







 本文介绍了类似FICO的信用评分模型开发过程,以支付宝芝麻信用为例。通过收集和分析用户数据,利用统计指标进行属性选择,处理离群值和缺失值,最终通过WOE和IV指标评估属性重要性,训练信用评分模型。
本文介绍了类似FICO的信用评分模型开发过程,以支付宝芝麻信用为例。通过收集和分析用户数据,利用统计指标进行属性选择,处理离群值和缺失值,最终通过WOE和IV指标评估属性重要性,训练信用评分模型。
以支付宝的芝麻信用为例,其分值范围在350-950分。一般认为分值越高,信用越好,个人业务的违约率越低。这里用的也是与FICO评分类似的个人信用评分工具。
FICO评分的只要思路是:多大量拥有多个属性的用户数据进行收集/分析/转换,使用各项统计指标(如相关系数/卡方校验/方差膨胀系数等)对属性进行取舍/复制/组合,最终得到一个量化的/综合的/可用于对比的分值。分值的高低,一方面反映了用户历史信用记录的好坏,另一方面暗示了未来违约可能性的大小。
这里使用到的原始数据主要包括客户的个人信息(包括性别/年龄/工作岗位/婚姻情况/学历状况等)/账户信息(包括各种账户的数量/存贷款余额等),以及该客户是否存在违约的分类标签。
数据集经过处理后,需要经过数据分箱/属性选择以及离散分类标签与连续信用评分结果的转换等过程。
数据集的下载
链接: https://pan.baidu.com/s/1xh1kjo6waZZEPrxJFrwCng 密码: u744
一.导入数据
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#查看原始数据
data = pd.read_csv('credit.csv')
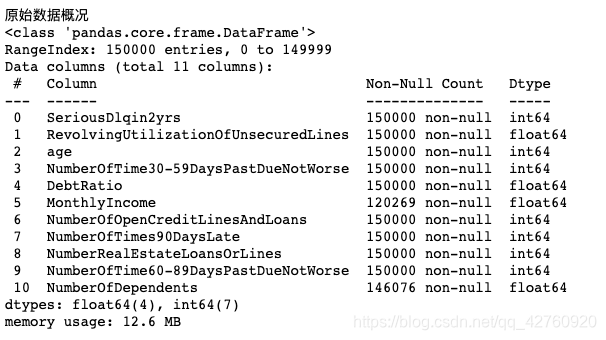
print('原始数据概况')
data.info()
#数据为12.6M,11个属性,有两个属性MonthlyIncome和NumberOfDependents中有空值
数据为12.6M,有11个属性,有两个属性MonthlyIncome和NumberOfDependents中有空值
二.数据清洗
因为MonthlyIncome和NumberOfDependents中有缺失值,需要对其进行处理,常用的方法1.有上下值填入空白处;2.属性均值填入空白处。但是各有它的缺点。这里定义了一个set_missing的函数,用来填充随机森林回归算法对缺失值进行填充。
#进行数据清洗
#用随机森林方法对MonthlyIncome缺失值进行预测填充,这里定义了set_missing函数
from sklearn.ensemble import RandomForestRegressor
def set_missing(df):
print('随机森林回归填充0值:')
process_df = df.iloc[:,[5,0,1,2,3,4,6,7,8,9]]
#把第5列的MonthlyIncome提前到第0列,作为一个标签,便于后续划分数据
#分成有数值缺失值两组
known = process_df.loc[process_df['MonthlyIncome']!=0].values
unknown = process_df.loc[process_df['MonthlyIncome']==0].values
X = known[:,1:]
y = known[:,0]
#用x,y训练随机森林回归算法
rfr = RandomForestRegressor(random_state=0,n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
#得到的模型进行缺失值预测
predicted = rfr.predict(unknown[:,1:]).round(0)
#得到的预测结果填补原缺失数据
df.loc[df['MonthlyIncome'] == 0,'MonthlyIncome'] = predicted
return df
定义outlier_processing函数,用于对属性中的离群数据点进行删除处理
这里用到的方法是数据分箱:将属性的取值分成若干段(箱体),落在同一个箱体范围内的数据,用一个统一的数值代替。
#对属性中的异常值进行删除处理,找出离群点,先计算最大和最小阈值作为删除标准
#最小阈值 = 第一四位点 - 1.5*(第三四分位点 - 第一四分位点)
#最大阈值 = 第三四位点 + 1.5*(第三四分位点 - 第一四分位点)
# <最小阈值 和 >最大阈值的行将会被删除
#定义了outlier_processing函数,用于处理离群数据点
def outlier_processing(df,cname):
s = df[cname]
onequater = s.quantile(0.25)
threequater = s.quantile(0.75)
irq = threequater - onequater
min = onequater - 1.5*irq
max = threequater + 1.5*irq
df = df[df[cname]<=max]
df = df[df[cname]>=min]
return df
MonthlyIncome原始分布图和处理后分布图
#对MonthlyIncome列进行数据整理
print('MonthlyIncome属性离群点原始分布:')
data[['MonthlyIncome']].boxplot()
plt.savefig('MonthlyIncome1.png',dpi = 300,bbox_inches = 'tight')
plt.show()
print('删除离群点,填充缺失数据:')
data = outlier_processing(data, 'MonthlyIncome')#删除离群点
data = set_missing(data)#填充缺失数据
print('处理MonthlyIncome后数据概况:')
data.info()#查看整理后数据
#图像显示
data[['MonthlyIncome']].boxplot()#箱线图
plt.savefig('MonthlyIncome2.png',dpi = 300,bbox_inches = 'tight')
plt.show()
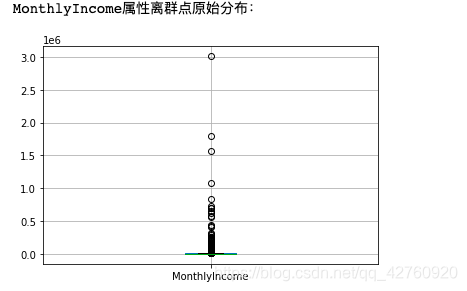
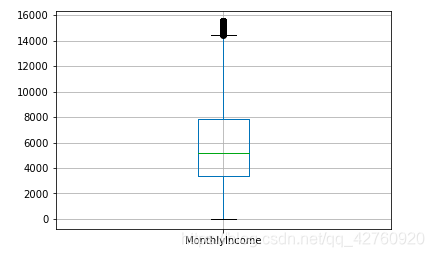
删除离群点,填充缺失数据后,数据集少了2M

同理,对其他属性进行离群点处理
#同理,对其他属性进行离群点处理
data = outlier_processing(data, 'age')
data = outlier_processing(data, 'RevolvingUtilizationOfUnsecuredLines')
data = outlier_processing(data, 'DebtRatio')
data = outlier_processing(data, 'NumberOfOpenCreditLinesAndLoans')
data = outlier_processing(data, 'NumberRealEstateLoansOrLines')
data = outlier_processing(data, 'NumberOfDependents')
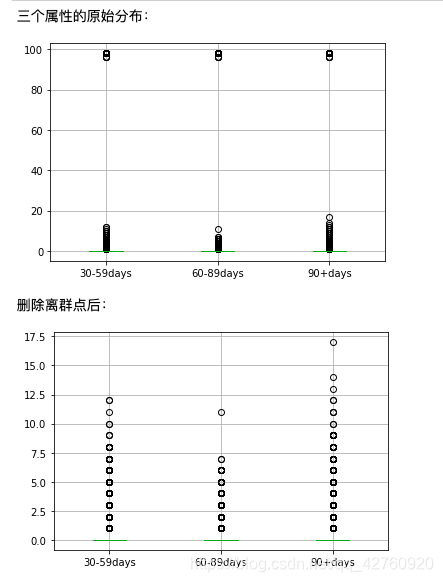
对于三个取值过于集中的属性进行手工处理
#三个取值过于集中的属性,三个四分位点的值相等,直接用outlier_processing的函数会导致所有值被删除
#因此对这三个属性进行手工处理
features = ['NumberOfTime30-59DaysPastDueNotWorse','NumberOfTime60-89DaysPastDueNotWorse','NumberOfTimes90DaysLate']
features_labels = ['30-59days','60-89days','90+days']
print('三个属性的原始分布:')
data[features].boxplot()
plt.xticks([1,2,3],features_labels)
plt.savefig('三个属性的原始分布', dpi = 300 ,bbox_inches = 'tight')
plt.show()
print('删除离群点后:')
data = data[data['NumberOfTime30-59DaysPastDueNotWorse']<90]
data = data[data['NumberOfTime60-89DaysPastDueNotWorse']<90]
data = data[data['NumberOfTimes90DaysLate']<90]
data[features].boxplot()
plt.xticks([1,2,3],features_labels)
plt.savefig('三个属性的整理后分布', dpi = 300 ,bbox_inches = 'tight')
plt.show()
print('处理离群点后数据概况:')
data.info()

#生成数据集和测试集
from sklearn.model_selection import train_test_split
#原始值0为正常,1为违约。因为习惯上信用评分越高,违约的可能越小,所以将原始值0和1置换
data['SeriousDlqin2yrs'] = 1- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









