







cpu不需要将数据从一个内存区域复制到另一个内存区域从而减少上下文切换以及CPU的拷贝时间.
主要作用是在网络数据报从网络设备都用户程序空间传递过程中,减少数据拷贝次数,减少系统调用,实现cpu的零参与,彻底消灭cpu在这方面的负载.
主要技术是DMA数据传输技术和内存区域映射技术.
DMA保证了直接从网络端口寄存器 – > 内存
1. 虚拟内存
虚拟内存和用户进程息息相关,虚拟内存的存在就是让每个进程觉得自己独占整个内存.每个进程所能使用的空间和cpu所使用的位数有关.
虚拟内存本质上还是一段地址,地址的位数依赖于CPU的位数.
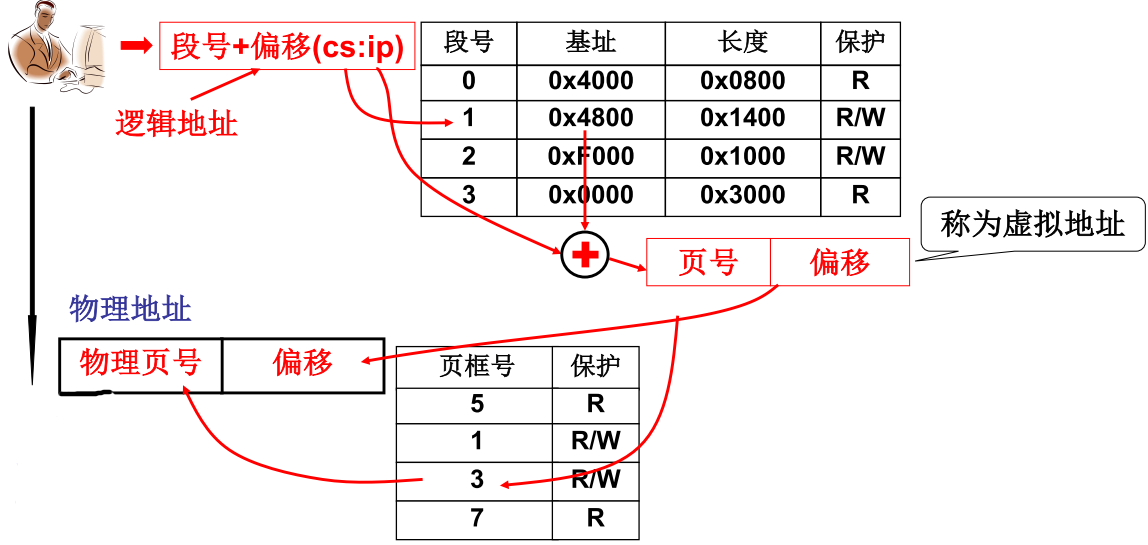
程序/进程 → 映射 逻辑地址 → segment unit 段 基 址 + 偏 移 地 址 虚拟地址 → page unit 页 表 物理内存地址 \text{程序/进程}\overset{}{\xrightarrow[\text{映射}]{}} \text{逻辑地址}\overset{段基址+偏移地址}{\xrightarrow[\text{segment unit}]{}} \text{虚拟地址}\overset{页表}{\xrightarrow[\text{page unit}]{}} \text{物理内存地址} 程序/进程映射逻辑地址segment unit段基址+偏移地址虚拟地址page unit页表物理内存地址
引入虚拟内存的优点:
-
地址空间:提供更大的地址空间,并且地址空间是连续的,使得程序编写、链接更加简单
-
进程隔离:不同进程的虚拟地址之间没有关系,所以一个进程的操作不会对其它进程造成影响
-
数据保护:每块虚拟内存都有相应的读写属性,这样就能保护程序的代码段不被修改,数据块不能被执行等,增加了系统的安全性
-
内存映射:有了虚拟内存之后,可以直接映射磁盘上的文件(可执行文件或动态库)到虚拟地址空间。这样可以做到物理内存延时分配,只有在需要读相应的文件的时候,才将它真正的从磁盘上加载到内存中来,而在内存吃紧的时候又可以将这部分内存清空掉,提高物理内存利用效率,并且所有这些对应用程序是都透明的
-
共享内存:比如动态库只需要在内存中存储一份,然后将它映射到不同进程的虚拟地址空间中,让进程觉得自己独占了这个文件。进程间的内存共享也可以通过映射同一块物理内存到进程的不同虚拟地址空间来实现共享
-
物理内存管理:物理地址空间全部由操作系统管理,进程无法直接分配和回收,从而系统可以更好的利用内存,平衡进程间对内存的需求
2. 用户空间和内核空间
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。
内核进程和用户进程所占的虚拟内存比例是 1:3.所以32位操作系统,对于每个进程而言只有3G虚拟内存空间.
2.1. 内核空间
-
进程私有的虚拟内存:每个进程都有单独的内核栈、页表、task 结构以及 mem_map 结构等。
-
进程共享的虚拟内存:属于所有进程共享的内存区域,包括物理存储器、内核数据和内核代码区域。
2.2. 用户空间

-
运行时栈:由编译器自动释放,存放函数的参数值,局部变量和方法返回值等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存储到栈顶,调用结束后调用信息会被弹出弹出并释放掉内存。栈区是从高地址位向低地址位增长的,是一块连续的内在区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
-
运行时堆:**用于存放进程运行中被动态分配的内存段,位于 BSS 和栈中间的地址位。**由卡发人员申请分配(malloc)和释放(free)。堆是从低地址位向高地址位增长,采用链式存储结构。频繁地 malloc/free 造成内存空间的不连续,产生大量碎片。当申请堆空间时,库函数按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
-
代码段:存放 CPU 可以执行的机器指令,该部分内存只能读不能写。通常代码区是共享的,即其它执行程序可调用它。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
-
未初始化的数据段:存放未初始化的全局变量,BSS 的数据在程序开始执行之前被初始化为 0 或 NULL。
-
已初始化的数据段:存放已初始化的全局变量,包括静态全局变量、静态局部变量以及常量。
-
内存映射区域:例如将动态库,共享内存等虚拟空间的内存映射到物理空间的内存,一般是 mmap 函数所分配的虚拟内存空间。
3. Linux I/O读写方式
linux提供了三种磁盘与主存(大部分时候是用户空间)之间的数据传输机制:
- 轮询
轮询的机制很简单,基于死循环对于I/O端口进行不断的检测,如果I/O没有完成预期的任务就会被一直卡死在那里.
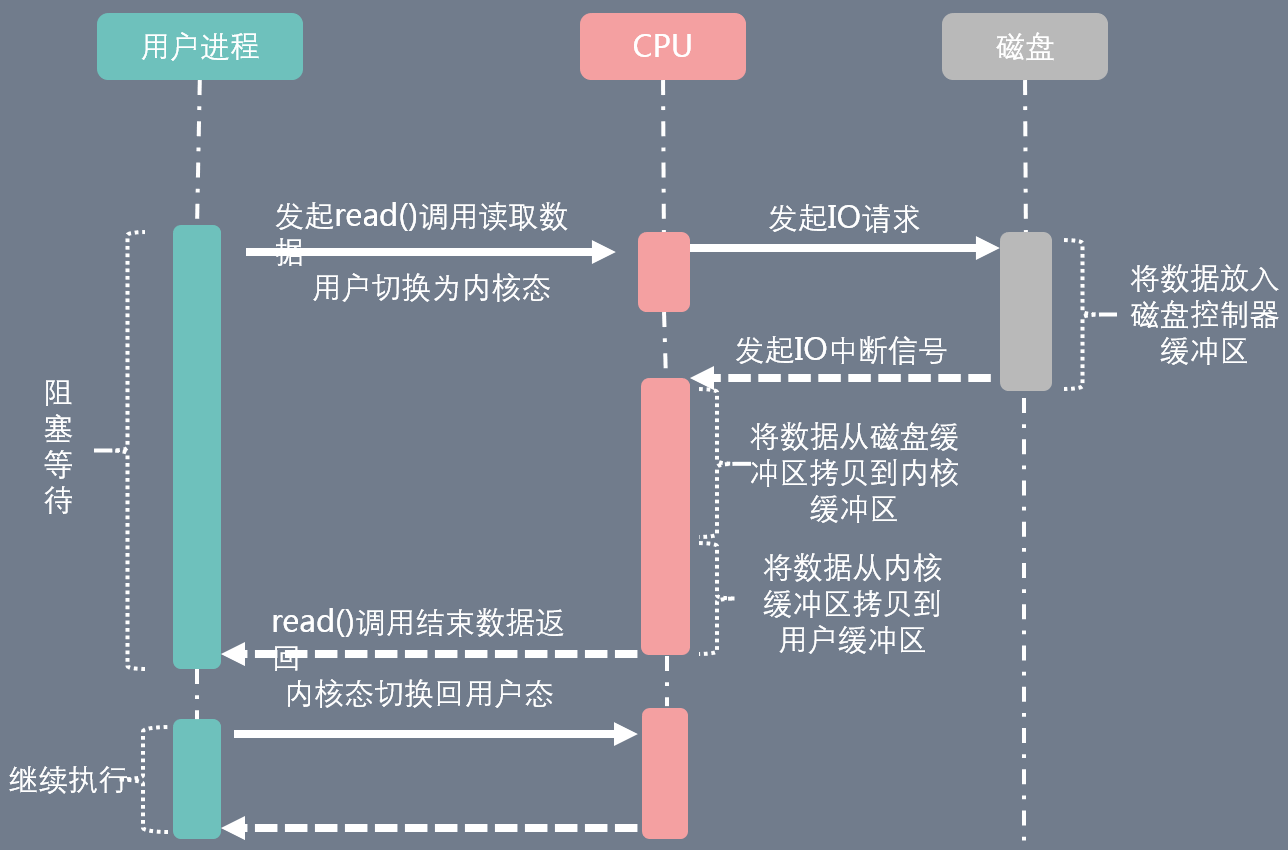
- I/O中断
CPU发起IO请求后,就执行其他任务,直到磁盘完成相应任务,发出IO中断信号,CPU在回来完成整个任务.
- DMA传输
DMA技术相较于I/O中断技术,改进的地方是:DMA技术可以直接将内容从磁盘缓冲区读取到内核缓冲区,相当于帮助cpu完成了部分工作.
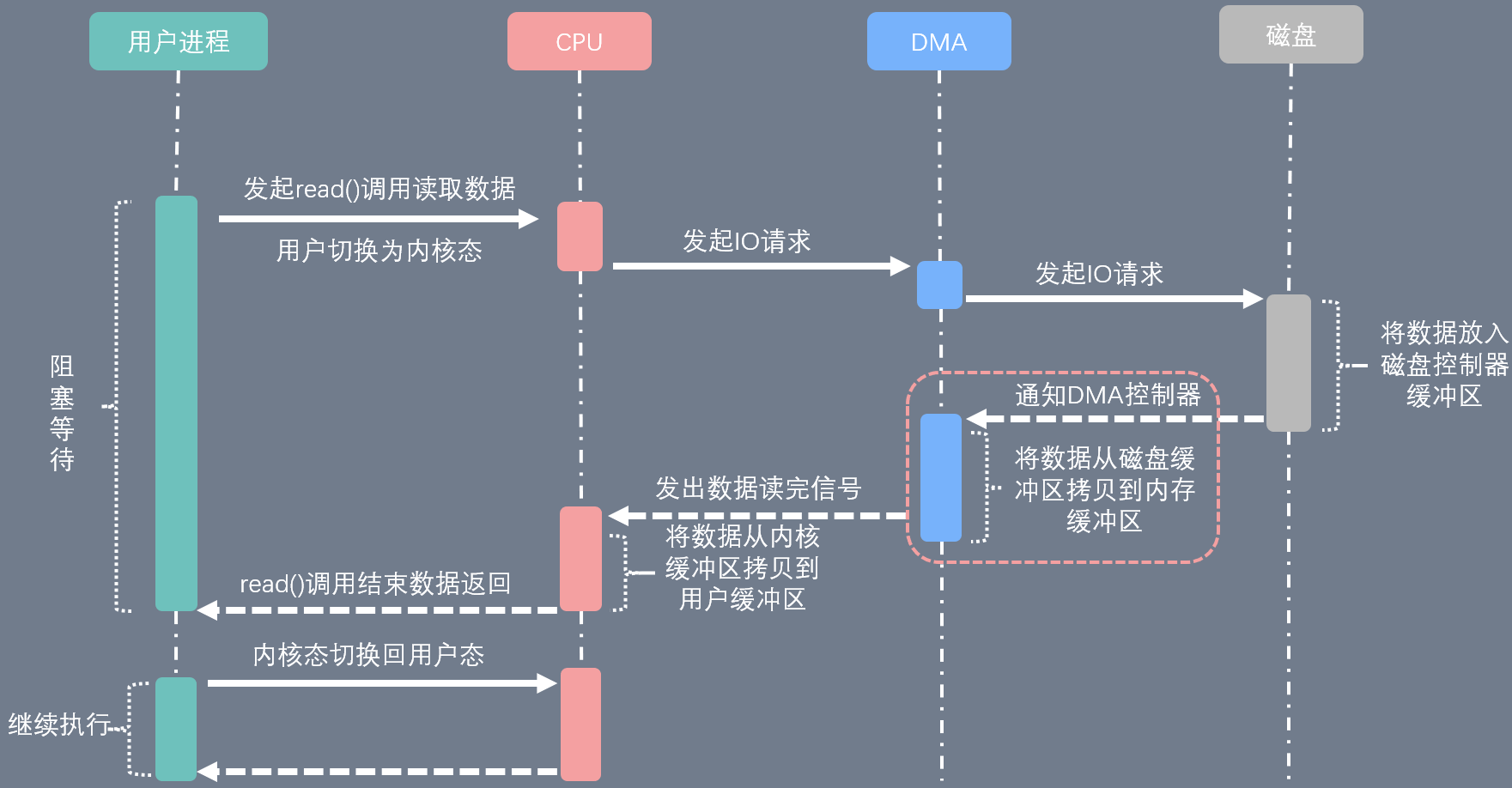
当然除了磁盘外,网卡,显卡和声卡都是支持DMA技术的.
5. 传统I/O方式
在linux系统中,传统的访问方式是通过write()和read()两个系统调用实现的.
read(file_fd, tmp_buf, len);
write(socket_fd, tmp_buf, len);
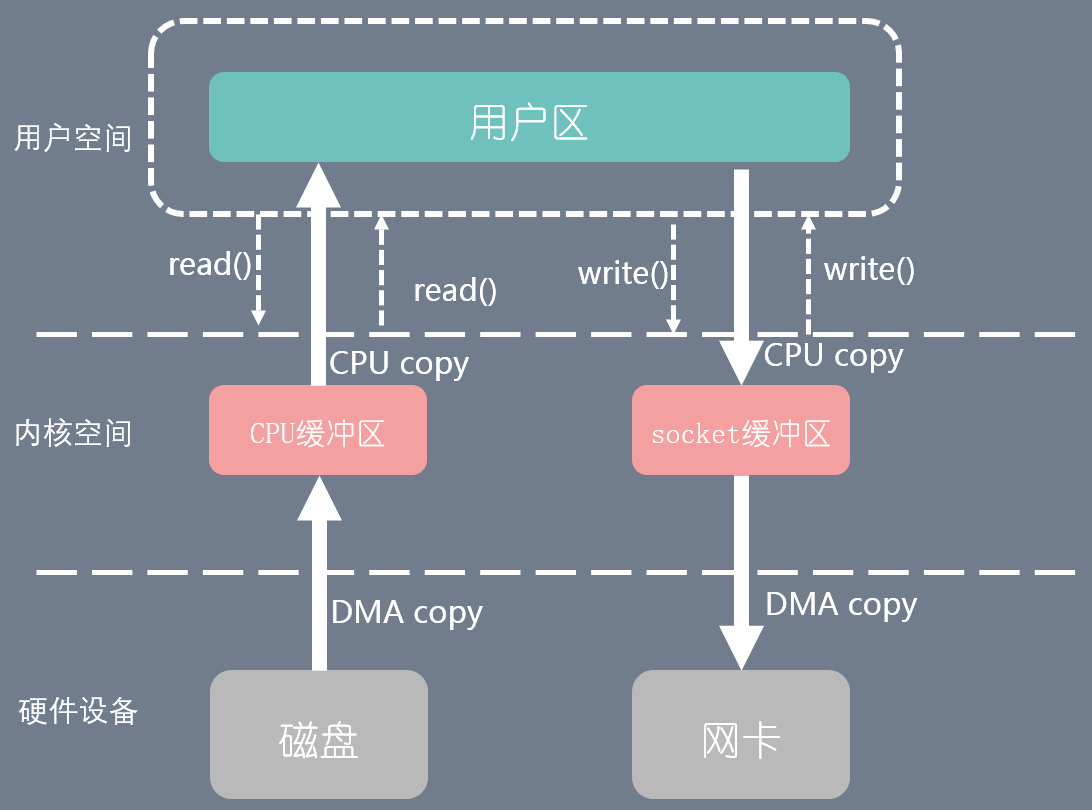
由图可见整个过程涉及了两次CPU拷贝,两次DMA拷贝,以及四次上下文切换(从内核态/用户态转为用户态/内核态).
6. 零拷贝方式
linux中零拷贝技术主要有三个实现的思路:
6.1 用户态直接IO:
用户空间直接与硬件设备直接交换数据.

此项技术整个过程两次硬件与用户空间的拷贝,四次上下文的切换.
用户态直接 I/O 只能适用于不需要内核缓冲区处理的应用程序,这些应用程序通常在进程地址空间有自己的数据缓存机制,称为自缓存应用程序,如数据库管理系统就是一个代表。其次,这种零拷贝机制会直接操作磁盘 I/O,由于 CPU 和磁盘 I/O 之间的执行时间差距,会造成大量资源的浪费,解决方案是配合异步 I/O 使用。
同步IO、异步IO、阻塞IO、非阻塞IO之间的联系与区别
6.2减少数据拷贝次数
对于四次的拷贝次数linux内核提供了几种技术以减少拷贝次数.
6.2.1 mmap + write
mmap的作用是将用户缓冲区一部分内容设置为共享区域,这部分区域可以共享到内核空间的缓存区.
tmp_buf = mmap(file_fd, len);
write(socket_fd, tmp_buf, len);
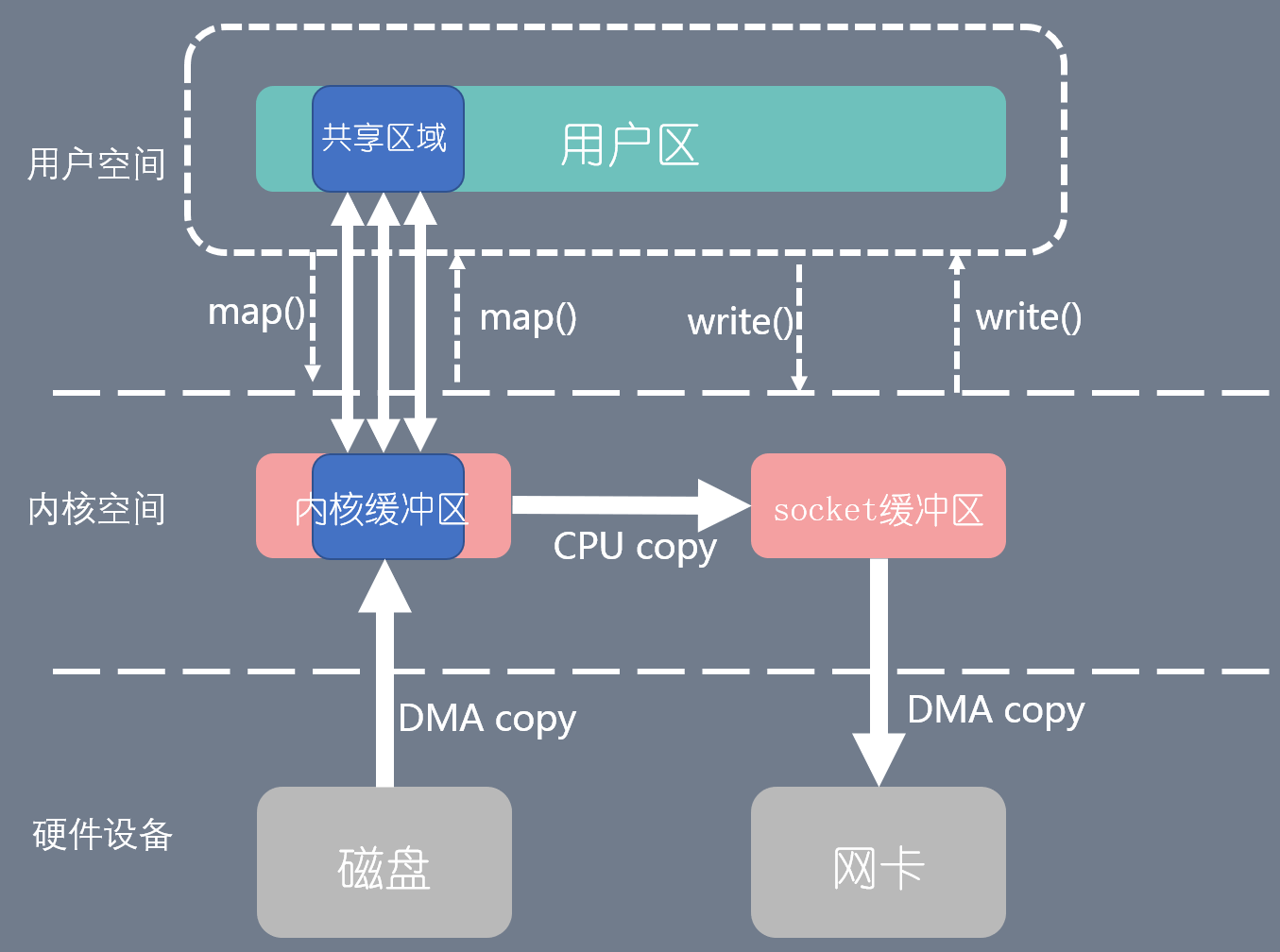
整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
-
用户进程通过 mmap() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。将用户进程的内核空间的读缓冲区(read buffer)与用户空间的缓存区(user buffer)进行内存地址映射。
-
CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
-
上下文从内核态(kernel space)切换回用户态(user space),mmap 系统调用执行返回。
-
用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
-
CPU将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
-
CPU利用DMA控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
-
上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费,因为内存映射总是要对齐页边界,最小单位是 4 KB,一个 5 KB 的文件将会映射占用 8 KB 内存,也就会浪费 3 KB 内存。
此外当mmap一个文件时,如果这个文件被另一个进程所截获, write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump,服务器可能因此被终止。
6.2.2 sendfile
sendfile(socket_fd, file_fd, len);//注意这里两者必须如描述所示
通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中** I/O 数据对用户空间是完全不可见的**。也就是说,这是一次完全意义上的数据传输过程。
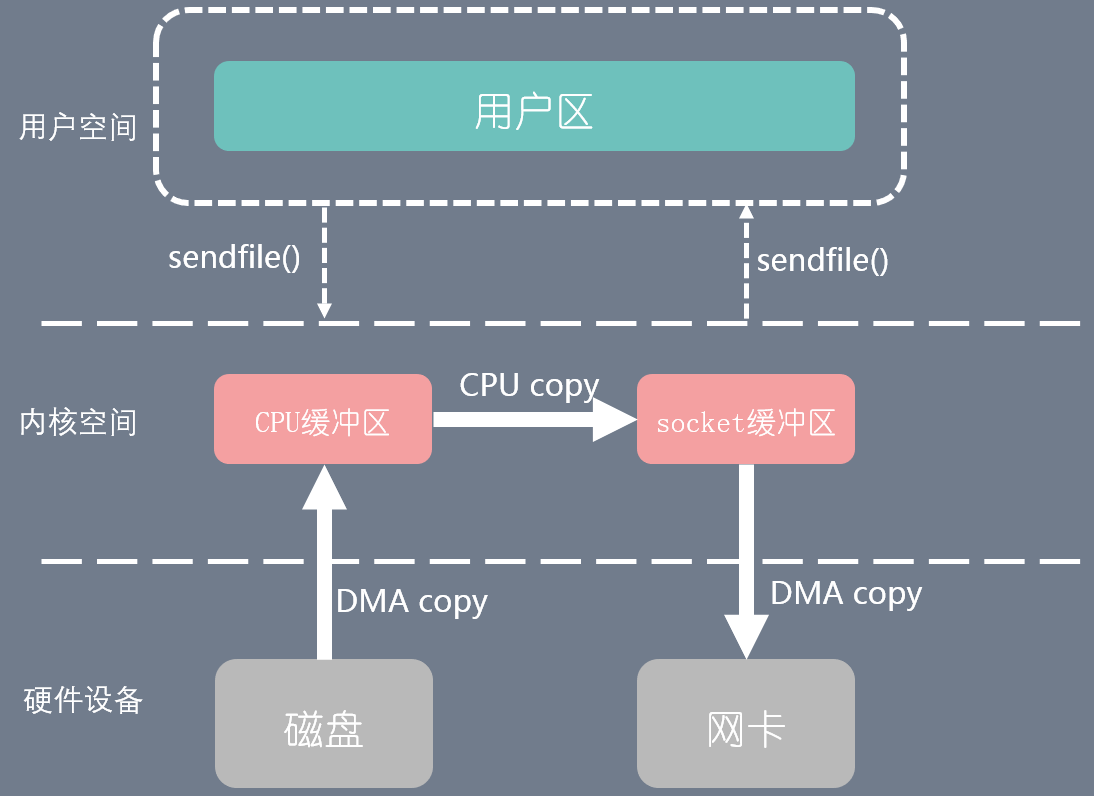
两次上下文切换过程,三次拷贝过程
整个过程的缺点也是显而易见的,用户程序由于对于整个过程是完全没有参与的,所以完全不知道输出的内容,单纯做了一个数据传输的过程.
6.2.3 sendfile + DMA gather copy
对于上述的内容,我们思考一下就是为什么一定要如上述一样DMA访问的是socket访问去,我们知道了cpu缓存区域地址,为什么不直接从cpu缓存区直接DMA传输到网卡设备.linux2.4 支持了这样的操作
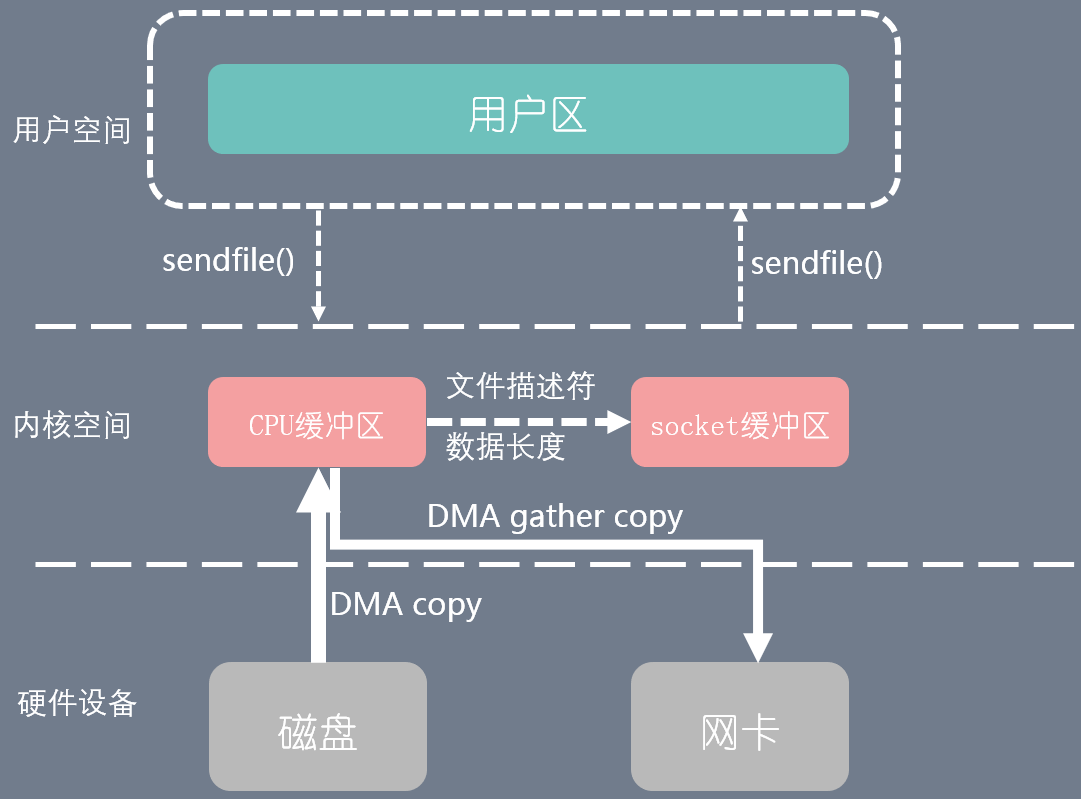
两次上下文切换,两次DMA拷贝
注意使用gather copy时需要将文件描述符,数据长度拷贝到socket缓存区,因为DMA gather copy是需要根据这些内容实现拷贝的.
它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
6.2.4 splice
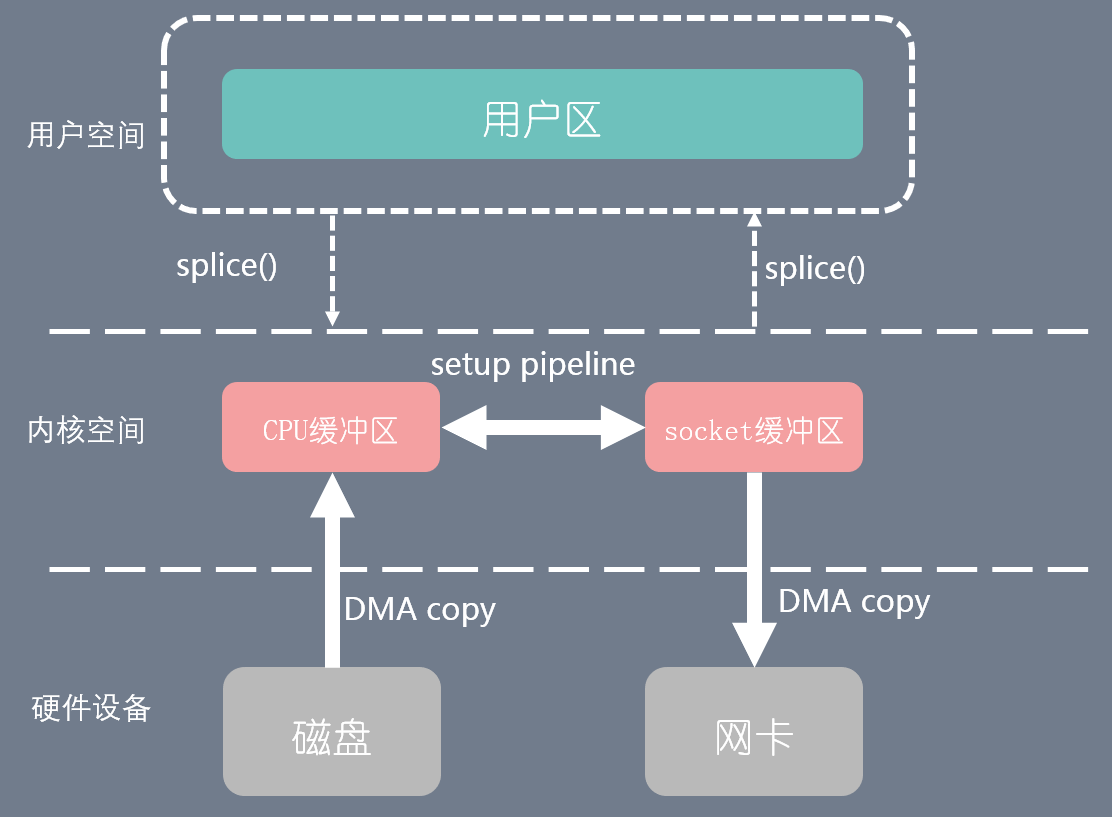
Linux 在 2.6.17 版本引入 splice 系统调用,不仅不需要硬件支持,还实现了两个文件描述符之间的数据零拷贝。
splice(fd_in, off_in, fd_out, off_out, len, flags);
//有一个文件描述符必须是管道描述符
-
用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
-
CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
-
CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
-
CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
-
上下文从内核态(kernel space)切换回用户态(user space),splice 系统调用执行返回。
6.3 写时复制
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









