







一、问题提出
- 在学习损失函数的时候,有个Variabel的操作,产生了疑问,在获取__getitem__的过程中,返回的image和label是什么类型呢?
- 总体存放形式是 [images,labels];
- 那么放入卷积神经网络的过程中,具体是什么数据类型呢?目前知道image类型是Tensor类型,label暂时定为数字试试。
二、制作过程
- 将星期一与数字1对应,CSV文件转换;
- 删除中文标题;
- 将单元格格式设置为百分数转成4位小数;
- 将所有单元格格式设置成为4位数值格式
- 取出所有单个片段进行训练
三、出现问题
TypeError: can't convert np.ndarray of type numpy.object_.
The only supported types are:
float64, float32, float16, int64, int32, int16, int8, uint8, and bool.
- 不知道是出现了空格问题,还是数据超出了预定义类型?
- 经过测试,发现转成numpy没有问题,numpy转Tensor有问题;
- 测试图片

- 猜想和空格行有关系,独立几个片段试一试。
- 发现torch.from_numpy()会有格式问题,那我在Excle里面去转换一下格式
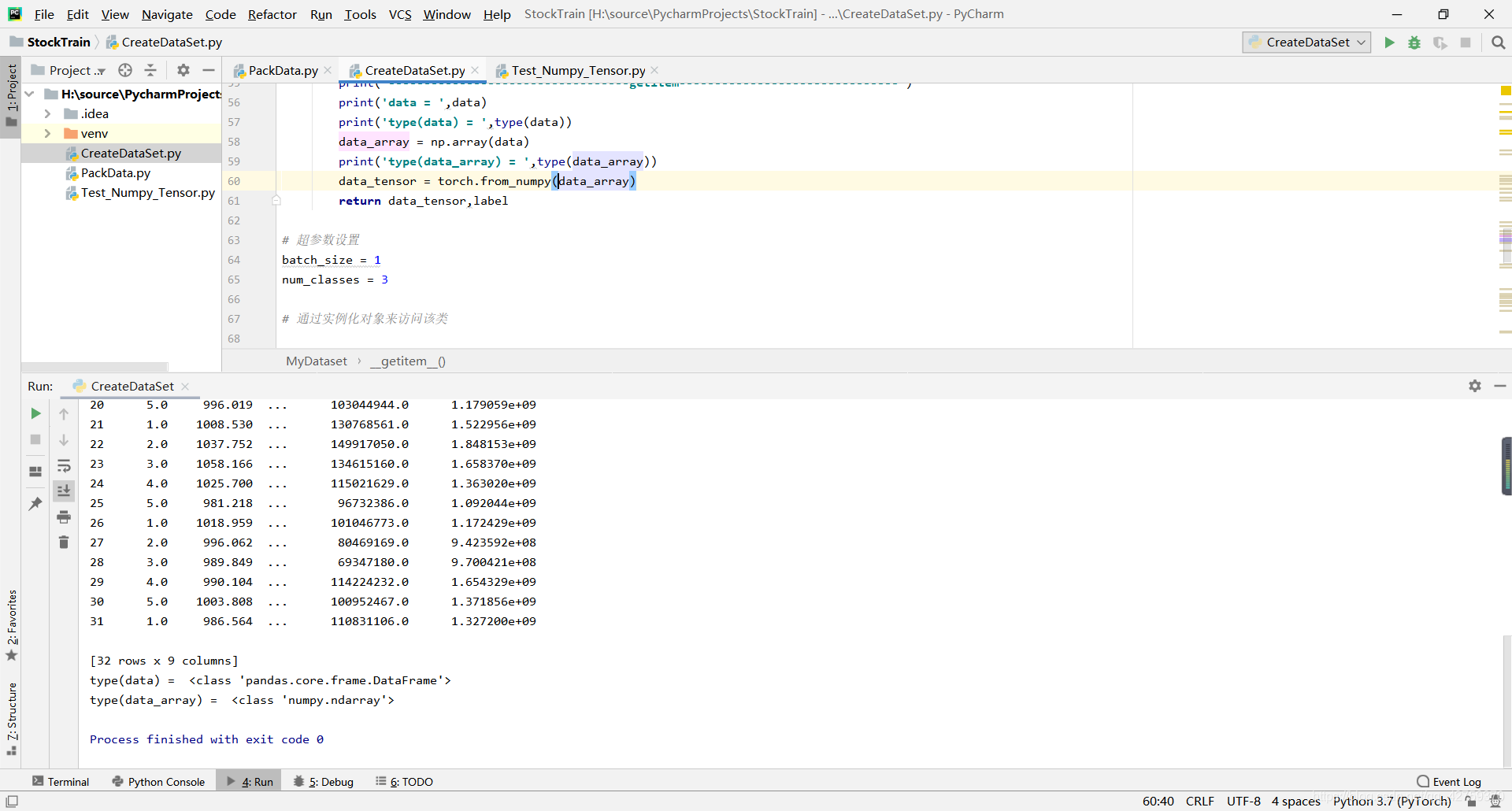
- 格式转换成功!
- 成功执行结果:
四、数据进一步处理
思路一:
- 选取中位数偏小的数据段,进行内容裁切,然后多余的,按照步长的方式,循环前进。
- 或者扩展数据选取,(增加误判错误的可能性),删除数据选取;
- 数据是否要归一化,因为存在数据量递增的情况?例如图片的时候,在色彩归一化的情况下,要么是0-255,要么是0~1。
- 获取所有CSV数据的行数,选取前1/5,作为基础行数,实现代码如下:
txt_path = 'G:/stock/path.txt'
fh = open(txt_path)
# 记录各个CSV文件的行数
data_len = []
# 根据文件路径TXT遍历CSV文件
# txt文件格式 路径 '\t' 类别 '\t' 长度
# 选取line[2]:作为长度数,并进行int(x)转换
for line in fh:
# 移除字符串'\n'
line = line.rstrip('\n')
# 各分字符串'\t'
line = line.split('\t')
# 将长度<str>转成数字<int>
line[2] = int(line[2])
data_len.append(line[2])
# 升序排序
data_len.sort()
# 显示数据长度
print('data_len = ',data_len)
# 数据总长度
length = len(data_len)
# 取比较小的数据集长度
index = int(length/4)
print('index = ',index)
print('data_len[index] = ',data_len[index])
- 实现结果:

- 反思总结:
到目前为止,我们舍去了行数<32的数据,将大于32行数的,先视野大小=32,每次移动1行,将一个行数比较多的数据,拆分成多个32 * 9的小片段。
所以,在卷积层的第一层卷积的时候:输入参数为:
batch_size = 64
input_channel = 1
output_channel = 4
卷积核大小暂时定为 = 5
开始构建卷积神经网络…
五、学习总结
- 格式转换参照:二、制作过程
- CSV文件转Tensor
import pandas as pd
import numpy as np
data = pd.read_csv(csv_path)
data_array = np.array(data)
# 方法一
data_tensor = Torch.Tensor(data_array)
# 方法二
data_tensor = Torch.from_numpy(data_array)
- pandas:DataFrame 获取行数和列数
import pandas as pd
data = pd.read_csv(CSV_PATH)
# 获取行数
rows = data.shape[0]
# 或
rows = len(data)
# 获取列数
cols = data.shape[1]
六、Excle小技巧
- 通配符:* 批量替换星期四:* 四 * 替换成 4















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









