本之家', 'www.jb51.net']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的,和上面的效果一样
print(s)# i like eat fruit and fish and beef
dict_temp = {'name': 'Lily', 'age': 18}
# 字典需要用 ** 进行拆分
s = 'My name is {name}, i am {age} years old'.format(**dict_temp)
print(s) # My name is Lily, i am 18 years old
#4.
# 以f开头表示在字符串中支持大括号内的python表达式 此用法3.6之后支持
name = "jgdabc"
age = 22.1234
print(f'my name is {name}') #my name is jgdabc
print(f"my age is {age:.2f}")#my age is 22.12
#5.
#在format 中使用{{来进行转义的,而不是\
print('数字{{{1}{2}}}和{0}'.format("12",4,'5'))#数字{45}和12
#6.
print("{0},{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(16))
print("{0:e},{0:E},{0:f},{0:%}".format(425))
print("{0:#x},{0:#o},{0:#b}".format(425))
#在前面加“#”,则带进制前缀:0x1a9,0o651,0b110101001
# b:二进制,c:Unicode,d:十进制,o:八进制,x:十六进制,e:指数形式,%:百分数形式
print("{0} ,{0:.3g}, {0:g}".format(12345678))#12345678 ,1.23e+07, 1.23457e+07
print("{0} ,{0:.3g}, {0:g}".format(10000000))#10000000 ,1e+07, 1e+07
print("{0} ,{0:.3g}, {0:g}".format(100))#100 ,100, 100
# g格式,在保证六位有效数字的前提下,使用小数方式,否则使用科学计数法
# .3g保留3位有效数字,使用长度不超过六位用小数或超过六位用科学计数法
#7.
# round(a1,a2),参数a1是数字表达式,a2是从小数点到最后四舍五入的位数
# round函数只有一个参数时,返回最靠近的整数,类似于四舍五入,当指定取舍的小数点位数的时候,一般情况也是使用四舍五入的规则,但是碰到.5的情况时,如果要取舍的位数前的小数是奇数,则直接舍弃,如果是偶数则向上取舍。
# 注:“.5”这个是一个“坑”,且python2和python3出来的接口有时候是不一样的,尽量避免使用round()函数吧
print(round(1.1125)) # 四舍五入,不指定位数,取整1
print(round(1.1135 ,3)) # 取3位小数,由于3为奇数,则向下“舍”1.113
print(round(1.1125 ,3) ) # 取3位小数,由于2为偶数,则向上“入”1.113
print(round(1.5)) # 无法理解,查阅一些资料是说python会对数据进行截断,没有深究2
print(round(2.5)) # 无法理解2
print(round(1.675 ,2)) # 无法理解1.68
print(round(2.675 ,2)) # 无法理解2.67
#所以还是不要用round函数吧
#8.
# 浮点型输出
print('%.2f'% 3.1415926) # π is 3.14
# 字符串输出
print('%s' % 'he') #he
print('%10s' % 'he')# 右对齐,取20位,不够则补位
print('%-10s' % 'he')# 左对齐,取20位,不够则补位
print('%.2s' % 'he')# 取2位
print('%10.2s' % 'he')# 右对齐,取2位
print('{:+f}; {:+f}'.format(3.14, -3.14) ) # 总是显示符号
# '+3.140000; -3.140000'
print('{: f}; {: f}'.format(3.14, -3.14) ) # 若是+数,则在前面留空格
# ' 3.140000; -3.140000'
print('{:-f}; {:-f}'.format(3.14, -3.14) ) # -数时显示-,与'{:f}; {:f}'一致
# '3.140000; -3.140000'
#9.
import datetime
d = datetime.datetime(2010, 7, 4, 12, 15, 58)
print('{:%Y-%m-%d %H:%M:%S}'.format(d))
# '2010-07-04 12:15:58'2.判断语句
a=1
if(a==1 and a==2):
print("两个条件均符合")
elif(a==1 or a==2):
print("至少有一个条件符合")
else:
print("都不符合")3.循环语句:for循环用到range函数
在Python中,循环语句有for和while
for语句其实是编程语言中针对可迭代对象的语句,可迭代对象(Iteratable Object) 是能够一次返回其中一个成员的对象,比如我们常用的字符串、列表、元组、集合、字典等等之类的对象都属于可迭代对象,获取到这些对象我们就可以用for循环来进行操作。
import collections.abc as co
import sys
b = ["小明", "小红", "小张", "小王", [19, 20, 18, 23]]
def IsIt(x):
return isinstance(x, co.Iterable) # 判断对象是否是可迭代对象,也可以是别的list等等
print(IsIt(b))
# 列表的for循环,类似可参考
def qiantao(x): # 定义一个函数
for each in x: # 遍历每个原始列表中的每个元素
if isinstance(each, list): # 判断每个元素是否是列表:isintance
qiantao(each) # 如果是列表,递归执行函数qiantao()
else:
print(each, end=' ') # 如果不是列表,就直接打印该元素
qiantao(b) # 调用函数,传入列表b
# range函数的for循环
# range函数是 Python 内置函数,用于生成一系列连续整数,多用于 for 循环中。
# range(start,stop,step);[start...stop-1];start默认为0;stop必须写;步长step可正可负,默认是1,不能为0,步长设为2,从0开始就是偶数
print('\n', list(range(10))) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],range(10) 生成的是可迭代对象
# 循环语句和else搭配使用
sum = 0
for i in range(10):
#for i in reversed(range(10)): 将序列反转输出
sum += 10
else:
print(sum)
# for循环执行完成后去执行else语句,如果for循环遇到break,则直接跳出循环,不执行else语句。
for i in range(10):
if (i == 3):
break
else:
print("不执行else")
# while语句的用法
while (1):
while True:
sum = 10
while sum < 10:
sum += 1
else: #while语句结束后,执行else中的内容
print(sum)
sys.exit()#直接退出程序
# 可以使用 CTRL+C 来退出当前的无限循环。4.python中的函数段,def
def Loveyou1314(s1):
print('LXX'+s1)
Loveyou1314('我喜欢你,不知你可不可以做我女朋友')5. lambda匿名函数
(1)lambda是匿名函数,但是可以命名,名字在等号左边
<函数名>=lambda<参数>:<表达式>
等价于 def <函数名>(<参数>):
<函数体>
return <返回值>(2)lambda只能包含一个表达式,不能包含复合语句
f = lambda x, y, z: x+y+z #f是表达式的名字
print(f(1,2,3)) #像函数一样调用(3)lambda的主体是一个单独的表达式,不是语句也不是一个代码块
x = (lambda a = "fee", b = "2", c = "3" : a + b + c)
print(x("acb")) #acb236.python第三方库下载
安装在python安装目录下的Lib\site-packages文件夹下
由于 Python 服务器在国外,因此使用 pip 安装第三方模块或者库的时候,下载速度特别慢,经常出现如下报错:$ socket.timeout: The read operation timed out
为提升下载速度,可以使用国内镜像下载,常用的国内镜像有:
豆瓣:https://pypi.douban.com/simple
阿里云:https://mirrors.aliyun.com/pypi/simple
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple
使用方法为在 pip 命令后加 -i URL 方法,以从阿里云下载 pandas 库为例:
pip install pandas -i https://mirrors.aliyun.com/pypi/simple
正常安装: pip install pandas
7.python导入库的几种方法
(1)将整个模块导入,格式为:import modulename
#import copy
import copy as cp #as后面是指定的别名
e1=[1]
e5=cp.deepcopy(e1)模块是指一个可以交互使用,或者从另一Python 程序访问的代码段。
只要导入了一个模块,就可以引用它的任何公共的函数、类或属性。
用import语句导入模块,就在当前的名称空间(namespace)建立了一个到该模块的引用.
这种引用必须使用全称,也就是说,当使用在被导入模块中定义的函数时,必须包含模块的名字。
(2)从某个模块导入某个、多个、全部函数,格式为:
from modname import funcname
from modname import fa, fb, fc
from modname import *
#modname中函数名可以直接用,函数前不用加模块的名字.
与第1种方法的区别:funcname 被直接导入到本地名字空间去了,所以它可以直接使用,而不需要加上模块名的限定。* 表示,该模块的所有公共对象(public objects)都被导入到 当前的名称空间,也就是任何只要不是以”_”开始的东西都会被导入。
如果模块包含的属性和方法与你的某个模块同名,你必须使用import module来避免名字冲突。
尽量少用 from module import * ,因为判定一个特殊的函数或属性是从哪来的有些困难,并且会造成调试和重构都更困难。
还可以百度搜一下,尝试通过代码自动导入缺失的库。
8.python没有++运算符
python 中,变量是以内容为基准而不是像 c 中以变量名为基准,所以只要你的数字内容是5,不管你起什么名字,这个变量的 ID 是相同的,也就说明了 python 中一个变量可以以多个名称访问
b = 5
a = 5
print(id(a))#2982608306544
print(id(b))#2982608306544
print(a is b)#True
a=a+1
print(b)#5
print(a is b)#False
正确的自增操作应该 a = a + 1 或者 a += 1,当此 a 自增后,通过 id() 观察可知,id 值变化了,即 a 已经是新值的名称。
9.排序(sorted函数)
sort() 只能对列表排序,而 sorted() 能对可迭代对象排序;所以,字符串、元组、字典、列表等类型想排序,可以用 sorted()
sort()和sorted()函数的区别:
sort只针对列表,没有返回值,会改变原列表顺序
sorted不改变原数据排列顺序,有返回值
str1 = "312"
print(sorted(str1))#['1', '2', '3']
tuple1 = (5, 1, 3)
print(sorted(tuple1))#[1, 3, 5]
dict1 = {"key1": 1, "key2": 2}
print(sorted(dict1))#['key1', 'key2']10.map函数
map的意思通常是指映射。map函数至少有2个参数。一个是参数是函数,另一个参数是一个或多个可迭代对象。
map函数接收一个函数为它的参数,接收一个或多个可迭代对象为参数,返回一个迭代器
。通常使用
list函数将其转换为列表。或者使用多个变量去接收结果。
通常用map进行类型转换
s = "2,3,4,5"
l = s.split(",")
print(list(map(int, l)))#[2, 3, 4, 5]
a=(1,2,3,4,5)
b=[1,2,3,4,5]
c="zhangkang"
la=list(map(str,a))
lb=list(map(str,b))
lc=list(map(str,c))
print(la)#['1', '2', '3', '4', '5']
print(lb)#['1', '2', '3', '4', '5']
print(lc)#['z', 'h', 'a', 'n', 'g', 'k', 'a', 'n', 'g']还可以用自定义函数
def square(n):
return n*n
my_list = [2,3,4,5,6,7,8,9]
updated_list = map(square, my_list)
print(list(updated_list))
def add(x,y,z):
return x+y+z
list1=[1,2,3]
list2=[1,2,3]
list3=[1,2]
res=list(map(add,list1,list2,list3))
print(res)#[3, 6, 9]二.扩展库的学习
1.Numpy的学习:Numpy库的学习_木白星枝的博客-CSDN博客
2.Pandas的学习:Pandas库的学习_木白星枝的博客-CSDN博客
三.用到的需要了解的
1.编程规则
1.1匈牙利命名法
匈牙利命名法通过在变量名前面加上相应的小写字母的符号标识作为前缀,标识出变量的作用域,类型等这些符号可以多个同时使用,顺序是先m_(成员变量), 再指针,再简单数据类型,再其它 。如c_MessageBox
属性+类型+描述
属性一般是小写字母+_:
g_:全局变量
m_:类成员变量
s_:静态变量
c_:常量
类型就多了:
b:bool
sz:以零结束的字符串
p:指针
n:整整
dw:双字
l:长整型
无符号:u
函数:fn1.2驼峰命名法
驼峰命名法包含了小驼峰命名法与大驼峰命名法,顾名思义利用了驼峰命名法来命名变量该变量也会有些高低起伏。
**小驼峰命名法:**变量名称开头小写,后面英文隔一部分后开始大写一个英文字母,如conTent…
**大驼峰命名法:**变量开头大写,后面每隔一部分英文后就大写一个英文字母,如ConTent…
1.3帕斯卡命名法
与大驼峰命名法一样,都是开头大写,后面每隔一部分英文后就大写一个英文字母,如MessageBox…
2.eval函数
#1.使用eva1()函数,将字符串还原为数字类型,和int()函数的作用类似
a = input()
#利用eval()将字符串类型转为整形
print(type(eval(a)),type(int(a)))
#2.将输入的字符串转为对应的数据类型:如列表、元组、字典
#[1,2,4]
#(1,2,4)
#{'a':1,'b':2}
a = input()
n = eval(a) #得到一个列表
print(type(n),type(a))
#3.对表达式的结果进行计算,返回计算后的值
ss1="5*8"
num=90
print(eval(ss1),eval("pow(3,2)"),eval('num+10'))
#4.可以使用格式化字符串的操作更加简便
a=10
oper='+'
b=5
#加法运算
sums=eval(f'{a}{oper}{b}')
print(f'{a}{oper}{b}={sums}')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









